-
Linux-Hadoop集群测试
一、通过UI界面查看Hadoop运行状态
Hadoop集群正常启动后,它默认开放了两个端口
9870和8088,分别用于监控HDFS集群和YARN集群。通过UI界面可以方便地进行集群的管理和查看,只需要在本地操作系统的浏览器输入集群服务的IP和对应的端口号即可访问。1、查看HDFS集群状态
-
在浏览器里访问
http://master:9870

-
不能通过主机名master加端口
9870的方式,原因在于没有在hosts文件里IP与主机名的映射,现在只能通过IP地址加端口号的方式访问:`http://192.168.1.101:9870
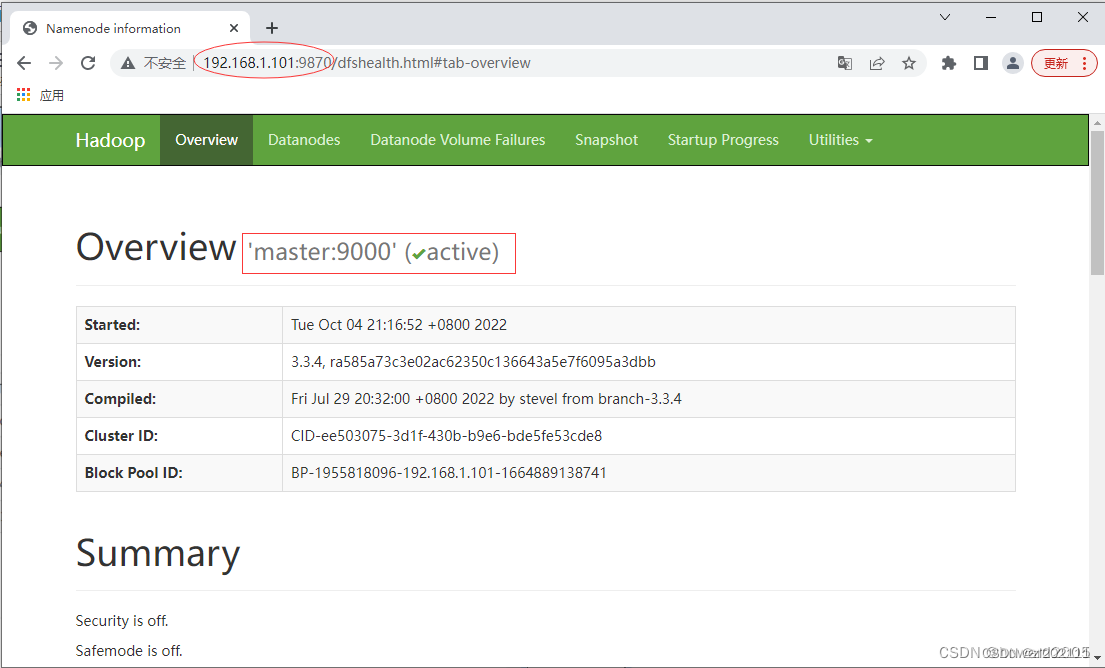
-
修改宿主机的
C:\Windows\System32\drivers\etc\hosts文件,增加hadoop集群主机名与IP地址的映射

