-
segmentation
(用于医学图像分割的金字塔医学transformer)
Pyramid Medical Transformer for Medical Image Segmentation
基于CNN的模型通过低效地堆叠卷积层来捕获长期依赖性,但基于注意力的模型明确地构建了所有范围的关系。然而,为全局关系分配可学习参数是昂贵的;因此,已经研究了全局自关注的有效近似,以避免固有的二次复杂性。最流行的技术是将整个图像分割为多个块,这些块随后用于计算块之间的全局关注度或块内的逐像素全局关注度。这种任意的分割机制给现有的医学分割方法带来了严重的问题,因为它不能捕获不同尺度和范围的所有注意力。当大型对象被分割成不同的块时,这些碎片不能有效地相互关注。
当前的医疗transformer在全分辨率图像上建模全局上下文,导致不必要的计算成本。为了解决这些问题,我们开发了一种新的方法,使用金字塔网络架构(即金字塔医疗transformer(PMTrans))集成多尺度注意力和CNN特征提取,并利用了自关注层和卷积层的特征提取能力
PMTrans通过处理多分辨率图像捕获多范围关系。
有四个分支:三个transformer分支(短、中、长分支)用门控轴向注意块构建,第四个分支用CNN块构建。在短距离transformer中采用了局部门控轴向注意力,在中距离和长距离分支采用全局门控轴向注意力.
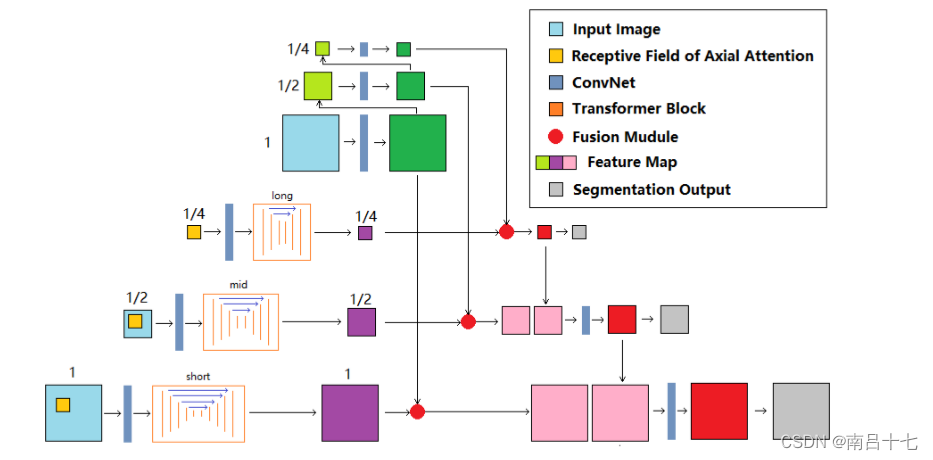
对于中程和远程分支,输入图像分别重新缩放为½和¼。来自transformer分支的特征图(紫色)与来自CNN分支的那些特征图(绿色)以不同比例融合。在培训阶段,深度监督以½和¼的比例进行。
三个transformer分支用于捕捉像素之间的关联,图像的尺度不同,CNN的第四分支用于提取图像中的特征。
它们都有一个初始卷积块,用于一开始的基本特征提取。该卷积块有三个卷积层,然后是batch normalization和ReLU函数。然后,他们有一个编码器-解码器式的transformer块来计算像素之间的自我关注。这些transformer块由门控轴向关注层构建,并且在编码器和解码器路径之间具有跳跃连接。短程transformer块的深度为5,中程块为4,长程块为3,以适应输入特征图的不同大小。这三个分支的输出具有与它们的输入相同的高度和宽度,并且随后与来自CNN分支的特征图集成。然后对组合结果进行上采样以恢复原始分辨率。
CNN块由残差块构建,通过跳跃连接堆叠卷积层以增强梯度流,来自CNN分支的特征图以不同比例融合到来自transformer分支的特征图中,并且金字塔融合方案是由注意力U-net提出的注意力门构建的。不是简单地连接特征图并让卷积层学习融合它们,而是添加权重以在不同尺度上有意识地将它们与注意感知的可学习参数集成.(即对相对位置编码增加权重)

