-
RabbitMQ之集群方案原理
对于无状态应用(如普通的微服务)很容易实现负载均衡、高可用集群。而对于有状态的系统(如数据库等)就比较复杂。
1、业界实践
- 主备模式:单活,容量对等,可以实现故障转移。使用独立存储时需要借助复制、镜像同步等技术,数据会有延迟、不一致等问题(CAP定律),使用共享存储时就不会有状态同步这个问题。
- 主从模式:一定程度的双活,容量对等,最常见的是读写分离。通常也需要借助复制技术,或者要求上游实现双写来保证节点数据一致。
- 主主模式:两边都可以读写,互为主备。如果两边同时写入很容易冲突,所以通常实现的都是“伪主主模式”,或者说就是主从模式的升级版,只是新增了主从节点的选举和切换。
- 分片集群:不同节点保存不同的数据,上游应用或者代理节点做路由,突破存储容量限制,分摊读写负载;典型的如MongoDB的分片、MySQL的分库分表、Redis集群。
- 异地多活:“两地三中心”是金融行业经典的容灾模式(有资源闲置的问题),“异地多活”才是王道。
2、常用负载均衡算法:
- 随机
- 轮询
- 加权轮询
- 最少活跃连接
- 原地址/目标地址hash(一致性hash)
3、集群中的经典问题:
脑裂(可以通过协调器选举算法、仲裁节点等方式来解决)
网络分区、一致性、可用性(CAP)
相关技术和工具:LVS、HAProxy、Nginx、KeepAlived、Heartbeat、DRBD、Corosync、Pacemaker、MMM/MHA、Galera、MGR等,感兴趣的同学可以研究。
现在太多公司选择直接购买公有云服务,基本不用太关心很多基础设施和中间件的部署、运维细节。但是这些技术以及背后的原理是非常重要的。
4、RabbitMQ分布式架构模式
主备模式
也叫Warren(兔子窝)模式,同一时刻只有一个节点在工作(备份节点不能读写),当主节点发生故障后会将请求切换到备份节点上(主恢复后成为备份节点)。需要借助HAProxy之类的(VIP模式)负载均衡器来做健康检查和主备切换,底层需要借助共享存储(如SAN设备)。
这不是RabbitMQ官方或者开源社区推荐方案,适用于访问压力不是特别大但是又有高可用架构需求(故障切换)的中小规模的系统来使用。首先有一个节点闲置,本身就是资源浪费,其次共享存储往往需要借助硬件存储,或者分布式文件系统。

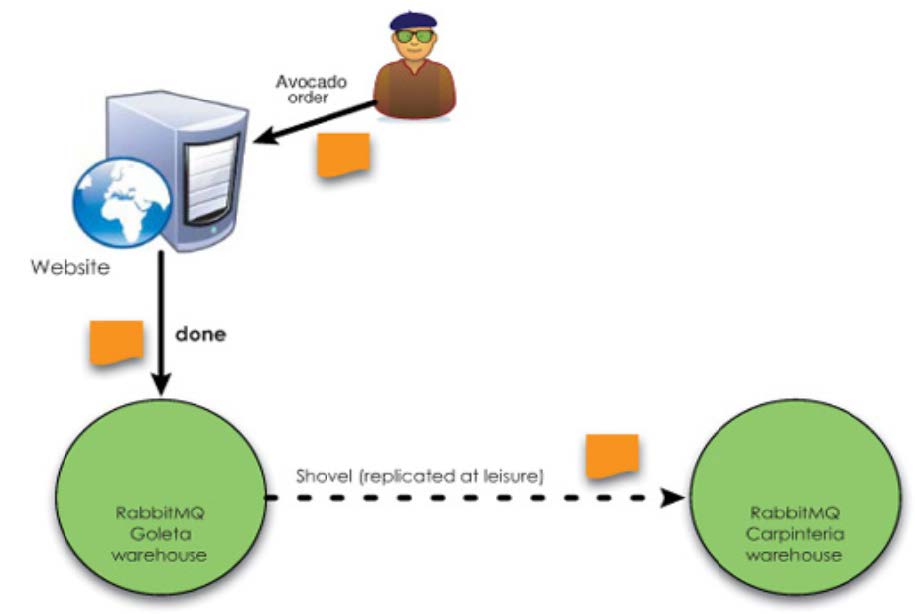
Shovel铲子模式
Shovel是一个插件,用于实现跨机房数据复制,或者数据迁移,故障转移与恢复等。
如下图,用户下单的消费先是投递在Goleta Broker实例中,当Goleta实例达到触发条件后(例如:消息堆积数达到阈值)会将消息放到Goleta实例的backup_orders备份队列中,并通过Shovel插件从Goleta的backup_orders队列中将消息拉取到Carpinteria实例存储。
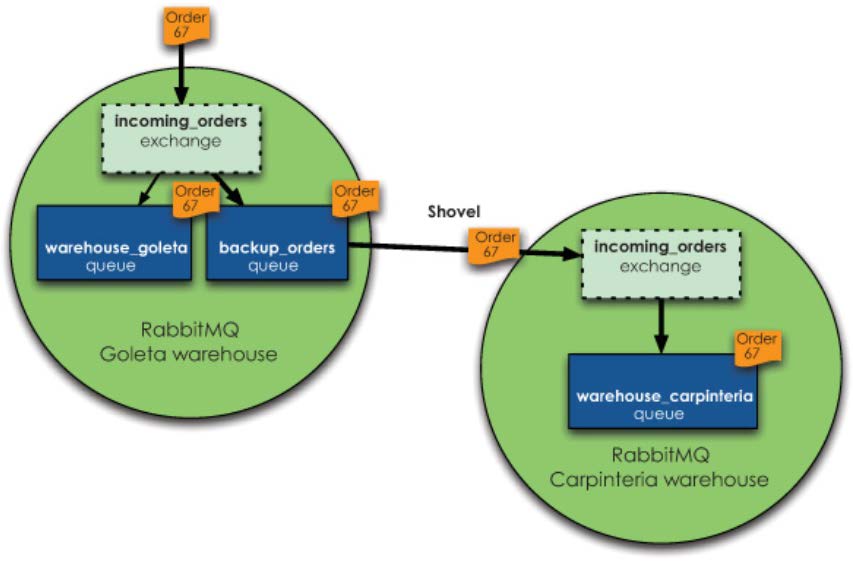
- 使用Shovel插件后,模型变成了近端同步确认,远端异步确认的方式。
- 此模式支持WAN传输,并且broker实例的RabbitMQ、Erlang版本不要求完全一致。
- Shovel的配置分静态模式(修改RabbitMQ配置)和动态模式(在控制台直接部署,重启后失效)