-
此时,访问
http://master:9870,从图中可以看出HDFS集群状态显示正常
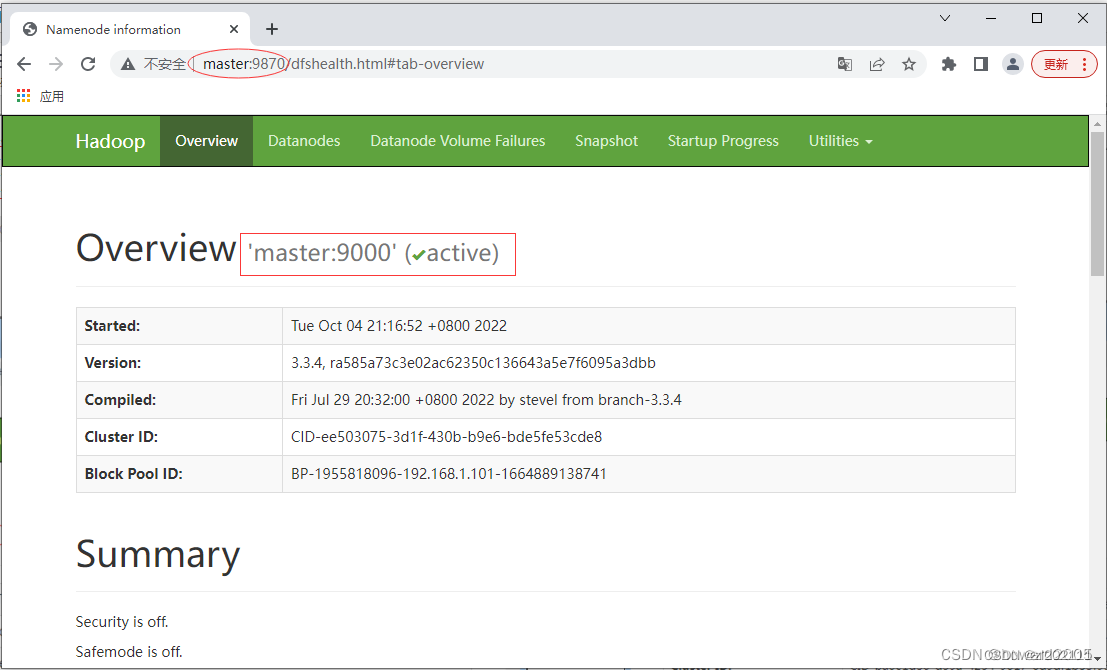
-
单击导航条上的【Datanodes】,查看数据节点信息
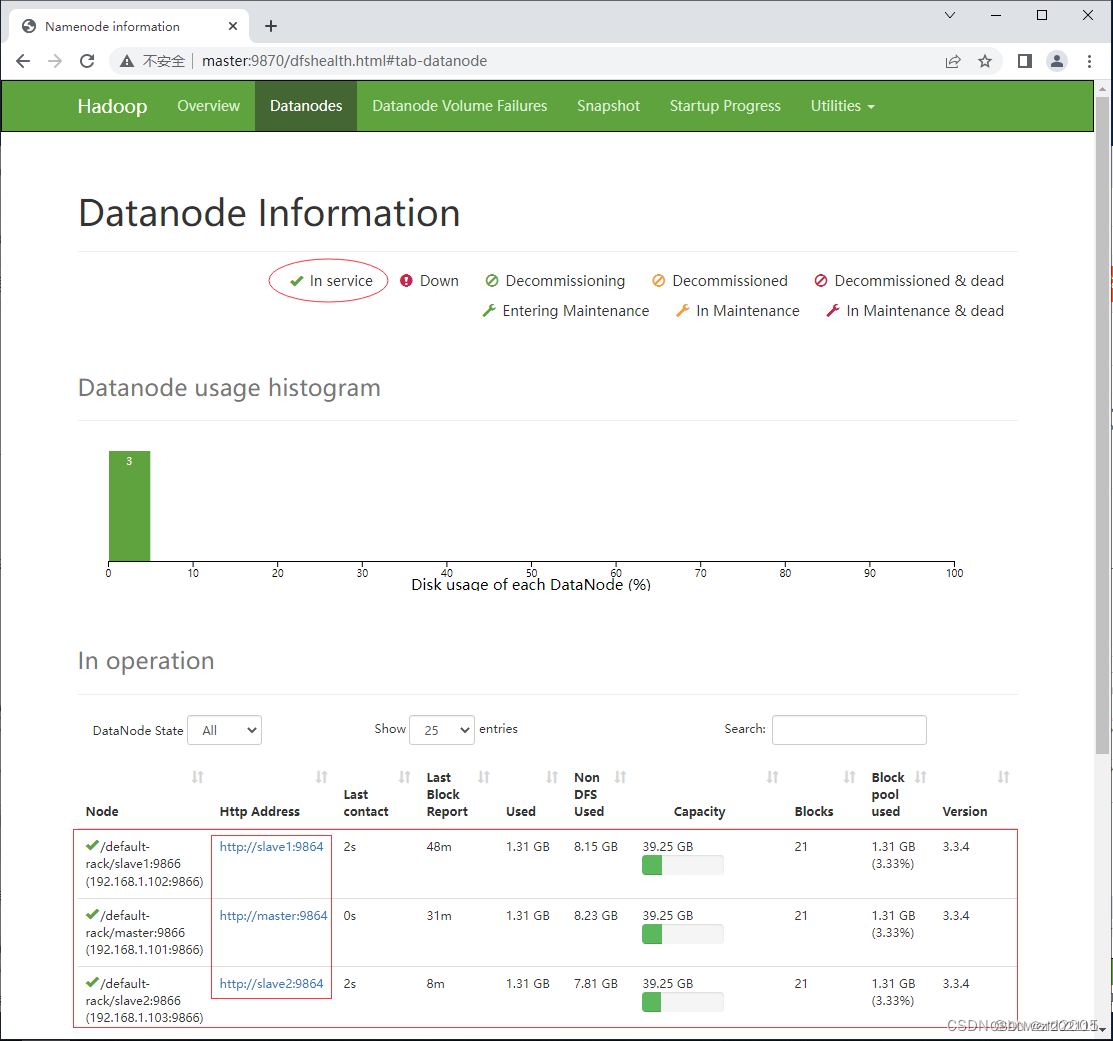
-
访问slave1的数据节点(DataNode)

