-
2022 CMU15-445 Project 1 Buffer Pool
通过截图

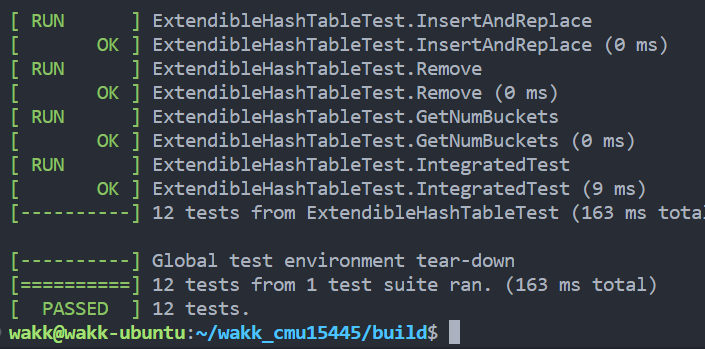
Task #1 - Extendible Hash Table
该 task 的知识点名为 可扩展动态散列
https://cloud.tencent.com/developer/article/1020586
这个部分要实现一个extendible哈希表,内部不可以用built-in的哈希表,比如unordered_map。这个哈希表在Buffer Pool Manager中主要用来存储 buffer pool 中 page id 和 frame id 的映射关系。
这里的算法我在课上没听懂太多,感觉给的图不是特别清晰,项目中给的IndexOf函数,是根据低位来进行判断。须知
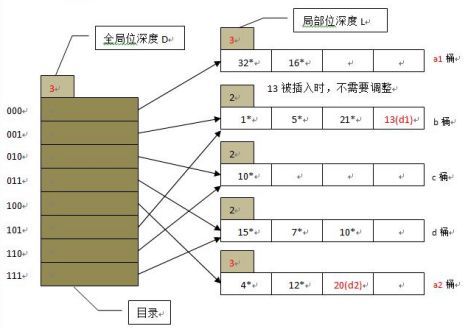
要完成这个 task 首先要明确 可拓展散列 的概念,其中有 几 个关键名词,目录,桶,全局位深度和局部位深度,
- 首先是目录,目录就是存放着桶指针的表,和一些元信息,可以看作为中控台。
- 桶,就是用来存放数据的。
- 全局位深度,这里写作 G ,可以看作目录中最多有 2 的 G 次方个桶。
- 局部位深度,这里写作 L ,是桶特有的,每个桶独自保存一个 L,这代表该桶中元素的 key 的哈希值的后 L 位是相等的,后面主要用于桶的分裂,这里没有概念很正常。
这里就讲一个该 task 中最难实现的方法,插入:
- 首先,初始深度为0,你哈希后取 index 只能为0
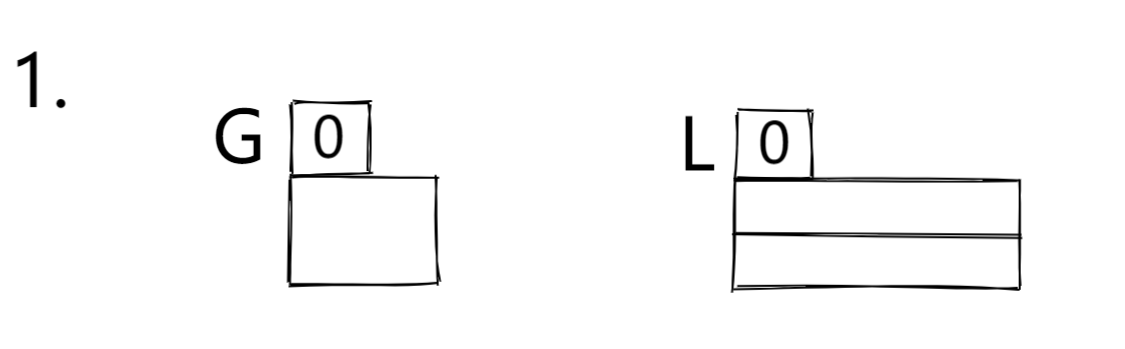
- 接着插入 2 个,桶的大小在项目中是有规定的,故这里取2来讲。
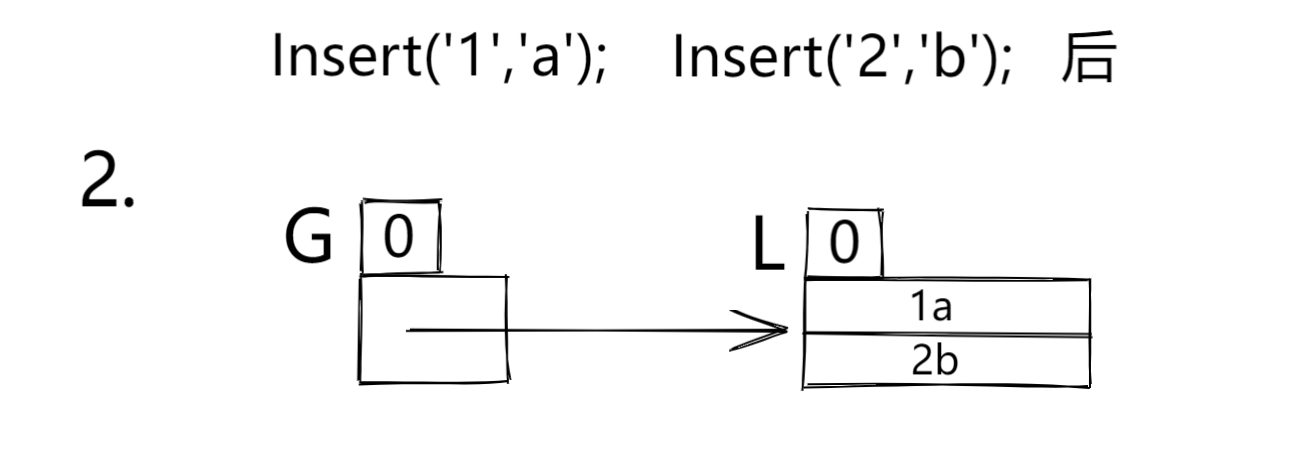
- 再插入第三个时,桶满了,此时 L == G,则采用这种策略
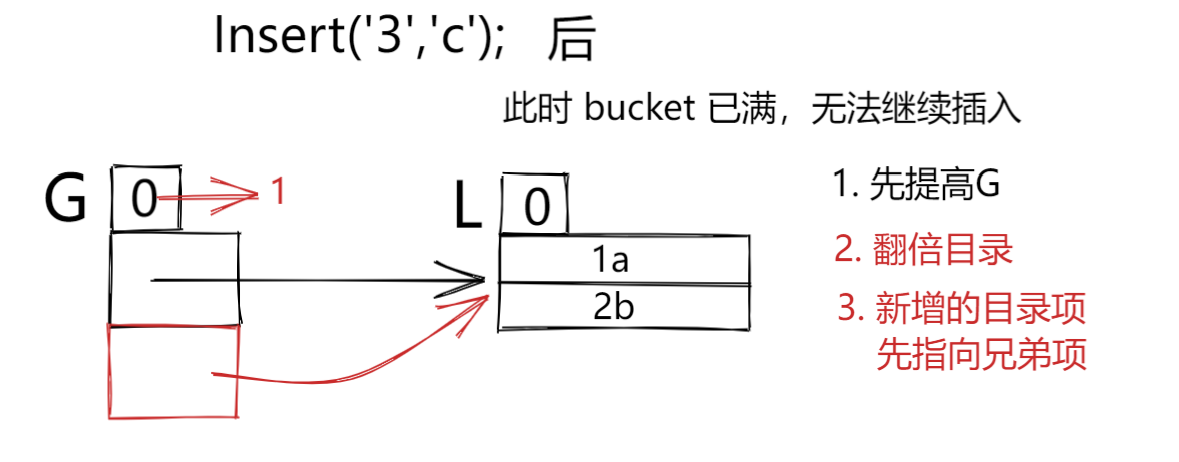
这里解释一下兄弟项,其实就是目录翻倍后,多出来的一倍,和原来的一倍按顺序一一对应即可,至于原理则是,翻倍后,这2部分的索引的二进制表达的第 G 位,分别为 1 ,0.(下图中便有)
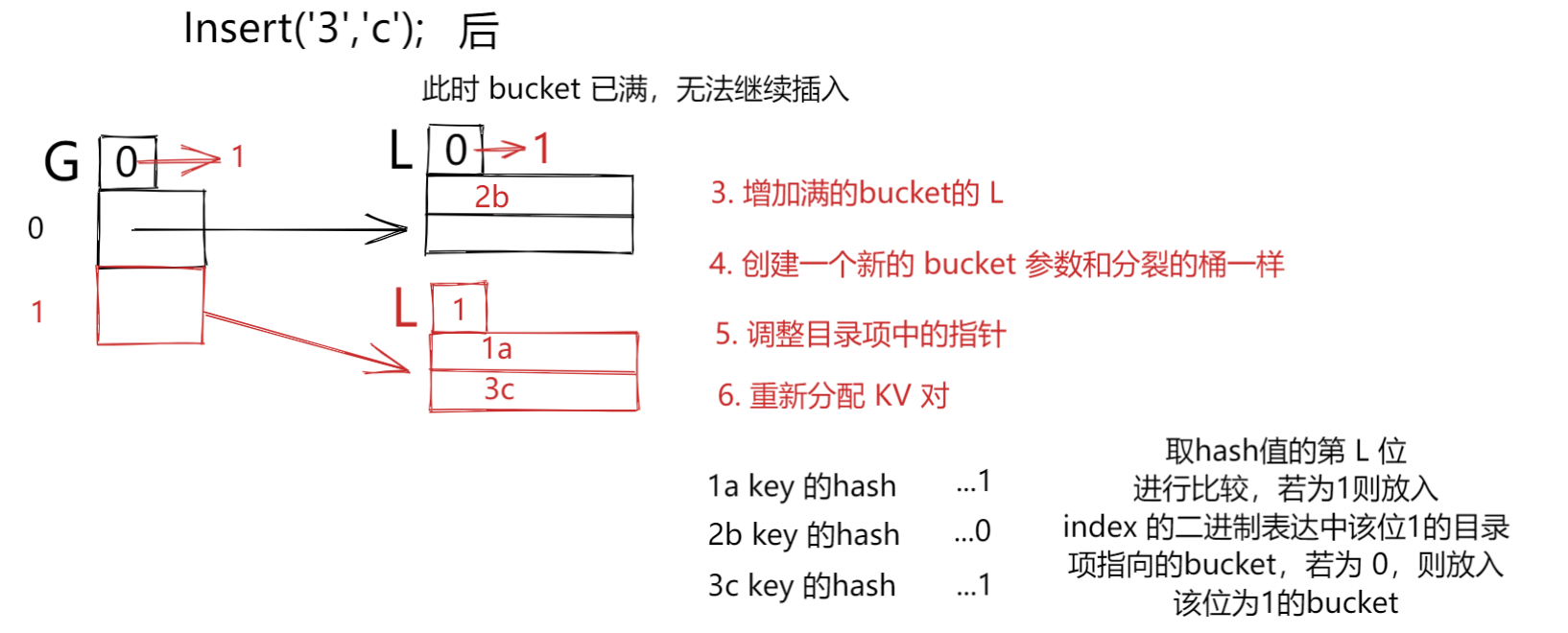
- 之后若有情况如,L < G 的 如下图中b桶如果要接着插入:
则说明存在指向相同的桶,此时不需要更新 G,只需要更新 L 并将兄弟项指向的桶进行新建,再进行 kv 重排列便可代码
void ExtendibleHashTable<K, V>::Insert(const K &key, const V &value) { std::scoped_lock<std::mutex> lock(latch_); // 先保存着 ,待会随着深度变化,再次调用结果可能会不一致 auto index = IndexOf(key); auto bucket = dir_[index]; // 有剩余空间则直接插入 if (bucket->Insert(key, value)) { // 这里是唯一正确的出口 return; } // 开始重整 // 若局部深度等于全局深度,则更新全局深度与目录容量 if (bucket->GetDepth() == GetGlobalDepthInternal()) { size_t len = dir_.size(); dir_.reserve(2 * len); std::copy_n(dir_.begin(), len, std::back_inserter(dir_)); global_depth_++; } // 莫名其妙到这里 item 失效了 原来是 vec 的自动扩容,导致本来的地址不能用了要重新获取 bucket, index // 也会变,要用之前的 bucket = dir_[index]; // 若局部深度小于全局深度,则更新局部深度并拿个新 Bucket 用 if (bucket->GetDepth() < GetGlobalDepthInternal()) { // 开始分裂 auto bucket0 = std::make_shared<Bucket>(bucket_size_, bucket->GetDepth() + 1); auto bucket1 = std::make_shared<Bucket>(bucket_size_, bucket->GetDepth() + 1); num_buckets_++; // 点睛之笔 比如 当前深度为 1,你不可能 把 1 左移 1位去判别兄弟节点,你应该把有效位的最后一位拿来 int mask = 1 << bucket->GetDepth(); for (auto &[k, v] : bucket->GetItems()) { size_t hashkey = std::hash<K>()(k); // 根据本地深度表示的有效位最后一位判别,若为 1,插入新建的那个bucket if ((hashkey & mask) != 0) { bucket1->Insert(k, v); } else { // 根据本地深度表示的有效位最后一位判别,若为 0,插入原有的 bucket bucket0->Insert(k, v); } } // 减少不必要的遍历,从前一位的大小开始,若是 0 则从 0 开始 ,若是 1 ,则可以节省很多,兄弟节点这一位肯定是一样的 for (size_t i = index & mask - 1; i < dir_.size(); i += mask) { // 根据本地深度表示的有效位最后一位判别,若为 1,取代新建的那个bucket if ((i & mask) != 0) { dir_[i] = bucket1; } else { // 根据本地深度表示的有效位最后一位判别,若为 0,取代原有的 bucket dir_[i] = bucket0; } } latch_.unlock(); // 递归插入本来要插入的值 Insert(key, value); latch_.lock(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
