-
机器学习与数据挖掘——前言
如果有兴趣了解更多相关内容,欢迎来我的个人网站看看:瞳孔空间
这是从老师的PPT里面提取出来的,知识点分布比较零散,可能他做PPT的时候也没想那么多。
一:机器学习
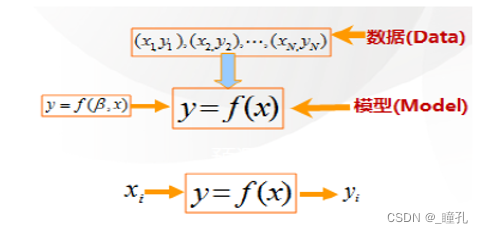
机器学习的定义:一个计算机程序被称为可以学习,是指它能够针对某个任务T和某个性能指标P,从经验E中学习。这种学习的特点是,它在T上的被P所衡量的性能,会随着经验E的增加而提高。
机器学习致力于研究如何通过计算的手段,利用经验来改善系统自身的性能,从而在计算机上从数据中产生“模型”,用于对新的情况给出判断。
机器学习是一门多学科交叉专业,涵盖概率论知识、统计学知识、近似理论知识和复杂算法知识。机器学习推动人工智能快速发展,是第三次人工智能发展浪潮的重要推动因素。
典型的机器学习过程:
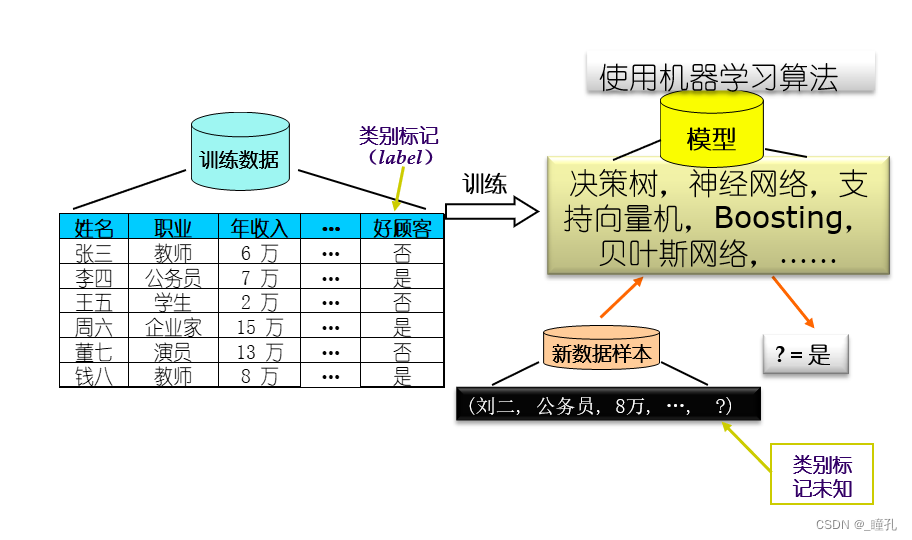
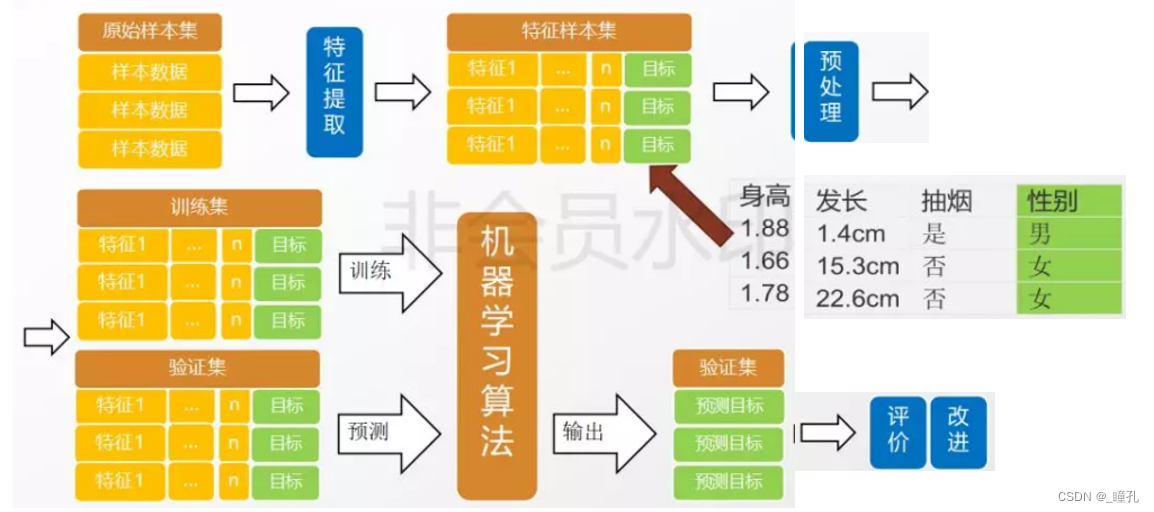
实施过程:
机器学习领域诞生了众多的经典理论:PAC学习理论、决策树、支持向量机SVM、Adaboost、循环神经网络RNN和LSTM、流形学习、随机森林Random Forest等,并走向实用。

