-
Linux4._冯•诺依曼体系结构
早期的 ENIAC 计算机存储容量很小,编程采用线路连接方式,很不方便。1946年,数学家 冯•诺依曼 提出了以存储程序为核心的计算机模型,该计算机模型一直沿用至今。通常称该计算机模型为冯•诺依曼模型(结构),将采用该思想设计的计算机为 冯•诺依曼 计算机。
1. 硬件结构
冯•诺依曼 计算机由运算器、控制器、存储器、输入设备和输出设备组成,其结构如图所示,运算器、控制器常合称为中央处理器(Central Processing Unit, CPU)。
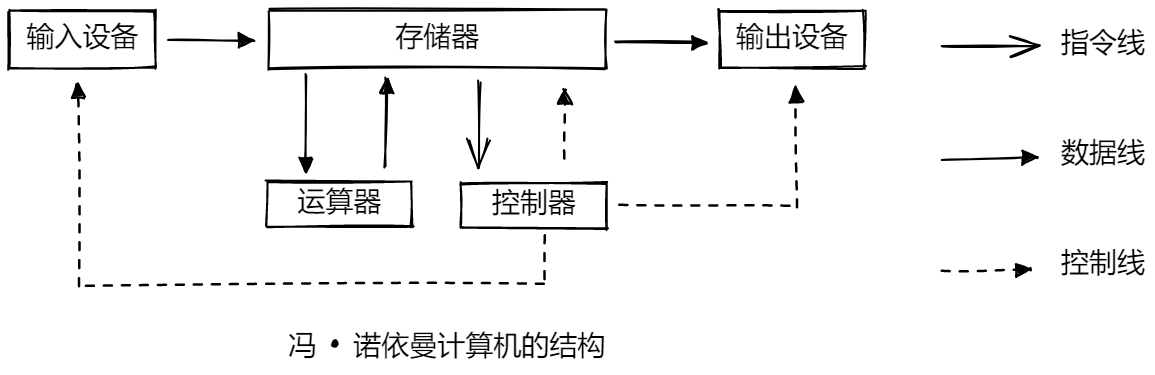
其中,输入设备、输出设备负责程序和数据的输入、输出;
存储器负责存储程序和数据;
运算器负责处理数据;
控制器负责指挥和控制各部件协调工作,以实现程序的预期功能。
由于输入 / 输出与运算器进行数据交换,因此,计算机以运算器为中心。
冯•诺依曼体系结构规定了硬件层面上数据的流向。2. 工作方式
冯•诺依曼计算机采用“存储程序”工作方式。其基本思想是:程序和数据预先存放在存储器中,机器工作时,自动、逐条地从存储器中取出指令并执行。
注意:- 这里的存储器指的是内存
- 不考虑缓存情况,这里的CPU能且只能对内存进行读写,不能访问外设(输入或输出设备)
但是,这里就有疑问了,为什么要将程序和数据预先存放在存储器中?原因很简单:输入设备和输出设备相对于中央处理器来说,速度是非常非常慢的!而存储器比它要快多了。
当向存储器发出操作命令,一定延迟后存储器就可以完成操作;只要连续地向存储器发出操作命令,那么存储器就可以被连续访问。因此,程序和数据存放在存储器中,为计算机自动工作奠定了基础。同时初步解释了,为何可执行程序在运行时,会预先加载到内存中再执行。
