-
【MySQL】-增删查改
作者:学Java的冬瓜
博客主页:☀冬瓜的主页🌙
专栏:MySQL
分享:至若春和景明,波澜不惊,上下天光,一碧万顷。沙鸥翔集,锦鳞游泳,岸芷汀兰,郁郁青青。
主要内容:数据库SQL语言关于库的操作,关于表的增删查改,约束项,设计表,查询的深度剖析

一、库和表的操作
1、库的操作
1、显示当前的数据库 SHOW DATABASES;- 1
- 2
- 3
2、创建数据库 1> CREATE DATABASE 数据库名; --若确定该数据库不存在,IF NOT EXISTS可以省略 --SQL不区分大小写,均可 2> CREATE DATABASE [IF NOT EXISTS] 数据库名; 3> CREATE DATABASE [IF NOT EXISTS] 数据库名 CHARACTER SET utf8mb4; --可以CHARACTER SET utf8mb4指定编码方式 拓展: UTF-8和utf8mb4的区别 UTF-8字符集每个字符最多使用3个字节,utf8mb4每个字符最多可使用4个字节。 说明:MySQL中的的UTF-8编码不是真正的UTF-8,没有包含某些复杂的中文字符,建议使用utf8mb4- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
3、使用数据库 use 数据库名;- 1
- 2
4、删除数据库 DROP DATABASE [IF EXISTS] 数据库名;- 1
- 2
2、表的操作
0、操作表前先选中数据库 use 数据库名; 补充: 常用数据类型: int varchar(size) --可变长字符串 double(m,d) --双精度,m为有效数字个数,d为小数点后个数,会发生精度丢失 decimal(m,d) --双精度,数值精确 timestamp --时间戳java.util.data或者java.sql.Timestamp包下- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
1、查看表结构 desc 表名;- 1
- 2
2、创建表 create table 表名( 字段名1 字段类型1, 字段名2 字段类型2, ...... 字段名n,字段类型n --定义一个字段后面不加',' );- 1
- 2
- 3
- 4
- 5
- 6
- 7
3、删除表 1> DROP TABLE [IF EXISTS] 表名; --常用 2> DROP TABLE [IF EXISTS] 表名1,表名2; 3> DROP TABLES [IF EXISTS] 表名1,表名2;- 1
- 2
- 3
- 4
- 5
- 6
- 7
二、表的增删查改
1、增删查改基本语法
@ 新增(Create)
1> INSERT INTO 表名 (字段1,字段2,...) VALUES (字段值1,字段值2...); 2> INSERT INTO 表名 VALUES (字段值1,字段值2...); --如果是全部字段都由对应的value值插入,则可以省略表名后的字段列表- 1
- 2
- 3
- 4
- 5
@ 查询(Retrieve)
完整查询语法: SELECT [DISTINCT] {* | {column [, column] ...} [FROM table_name] [WHERE ...] [ORDER BY column [ASC | DESC], ...] LIMIT ... 1> SELECT * FROM 表名; --全列查询 2> SELECT id,name FROM 表名; --指定列查询 3> SELECT name,math+10 FROM course; --查询字段为表达式 4> SELECT name,chinese+math+english AS total FROM course; --重命名 5> SELECT DISTINCT name,math FROM course; --去重 6> SELECT name,chinese+math+english AS total FROM course ORDER BY total; --排序 7> SELECT name, math FROM exam_result WHERE math IN (58, 59, 98, 99); --条件查询(范围查询) -- % 匹配任意多个(包括 0 个)字符 SELECT name FROM exam_result WHERE name LIKE '张%';-- 匹配到name以张为开头的数据 -- _ 匹配严格的一个任意字符 SELECT name FROM exam_result WHERE name LIKE '孙_';-- 匹配到name姓孙的名字为一个字的数据 --条件查询(模糊查询) 8> - 查询 qq_mail 未知的同学姓名 SELECT name, qq_mail FROM student WHERE qq_mail IS NULL; --空的查询 9> SELECT id, name FROM exam_result ORDER BY id LIMIT 3 OFFSET 0; --limit后面跟限制行数,offset后面跟开始的位置 --分页查询- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