这里讲我卡很久的一个点
Insert的时候先找是否已存在 若存在直接覆盖值就好了 就是因为顺序错了导致线上测试才没过
Task #2 - LRU-K Replacement Policy
该 task 的知识点名为 LRU-K算法
https://blog.csdn.net/love254443233/article/details/82598381
这个部分要实现一个LRU-K替换器,比刚刚简单多了,看懂了上面文章,另外再替换策略上加一层:先排除用的最少的缓存,缓存一样便排除最久未使用的缓存,这里意味着可能要用时间戳。测试后发现只要移动队列中元素位置便可,无需时间戳。历史队列和缓存队列我都采取了list结构进行实现,因为好进行二次排序,再使用 hashmap 来进行 o(1) 的查找。
以下展示部分代码:void LRUKReplacer::RecordAccess(frame_id_t frame_id) { std::lock_guard<std::mutex> lock_guard(latch_); BUSTUB_ASSERT((size_t)frame_id <= replacer_size_, true); size_t new_times = ++map_[frame_id].times_; // 新元素 if (new_times == 1) { // std::cout << "插入frame " << frame_id << " count: " << map_[frame_id].times_ << std::endl; history_list_.emplace_front(frame_id); map_[frame_id].pos_ = history_list_.begin(); } else { if (new_times == k_) { history_list_.erase(map_[frame_id].pos_); cach_list_.emplace_front(frame_id); // 更新索引 map_[frame_id].pos_ = cach_list_.begin(); } else if (new_times > k_) { // 已在缓存队列,更新位置 cach_list_.erase(map_[frame_id].pos_); cach_list_.emplace_front(frame_id); // 更新索引 map_[frame_id].pos_ = cach_list_.begin(); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
这里也讲一个卡了我很久的点
RecordAccess时达到k_ 次,放入缓存队列 ,记住若小于 k_ 次,访问不会改变位置,按第一次来,因为这个所以才通不过在线测试,且缓存的evictable_应该初始化为false, 否则影响测评
Task #3 - Buffer Pool Manager Instance