使用浅层网络来完成任务。通过融合transformer和CNN的特征图,我们的模型保留了低层次的上下文和全局关系。深度监督被引入到两个下采样特征图中。

总结:
三个transformer有不同的receptive field,但都使用相同的门控轴向注意力机制,使得多尺度信息能够被高效地捕捉,也避免了将图像分割成块面临的问题。
模型采用了金字塔结构,包含四个分支:3个Transformer(多尺度)分支和一个CNN分支;
使用attention U-net,用以将3个不同尺度transformers和CNN分支融合输出多尺度特征图。
Segmenter: Transformer for Semantic Segmentation
(Segmenter:语义分割的transformer)
最近的语义分割方法通常依赖于卷积编码器-解码器架构,其中编码器生成低分辨率图像特征。最先进的方法部署了完全卷积网络(FCN),并在具有挑战性的分割基准上取得了令人印象深刻的结果。这些方法依赖于可学习的堆叠卷积,可以捕获语义丰富的信息,并且在计算机视觉中非常成功。然而,卷积滤波器的局部性质限制了对图像中全局信息的访问。
这种信息对于分割尤其重要,其中局部斑块的标记通常取决于全局图像上下文。为了避免这个问题,DeepLab方法引入了具有扩张卷积和空间金字塔池的特征聚集。这允许扩大卷积网络的接收场并获得多尺度特征。随着NLP的最新进展,几种分割方法探索了基于信道或空间注意力和逐点注意力的替代聚合方案,以更好地捕获上下文信息。然而,这种方法仍然依赖于卷积主干,因此偏向于局部交互。广泛使用专用层来弥补这种偏差表明了卷积结构在分割方面的局限性。
提出了一种基于视觉变换器(ViT)的语义分割新方法,该方法不使用卷积,通过设计捕获上下文信息

与基于卷积的方法相比,我们的方法允许在第一层和整个网络中建模全局上下文。我们基于最近的视觉变换器(ViT),并将其扩展到语义分割。
我们依赖于对应图像块的输出嵌入,并使用逐点线性解码器或掩码变换器解码器从这些嵌入中获得类标签。我们利用预先训练的模型进行图像分类,并表明我们可以在可用于语义分割的中等大小的数据集上对它们进行微调。线性解码器已经可以获得优异的结果,但通过生成类掩码的掩码变换器可以进一步提高性能。
图像被分成一系列的补丁,每个补丁然后被平坦化为1D向量接着线性投影到补丁嵌入用来产生补丁嵌入序列,为了捕获位置信息,可学习的位置补丁被添加到补丁序列用来得到结果输入序列,transformer编码器应用于补丁序列以生成上下文化编码序列。
额外增加了一个cls token,再继续做一个Transformer Encoder,计算归一化贴片嵌入和类嵌入之间的标量积来生成K个mask,解码器是由M层组成的transformer编码器
第三部分就是将图片经过网络的输出与cls token对应位置的输出做一个矩阵乘,得到class Masks,最后经过双线性上采样,还原成原图大小,应用softmax和应用层范数,以获得形成最终分割图的像素级类分数从而得到语义分割的结果