@ 修改(Update)
UPDATE 表名 SET 字段名1=值1,字段名2=值2... [WHERE...][GROUP BY...][LIMIT...];- 1
- 2
@ 删除(Delete)
2、总结
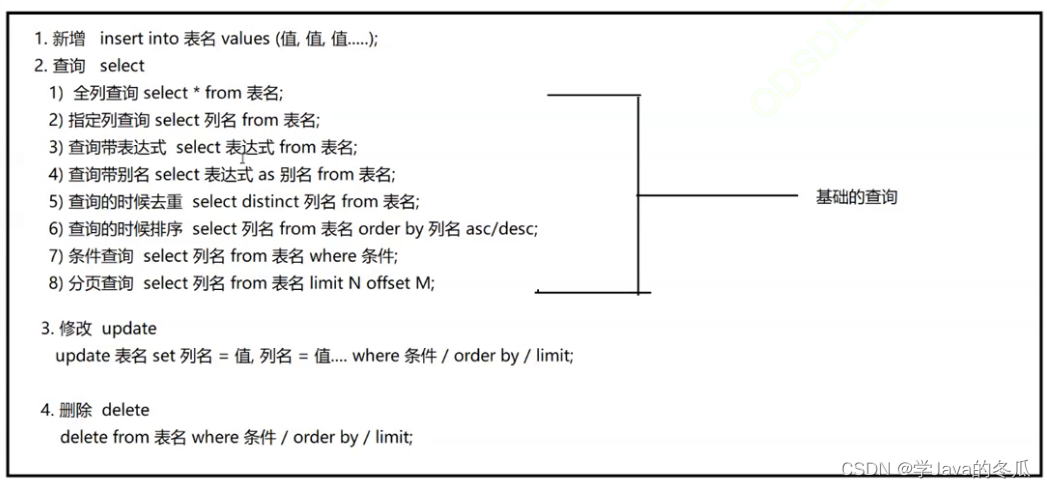
DELETE FROM 表名 [WHERE...][GROUP BY][LIMIT BY];- 1
三、设计表
1、约束条件
- 约束类型:
NOT NULL --非空约束
UNIQUE --唯一约束
DEFAULT --默认值
PRIMARY KEY --主键约束
FOREIGN KEY --外键约束 - 详解:
- NOT NULL + UNIQUE 相当于PRIMARY KEY
- 创建表时使用DEFAULT默认初始化某个字段,那么插入一行数据时,如果不给这个字段值,那这一行的这个字段的值就是创建表时DEFAULT的默认值。
- PRIMARY KEY auto_increment --表示主键默认自增,PRIMARY KEY和AUTO_INCERMENT之间不用加符号
- 代码:
# NOT NULL DROP TABLE IF EXISTS student; CREATE TABLE student ( id int NOT NULL, sn int, name varchar(20), qq_mail varchar(20) ); # UNIQUE DROP TABLE IF EXISTS student; CREATE TABLE student ( id int NOT NULL, sn int UNIQUE, name varchar(20), qq_mail varchar(20) ); # DEFAULT DROP TABLE IF EXISTS student; CREATE TABLE student ( id int NOT NULL, sn int UNIQUE, name varchar(20) DEFAULT 'unkown', qq_mail varchar(20) ); # PRIMARY KEY DROP TABLE IF EXISTS student; CREATE TABLE student ( id int PRIMARY KEY, # 对于整数类型的主键,常配搭自增长auto_increment来使用。 # 插入数据对应字段不给值时,使用最大值+1。 # id int PRIMARY KEY auto_increment sn int UNIQUE, name varchar(20) DEFAULT 'unkown', qq_mail varchar(20) );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 外键深度剖析
- 对下面的例子来说,班级表(父表)对学生表(子表)有约束,学生表(子表)要插入、修改数据,classid必须是班级表(父表)有的值。
- 同时学生表(子表)对班级表(父表)也有约束,父表内容被子表内容引用时,删除必须先删除学生表(子表)内容,才能删除班级表(父表)内容。
- 在建立外键联系前,先创建父表,再创建子表建立外键关系后,想删除class(父表)得先删除student(子表)。
- 想要student学生表(子表)的classid字段和class班级表(父表)的id建立外键联系,要求父表班级表class的id必须是PRIMARY KEY(主键)
- 在student学生表(子表)插入数据时,要先查询学生表的classid的值有没有在与student建立外键关系的父表class表中存在,存在才能插入。
- class表的id是主键,class表的id会被索引起来,当student表插入数据时,查student里的classid是否与class的id对应,会从索引里找,提高查找效率
# FOREIGN KEY -- 创建班级表,有使用MySQL关键字作为字段时,需要使用``来标识 DROP TABLE IF EXISTS classes; CREATE TABLE classes ( id int PRIMARY KEY auto_increment, name varchar(20), `desc` varchar(100) ); -- 创建学生表student,一个学生对应一个班级,一个班级对应多个学生。 -- student中id作为主键,设置classid为外键,关联班级id DROP TABLE IF EXISTS student; CREATE TABLE student ( id int PRIMARY KEY auto_increment, sn int UNIQUE, name varchar(20) DEFAULT 'unkown', qq_mail varchar(20), classes_id int, FOREIGN KEY (classes_id) references classes(id) );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2、表的设计
- 基本思路:
1>先明确实体
2>再明确实体之间的关系
3>根据1,2套入公式建表 - 例子如下:对于教务处管理系统,有学生信息,老师信息,课程信息…
@ 一对一
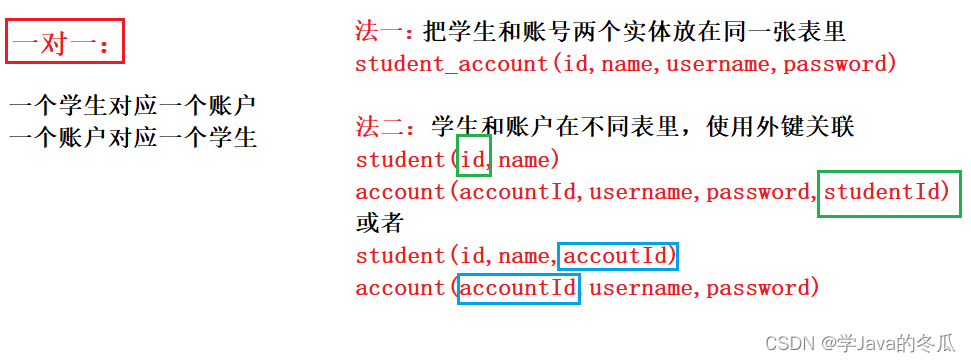
@ 一对多

@ 多对多

四、新增查询结果集
案例:
创建一张用户表,设计有name姓名、email邮箱、sex性别、mobile手机号字段。需要把已有的
学生数据复制进来,可以复制的字段为name、qq_mail-- 创建用户表 drop table if exists test_user; create table test_user ( id int primary key auto_increment, name varchar(20), age int, email varchar(20), sex varchar(1), mobile varchar(20) ); -- 将学生表中的所有数据的,name和qq_mail内容复制到用户表 insert into test_user(name, email) select name, qq_mail from student;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
五、复杂查询
1、聚合查询
@ 聚合函数
COUNT() # ()里面可以是*,或者某个字段,*则统计所有行数,字段则统计当前字段的非空行数 # 对SUM() AVG() MAX() MIN()函数来说,()里必须为数字字段 SUM() AVG() MAX() MIN()- 1
- 2
- 3
- 4
- 5
- 6
# COUNT -- 统计班级共有多少同学,有多少行算多少行,值为NULL也算 select count(*) from student; -- 统计班级收集的 qq_mail 有多少个,qq_mail 为 NULL 的数据不会计入结果 select count(qq_mail) from student;- 1
- 2
- 3
- 4
- 5
@ GROUP BY 字句
注意:带聚合函数的查询,才带有group by
# emp表内全部数据 mysql> select * from emp; +----+------+--------+--------+ | id | name | role | salary | +----+------+--------+--------+ | 1 | 李白 | 老板 | 200000 | | 2 | 韩信 | 经理 | 100000 | | 3 | 玄策 | 程序员 | 12000 | | 4 | 露娜 | 程序员 | 10000 | | 5 | 小乔 | 助理 | 8000 | | 6 | 大乔 | 助理 | 8500 | +----+------+--------+--------+ 6 rows in set (0.00 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
# 查询以职位分组的平均工资的升序 mysql> select role,avg(salary) as avg_salary from emp group by role order by avg_salary asc; +--------+-------------+ | role | avg_salary | +--------+-------------+ | 助理 | 8250.0000 | | 程序员 | 11000.0000 | | 经理 | 100000.0000 | | 老板 | 200000.0000 | +--------+-------------+ 4 rows in set (0.00 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
# 查询以职位分组的平均工资的升序,限制两条数据,从0开始 mysql> select role,avg(salary) as avg_salary from emp group by role order by avg_salary asc limit 2 offset 0; +--------+------------+ | role | avg_salary | +--------+------------+ | 助理 | 8250.0000 | | 程序员 | 11000.0000 | +--------+------------+ 2 rows in set (0.01 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
@ HAVING
