-
人工智能数学基础--概率与统计14:连续随机变量的指数分布、威布尔分布和均匀分布

一、引言
在《人工智能数学基础–概率与统计12:连续随机变量的概率密度函数以及正态分布》介绍了连续随机变量概率分布及概率密度函数以及正态分布,《人工智能数学基础–概率与统计13:连续随机变量的标准正态分布》介绍了标准正态分布,本文将继续介绍几个连续随机变量的分布函数。
二、指数分布
2.1、定义
若随机变量X有概率密度函数: f ( x ) = { 0 当 x ≤ 0 时 λ e − λ x 当 x > 0 时 f(x) = {\Huge \{}{\huge^{λe^{-λx}\;\;\;\;当x>0时}_{0\;\;\;\;\;\;\;\;\;\;\;\;当x≤0时}} f(x)={0当x≤0时λe−λx当x>0时
则称X服从指数分布,其中λ为参数,其值大于0,当x大于0时,-λx为负数,因此该分布也称为负指数分布。对于指数分布来说,当x≤0时,f(x)= 0,表示随机变量取负值的概率为0,故X只取正值,函数f(x)在x=0处不连续。
2.2、指数分布的分布函数
指数分布的分布函数 F ( x ) = ∫ − ∞ x f ( t ) d ( t ) = { 0 当 x ≤ 0 时 1 − e − λ x 当 x > 0 时 F(x)=∫_{-∞}^xf(t)d(t)\\\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;= {\Huge \{}{\Large^{1-e^{-λx}\;\;\;\;当x>0时}_{0\;\;\;\;\;\;\;\;\;\;\;\;当x≤0时}} F(x)=∫−∞xf(t)d(t)={0当x≤0时1−e−λx当x>0时
2.3、指数分布的适用场景及推导
指数分布最常见的一个场景是寿命分布。
设想一种大批生产的电子元件,其寿命X 是随机变量,以F(x)记X的分布函数。证明:在一定的条件下,F(x)就是指数分布的分布函数。
为了证明要进行技术上“无老化”的假定,就是说,“元件在时刻x尚为正常工作的条件下,其失效率总保持为某个常数λ>0,与x无关。失效率就是单位长度时间内失效的概率。用条件概率的形式,上述假定可表达为:
P ( x ≤ X ≤ x + h ∣ X > x ) / h = λ ( h → 0 ) P(x≤X≤x+h|X>x)/h=λ\;\;\;\;\;\;\;\;\;\;\;\;(h→0) P(x≤X≤x+h∣X>x)/h=λ(h→0)
此式解释如下:- 元件在时刻x时尚正常工作,表示其寿命大于x,即X>x;
- 在x处,长为h的时间段内失效,即x≤X≤x+h;
- 把这个条件概率除以时间段的长h,即得在x时刻的平均失效率;
- 令h→0,得瞬时失效率,按假定,它应为常数λ。
按条件概率的定义,注意到P(X>x)=1-F(x),又 { X > x } { x ≤ X ≤ x + h } = { x < X ≤ x + h } \{X>x\}\{x≤X≤x+h\}=\{x
有 P ( x ≤ X ≤ x + h ∣ X > x ) / h = P ( x < X ≤ x + h ) / ( h ( 1 − F ( x ) ) ) = ( F ( x + h ) − F ( x ) ) / h ] / ( 1 − F ( x ) ) → F ′ ( x ) / ( 1 − F ( x ) ) = λ P(x≤X≤x+h|X>x)/h=P(x
这个微分方程的通解为 F ( x ) = 1 − C e − λ x F(x)=1-Ce^{-λx} F(x)=1−Ce−λx(x>0),当x≤0时,F(x)为0。常数C可用初始条件F(0)=0求出为1。老猿注:
- 上面这个推导过程用到了极限的定义、条件概率公式、条件概率定义、分布函数的定义及性质,挺有意思的一个推导过程;
-
F
(
x
)
=
1
−
C
e
−
λ
x
F(x)=1-Ce^{-λx}
F(x)=1−Ce−λx(x>0)是通过微分方程求解得到的,这个过程老猿演示如下:
设F(x)=y,则F ′ (x)/(1−F(x))=λ可以化为dy/(dx(1-y))=λ,则可得:
dy/(1-y)=λdx,对该式两边求积分:∫ dy/(1-y)=∫λdx,则得到:
-ln(1-y)+c1 = λx+c2
∴ln(1-y)=-λx+c3
∴ 1 − y = e − λ x + c 3 = e c 3 e − λ x = C e − λ x 1-y=e^{-λx+c3}=e^{c3}e^{-λx}=Ce^{-λx} 1−y=e−λx+c3=ec3e−λx=Ce−λx
∴y=1- C e − λ x Ce^{-λx} Ce−λx
注意整个推导过程中常数的和差幂运算的结果还是常数,因此有c1、c2、c3和C。
2.4、补充说明
从上面的推导过程可以知道λ的意义就是失效率,失效率越高,平均寿命就越小,因此指数分布描述了无老化时的寿命分布,但实际中“无老化”是不可能的,因而指数分布只是一种近似的寿命分布。对一些寿命长的元件,在初期阶段,老化现象很小,在这一阶段指数分布比较准确相当描述了其寿命分布。
三、威布尔分布
如果将指数分布推导过程中考虑老化的情况,则失效率会随时间上升而上升,故应取为一个x的增函数 λ x m λx^m λxm,其中λ和m都为大于0的常数。在这个条件下,按指数分布的推理,将得出:寿命分布F(x)满足微分方程 F ′ ( x ) / [ 1 − F ( x ) ] = λ x m F'(x)/[1-F(x)]=λx^m F′(x)/[1−F(x)]=λxm
结合F(0)=0,得出: F ( x ) = 1 − e − ( λ / ( m + 1 ) ) x m + 1 F(x) = 1-e^{-(λ/(m+1))x^{m+1}} F(x)=1−e−(λ/(m+1))xm+1
取α = m+1(α>1),并把λ/(m+1)记为λ,得出: F ( x ) = 1 − e − λ x α ( x > 0 ) F(x)=1-e^{-λx^α} \;\;\;\;\;\;\;\;(x>0) F(x)=1−e−λxα(x>0)
而当x≤0时F(x)=0,此时的函数F(x)就称为威布尔分布函数。此分布的密度函数为:
f ( x ) = { 0 当 x ≤ 0 时 λ α x α − 1 e − λ x α 当 x > 0 时 f(x) = {\Huge \{}{\huge^{λαx^{α -1}e^{-λx^α }\;\;\;\;当x>0时}_{0\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;当x≤0时}} f(x)={0当x≤0时λαxα−1e−λxα当x>0时威布尔分布和指数分布一样,在可靠性统计分析中占据重要地位,实际上指数分布是威布尔分布的α=1的特例。
三、均匀分布
3.1、定义
设随机变量X有概率密度函数:
f ( x ) = { 0 其 他 1 b − a 当 a ≤ x ≤ b 时 f(x) = {\Huge \{} ^{{\huge\frac{1}{b-a}}{\large\;\;\;\;\;\;\;\;\;\;\;\;当a≤x≤b时}}_{\large0\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;其他} f(x)={0其他b−a1当a≤x≤b时
则称X服从区间[a,b]上的均匀分布,记为X~R(a,b),这里a、b是常数,满足 -∞均匀分布的分布函数为:
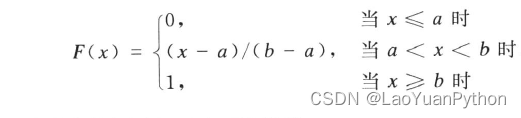
3.2、均匀分布的一种应用
对于一般分布函数F(x),如果X~R(0,1),且F(x)处处连续严格单调递增,其反函数G存在,且G(x) ~ F。
证明:
∵{G(X)≤x}
∴{F(G(X))≤F(x)}
∴{X≤F(x)}
∵X ~ R(0,1)
∴R(0,1)的分布函数为F(x)=x(0
∴G(X) ~ F因此可以利用均匀分布实现对满足上述条件的一般分布F的模拟。
四、小结
本文是老猿学习中国科学技术大学出版社出版的陈希孺老先生的《概率论与数理统计》的总结和思考,在文中介绍了指数分布、威布尔分布和均匀分布的概念,以及其中一些推导过程,在文中根据老猿自己的理解补充说明了一些推导过程。
更多人工智能数学基础请参考专栏《人工智能数学基础》。
写博不易,敬请支持:
如果阅读本文于您有所获,敬请点赞、评论、收藏,谢谢大家的支持!