我们知道,程序是由若干条指令组成,其类型分为顺序型、转移型,程序的执行顺序由序列中每条指令的类型及执行结果决定。因此其决定了程序执行时,必须逐条执行指令,不能同时执行多条指令,且下条指令地址由当前指令产生。又因程序存放在存储器中,故执行指令时,必须先将指令取到 CPU 中,CPU 分析指令,然后才能执行指令。因此,程序执行过程可以看作一个循环的指令执行过程,循环变量为指令地址。其中,指令执行过程又可分为取指令、分析指令、执行指令三个阶段,当前指令由指令地址取得,并产生下条指令的指令地址。
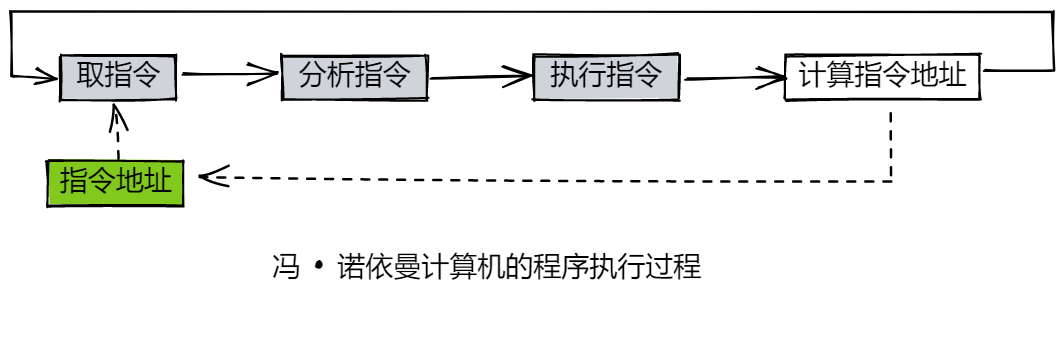
3. 存储器结构
冯•诺依曼计算机中,存储器可以存放程序和数据,因此,计算机中只需一个存储器。根据存储程序工作方式的要求,存储器需要按地址进行访问。由于存储器中无须区分指令和数据(CPU 中才需要区分),因此,存储器可为由定长单元组成的一维空间。通常,存储器地址为线性地址,即地址是连续的非负整数。
理解冯•诺依曼体系结构,注意以下几点:这里的存储器指的是内存 不考虑缓存情况,这里的CPU能且只能对内存进行读写,不能访问外设(输入或输出设备) 外设(输入或输出设备)要输入或者输出数据,也只能写入内存或者从内存中读取。 一句话,所有设备都只能直接和内存打交道- 1
- 2
- 3
- 4
补充:
而在现如今,由于主存与CPU速度不匹配,其存储器结构越来越复杂。不同的存储技术,其访问时间及成本差异较大。通常来说,速度越快,每字节的成本越高。为满足人们普遍需求,只好选择降低成本以满足人们的普遍需求。倘若以磁盘等作为主存,又无法满足CPU 和主存之间的速度差异,由木桶原理可知,这会降低计算机整体效率。
为了平衡其差异与价格,人们想到了一种组织存储器系统的方法,称为 存储器层次结构( memory hierarchy)。如图所示:
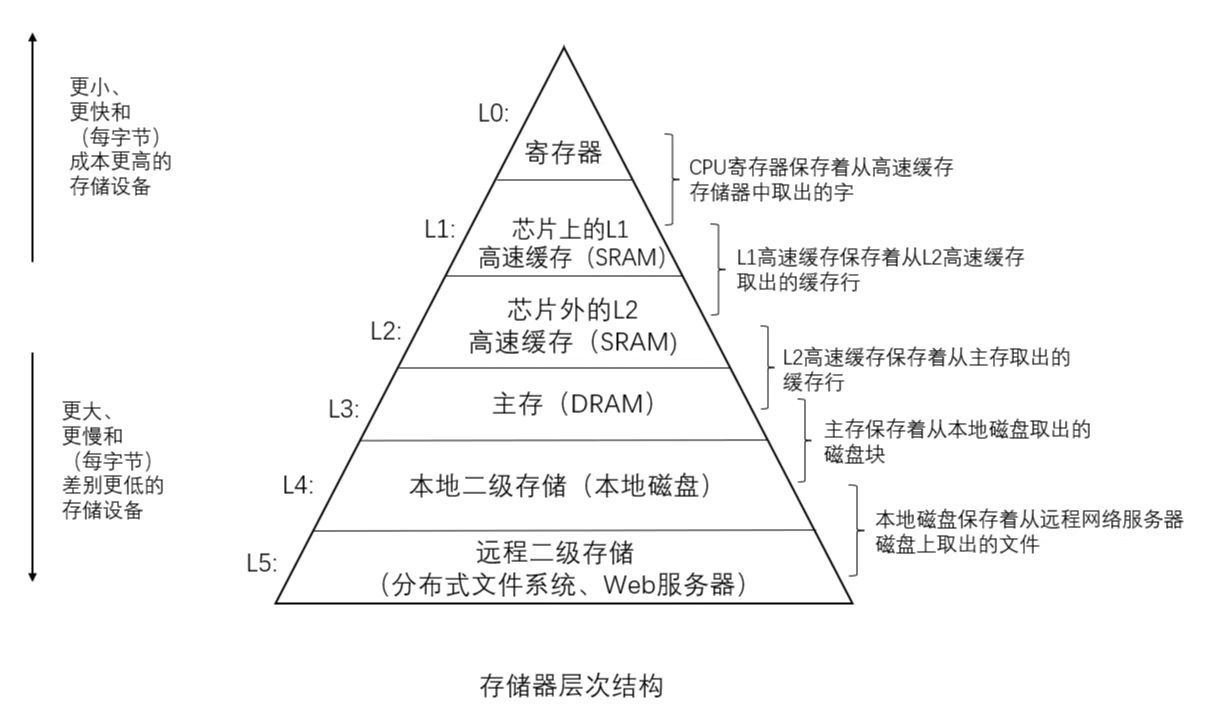
