-
awk命令的使用
1、获取根分区剩余大小
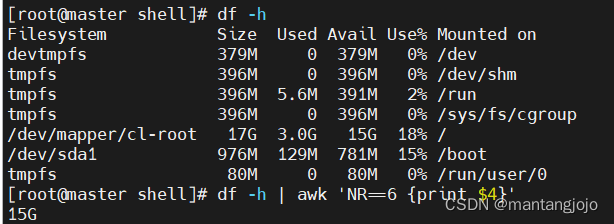
先用df -h命令查看磁盘,确定我们需要获取字段的位置
再使用awk命令获取此字段
- df -h
- df -h | awk 'NR==6 {print $4}'
2、获取当前机器ip地址
ifconfig | awk 'NR==2 {print $2}'
3、统计出apache的access.log中访问量最多的5个IP
使用awk '{print $1}'去除IP地址,再对取出来的IP地址进行排序,统计
awk '{print $1}' access.log | sort -r | uniq -c | head -54、打印/etc/passwd中UID大于500的用户名和uid
需要使用-F来指定分隔符,在awk中默认空格符为空格
awk -F : '$3>500 {print $1,$3}' /etc/passwd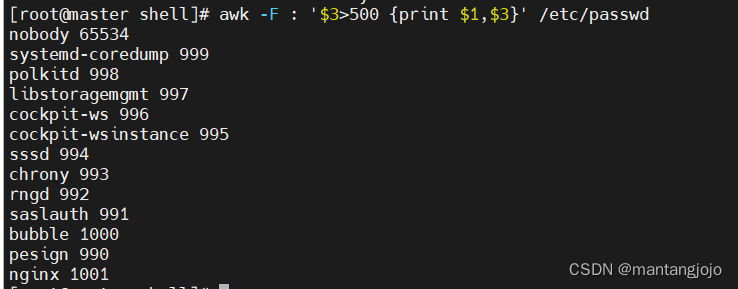
5、/etc/passwd 中匹配包含root或net或ucp的任意行
使用正则表达式对所需要的内容进行匹配
awk '(/root|net|ucp/) {print $0}' /etc/passwd
6、处理以下文件内容将域名取并根据域名进行计数排序处理(百度搜狐面试题)
test.txt
http://www.baidu.com/index.html
http://www.baidu.com/1.html
http://post.baidu.com/index.html
http://mp3.baidu.com/index.htm
http://www.baidu.com/3.html
http://post.baidu.com/2.htmlLinux在统计时只能统计排在一起的相同数据,所以在统计之前我们需要对数据首先进行排序
awk -F / '{print $3}' test.txt | sort | uniq -c
7.一个文件,大概1亿行,每行一个ip,将出现次数最多的top10输出到一个新的文件中
sort -r:降序排序
-n:升序排序
head -n:取文件的前n行,不带n,默认去文件的前10行
(awk '{print $0}' test.txt | sort -r | uniq -c | head) >txt -
相关阅读:
【学习笔记】「JOI Open 2022」长颈鹿
深度学习Tensorflow生产环境部署
AIGC|数字时代巨变,创新潮流涌现,万亿市值风口已开!
X电容和Y电容
Java 命令执行笔记
攻防世界-PWN-new_easypwn
ROS 学习应用篇(六)参数的使用与编程
二叉树基本操作实现 && 树和二叉树&& 二叉树进阶oj && 堆的基本概念 && 优先级队列的使用_
鸡卵清白蛋白修饰黄素单核苷酸(FMN-OVA),Flavin Mononucleotide-Ovalbumin的保存条件
Pod详解
- 原文地址:https://blog.csdn.net/mantangjojo/article/details/128178869