-
MySQL索引事务——小记
索引
概念
使用一定的数据结构,来保存索引字段(一列或多列)对应的数据。以后根据索引字段来检索,就可提高检索效率。
sql性能优化关键:是否能够命中索引。
因为其使用一定数据结构来保存,所以需要一定的空间(本地硬盘的文件)来保存。创建索引,更新/删除索引字段,插入数据:都会导致索引更新的耗时操作。
page
数据库保存数据的基本单位:page
目的:硬盘读取文件到内存的io操作也是耗时的,读取数据最好也就能最少次读取到需要的结果集
索引类型
B树vsB+树
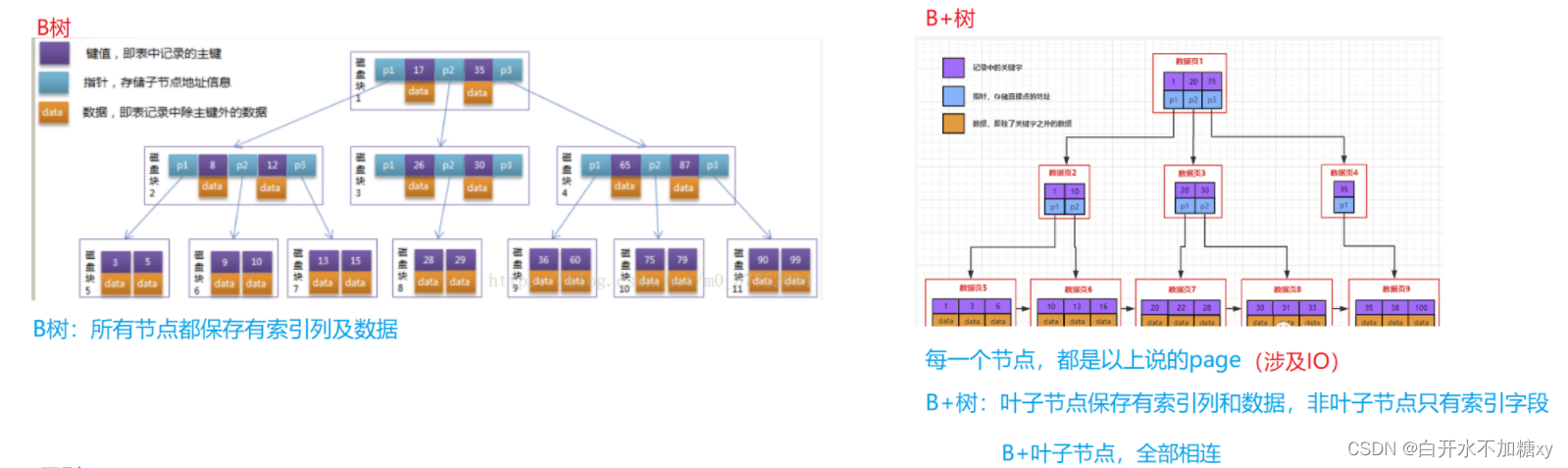
区别:
1. 数据的保存位置不同B+树保存在叶子结点,B树保存在所有结点中。
体现了B+树优势:结点不存储数据,这样一个结点可以存储更多key,可使得树更紧凑,所以IO操作次数更少。
查询性能稳定:每次查询都是从根节点遍历到叶子节点,查询路径长度相同,即每次查询效率相当2. 叶子节点的指向:
B+树相邻的叶子节点通过指针相连,B树没有
体现出B+树优势:所有叶子节点形成有序链表,便于范围查找B+树:

主键索引
默认是B+树,聚簇索引(一张表只能有一个主键索引)
B+树的叶子节点上,存放主键字段(索引字段)及数据

主键索引(聚簇索引)