RabbitMQ集群
RabbitMQ集群允许消费者和生产者在RabbitMQ单个节点崩溃的情况下继续运行,并可以通过添加更多的节点来线性扩展消息通信的吞吐量。当失去一个RabbitMQ节点时,客户端能够重新连接到集群中的任何其他节点并继续生产和消费。
RabbitMQ集群中的所有节点都会备份所有的元数据信息,包括:
- 队列元数据:队列的名称及属性;
- 交换器:交换器的名称及属性;
- 绑定关系元数据:交换器与队列或者交换器与交换器之间的绑定关系;
- vhost元数据:为vhost内的队列、交换器和绑定提供命名空间及安全属性。
基于存储空间和性能的考虑,RabbitMQ集群中的各节点存储的消息是不同的(有点儿类似分片集群,各节点数据并不是全量对等的),各节点之间同步备份的仅仅是上述元数据以及Queue Owner(队列所有者,就是实际创建Queue并保存消息数据的节点)的指针。当集群中某个节点崩溃后,该节点的队列进程和关联的绑定都会消失,关联的消费者也会丢失订阅信息,节点恢复后(前提是消息有持久化)消息可以重新被消费。虽然消息本身也会持久化,但如果节点磁盘存储设备发生故障那同样会导致消息丢失。
总的来说,该集群模式只能保证集群中的某个Node挂掉后应用程序还可以切换到其他Node上继续地发送和消费消息,但并无法保证原有的消息不丢失,所以并不是一个真正意义的高可用集群。

这是RabbitMQ内置的集群模式,Erlang语言天生具备分布式特性,所以不需要借助类似Zookeeper之类的组件来实现集群(集群节点间使用cookie来进行通信验证,所有节点都必须使用相同的.erlang.cookie 文件内容),不同节点的Erlang、RabbitMQ版本必须一致。
镜像队列模式
前面我们讲了,RabbitMQ内置的集群模式有丢失消息的风险,“镜像队列”可以看成是对内置默认集群模式的一种高可用架构的补充。可以将队列镜像(同步)到集群中的其他broker上,相当于是多副本冗余。如果集群中的一个节点失效,队列能自动地切换到集群中的另一个镜像节点上以保证服务的可用性,而且消息不丢失。
在RabbitMQ镜像队列中所谓的master和slave都仅仅是针对某个queue而言的,而不是node。一个queue第一次创建所在的节点是它的master节点,其他节点为slave节点。如果master由于某种原因失效,最先加入的slave会被提升为新的master。
无论客户端请求到达master还是slave,最终数据都是从master节点获取。当请求到达master节点时,master节点直接将消息返回给client,同时master节点会通过GM(Guaranteed Multicast)协议将queue的最新状态广播到slave节点。GM保证了广播消息的原子性,即要么都更新要么都不更新。当请求到达slave节点时,slave节点需要将请求先重定向到master节点,master节点将消息返回给client,同时master节点会通过GM协议将queue的最新状态广播到slave节点。
很多同学可能就会疑惑,这样设计太傻叉了,slave完全是闲置的啊!干嘛不学习MySQL主从复制,起码可以搞个读写分离啊!其实业界很多HA架构实践中冗余资源都是闲置的。前面我们讲了RabbitMQ镜像队列中的master、slave是Queue维度而并非Node维度,所以我们可以交叉减少资源限制,如下图所示:

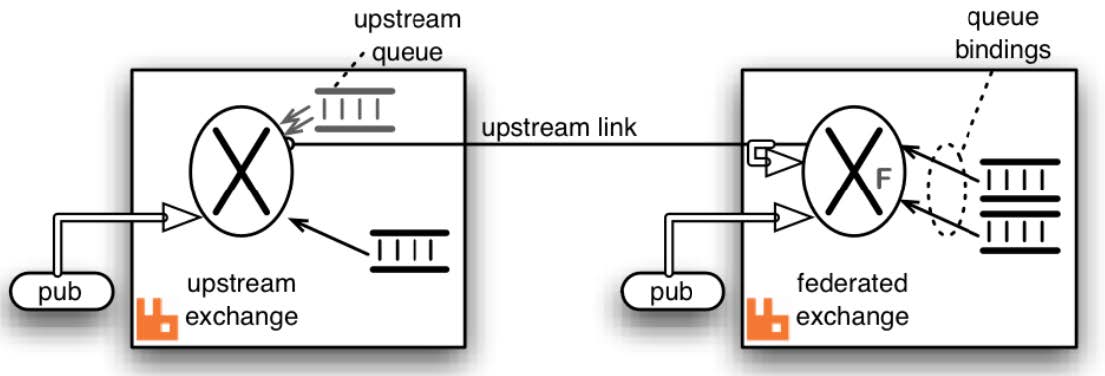
Federation联邦模式
Federation和Shovel类似,也是一个实现跨集群、节点消息同步的插件。支持联邦交换器、联邦队列(作用在不同级别)。
Federation插件允许你配置一个exchanges federation或者queues federation。
一个exchange/queues federation允许你从一个或者多个upstream接收信息,就是远程的exchange/queues。
无论是Federation还是Shovel都只是解决消息数据传输的问题(当然插件自身可能会一些应用层的优化),跨机房跨城市的这种网络延迟问题是客观存在的,不是简单的通过什么插件可以解决的,一般需要借助昂贵的专线。
很多书籍和文章中存在误导大家的,可能会说Federation/Shovel可以解决延迟的问题,可以实现异地多活等等,其实这都是错误的。而且我可以负责人的告诉大家,他们所谓的“异地多活”并非大厂最佳实践。
例如:使用Shovel构建集群,RabbitMQ和应用程序都选择双机房部署时,当杭州机房发生了消息积压后超出阈值部分的消息就会被转发到上海机房中,此时上海机房的应用程序直接消费掉上海机房RabbitMQ的消息,这样看起来上海机房是可以分摊负载,而且一定程度上实现“双机房多活”的。但是数据库呢?选择两边都部署还是仅部署在某个机房呢?两边同时写入是很容易造成冲突的,如果数据库仅仅部署在杭州机房,那么数据库也可能成为瓶颈导致消费速度依然上不去,只不过是多了上海机房中的消费者实例节点而已。
而使用Federation模式呢?如果要真正要实现“双机房多活”那么应用程序也是多机房的,那某些Exchange/Queue中的消息会在两边机房都有,两边机房的应用程序都会同时消息,那必然会造成重复消息!
异地多活架构
方案 容量 容灾 成本 异地多活 [优]基于逻辑机房,容量可伸缩的云微架构
[优]容量可异地伸缩[优]日常运行,容灾时可用性高。
[劣]受城际网络故障影响,影响度取决于横向依赖程度[优]IDC、应用等成本在日常得到有效利用 两地三中心 [劣]仅可部署在一个城市,容量伸缩有城市级瓶颈 [劣]灾备设施冷备等待,容灾时可用性低。 [劣]容灾设施等成本仅在容灾时才使用,且受限于可用性 -
相关阅读:
网络安全应急响应典型案例-(DDOS类、僵尸网络类、数据泄露类)
铸造工艺问题1
登录业务实现(单点登录+微信扫码+短信服务)
【计算机网络三】数据链路层
13届蓝桥杯省赛PythonB组真题-蜂巢
【WebRTC---源码篇】(十:零)WEBRTC/StreamStatisticianImpl持续更新中)
MySql触发器使用
Java数据类型转换:强制类型转换+自动类型转换
销售过程管理的最后一公里——销售日报管理(下)
2023-09-28 mysql-代号m-schema调研-文档记录
- 原文地址:https://blog.csdn.net/weixin_52851967/article/details/128150114