存储器层次结构的中心思想是:对于每个 k, 位于k + 1 层的更快更小的存储设备作为位于k + 1层的更大更慢的存储设备的缓存。 换句话说,层次结构中的每一层都缓存来自较低一层的数据对象。
当程序需要第k + 1层的某个数据对象d时,它首先在当前存储在第k层的一个块中查找。如果 d刚好缓存在第 k 层中, 那么就是我们所说的缓存命中(cache hit)。该程序直接从第 k 层读取数据d,根据存储器层次结构的性质,这要比从第k + 1层读取更快。当缓存不命中时,第k层则从第k + 1层去取出包括d的块。程序则可以像之前一样从第k层读取d了。
补充:
一般而言, 高速缓存(cache, 读作 “cash”) 是一个小而快速的存储设备,它作为存储在更大、也更慢的设备中的数据对象的缓冲区域。 使用高速缓存的过程称为缓存( caching, 读作“cashing”)。为解决主存储器与处理器速度不匹配而生。
早期计算机系统的存储器层次结构只有三层 :CPU 寄存器、DRAM 主存储器和磁盘存储。不过,由于 CPU 和主存之间逐渐增大的差距,系统设计者被迫在 CPU 寄存器文件和主存之间插入了一个小的 SRAM高速缓存存储器, 称为 L1 高速缓存(一级缓存)。L1高速缓存的访问速度几乎和寄存器一样快。随着 CPU 和主存之间的性能差距不断增大,系统设计者在 L1 高速缓存和主存之间又插人了一个更大的高速缓存,称为 L2 高速缓存。有些现代系统还包括有一个更大的高速缓存,称为 L3 高速缓存,在存储器层次结构中,它位于 L2 高速缓存和主存之间。4. 局部性原理
不过,依据上文我们容易产生另一个疑问:每一层的容量是递增的,那么对于高层来说,存储数据少,意味着每一层命中的概率并不高。同时,各层存储之间的速度差异,CPU要高速工作,我们希望CPU需要的数据更多的就在L1里面以提高命中率,不希望更多的跑到下面内存乃至磁盘里面去找。这样花更多的时间效率还能高吗?