优缺点:
优点: 速度快
缺点: 主键需要是整型,且字段不要太长。更新代价大(效率低)非聚簇索引
非主键索引都是。可以使用很多种类型的索引,如B+树,Hash索引等。
假如用B+树,存储结构︰叶子节点:存放索引字段值+主键的值

age字段建立的B+树索引

搜索数据的方式:
(1)先通过索引字段,找到叶子节点上的主键值
(2) 再通过主键值,找整条数据。存在回表,意味着效率比主键索引慢优缺点:
优点: 更新代价相对比聚簇索引小(叶子节点是索引值和主键值,没有真实数据)
缺点:
(1)也依赖有序数据
(2)可能产生回表操作导致效率会更低覆盖索引
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为"覆盖索引"


检索的时候,是根据name索引字段来检索(name是在叶子节点,排序的),查询字段又没有其他字段,所以就不需要回表复合索引/联合索引
涉及最左匹配原则︰联合索引的多个索引字段,遵循从左往右的优先级,最左优先,当出现范围查询(>

优化
基于B+树的索引
1.主键索引(聚簇索引)2.非聚簇索引

hash索引
Hash索引指的就是Hash表,最大的优点就是能够在很短的时间内,根据Hash 函数定位到数据所在的位置,这是B+树所不能比的。
hashmap存储数据的特性:键值对,无序,键唯一(不重复)
hashmap底层数据结构:数组+链表+红黑树!!

缺点:不支持顺序和范围查询哈希表实现 vs 搜索树实现
优缺点:
哈希表优点:
1.速度相对来说较快。
2.原理和实现简单。——实现线程安全比较容易
缺点:查找只支持 is / is not平衡搜索树优点:
1.搜索树中维护的key是有序的 ——在数据库中搜索树应用更广,支持范围查询 > <
2.不会出现哈希冲突的问题。事务
事务的特性ACID