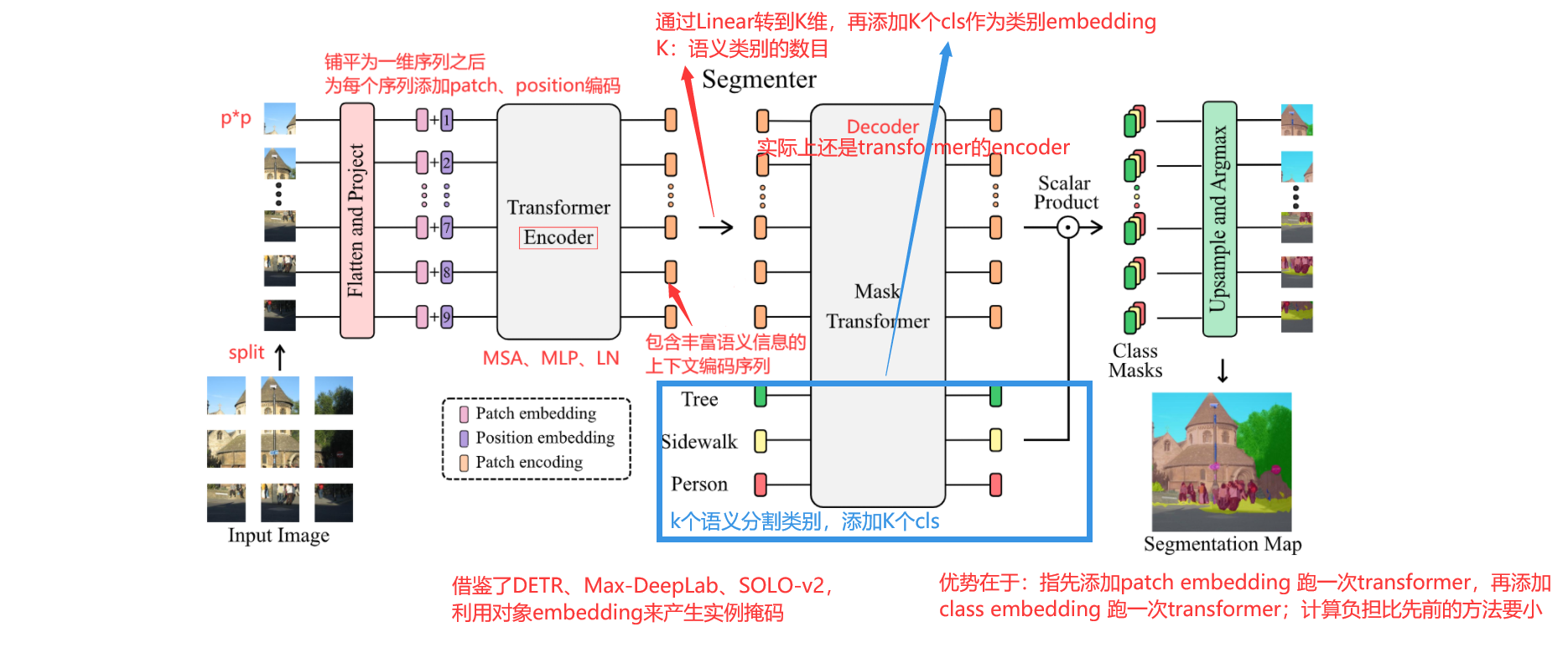
argmax()是一种函数,是对函数求参数的函数,也就是求自变量最大的函数。
Patch Embedding用于将原始的2维图像转换成一系列的1维patch embeddings。
Scalar product:向量点乘,也称向量的数量积
总结:
先添加patch embedding跑一次transformer, 再添加class embedding跑一次transformer; 计算负担比先前的方法要小
在解码阶段联合处理补丁和类嵌入解决了语义分割,但 Mask transformer 也可以通过用对象嵌入替换类嵌入来直接适用于执行全景分 割。
在优化方面,使用逐像素交叉熵损失函数。分别检查每个像素,将类预测(深度方向的像素向量)与我们的热编码目标向量进行比较。交叉熵的损失函数单独评估每个像素矢量的类预测,然后对所有像素求平均值,所以我们可以认为图像中的像素被平等的学习,但是如果应用在遥感方向上常出现类别不均衡(class imbalance)的问题,由此导致训练会被像素较多的类主导,对于较小的物体很难学习到其特征,从而降低网络的有效性。
token:包含class token、patch token,在NLP叫每一个单词为token,然后有一个标注句子语义的标注是CLS,在CV中把图像切割成不重叠的patch序列(其实就是token)
transformer变量的细节

Ti- tiny(极小的)S-small(小的)L-large(大的) B-base(基础的)
Seg-B/16表示具有16×16输入补丁大小的“Base”变量
基于DeiT的模型用†表示,例如Seg-B†/16
ADE20K验证集上具有不同主干和输入补丁大小的不同分段器模型的性能比较。