-
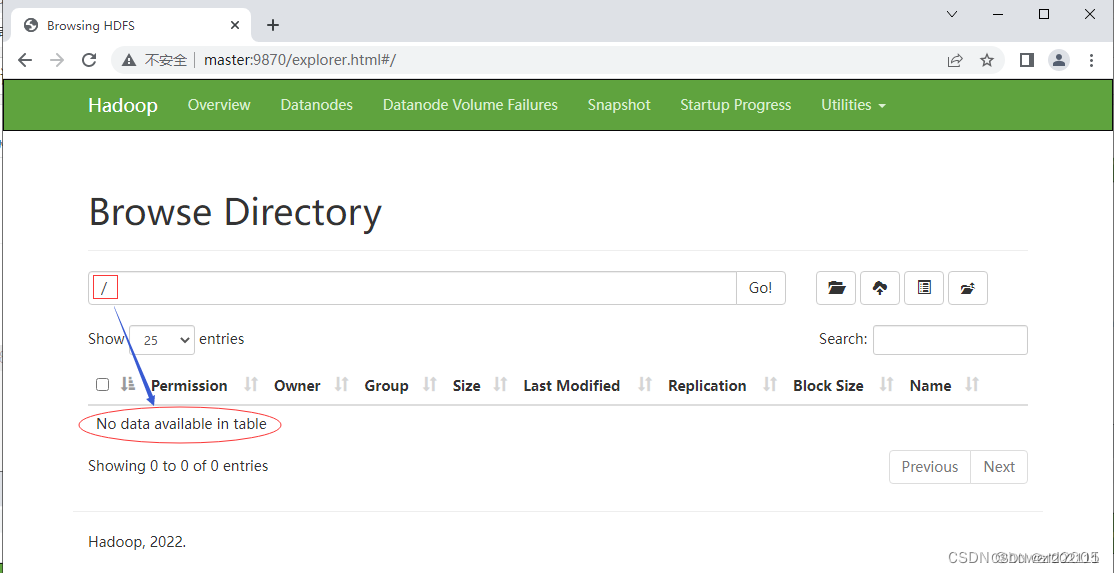
点开【Utilities - 实用工具】下拉菜单,选择【Browse the file system - 浏览文件系统】

-
此时HDFS上没有任何文件或文件夹
-
在HDFS上创建一个目录·BigData·,既可以在WebUI上创建,也可以通过shell命令创建
-
执行命令:·hdfs dfs -mkdir /BigData·
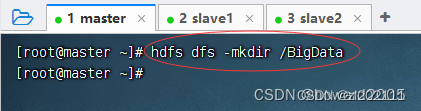
-
在Hadoop WebUI界面查看刚才创建的目录