说明:
分组查询:可以指定条件进行筛选,两种情况
1、分组前筛选(where)
2、分组后再筛选(having)
3、也可以1+2分组前筛选:
需求:除去玄策后,再统计每个岗位的平均薪资# emp表的所有数据 mysql> select * from emp; +----+------+--------+--------+ | id | name | role | salary | +----+------+--------+--------+ | 1 | 李白 | 老板 | 200000 | | 2 | 韩信 | 经理 | 100000 | | 3 | 玄策 | 程序员 | 12000 | | 4 | 露娜 | 程序员 | 10000 | | 5 | 小乔 | 助理 | 8000 | | 6 | 大乔 | 助理 | 8500 | +----+------+--------+--------+ 6 rows in set (0.00 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
# 除去玄策后,再统计每个岗位的平均薪资 mysql> select role,avg(salary) from emp where name!='玄策' group by role; +--------+-------------+ | role | avg(salary) | +--------+-------------+ | 老板 | 200000.0000 | | 经理 | 100000.0000 | | 程序员 | 10000.0000 | | 助理 | 8250.0000 | +--------+-------------+ 4 rows in set (0.00 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
分组后筛选
需求:除去薪资在10w以上的,再统计每个岗位的平均薪资# 除去薪资在10w以上的,再统计每个岗位的平均薪资 mysql> select role,avg(salary) from emp group by role having avg(salary)<100000; +--------+-------------+ | role | avg(salary) | +--------+-------------+ | 程序员 | 11000.0000 | | 助理 | 8250.0000 | +--------+-------------+ 2 rows in set (0.00 sec) mysql>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
分组前后都筛选:
需求:除去玄策后,除去薪资在10w以上的,再统计每个岗位的平均薪资# 除去玄策后,除去薪资在10w以上的,再统计每个岗位的平均薪资 mysql> select role,avg(salary) from emp where name!='玄策' group by role having avg(salary)<100000; +--------+-------------+ | role | avg(salary) | +--------+-------------+ | 程序员 | 10000.0000 | | 助理 | 8250.0000 | +--------+-------------+ 2 rows in set (0.00 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
@ 查询语句执行次序
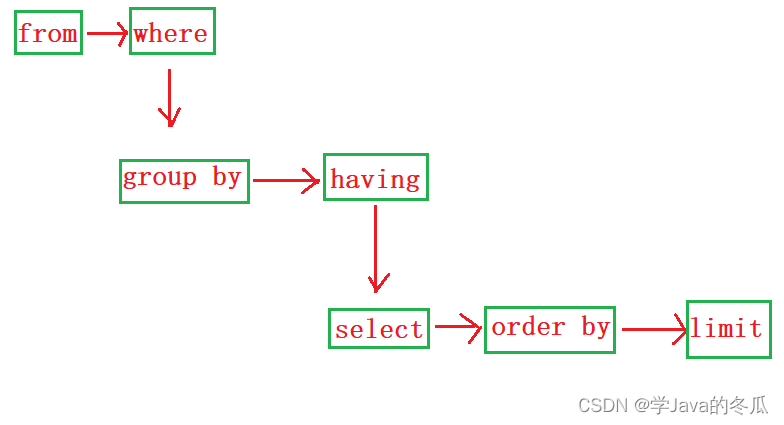
2、联合查询
@ 笛卡尔积
# 学生表信息 mysql> select * from student; +----+------+---------+ | id | name | classid | +----+------+---------+ | 1 | 张三 | 1 | | 2 | 李四 | 2 | +----+------+---------+ 2 rows in set (0.00 sec) # 班级表信息 mysql> select * from class; +----+------+ | id | name | +----+------+ | 1 | Java | | 2 | C++ | +----+------+ 2 rows in set (0.00 sec) # 笛卡尔积信息 mysql> select * from student,class; +----+------+---------+----+------+ | id | name | classid | id | name | +----+------+---------+----+------+ | 2 | 李四 | 2 | 1 | Java | | 1 | 张三 | 1 | 1 | Java | | 2 | 李四 | 2 | 2 | C++ | | 1 | 张三 | 1 | 2 | C++ | +----+------+---------+----+------+ 4 rows in set (0.01 sec) 分析: 两张表笛卡尔积结果:得到更大的表 列数是两张表的列数和 行数是两张表的行数积 结论: 可以从笛卡尔积查询结果发现,只有当 student.classId=class.id(连接条件)时,才是真实有效的数据。