该 task 的知识点名为 Buffer Pool Manager
该 task 概念比较容易,就讲一下我卡住的几个点- 当你实现
FetchPgImp时,记住,若返回已经存在的frame中page时,也要记得将 将Evictable设置为false UnpinPgImp中关于修改is_dirty部分,只能从 false -> true 修改,true->false 只能写回后才能修改FlushPgImp函数不需要管is_dirty直接写回,然后更新信息- 当你进入一个函数时,一定要做完所有工作再交出锁,否则你永远不知道抢到该锁的是不是你想交给的那个函数。
以下展示部分代码:
// 该函数 NewPgImp 和 FetchPgImp 都用得到 auto BufferPoolManagerInstance::GetFrame(frame_id_t *frame_id) -> bool { frame_id_t fid; if (!free_list_.empty()) { fid = free_list_.front(); free_list_.pop_front(); *frame_id = fid; return true; } if (replacer_->Evict(&fid)) { // std::cout << "Evict page: " << pages_[fid].GetPageId()<< std::endl; if (pages_[fid].IsDirty()) { disk_manager_->WritePage(pages_[fid].GetPageId(), pages_[fid].GetData()); pages_[fid].is_dirty_ = false; } page_table_->Remove(pages_[fid].GetPageId()); *frame_id = fid; pages_[fid].pin_count_ = 0; pages_[fid].ResetMemory(); return true; } return false; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
-
相关阅读:
Leetcode-1106. 解析布尔表达式
ssm生鲜超市管理系统的设计与实现毕业设计源码261635
在vscode如何利用快捷键选择一样的单词
热门Java开发工具IDEA入门指南——如何安装IntelliJ IDEA(下)
七、文件包含漏洞
鲸探发布点评:9月19日发售《中国大飞机C919》数字藏品
如何在macOS上安装Go并搭建本地编程环境
iOS 关于UIDatePicker、UIPickerView常见使用方法
设计数据密集型应用的主要关注点
痞子衡嵌入式:恩智浦i.MX RT1xxx系列MCU硬件那些事(2.3)- 串行NOR Flash下载算法(J-Link工具篇)
- 原文地址:https://blog.csdn.net/q2453303961/article/details/128153709