-
单击【BigData】右边的删除按钮
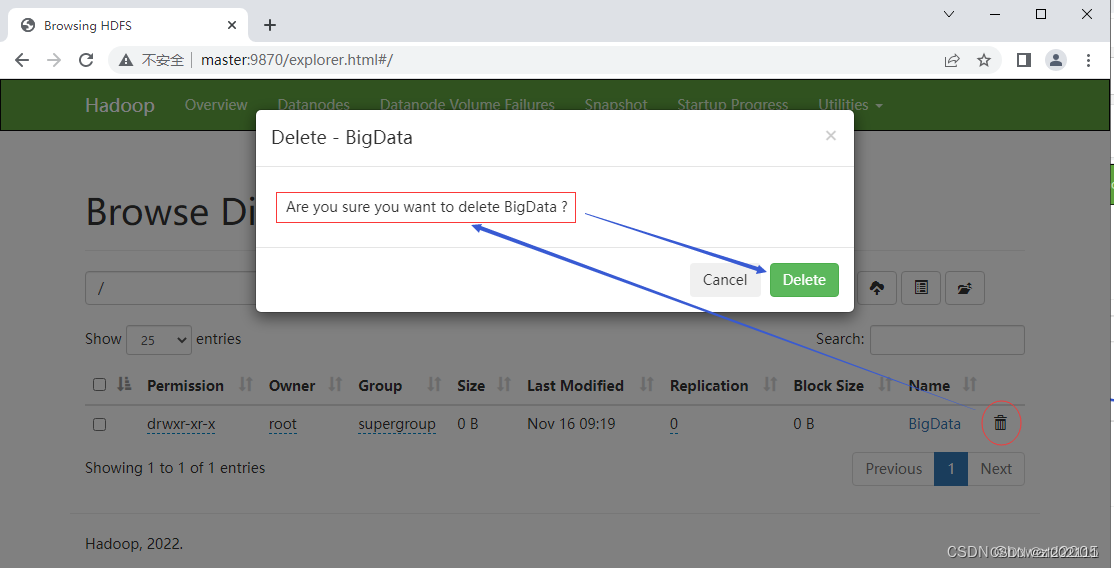
-
单击【Delete】按钮

-
查看四个功能按钮

-
在Hadoop WebUI界面里创建目录
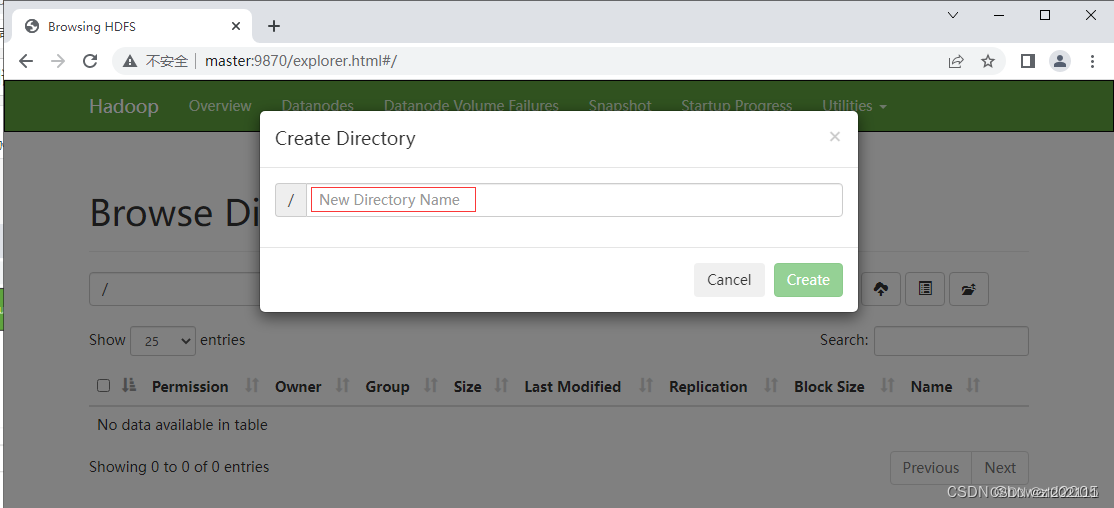
-
在弹出的【Create Directory】对话里输入目录名 -
BigData