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
@ 内连接
- 用笛卡尔积:
select * from student,course,score where student.id=score.student_id and course.id=scores.course_id- 1
- join on连接:先表1+表2,最后+表3
select * from student join score on student.id=score.student_id join course on course.id=score.course_id- 1
准备:SQL建表添加数据:
drop table if exists classes; drop table if exists student; drop table if exists course; drop table if exists score; create table classes (id int primary key auto_increment, name varchar(20), `desc` varchar(100)); create table student (id int primary key auto_increment, sn varchar(20), name varchar(20), qq_mail varchar(20) , classes_id int); create table course(id int primary key auto_increment, name varchar(20)); create table score(score decimal(3, 1), student_id int, course_id int); insert into classes(name, `desc`) values ('计算机系2019级1班', '学习了计算机原理、C和Java语言、数据结构和算法'), ('中文系2019级3班','学习了中国传统文学'), ('自动化2019级5班','学习了机械自动化'); insert into student(sn, name, qq_mail, classes_id) values ('09982','黑旋风李逵','xuanfeng@qq.com',1), ('00835','菩提老祖',null,1), ('00391','白素贞',null,1), ('00031','许仙','xuxian@qq.com',1), ('00054','不想毕业',null,1), ('51234','好好说话','say@qq.com',2), ('83223','tellme',null,2), ('09527','老外学中文','foreigner@qq.com',2); insert into course(name) values ('Java'),('中国传统文化'),('计算机原理'),('语文'),('高阶数学'),('英文'); insert into score(score, student_id, course_id) values -- 黑旋风李逵 (70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6), -- 菩提老祖 (60, 2, 1),(59.5, 2, 5), -- 白素贞 (33, 3, 1),(68, 3, 3),(99, 3, 5), -- 许仙 (67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6), -- 不想毕业 (81, 5, 1),(37, 5, 5), -- 好好说话 (56, 6, 2),(43, 6, 4),(79, 6, 6), -- tellme (80, 7, 2),(92, 7, 6);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
需求1:列出每个同学的姓名,总分,以总分升序排列