这里就不得不提到局部性原理(principle of locality):指CPU访问存储器时,无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小的连续区域中。所以当CPU获取某一数据时,内存可以将该数据之后的数据一同加载进来。
局部性通常有两种不同的形式 :
**时间局部性:**如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。所以数据在寄存器被计算完成后,将会放入告诉缓存中。
**空间局部性:**如果一个存储器位置被引用了一次, 那么程序很可能在不远的将来引用附近的一个存储器位置。一个编写良好的计算机程序常常具有良好的局部性( locality)。也就是说,它们倾向于引用邻近于其他最近引用过的数据项的数据项,或者最近引用过的数据项本身。 这种倾向性,对硬件和软件系统的设计和性能都有着极大的影响。
以下列代码为例,理解空间局部性
#include#include using namespace std; #define ROW 10000 #define COL 100000 int main() { int(*grid)[COL] = new int[ROW][COL]; clock_t start, end; start = clock(); int sum = 0; for (int i = 0; i < ROW; i++) { for (int j = 0; j < COL; j++) { sum += grid[i][j]; } } end = clock(); cout << "用时1:" << (double)end - start << endl;; start = clock(); for (int j = 0; j < COL; j++) { for (int i = 0; i < ROW; i++) { sum += grid[i][j]; } } end = clock(); cout << "用时2:" << (double)end - start << endl; delete[]grid; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
无论测试多少次,行遍历一直要比列遍历用时少的多。
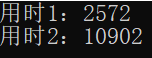
对于行维度来说,在空间上具有良好的空间局部性原理。