ADE20K数据集的最新对比,该数据集包含具有细粒度标签的具有挑战性的场景,是最具挑战性的语义分割数据集之一
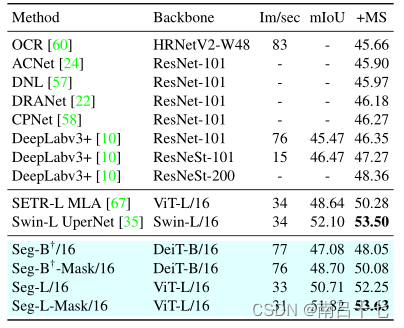
Cityscapes验证集的最新比较
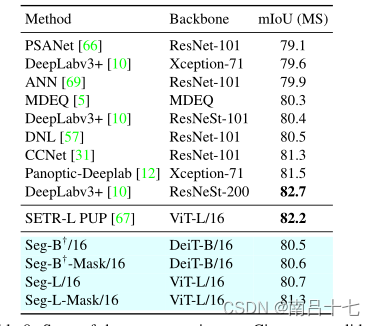
image/sec每秒钟多少张图
ResT: An Efficient Transformer for Visual Recognition
(ResT:一种有效的视觉识别Transformer)
传统的transformer存在以下几个问题
1.transformer 对于图像边角等低级特征提取比较困难
2.transformer的自注意力和patch 的二次缩放会导致大量训练与推理开销
3.MSA中的每个header仅仅负责每个token的子集,当token的维度比较短时候会导致query 与key的点积无法形成有效信息
4.现有transformer中token 和pe都是固定规模对密集预测的视觉任务来讲不是很适应。

(1)构建了一种记忆高效的多头自我注意,它通过简单的深度卷积来压缩记忆,并在保持多头多样性的同时将交互作用投射到注意头维度;
MSA有两个缺点:
MSA的计算量与d m 或n成平方关系,导致训练和推理的开销很大;
MSA中的每个头部只负责嵌入维度的一个子集,这可能会影响网络的性能,特别是每个头部的token嵌入维度较小时。

Conv()是一个标准的1×1卷积运算,它模拟了不同头部之间的相互作用。每个头部的注意力功能可以依赖于所有键和查询。但是削弱MSA在不同位置联合处理来自不同表示子集的信息的能力。为了恢复这种多样性能力,我们为点积矩阵(Softmax之后)添加了实例归一化——IN(·)



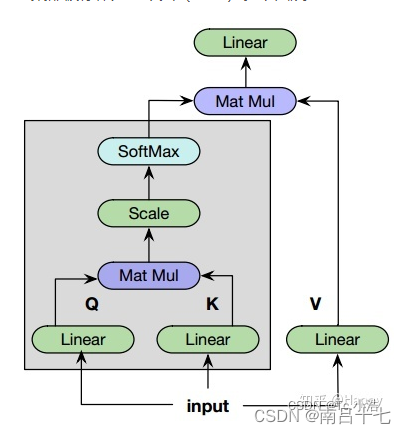
函数matmul:矩阵乘法
函数multiply:矩阵点乘

(2) 空间注意力机制(pixel-attention——PA)位置编码被构造为空间注意力,它更灵活,可以处理任意大小的输入图像,无需插值或微调;
原因:在ViT中位置编码的长度和输入token的长度完全相同,限制应用场景
通过PA应用深度卷积获得像素权重,然后通过S形函数进行缩放

token(符号):包括单词和标点
(3)以4的缩减因子缩小高度和宽度维度。为了以较少的参数有效地捕获低特征信息,代替在每个阶段开始时直接进行标记化,我们将patch嵌入设计为重叠的卷积运算堆栈,并在2D整形的标记图上大步前进

一个stem结构提取特征后面跟随四个阶段,每个阶段包含一个patch embedding 和一个 PE(位置编码) 与多个不同通道和感受野的Transformer。
在每个阶段的开始,采用patch embedding模块来降低token的分辨率并扩展通道维度。融合位置编码模块,抑制位置信息,增强patch embedding的特征提取能力,并随之送入到efficent transformer 中。
ViT中的Patch Embedding用于将原始的2维图像转换成一系列的1维patch embeddings。
与ImageNet-1k基准上最先进的主干进行比较

FLOPs计算量。可以用来衡量算法/模型的复杂度
TOP-1/TOP-5:预测概率值
Throughput——吞吐量:指相当一段时间内测量出来的系统单位时间处理的任务数或事务数
计算量要看网络执行时间的长短,参数量要看占用显存的量
总结:虽然预测概率值比较准确,但是同样的算法复杂度,更加占显存,而且相同时间内处理任务少