单击【Create】按钮

2、查看YARN集群状态
-
访问
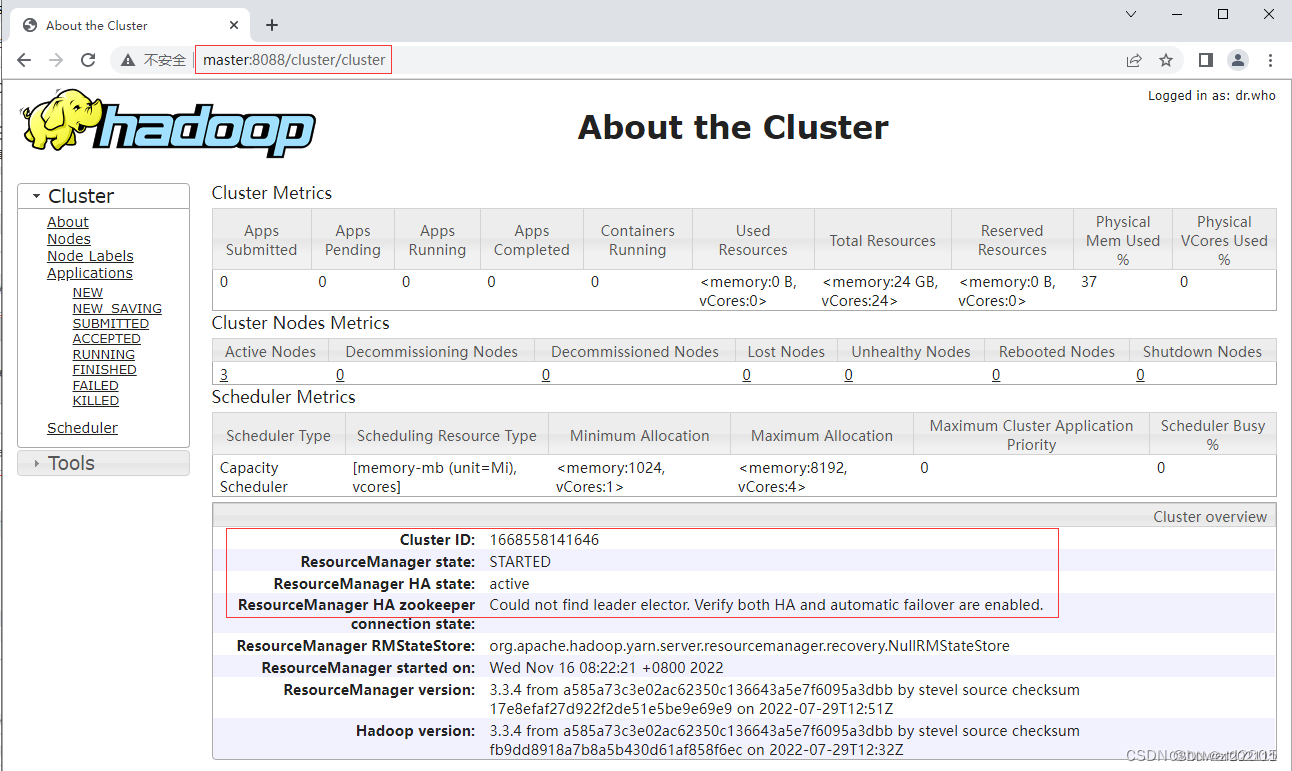
http://master:8088/cluster,从图中可以看出YARN集群状态显示正常

-
单击【About】链接
二、Hadoop集群 —— 词频统计
1、启动Hadoop集群
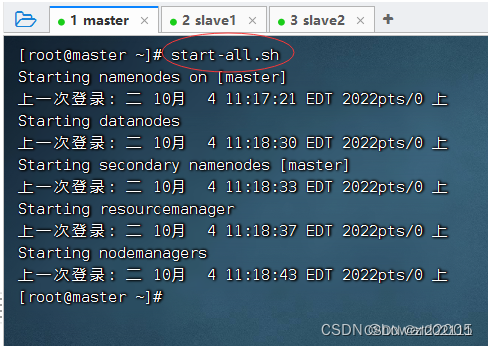
- 在master虚拟机上执行命令:
start-all.sh
2、在虚拟机上准备文件
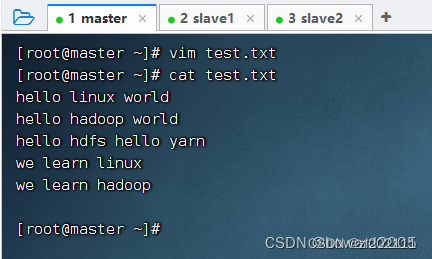
- 在
master虚拟机上创建test.txt文件
3、文件上传到HDFS指定目录
-
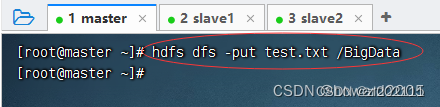
上传
test.txt文件到HDFS的/BigData目录(如果没有就创建目录)
-
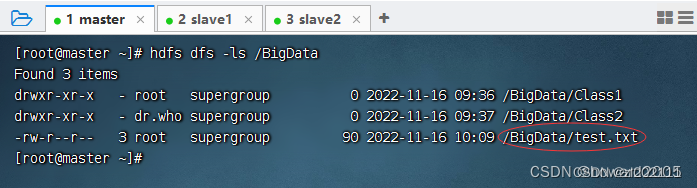
利用HDFS命令查看文件是否上传成功
- 利用Hadoop WebUI查看文件是否上传成功