# 笛卡尔积+条件查询: mysql> select name,sum(score) as total_score from student,score where student.id=score.student_id group by name order by total_score; +------------+-------------+ | name | total_score | +------------+-------------+ | 不想毕业 | 118.0 | | 菩提老祖 | 119.5 | | tellme | 172.0 | | 好好说话 | 178.0 | | 白素贞 | 200.0 | | 许仙 | 218.0 | | 黑旋风李逵 | 300.0 | +------------+-------------+ 7 rows in set (0.00 sec) # (inner) join on: mysql> select name,sum(score) as total_score from student inner join score on student.id=score.student_id group by name order by total_score; +------------+-------------+ | name | total_score | +------------+-------------+ | 不想毕业 | 118.0 | | 菩提老祖 | 119.5 | | tellme | 172.0 | | 好好说话 | 178.0 | | 白素贞 | 200.0 | | 许仙 | 218.0 | | 黑旋风李逵 | 300.0 | +------------+-------------+ 7 rows in set (0.00 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
需求2:查询所有学生的成绩,及其课程信息
# 笛卡尔积+条件查询 mysql> select student.name as 学生姓名,course.name 课程名称,score.score from student,course,score where student.id = score.student_id and course.id = score.course_id; +------------+--------------+-------+ | 学生姓名 | 课程名称 | score | +------------+--------------+-------+ | 黑旋风李逵 | Java | 70.5 | | 黑旋风李逵 | 计算机原理 | 98.5 | | 黑旋风李逵 | 高阶数学 | 33.0 | | 黑旋风李逵 | 英文 | 98.0 | | 菩提老祖 | Java | 60.0 | | 菩提老祖 | 高阶数学 | 59.5 | | 白素贞 | Java | 33.0 | | 白素贞 | 计算机原理 | 68.0 | | 白素贞 | 高阶数学 | 99.0 | | 许仙 | Java | 67.0 | | 许仙 | 计算机原理 | 23.0 | | 许仙 | 高阶数学 | 56.0 | | 许仙 | 英文 | 72.0 | | 不想毕业 | Java | 81.0 | | 不想毕业 | 高阶数学 | 37.0 | | 好好说话 | 中国传统文化 | 56.0 | | 好好说话 | 语文 | 43.0 | | 好好说话 | 英文 | 79.0 | | tellme | 中国传统文化 | 80.0 | | tellme | 英文 | 92.0 | +------------+--------------+-------+ 20 rows in set (0.00 sec) # join on连接:先表1+表2,最后+表3 mysql> select student.name as 学生姓名,course.name as 课程名称,score.score from student join score on student.id=score.student_id join course on course.id=score.course_id; +------------+--------------+-------+ | 学生姓名 | 课程名称 | score | +------------+--------------+-------+ | 黑旋风李逵 | Java | 70.5 | | 黑旋风李逵 | 计算机原理 | 98.5 | | 黑旋风李逵 | 高阶数学 | 33.0 | | 黑旋风李逵 | 英文 | 98.0 | | 菩提老祖 | Java | 60.0 | | 菩提老祖 | 高阶数学 | 59.5 | | 白素贞 | Java | 33.0 | | 白素贞 | 计算机原理 | 68.0 | | 白素贞 | 高阶数学 | 99.0 | | 许仙 | Java | 67.0 | | 许仙 | 计算机原理 | 23.0 | | 许仙 | 高阶数学 | 56.0 | | 许仙 | 英文 | 72.0 | | 不想毕业 | Java | 81.0 | | 不想毕业 | 高阶数学 | 37.0 | | 好好说话 | 中国传统文化 | 56.0 | | 好好说话 | 语文 | 43.0 | | 好好说话 | 英文 | 79.0 | | tellme | 中国传统文化 | 80.0 | | tellme | 英文 | 92.0 | +------------+--------------+-------+ 20 rows in set (0.00 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
@ 外连接