经典的机器学习算法:
- 上世纪50年代的图灵测试与塞缪尔开发的西洋跳棋程序
- 上世纪60年代中到70年代末的发展几乎停滞
- 上世纪80年代使用神经网络反向传播(BP)算法
- 昆兰在1986年提出的“决策树”(ID3算法)
- 上世纪90年代支持向量机(SVM)算法(1964年已被提出)
- 2006年辛顿(Hinton)提出深度学习(Deep Learning)
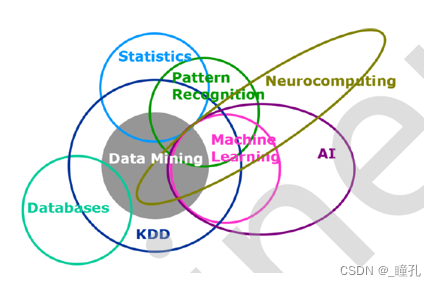
机器学习相关概念的辨识:
- 数据挖掘:Data Mining,简称DM
- 知识发现:Knowledge Discovery in Database, 简称KDD
- 模式识别:Pattern Recognition,简称PR
- 统计:Statistics
- 神经计算:Neuro Computing
- 数据库:Databases
机器学习算法分类:
- 监督学习(Supervised Learning)
- 无监督学习(Unsupervised Learning)
- 半监督学习(Semi-Supervised Learning)
- 自监督学习(Self-Supervised Learning)
监督学习
- 监督学习中的数据集是有标签的,对于给出的样本是有答案的,这类机器学习称为监督学习
- 根据标签类型的不同,监督学习分为分类问题和回归问题两类:
- 分类是预测某一样东西所属的类别(离散的),比如给定一个人的身高、年龄、体重等信息,然后判断性别、是否健康等
- 回归则是预测某一样本所对应的实数输出(连续的),比如预测某一地区人的平均身高
- 大部分模型都是属于监督学习,包括线性分类器、支持向量机等。常见的监督学习算法有:k-近邻算法(k-Nearest Neighbors,KNN)、决策树(Decision Trees)、朴素贝叶斯(Naive Bayesian),支持向量机(SVM)等
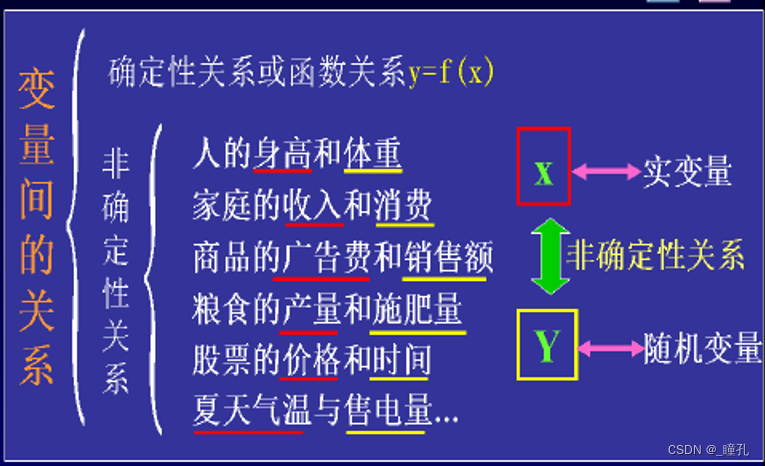
回归的定义:假定同一个或多个独立变量存在相关关系,寻找相关关系的模型。不同于时间序列法的是:模型的因变量是随机变量,而自变量是可控变量。分为线性回归和非线性回归,通常指连续要素之间的模型关系,是因果关系分析的基础。(回归研究的是数据之间的非确定性关系)
线性回归算法寻找属性与预测目标之间的线性关系。通过属性选择与去掉相关性,去掉与问题无关的变量或存在线性相关性的变量。
在建立回归模型之前,可先进行主成分分析,消除属性之间的相关性。最后通过最小二乘法,算法得到各属性与目标之间的线性系数。
分类与聚类:
- 分类:类别是已知的,通过对已知分类的数据进行训练和学习,找到这些不同类的特征,再对未分类的数据进行分类。属于监督学习
- 聚类:事先不知道数据会分为几类,通过聚类分析将数据聚合成几个群体。聚类不需要对数据进行训练和学习。属于无监督学习
二:数据挖掘
数据挖掘可以视为机器学习和数据库的交叉,它主要利用机器学习界提供的技术来分析海量数据,利用数据库界提供的技术来管理海量数据。
- 数据库知识发现(Knowledge Discovery in Databases,KDD)
- 数据挖掘(Data Mining DM)
- 数据分析(Data Analysis)
- 数据融合(Data Fusion)
- 决策支持(Decision Supporting)
知识发现的定义:Fayyad,Piatetsky-Shapiro和Smyth在KDD96国际会议的会议论文《From Data Mining to Knowledge Discovery》一文中将KDD定义为:从大量数据中获取有效的、新颖的、有潜在作用的和最终可理解的模式的非平凡过程。
数据挖掘(Date Mining)是从大型数据库或数据仓库中提取人们感兴趣的知识,这些知识是隐含的、事先未知的、潜在的有用的信息。广泛观点的定义:是从存放在数据库、数据仓库或其他信息库中的大量数据中挖掘有趣的知识过程。
数据分析方法:
- 关联分析(Association):如经典的啤酒与尿布案例
- 市场组合分析
- 套装产品分析
- 目录设计
- 交叉销售
- 聚类分析(Clustering)
- 客户细分
- 市场细分
- 神经网络(Neural Networks)
- 倾向性分析
- 客户保留
- 目标市场
- 欺诈检测
三:数据及数据类型
3.1:数据的基本概念
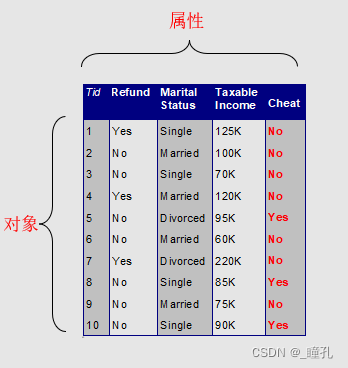
数据的属性:是对象的性质或特性
- 属性也称为变量、字段、特性、特征或维
- 如:眼球颜色、物体的温度等
对象(object)、样本(sample):用一组属性描述,对象也称为记录、点、向量、案例、样本、实体或事件
数据(Data) = 数据对象及其属性的集合
离散属性(Discrete Attribute):
- 具有有限或无限可数个值,例如:邮政编码、计数
- 通常用整数变量表示(注:二元属性是离散属性的一种特殊情况)
连续属性(Continuous Attribute):
- 是取实数值的属性,例如:温度、高度或重量
- 实践中,实数值只能用有限的精度测量和表示
- 通常,连续属性用浮点变量表示
3.2:数据集的类型
3.2.1:记录数据
记录数据(Record Data):数据是记录的汇集,每个记录包含固定的数据字段(属性)集
- 数据矩阵
- 文档数据
- 事务数据
记录数据——数据矩阵(Data Matrix):
- 如果一个数据集中的所有数据对象都具有相同的数值属性集,则数据对象可看作多维空间中的点,其中每个维代表描述对象的一个不同属性
- 数据对象集可用一个m*n的矩阵表示
- m表示对象行数,一个对象一行
- n表示属性列,一个属性一列