4、运行词频统计程序的jar包
-
查看Hadoop自带示例的jar包

-
执行命令:
hadoop jar ./hadoop-mapreduce-examples-3.3.4.jar wordcount /BigData/test.txt /wc_result

[root@master mapreduce]# hadoop jar ./hadoop-mapreduce-examples-3.3.4.jar wordcount /BigData/test.txt /wc_result 2022-11-16 10:42:43,067 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at master/192.168.1.101:8032 2022-11-16 10:42:43,852 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1668566449679_0001 2022-11-16 10:42:45,107 INFO input.FileInputFormat: Total input files to process : 1 2022-11-16 10:42:45,555 INFO mapreduce.JobSubmitter: number of splits:1 2022-11-16 10:42:45,904 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1668566449679_0001 2022-11-16 10:42:45,904 INFO mapreduce.JobSubmitter: Executing with tokens: [] 2022-11-16 10:42:46,107 INFO conf.Configuration: resource-types.xml not found 2022-11-16 10:42:46,108 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'. 2022-11-16 10:42:46,567 INFO impl.YarnClientImpl: Submitted application application_1668566449679_0001 2022-11-16 10:42:46,607 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1668566449679_0001/ 2022-11-16 10:42:46,608 INFO mapreduce.Job: Running job: job_1668566449679_0001 2022-11-16 10:42:54,755 INFO mapreduce.Job: Job job_1668566449679_0001 running in uber mode : false 2022-11-16 10:42:54,758 INFO mapreduce.Job: map 0% reduce 0% 2022-11-16 10:42:59,841 INFO mapreduce.Job: map 100% reduce 0% 2022-11-16 10:43:04,876 INFO mapreduce.Job: map 100% reduce 100% 2022-11-16 10:43:05,899 INFO mapreduce.Job: Job job_1668566449679_0001 completed successfully 2022-11-16 10:43:06,021 INFO mapreduce.Job: Counters: 54 File System Counters FILE: Number of bytes read=98 FILE: Number of bytes written=552153 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=190 HDFS: Number of bytes written=60 HDFS: Number of read operations=8 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 HDFS: Number of bytes read erasure-coded=0 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=2619 Total time spent by all reduces in occupied slots (ms)=3007 Total time spent by all map tasks (ms)=2619 Total time spent by all reduce tasks (ms)=3007 Total vcore-milliseconds taken by all map tasks=2619 Total vcore-milliseconds taken by all reduce tasks=3007 Total megabyte-milliseconds taken by all map tasks=2681856 Total megabyte-milliseconds taken by all reduce tasks=3079168 Map-Reduce Framework Map input records=5 Map output records=16 Map output bytes=154 Map output materialized bytes=98 Input split bytes=100 Combine input records=16 Combine output records=8 Reduce input groups=8 Reduce shuffle bytes=98 Reduce input records=8 Reduce output records=8 Spilled Records=16 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=109 CPU time spent (ms)=1680 Physical memory (bytes) snapshot=511000576 Virtual memory (bytes) snapshot=5589139456 Total committed heap usage (bytes)=388497408 Peak Map Physical memory (bytes)=295997440 Peak Map Virtual memory (bytes)=2790174720 Peak Reduce Physical memory (bytes)=215003136 Peak Reduce Virtual memory (bytes)=2798964736 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=90 File Output Format Counters Bytes Written=60- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
说明:作业编号 -
job_1668566449679_0001,读取90个字节,写入60个字节-
查看输出目录
/wc_result,执行命令:hdfs dfs -ls /wc_result