关于老猿的付费专栏
- 付费专栏《https://blog.csdn.net/laoyuanpython/category_9607725.html 使用PyQt开发图形界面Python应用》专门介绍基于Python的PyQt图形界面开发基础教程,对应文章目录为《 https://blog.csdn.net/LaoYuanPython/article/details/107580932 使用PyQt开发图形界面Python应用专栏目录》;
- 付费专栏《https://blog.csdn.net/laoyuanpython/category_10232926.html moviepy音视频开发专栏 )详细介绍moviepy音视频剪辑合成处理的类相关方法及使用相关方法进行相关剪辑合成场景的处理,对应文章目录为《https://blog.csdn.net/LaoYuanPython/article/details/107574583 moviepy音视频开发专栏文章目录》;
- 付费专栏《https://blog.csdn.net/laoyuanpython/category_10581071.html OpenCV-Python初学者疑难问题集》为《https://blog.csdn.net/laoyuanpython/category_9979286.html OpenCV-Python图形图像处理 》的伴生专栏,是笔者对OpenCV-Python图形图像处理学习中遇到的一些问题个人感悟的整合,相关资料基本上都是老猿反复研究的成果,有助于OpenCV-Python初学者比较深入地理解OpenCV,对应文章目录为《https://blog.csdn.net/LaoYuanPython/article/details/109713407 OpenCV-Python初学者疑难问题集专栏目录 》
- 付费专栏《https://blog.csdn.net/laoyuanpython/category_10762553.html Python爬虫入门 》站在一个互联网前端开发小白的角度介绍爬虫开发应知应会内容,包括爬虫入门的基础知识,以及爬取CSDN文章信息、博主信息、给文章点赞、评论等实战内容。
前两个专栏都适合有一定Python基础但无相关知识的小白读者学习,第三个专栏请大家结合《https://blog.csdn.net/laoyuanpython/category_9979286.html OpenCV-Python图形图像处理 》的学习使用。
对于缺乏Python基础的同仁,可以通过老猿的免费专栏《https://blog.csdn.net/laoyuanpython/category_9831699.html 专栏:Python基础教程目录)从零开始学习Python。
如果有兴趣也愿意支持老猿的读者,欢迎购买付费专栏。
老猿Python,跟老猿学Python!
☞ ░ 前往老猿Python博文目录 https://blog.csdn.net/LaoYuanPython ░
-
相关阅读:
Kafka消费者重平衡
Elasticsearch-06-Elasticsearch Java API Client
非零基础自学Java (老师:韩顺平) 第12章 异常 - Exception
媒体查询?
一行shell实现tree
Python 潮流周刊#39:Rust 开发的性能超快的打包工具
基于卷积神经网络的分类算法
MySQL的缓冲池(buffer pool)及 LRU算法
VR全景对行业发展有什么帮助?VR全景制作需要注意什么?
Linux服务器配置与管理(基于Centos7.2)任务目标(五)
- 原文地址:https://blog.csdn.net/LaoYuanPython/article/details/128142832