记录数据——文档数据(Text Data)
- 每个文档表示为一个向量
- 文档中的每个单词表示为向量的一个分量(属性)
- 每个分量的值是对应词在文档中出现的次数
- 每个单词表示为一个向量
- 向量中的每个分量无物理意义
- 一个文档表示为一个矩阵


记录数据——事务数据(Transaction Data):是一种特殊的记录数据
- 每个记录(事务)涉及一个项的集合
- 例如,一个杂货店。顾客一次购物所购买的商品的集合就构成一个事务,而购买的商品是项

3.2.2:基于图形的数据
基于图形的数据(Graphic Data)
- 万维网
- 分子结构
基于图形的数据——万维网:例如类图和HTML链接

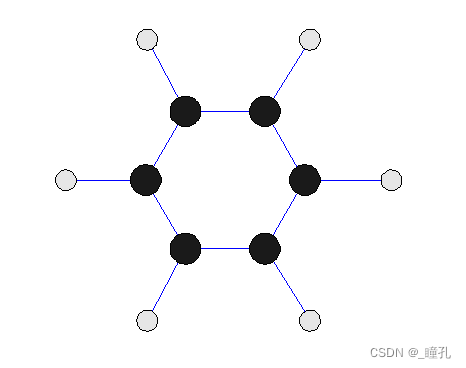
基于图形的数据——分子结构:例如苯分子(C6H6):
3.2.3:有序数据
有序数据(Sequence Data)
- 空间数据
- 时间数据
- 时序数据
- 基因序列数据
有序数据——事务序列:

有序数据——基因序列数据:

有序数据——地理时空数据:

3.3:数据集的特点
- 维度(dimensionality):超高维
- 交易数据、Web文档、基因表达数据、文档词频数据、用户评分数据、WEB使用数据及多媒体数据等
- 稀疏性(sparsity)
- 分辨率(resolution)
- 粒度(granularity),层次的问题
-
相关阅读:
【Linux内核系列】进程调度
Bark Ai 文本转语音 模型缓存位置修改
【Rust 日报】2022-08-04 异步Rust的实践:性能、隐患、分析
Dubbo架构篇 - 服务路由
Android Framework中的addView和addWindow
Ubuntu(Linux)的基本操作
GLSL加载图片的流程
阿木实验室PrometheusV1.1安装+Ubuntu 20.04
Linux系统的安装
java-net-php-python-jsp小家蔬菜展示平台计算机毕业设计程序
- 原文地址:https://blog.csdn.net/tongkongyu/article/details/128037175