-
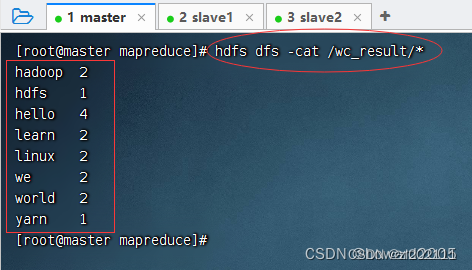
查看词频统计结果,执行命令:
hdfs dfs -cat /wc_result/*
-
再次运行程序,会报错:输出目录已存在

-
删除输出目录之后,可以再次运行程序
5、在HDFS集群UI界面查看结果文件
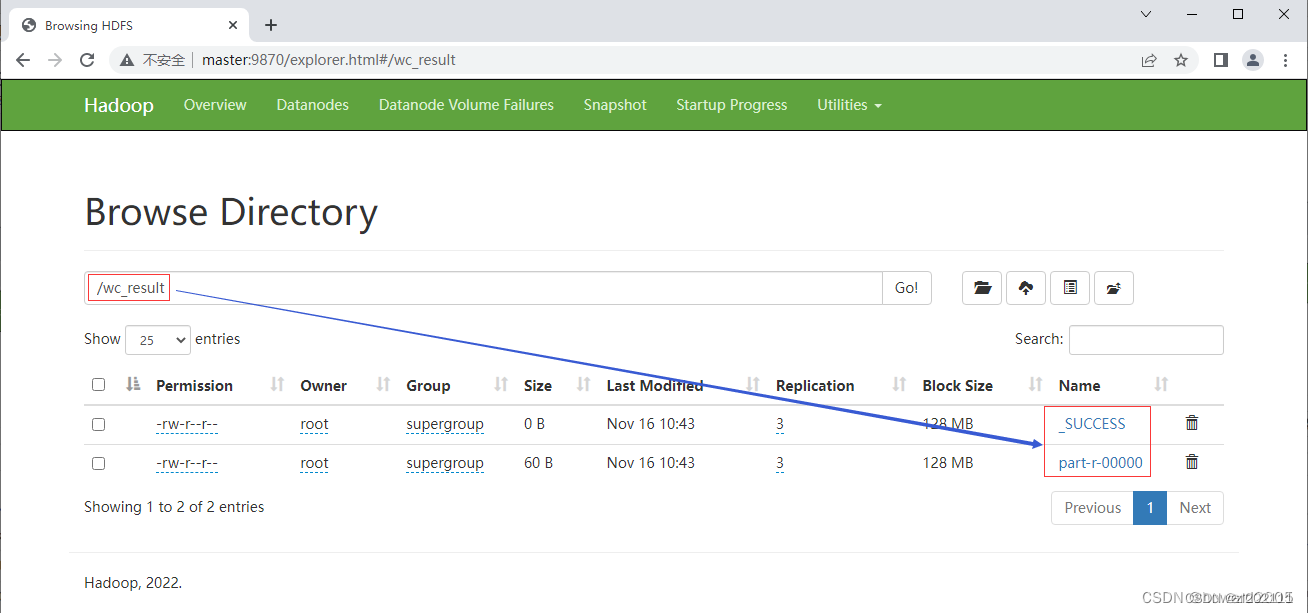
-
在HDFS集群UI界面,查看
/wc_result目录
-
单击结果文件
part-r-00000