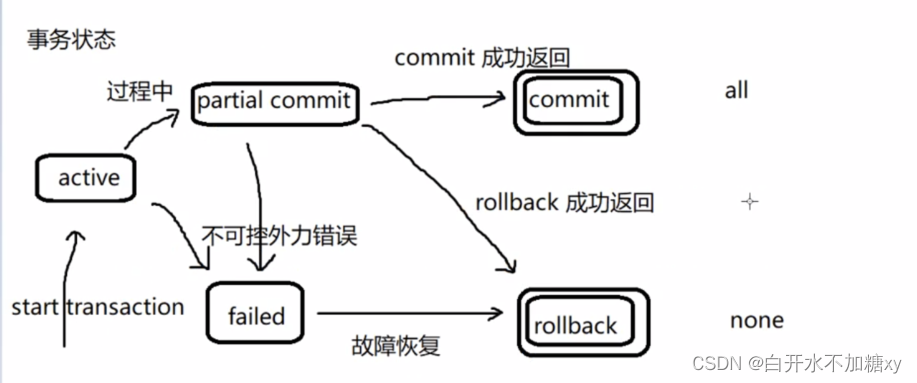
事务状态
问题
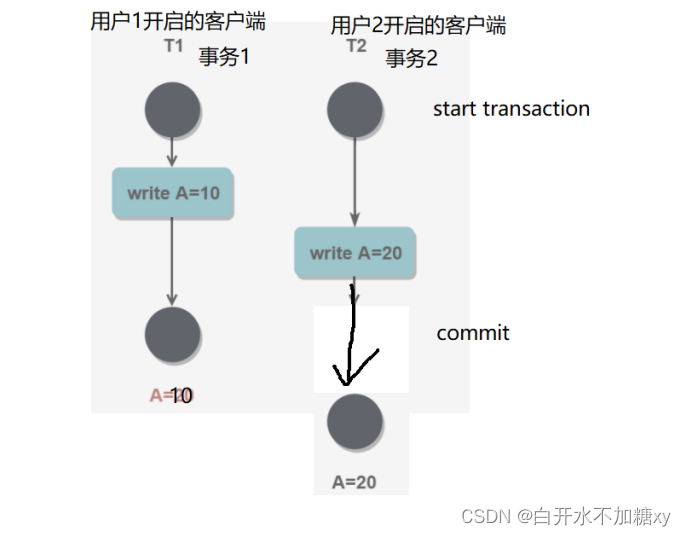
(1)丢失更新 事务1修改数据的操作,在事务2修改以后,就覆盖掉(相当于丢失)
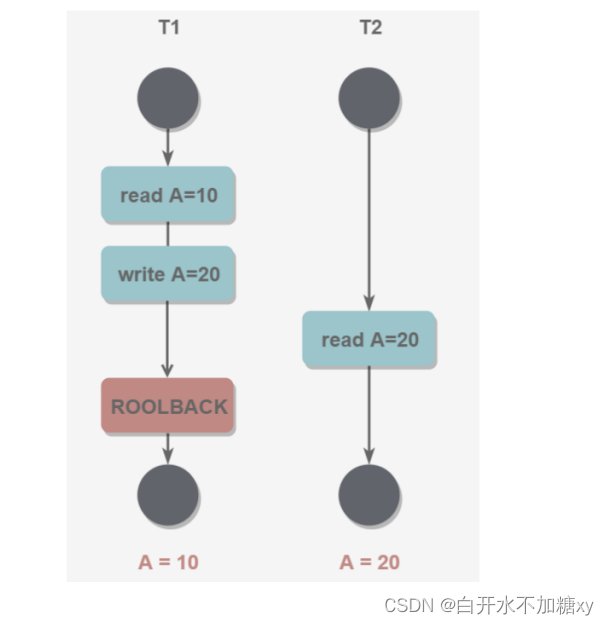
(2)脏读(第一个事务修改数据但没有提交,第二个事务就读取,在第一个事务回滚后,第二个事务读取的就是脏数据)
(3)不可重复读―一个事务两次读取数据,中间有另一个事务修改,第一个事务两次读取的数据就不同(不一致)
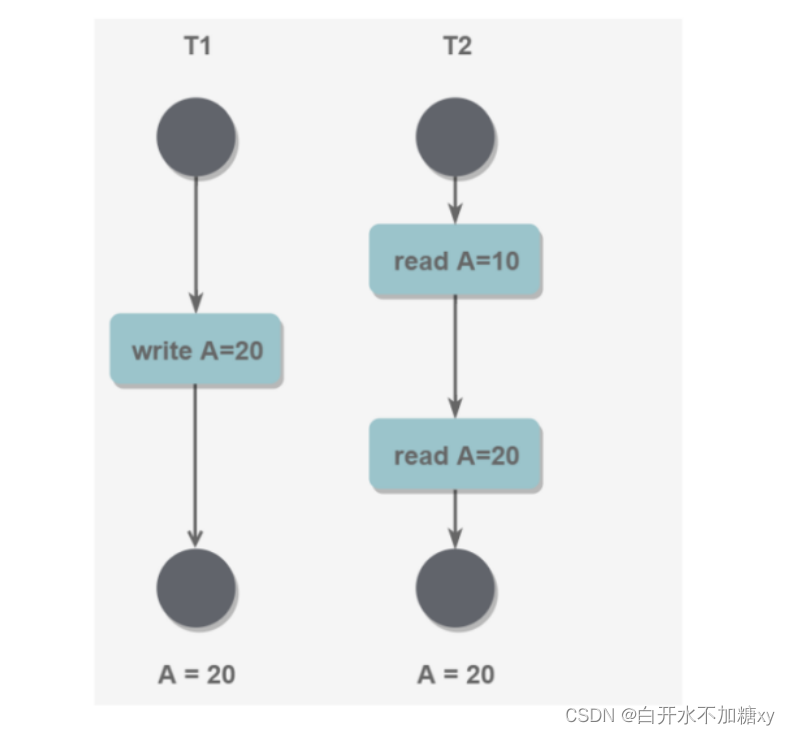
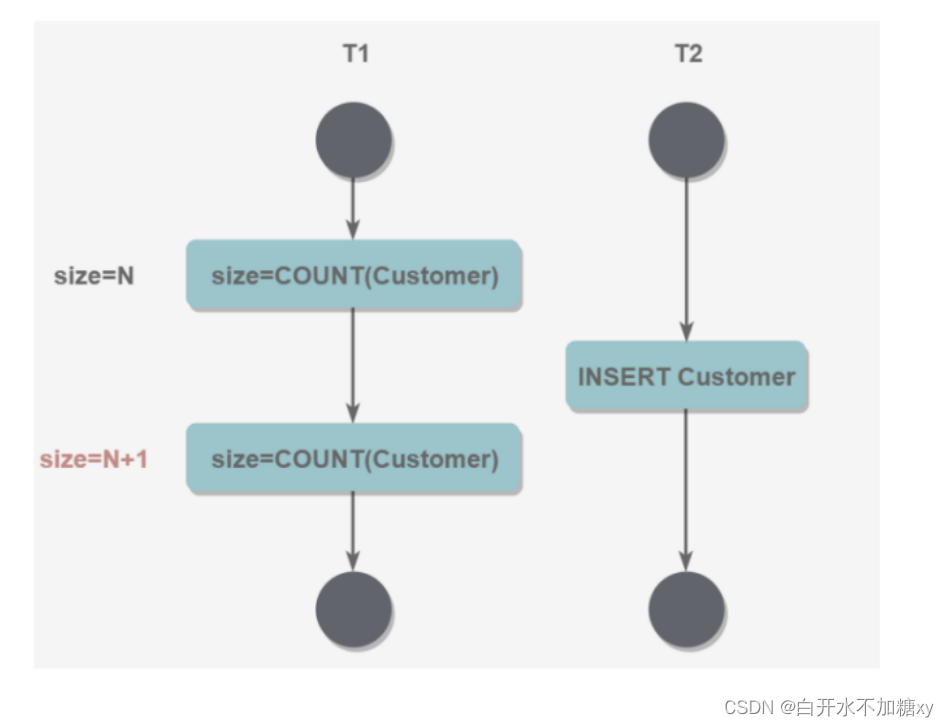
(4) 幻读 一个事务两次读取,中间有另一个事务执行了插入操作,造成第一个事务看到不同的结果
隔离级别
隔离级别!!!