Transformer Meets Convolution: A Bilateral Awareness Network for Semantic Segmentation of Very Fine Resolution Urban Scene Images
(Transformer遇到卷积:一种用于高分辨率城市场景图像语义分割的双边感知网络)
超精细分辨率(VFR)城市场景图像的语义分割是遥感界的一个热门话题。它在各种城市应用中发挥着至关重要的作用,如城市规划、车辆监测、土地覆盖测绘、变化检测、建筑和道路提取以及其他实际应用。语义分割的目标是用特定类别标记每个像素。由于城市地区的地理对象通常具有类内方差大和类间方差小的特点,因此非常精细分辨率RGB图像的语义分割仍然是一个具有挑战性的问题。
不同材料制成的城市建筑显示出不同的光谱特征,而由相同材料(例如水泥)制成的建筑和道路在RGB图像中显示出相似的纹理信息。
stem block是由三个3×3卷积层和一个2×2最大池化层组成的,提高了检测性能,可以减少从原始输入图像的信息损失。
Embedding patch:
- 将图片像分词一样划分
- 将分好的图片(我们这里称为Patch)进行N(embedded_dim)维空间的映射
VisionTransformer(一)—— Embedding Patched与Word embedding及其实现_lzzzzzzm的博客-CSDN博客
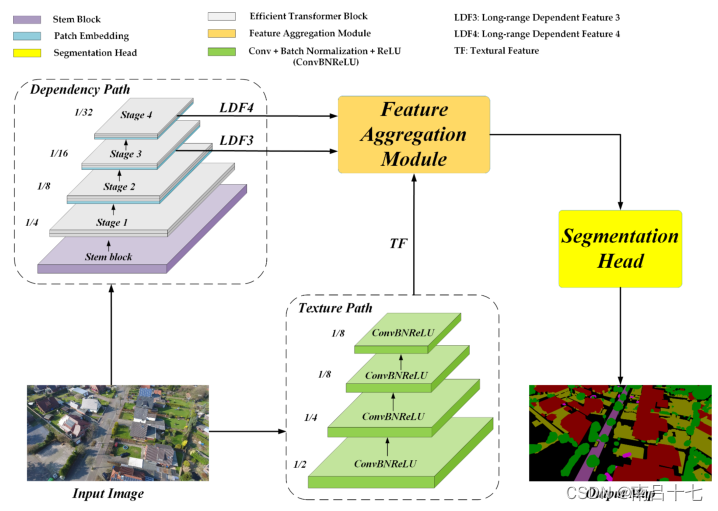
依赖路径采用一个茎块和四个transformer(即阶段1-4)来提取远程依赖特征。每个阶段由两个有效的transformer块(ETB)组成。特别地,阶段2、阶段3和阶段4还涉及补片嵌入(PE)操作。通过依赖路径,生成两个长距离依赖特征(即LDF3和LDF4)。
依赖路径主要由ResT-Lite:主干块、补丁嵌入和高效transformer块
stem block:前两个卷积之后是BN和relu
embeeding patch:对特征图进行下采样,以进行分层特征表示
高效transformer块:高效多头自关注(EMSA)、MLP(全连接神经网络)和LN组成
EMSA
Linear Projection为数据特征的线性投影(虽然字面意思像线性预测),通过一个多维空间展示数据特征,可视化数据分类。

BN对Batch中的每一张图片的同一个通道一起进行Normalization操作,而IN是指单张图片的单个通道单独进行Normalization操作。其中C代表通道数,N代表图片数量(Batch)。

纹理路径部署了四个卷积层来捕获纹理特征(TF),而每个卷积层都配备了批量归一化(BN)和ReLU激活功能。纹理路径的下采样因子设置为8,以保留空间细节.

T表示由卷积层、批归一化操作和ReLU激活组成的组合函数。
T1的卷积层的核大小为7,步长为2,这将信道维度从3扩展到64。对于T2和T3,核大小和步长分别为3和2。信道尺寸保持为64。对于T4,卷积层为标准11卷积,步幅为1,将通道尺寸从64扩展到128。因此,输出纹理特征被缩小8倍,通道尺寸为128。
Feature aggregation module (特征聚合模块)