-
单击【Download】,下载结果文件到本地

- 利用Notepad++打开结果文件

6、在YARN集群UI界面查看程序运行状态
-
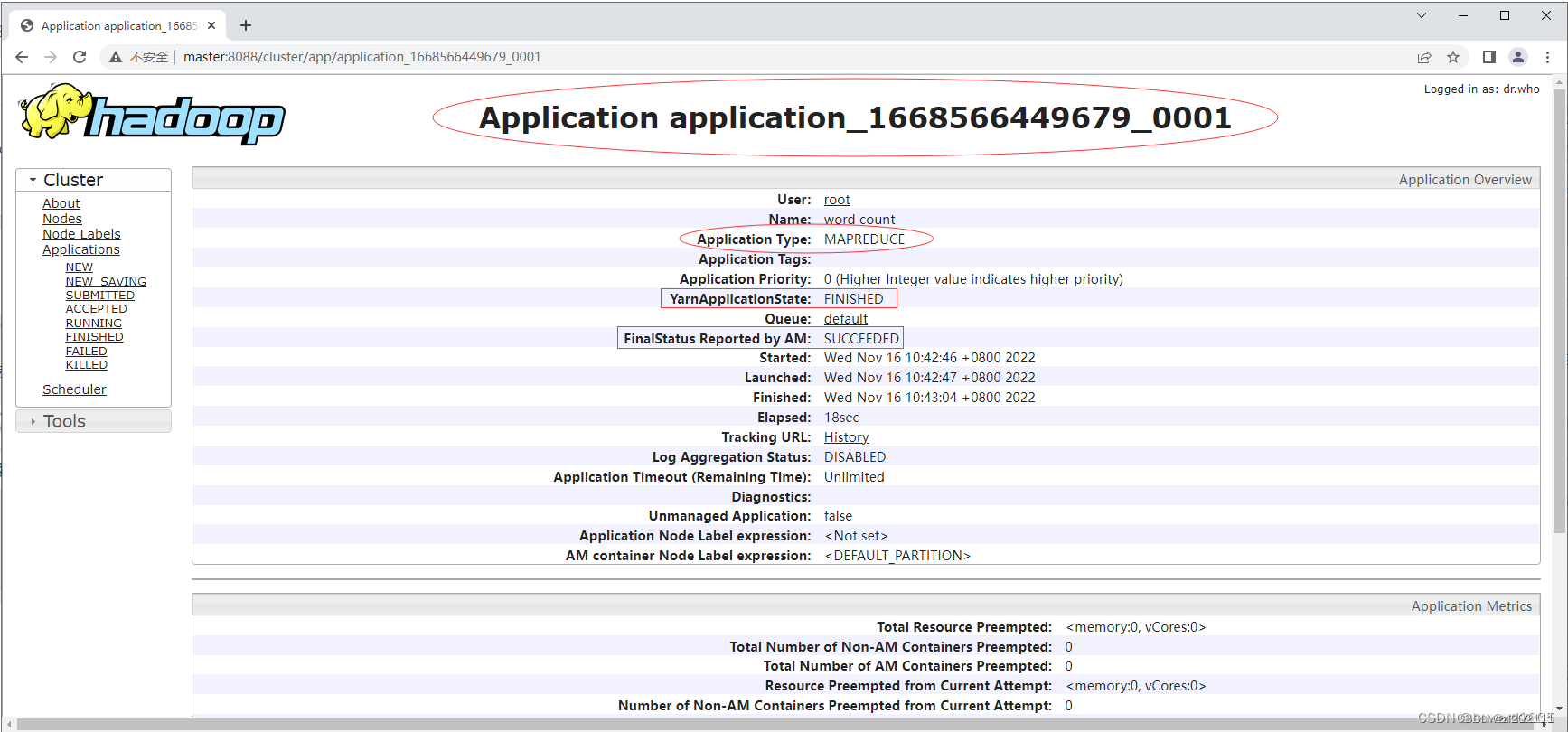
访问
http://master:8088,看到FINISHED和SUCCEEDED

-
单击应用标识
application_1668566449679_0001(注意:每次运行同一个应用,应用标识会发生变化),查看应用的运行详情
-
-
相关阅读:
enote笔记法之附录1——“语法词”(即“关联词”)(ver0.2)
OpenCV的介绍以及常用方法(Java)
HRNet人体关键点检测
[ C++ ] STL_stack(栈)queue(队列)使用及其重要接口模拟实现
【数组】最多能完成排序的块 数学
CommunityToolkit.Mvvm8.1 IOC依赖注入控制反转(5)
MySQL——日志
地图之战争迷雾/地图算法/自动导航(一)
354. 俄罗斯套娃信封问题
哨兵(Sentinel-1、2)数据下载
- 原文地址:https://blog.csdn.net/Pythonwudud/article/details/128120558