undo log
undo log是事务原子性和隔离性实现的基础。
之所以能够保证原子性,则是靠undo log。当事务对数据库进行修改时,InnDB会生成对应的undo log;如果事务失败或者调用了rollback,导致事务回滚,便可以利用undo log中的信息将数据回滚到修改之前的样子。
undo log属于逻辑日志,它记录的是sql执行相关的信息。当发生回滚时,InnoDB会根据undo log的内容做与之前相反的工作:对于每个insert,回滚时会执行delete;对于每个delete,回滚时会执行insert;对于每个update,回滚时会执行一个相反的update,把数据改回去。
以update操作为例:当事务执行update时,其生成的undo log中会包含被修改行的主键(以便知道修改了哪些行)、修改了哪些列、这些列在修改前后的值等信息,回滚时便可以使用这些信息将数据还原到update之前的状态。
-
相关阅读:
asp.net毕业设计项目源码社区保障管理系统
[附源码]计算机毕业设计JAVA社团管理系统
【k8s】【docker】web项目的部署
hms学习
【时时三省】(C语言基础)操作符5
云课五分钟-09Linux基础命令实践-AI助力快速入门
typecho文档下的系统使用要求及文件结构说明
Qt中QTimer定时器的用法
【数据结构】时间复杂度与空间复杂度
《算法竞赛进阶指南》 双端队列
- 原文地址:https://blog.csdn.net/xy199931/article/details/128181568