但是对于列维度来说(以列序为主序遍历),意味着每访问一个元素,就要跳过COL个元素才能访问下一个,这种情况下没有良好的空间局部性。所以在遍历时出现了明显的性能差异。5. 实例分析
请解释,从你登录上QQ开始和某位朋友聊天开始,数据的流动过程。 从你打开窗口,开始给他发消息,到他的收到消息之后的数据流动过程。如果是在QQ上发送文件呢?
- 发送消息
当你发送消息时,先通过键盘这个输入设备键入消息到内存中,内存将数据加载到CPU中处理(封包,加密等处理),CPU处理完后又加载到内存中,内存中的数据又加载到显示器让你看到,同时又输出到网卡,此时显示器与网卡均作为输出设备。
数据经过网络来到朋友的网卡,此时网卡担任输入设备,将数据加载到内存中,经过内存来到CPU处理(解包,解密等),CPU处理完后数据流向内存,并最终输出到显示器上,此时你的朋友就收到了你的消息。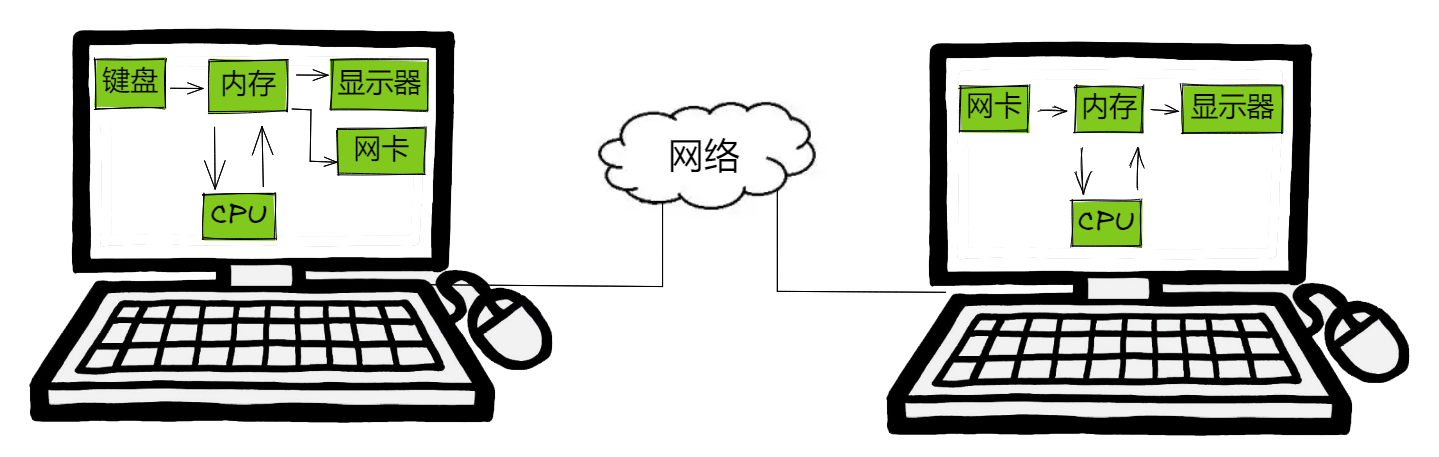
- 发送文件
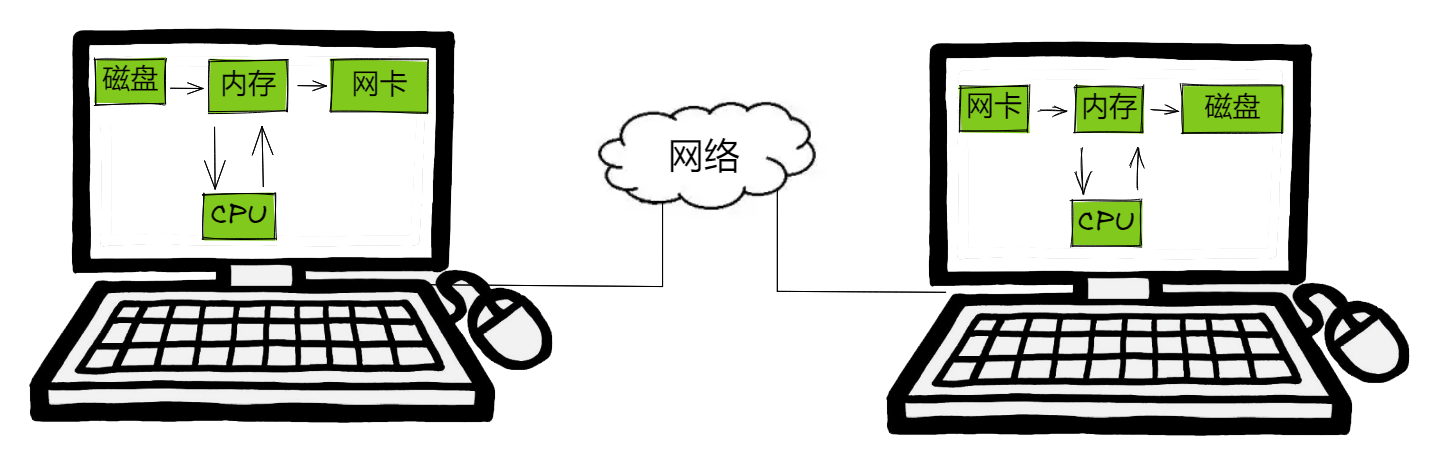
与上述发送消息类似,不过发送文件时,自己的输入设备为磁盘,朋友的输出设备也是磁盘。
补充
事实上,某些设备既可以是输出设备也可以是输入设备。比如上述的网卡。
关于冯•诺依曼体系中存储器指的是内存,不考虑缓存。上述缓存内容仅作补充介绍。
外设(输入或输出设备)要输入或者输出数据,也只能写入内存或者从内存中读取。
一句话,所有设备都只能直接和内存打交道。
可以是输出设备也可以是输入设备。比如上述的网卡。
关于冯•诺依曼体系中存储器指的是内存,不考虑缓存。上述缓存内容仅作补充介绍。
外设(输入或输出设备)要输入或者输出数据,也只能写入内存或者从内存中读取。
一句话,所有设备都只能直接和内存打交道。
以上就是关于冯•诺依曼体系结构的简单说明,欢迎各位批评指正!
-
相关阅读:
vue3按钮隐藏显示元素
spring/springboot/sprinngMVC
Go——二、变量和数据类型
问题解析:为什么数组下标从0 开始而不是 1 ?
Python 爬虫入门:常见工具介绍
MyBatis Plus详细教程
Linux 线程:线程同步、生产者消费者模型
Centos安装RabbitMQ超详细(必须收藏)
数据备份必备知识与策略设计方法
计算机系统基础实验——数据的机器级表示(条件表达式 x?y:z)
- 原文地址:https://blog.csdn.net/qq_56780490/article/details/128143369