Attention Map:
一种特征矩阵的计算方式,凝练出有特点的矩阵数据,使得卷积运算中,更加关注有效的特征,忽略无效的特征.
使用掩码(mask)实现,通过新一层的权重,强调重点。将图片数据中关键的特征标识出来,通过学习训练,让深度神经网络学到每一张新图片中需要关注的区域,也就形成了注意力。本质是希望通过学习得到一组可以作用在原图上的权重分布。
matrix multiplication:矩阵乘法
注意力嵌入模块(AEM)来合并LDF3和LDF4
Linear Attenttion(线性注意力模块)

Attentional Embedding Module


Swin Transformer:使用移位窗口的分层视觉转换器(Hierarchical Vision Transformer using Shifted Windows)
与transformer相比的改动,将Transformer块中的标准多头自关注(MSA)模块替换为基于移位窗口的模块
Swin Transformer,一个使用移动窗口(Shifted window),具有层级设计的(hierarchical)多功能主干网络(general-proposed backbone)
移动窗口操作(shifted windowing scheme)将自注意力计算限制在了不重叠的局部窗口中,大大提升了计算效率,同时也允许不同窗口间的交互(cross-window connection);层次结构(hierarchical architecture)具有多尺度建模的灵活性,并且具有相对于图像大小的线性计算复杂度.
shift是在连续两个self-attention layer之间执行的,shift操作让原本相互独立的windows之间有了交互(bridge the windows of the preceding layer),从而大大提升了模型建模能力(modeling power)
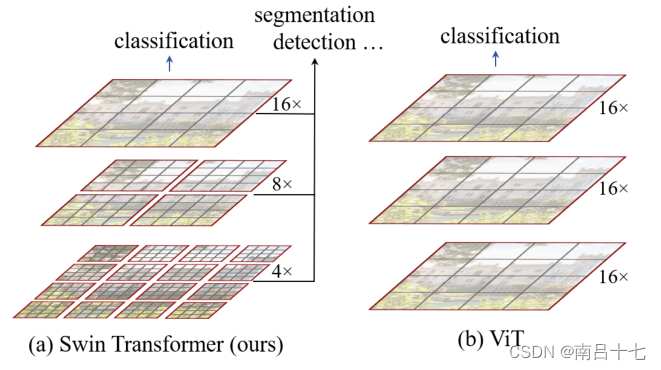
Swin Transformer通过合并更深层中的图像块(以灰色显示)来构建分层特征图,并且由于仅在每个局部窗口(以红色显示)内计算自我关注,因此对输入图像大小具有线性计算复杂度。
相比之下,先前的视觉变换器(ViT)产生单个低分辨率的特征图,并且由于全局自关注的计算,对输入图像大小具有二次计算复杂性。

patch Merging:做下采样,用于缩小分辨率,调整通道数进而形成层次化的设计,同时也能节省一定运算量。类似池化的操作,但是比Pooling操作复杂一些。池化会损失信息,patch Merging不会。
每次降采样是两倍,因此在行方向和列方向上,按位置间隔2选取元素,拼成新的patch,再把所有patch都连接起来作为一整个张量,最后展开。此时通道维度会变成原先的4倍(因为H,W各缩小2倍),此时再通过一个全连接层再调整通道维度为原来的两倍。

Patch Partition+Linear Embedding:首先将RBG图像分割为不重叠的patches,然后把patch拉直作为“token”,patch大小为4x4,所以每一个token维度为4x4x3=48,然后做linear embedding,将特征映射到任意维度(设为C),假设patches数量为N (N=H/4 * W/4),则得到维度为NxC的矩阵
Swin Transformer块由一个基于移位窗口的MSA模块组成,随后是一个2层MLP,其间有GELU非线性。在每个MSA模块和每个MLP之前应用层规范(LN)层,在每个模块之后应用剩余连接。

W-MSA就是在一个小窗口内进行transformer的操作。为什么要用W-MSA而不直接用MSA。因为视觉任务本身有局部性,transformer能看到所有像素,很可能没必要,对图片中的一个车或者一个人来说,局部就足够了。另外一方面,省资源。
W-MSA能够获取窗口内部的信息,那么窗口之间的信息由SW-MSA获取。SW-MSA分为三部分:移动窗口,cyclic shift(循环位移)和mask。