- 当两个表的数据一一对应时内外链接的查询结果相同。
- 不对应时:左外连接显示左表全部数据,右外连接显示有表全部数据
准备:student和score表数据
mysql> select * from student; +------+------+ | id | name | +------+------+ | 1 | 张三 | | 2 | 李四 | +------+------+ 2 rows in set (0.00 sec) mysql> select * from score; +------------+-------+ | student_id | score | +------------+-------+ | 1 | 90 | | 3 | 88 | +------------+-------+ 2 rows in set (0.00 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
内连接:
# 笛卡尔积+连接条件 mysql> select * from student,score where student.id=score.student_id; +------+------+------------+-------+ | id | name | student_id | score | +------+------+------------+-------+ | 1 | 张三 | 1 | 90 | +------+------+------------+-------+ 1 row in set (0.00 sec) # join on连接 mysql> select * from student join score on student.id=score.student_id; +------+------+------------+-------+ | id | name | student_id | score | +------+------+------------+-------+ | 1 | 张三 | 1 | 90 | +------+------+------------+-------+ 1 row in set (0.00 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
外连接:
# 左外连接 mysql> select * from student left join score on student.id=score.student_id; +------+------+------------+-------+ | id | name | student_id | score | +------+------+------------+-------+ | 1 | 张三 | 1 | 90 | | 2 | 李四 | NULL | NULL | +------+------+------------+-------+ 2 rows in set (0.00 sec) # 右外连接 mysql> select * from student right join score on student.id=score.student_id; +------+------+------------+-------+ | id | name | student_id | score | +------+------+------------+-------+ | 1 | 张三 | 1 | 90 | | NULL | NULL | 3 | 88 | +------+------+------------+-------+ 2 rows in set (0.00 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
@ 自连接
思考:一般情况下SQL中无法针对行和行之间的比较,自连接可以实现把行转换列进行列和列的比较。
需求1:显示所有计算机原理成绩比Java成绩高的成绩信息。
步骤:
a>找两门课程的id(也可以直接用子查询)

b>笛卡尔积:可以发现是随机排列组合的结果(两个student_id和两个course_id都不是对应的)
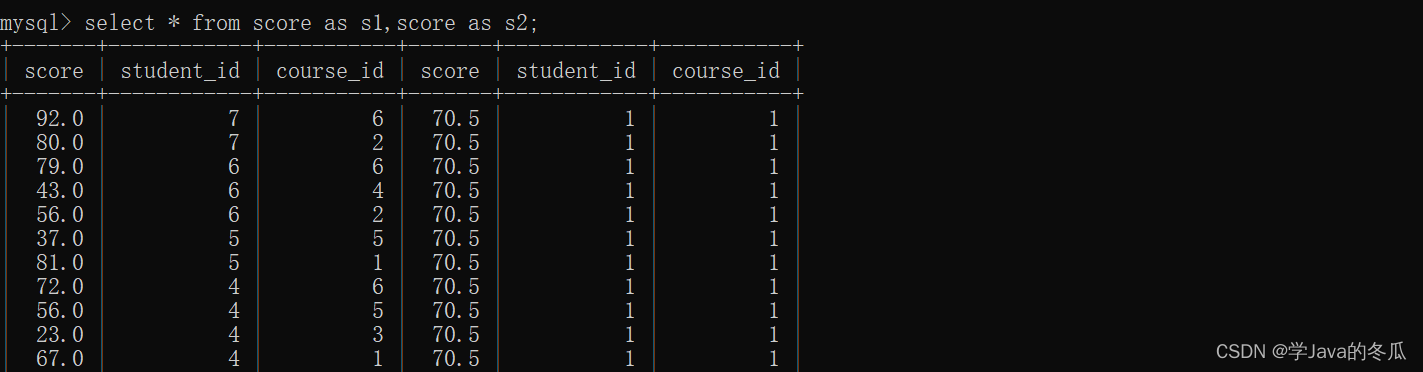
