-
ResNet网络的改进版:ResNeXt
之前的文章讲过ResNet网络的基本架构,其本质就是让网络的学习目的从学习 转为学习 ,也就是学习输入和输出之间的残差信息,从而缓解了梯度消失和网络退化问题。
本文讲下ResNet网络的改进版:ResNeXt。
架构
下面是ResNet和ResNeXt的架构对比:
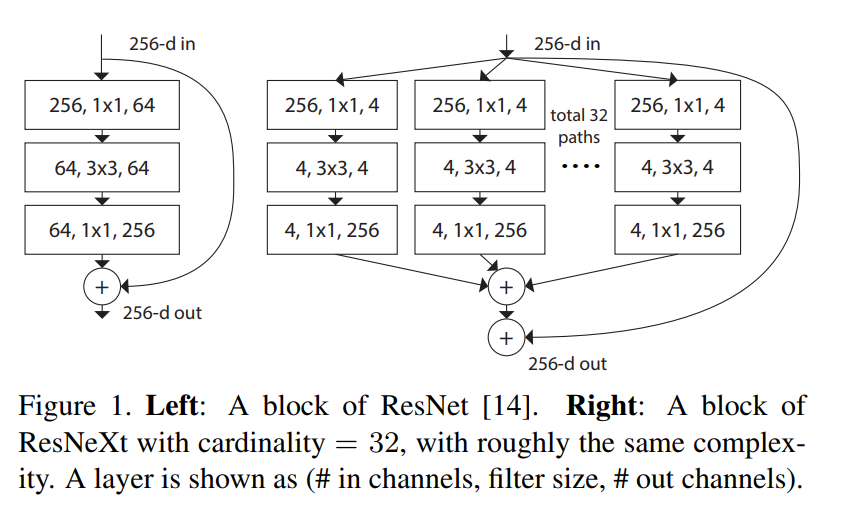
引用自参考1 从上图中便可以看到ResNeXt的核心:用了类似于Inception的思想,把残差块的一条路径变成多条路径。
如果看原文也可以发现,其实作者最主要的对标就是Inception的模块。在Inception中,作者设计了4个不同的路径来从数据中提取信息,然后在输出的通道维进行合并,但是其弊端是这种拓扑结构(卷积核的个数和大小)需要精心设计才能够取得理想的效果,更增加了深度学习的黑箱特性。
在ResNeXt中,作者沿用了VGG和ResNet的两个主流思想:
-
层数堆叠 -
split-transform-merge思想(就是分割-转换-合并,对于于上图)
但是在进行transform的时候,ResNeXt对于每一个路径的转换都是相同的,比如每条路径的输入和输出通道、卷积核大小都是相同的,这样子就避免了像Inception那样还要花费心思来设计路径数量,本文作者直接把这个通道数量设计成了一个参数,叫做cardinality。
如果与ResNet对比,则如下图所示:
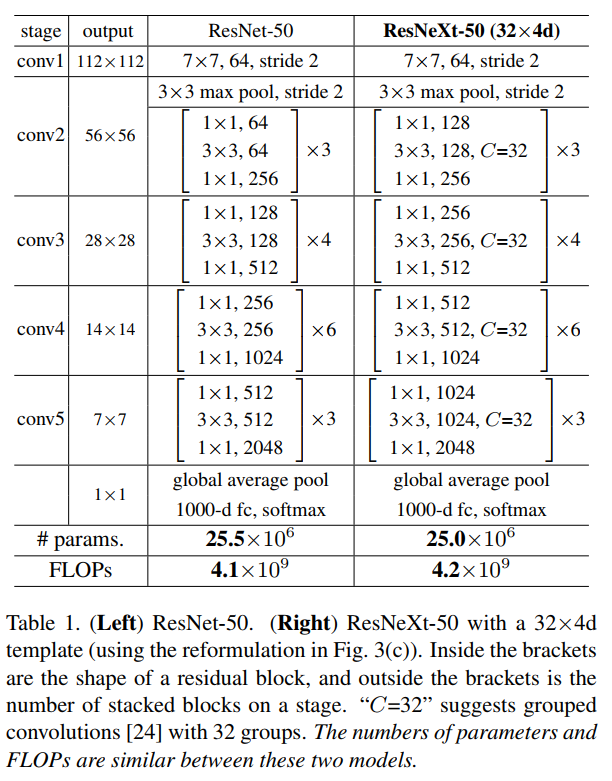
参考1 值得注意的是,作者在原文中说道,增加cardinality比增加深度和宽度更有效!
代码
有了架构图,代码按照搭积木原则来写就行,这里直接放上公布的代码(具体的可以看参考链接2):
import torch.nn as nn
import math
__all__ = ['ResNeXt', 'resnext18', 'resnext34', 'resnext50', 'resnext101',
'resnext152']
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, num_group=32):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes*2, stride)
self.bn1 = nn.BatchNorm2d(planes*2)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes*2, planes*2, groups=num_group)
self.bn2 = nn.BatchNorm2d(planes*2)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, num_group=32):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes*2, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes*2)
self.conv2 = nn.Conv2d(planes*2, planes*2, kernel_size=3, stride=stride,
padding=1, bias=False, groups=num_group)
self.bn2 = nn.BatchNorm2d(planes*2)
self.conv3 = nn.Conv2d(planes*2, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNeXt(nn.Module):
def __init__(self, block, layers, num_classes=1000, num_group=32):
self.inplanes = 64
super(ResNeXt, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0], num_group)
self.layer2 = self._make_layer(block, 128, layers[1], num_group, stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], num_group, stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], num_group, stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, num_group, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, num_group=num_group))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, num_group=num_group))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def resnext18( **kwargs):
"""Constructs a ResNeXt-18 model.
"""
model = ResNeXt(BasicBlock, [2, 2, 2, 2], **kwargs)
return model- 1
知识点速记
结合ResNet和Inception的思想,ResNeXt把每个模块的路径数设置为一个超参数,称为cardinality。
另外要注意,下面这三种方式是严格等价的:

参考
【1】XIE S, GIRSHICK R, DOLLáR P, et al. Aggregated residual transformations for deep neural networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.2017:1492-1500.
【2】https://github.com/miraclewkf/ResNeXt-PyTorch本文由 mdnice 多平台发布
-
-
相关阅读:
代码坏味道与重构之过长参数列表
数据结构-求关键路径和关键活动
(入门以及简介+实战)超参数寻找器hyperopt库中常见的函数或类的作用
人力资源从业者如何提升自己的能力?很实用
访问者模式 行为型设计模式之九
咖啡技术培训:传统意式咖啡菜单制作配方及流程
上线后出现问题,被自己坑了...
竞赛 题目:基于深度学习的人脸表情识别 - 卷积神经网络 竞赛项目 代码
1023 组个最小数(满分)
tuxera ntfs2024破解版mac电脑磁盘读写软件
- 原文地址:https://blog.csdn.net/qq_41387508/article/details/128169725