移动窗口(将这个窗口向右下角移动),原来只需要计算四个块,而现在划分了九个块,而且麻烦的是块的大小还不一样


cyclic shift(循环位移),除了E这个块之外,其他的块都是来自不同的地方

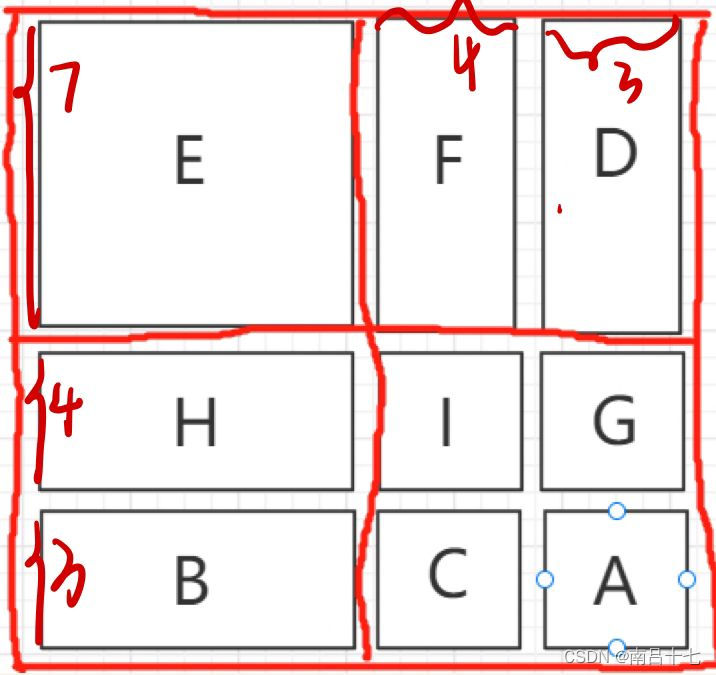 mask,去计算注意力
mask,去计算注意力一个patch是7*7的大小,移动窗口的时候呢是移动patch/2的距离,也就是移动了3,所以H块的大小为7*4,B的大小为7*3

相对位置偏差B


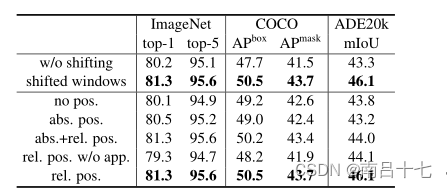
与没有位置编码和具有绝对位置嵌入的那些相比,COCO上为+2.3/+2.9mIoU,ADE20K上为+2.2/+2.9m IoU。这表明了相对位置偏差的有效性。还要注意的是,虽然包含绝对位置嵌入提高了图像分类精度(+0.4%),但它损害了对象检测和语义分割(COCO上为-0.2盒/掩模AP,ADE20K上为-0.6 mIoU)

分割上的实验

优点:
- Swin Transformer使用CNN结构设计中的一些理念(降采样、局部dependency)来重新设计Transformer。
- 每层仅对局部进行关系建模,同时不断缩小特征图的宽高,扩大感受野。
- 移位窗口方案通过将self-attention计算限制在非重叠的局部窗口上,同时允许跨窗口连接,从而提高了效率。
- Swin Transformer随着网络深度的加深数量会逐渐减少并且每个patch的感知范围会扩大
缺点:
- Swin Transformer并没有提供一个像反卷积那样的上采样的算法,因此对于这类需求的backbone,Swin Transformer并不能直接替换,也许可以采用双线性差值来实现,但效果如何还需要评估。
- 从W-MSA一节中可以看出每个窗口都有一组独立的Q,K,V,因此Swin Transformer并不具有CNN一个特别重要的特性:权值共享。
个人理解与想法:
- Swin Transformer的网络结构非常简单,由4个stage和一个输出的Head组成,非常容易扩展。
-
相关阅读:
基于JavaSwing聊天系统的设计与实现(加好友 视频 发文件 远程监控) 毕业设计
【无标题】
数据源、映射器的复用
工业4.0 管理壳学习笔记(6)-数字铭牌
37-5 基于时间的盲注 SQL 注入 PoC 的 Python 编写
江苏移动基于OceanBase稳步创新推进核心数据库分布式升级
Hugging Face:成为机器学习界的“GitHub”
javascript实现常用数组方法重写
[探究] program break (chatgpt 协助)
推荐系统笔记(十六):推荐系统图协同过滤的深入理解/
- 原文地址:https://blog.csdn.net/qq_44832048/article/details/127824732