c>添加连接条件:针对个人比较课程,所以用student_id作为自连接条件。确保是比较每个人的计算机原理成绩比Java成绩高的信息。
(如果是针对课程,比较不同同学的成绩情况,就要用course_id作为连接条件)
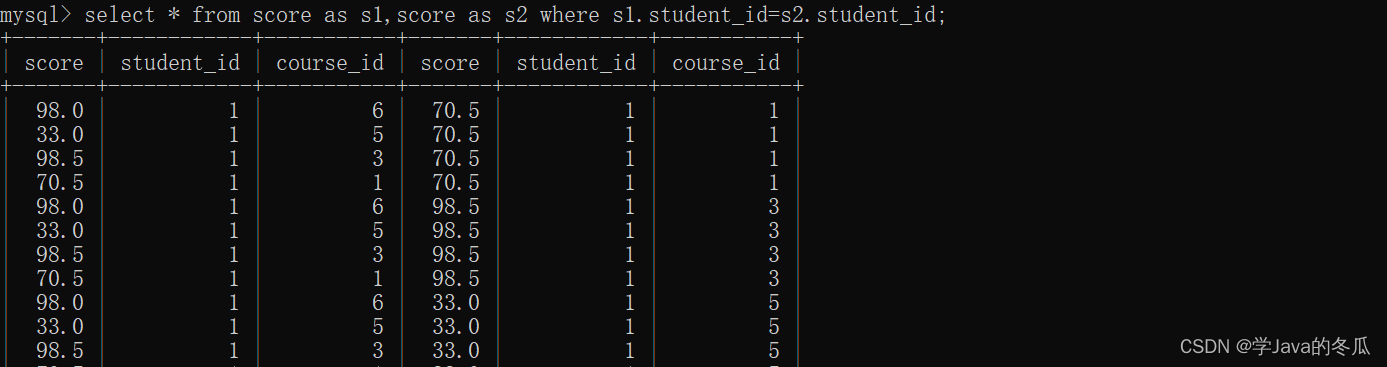
d>添加课程限制:前三列是course_id=1,后三列是course_id=3的

e>查询比较同一个学生的计算机原理成绩比Java成绩高的信息
需求2:显示白素贞成绩比许仙成绩高的成绩信息。
步骤:
a>找两位同学的id(也可以直接用子查询)

b>笛卡尔积+添加连接条件+学生限制条件:

c>查询比较白素贞成绩比许仙高的课程

@ 子查询
分析:
子查询对代码可读性、运行效率都是较低的,可以用多次查询代替子查询。
认识:
可读性,可维护性=》提高开发效率
程序跑得快=》提升运行效率单行子查询:返回一行记录的子查询
查询与“不想毕业” 同学的同班同学:mysql> select * from student where classes_id=(select classes_id from student where name='不想毕业') and name!='不想毕业'; +----+-------+------------+-----------------+------------+ | id | sn | name | qq_mail | classes_id | +----+-------+------------+-----------------+------------+ | 1 | 09982 | 黑旋风李逵 | xuanfeng@qq.com | 1 | | 2 | 00835 | 菩提老祖 | NULL | 1 | | 3 | 00391 | 白素贞 | NULL | 1 | | 4 | 00031 | 许仙 | xuxian@qq.com | 1 | +----+-------+------------+-----------------+------------+ 4 rows in set (0.00 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
多行子查询:返回多行记录的子查询
案例:查询“语文”或“英文”课程的成绩信息- [NOT] IN关键字:
mysql> select * from score where course_id in (select id from course where name='语文' or name='英文'); +-------+------------+-----------+ | score | student_id | course_id | +-------+------------+-----------+ | 98.0 | 1 | 6 | | 72.0 | 4 | 6 | | 43.0 | 6 | 4 | | 79.0 | 6 | 6 | | 92.0 | 7 | 6 | +-------+------------+-----------+ 5 rows in set (0.04 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- [NOT] EXISTS关键字:
一般不用,因为效率低,用这个还不如分多次查询。
@ 合并查询
分析:
- 如果在同一表里可以用or来连接做到合并的效果,这时用or或者union一样。
- 但当从两个表中查询两个SQL语句合并起来,只能用union,并且要求字段要对应相同。
- 对于查询结果union可以去重,union all保留全部,不去重。
mysql> select * from course where id<3 union select * from course where name='高阶数学'; +----+--------------+ | id | name | +----+--------------+ | 1 | Java | | 2 | 中国传统文化 | | 5 | 高阶数学 | +----+--------------+ 3 rows in set (0.04 sec)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3、认识
- 可读性,可维护性=》提高开发效率
- 程序跑得快=》提升运行效率
- 高内聚:把有关联关系的代码写到一起。
- 低耦合:模块之间影响小,修改一个模块不会影响另一个。
-
相关阅读:
前端面试(2)——页面布局
Linux文件权限
EVE111
状态模式(状态和行为分离)
Feign服务调用
Java基础-Stream流
android kotlin Dimension
爬虫 — Js 逆向案例五闪职网登录
层叠、继承与盒模型
单视频播放量超20万的公开课配套教材,猫书来了~
- 原文地址:https://blog.csdn.net/m0_63979882/article/details/128060670
