-
Flink系列之Flink基础使用与核心概念
声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
B站:https://space.bilibili.com/1523287361 点击打开链接
微博地址: https://weibo.com/luoyepiaoxue2014 点击打开链接
title: Flink系列
三、Flink基础使用与核心概念
3.1 编程入门
一般程序都是需要有输入、处理、输出。那么 Flink 同样也是,它的专业术语是什么?Flink 专业术语对应 Source,Transformation,Sink。

Spark、 Flume : source transform sink
也就是在在我们提到Flink程序的时候,我们会有Source数据源,然后map其实就是对输入的数据处理的意思,接着Sink就是落地数据,也就是我们存储数据到什么地方。这里需要跟Flume的source和sink比较,这二者含义和作用基本相同,但是却不能混淆。Flink的source,虽然也是数据源,但是这些我们需要代码指定的,Flume直接通过配置文件指定。同样sink也是。而Flink中间还有对数据的处理,也就是map。这就是程序Flink的程序结构。
官网链接: https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/learn-flink/overview/
Flink的程序和数据流结构:
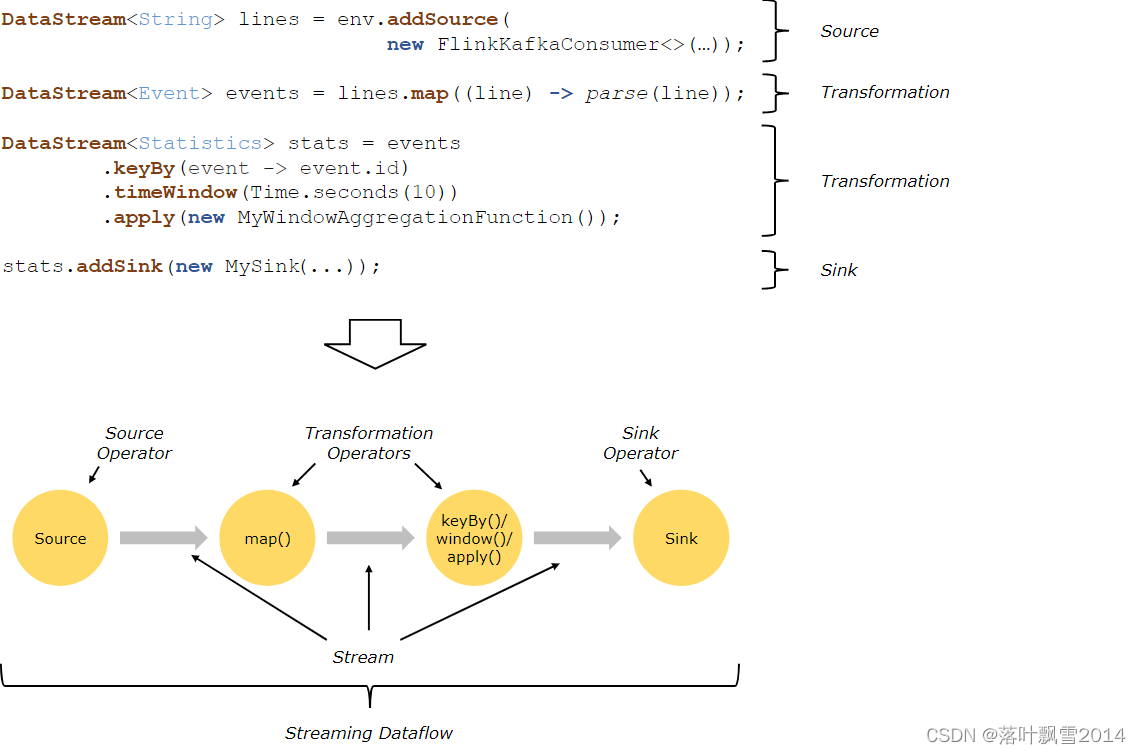
Operator: 操作计算逻辑;不仅仅是普通的 操作符,还有方法,
关于上图的理解:FlinkKafkaConsumer 是一个 Source Operator, map、keyBy、timeWindow、apply 是 Transformation Operator, RollingSink 是一个Sink Operator- 1
- 2
- 3
总结编程套路:
1、获得一个执行环境:(Execution Environment) 2、加载/创建初始数据:(Source) 3、指定转换这些数据:(Transformation) 4、指定放置计算结果的位置:(Sink) 5、触发程序执行:(Action)- 1
- 2
- 3
- 4
- 5
3.1.0 添加依赖
<dependency> <groupId>org.apache.flinkgroupId> <artifactId>flink-scala_2.12artifactId> <version>1.14.3version> dependency> <dependency> <groupId>org.apache.flinkgroupId> <artifactId>flink-streaming-scala_2.12artifactId> <version>1.14.3version> dependency> <dependency> <groupId>org.apache.flinkgroupId> <artifactId>flink-clients_2.12artifactId> <version>1.14.3version> dependency>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3.1.1 批处理的WordCount
package com.aa.flinkscala import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment} /** * @Author AA * @Date 2021/12/13 16:02 * @Package com.aa.flinkscala * 使用 Flink 实现 WordCount的 批处理 */ object WordCountScalaBatch { def main(args: Array[String]): Unit = { //1、获取执行环境 val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment //2、获取数据源 val text: DataSet[String] = env.readTextFile("D:\\input\\test1.txt") import org.apache.flink.api.scala._ //加载隐式转换 //3、数据的业务逻辑处理 val res: AggregateDataSet[(String, Int)] = text.flatMap(_.split(" ")).map((_, 1)).groupBy(0).sum(1) //4、数据结果保存或输出打印 res.print() } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
3.1.2 流处理的WordCount
package com.aa.flinkscala //import org.apache.flink.api.scala.createTypeInformation 导入隐式参数时候,这个也可以,下面那个import org.apache.flink.streaming.api.scala.createTypeInformation也可以 import org.apache.flink.streaming.api.scala.createTypeInformation import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} /** * @Author AA * @Date 2021/12/13 16:54 * @Package com.aa.flinkscala */ object WordCountScalaStream { def main(args: Array[String]): Unit = { //1、获取执行环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //2、获取数据源 val textStream: DataStream[String] = env.socketTextStream("192.168.22.138", 9999) //3、数据计算处理逻辑 val wordCountStreamRes: DataStream[(String, Int)] = textStream.flatMap(_.split(" ")) .map((_, 1)) .keyBy(line => line._1) //.keyBy(0) //过期的方法,将来可能不支持啦 .sum(1) //4、打印输出结果 wordCountStreamRes.print() //5、启动应用程序 env.execute("WordCountScalaStream") } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
3.2 核心概念
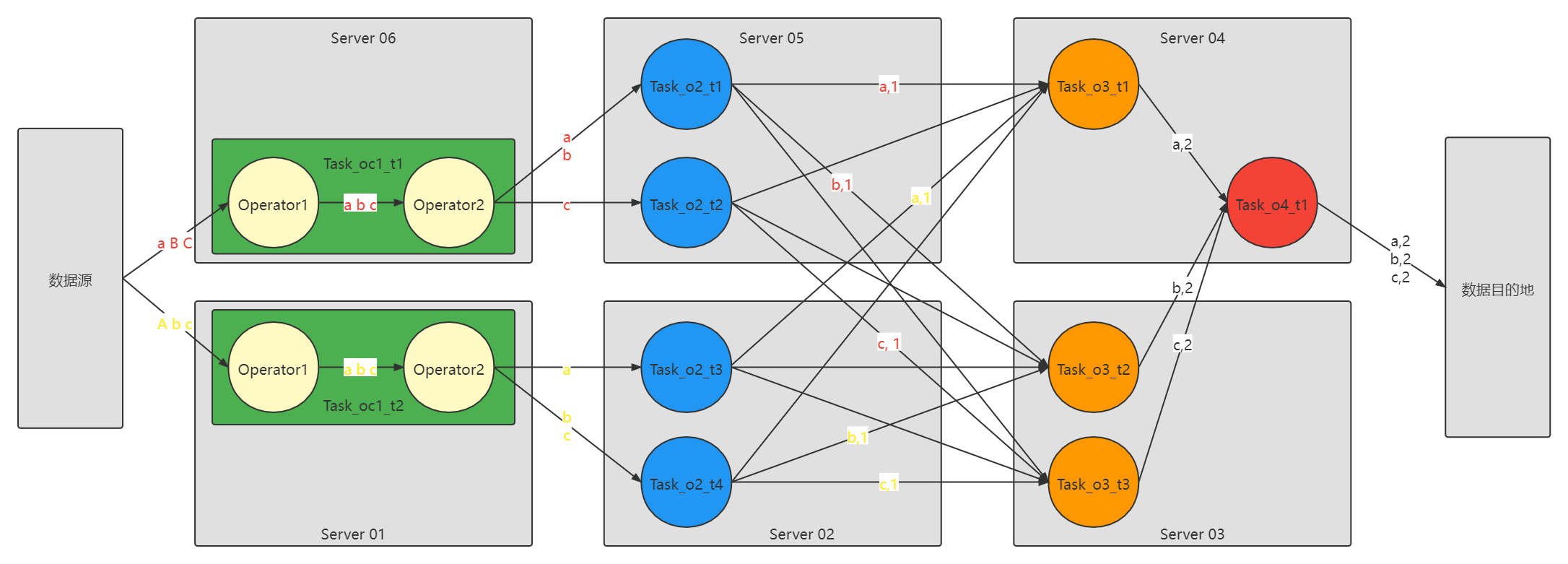
图中的 o: Operator, oc 表示 OperatorChain, t 表示 Task
图中的 圆圈 就是一个 Task,绿色的是 Task,只不过是包含两个 Operator, 箭头是数据流, Task 是预先启动不转移位置的,数据流中的数据是流动的
OperatorChain 可以理解成类似于 Spark 中的 Stage
OperatorChain 包含了多个 Operator,基于并行度 并行运行成多个 Task Stage 包含了多个 算子,其实包含了多个 RDD, Stage 中的 Task 数量取决于 这个 Stage 的 最后一个 RDD 的分区数量。这个 stage 中的 RDD 的都是一样的- 1
- 2
具体见代码
-
相关阅读:
读《DevOps实践指南》有感
html css制作正六边形
项目管理具体是做什么的?
C++笔记之关于函数名前的取址符
如何将PDF设置为只读?
《面试1v1》List
使用Nginx后如何在web应用中获取用户ip及原理解释
pg服务-配置文件管理
面向对象语言的三大特征
Python爬虫之Js逆向案例(9)-企ming科技之webpack
- 原文地址:https://blog.csdn.net/luoyepiaoxue2014/article/details/128078969