-
Java通过Lambda表达式根据指定字段去除重复数据(集合去重)
这里博主给大家封装好了一个工具类,里面有两个方法。
- 方法一:可以根据指定字段去除重复数据。
- 方法二:可以获取到重复的数据。
大家在使用过程中直接拷贝下方代码在要去重的类中调用即可。
package com.jzmy.specialist.entity.util; import java.util.Map; import java.util.concurrent.ConcurrentHashMap; import java.util.function.Function; import java.util.function.Predicate; /** * 操作去重工具类 * @author mengzhichao * @create 2022-11-02-15:15 */ public class DeduplicationUtil { /** * 自定义函数去重(采用 Predicate函数式判断,采用 Function获取比较key) * 内部维护一个 ConcurrentHashMap,并采用 putIfAbsent特性实现 * * @param keyExtractor * @param* @return */ public static <T> Predicate<T> distinctByKey(Function<? super T, ?> keyExtractor) { Map<Object,Boolean> seen = new ConcurrentHashMap<>(); return t -> seen.putIfAbsent(keyExtractor.apply(t), Boolean.TRUE) == null; } /** * 只获取重复的数据 * * @param keyExtractor * @param* @return */ public static <T> Predicate<T> distinctNotByKey(Function<? super T, ?> keyExtractor) { Map<Object,Boolean> seen = new ConcurrentHashMap<>(); return t -> seen.putIfAbsent(keyExtractor.apply(t), Boolean.TRUE) != null; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
导入这个工具类后怎么使用呢?我们接着往下看。
方法一根据指定字段去重
package com.jzmy.specialist.entity.util; import java.util.ArrayList; import java.util.List; import java.util.stream.Collectors; /** * @author mengzhichao * @create 2022-12-02-10:46 */ public class Test { public static class Student{ private String id; private String name; public String getId() { return id; } public void setId(String id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } } public static void main(String[] args) { List<Student> list =new ArrayList<>(); Student student =new Student(); student.setId("1"); student.setName("张三"); list.add(student); Student student2 =new Student(); student2.setId("1"); student2.setName("张三"); list.add(student2); Student student3 =new Student(); student3.setId("1"); student3.setName("李四"); list.add(student3); Student student4 =new Student(); student4.setId("2"); student4.setName("王五"); list.add(student4); System.out.println("未去重前list有几条数据:"+list.size()); List<Student> rstList = list.stream().filter(DeduplicationUtil.distinctByKey(Student::getId)).collect(Collectors.toList()); System.out.println("未去重前list有几条数据:"+rstList.size()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
List rstList = list.stream().filter(DeduplicationUtil.distinctByKey(Student::getId)).collect(Collectors.toList());
- 这段代码的意思是通过stream的filter方法进行过滤,过滤Id不相同的数据并通过collect方法收集为一个新的集合。
代码运行结果
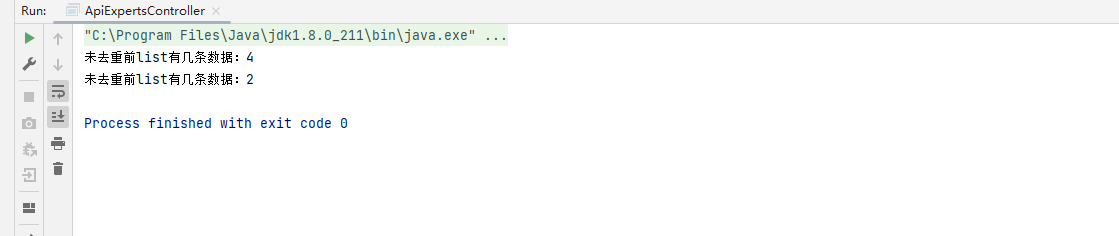
方法二获取重复数据
package com.jzmy.specialist.entity.util; import java.util.ArrayList; import java.util.List; import java.util.stream.Collectors; /** * @author mengzhichao * @create 2022-12-02-10:46 */ public class Test { public static class Student{ private String id; private String name; public String getId() { return id; } public void setId(String id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } } public static void main(String[] args) { List<Student> list =new ArrayList<>(); Student student =new Student(); student.setId("1"); student.setName("张三"); list.add(student); Student student2 =new Student(); student2.setId("1"); student2.setName("张三"); list.add(student2); Student student3 =new Student(); student3.setId("1"); student3.setName("李四"); list.add(student3); Student student4 =new Student(); student4.setId("2"); student4.setName("王五"); list.add(student4); System.out.println("集合中的全部数据"); for (int i=0;i<list.size();i++){ System.out.println(list.get(i).getId()); System.out.println(list.get(i).getName()); } List<Student> rstList = list.stream().filter(DeduplicationUtil.distinctNotByKey(Student::getId)).collect(Collectors.toList()); System.out.println("集合中的重复数据"); for (int i=0;i<rstList.size();i++){ System.out.println(rstList.get(i).getId()); System.out.println(rstList.get(i).getName()); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
List rstList = list.stream().filter(DeduplicationUtil.distinctNotByKey(Student::getId)).collect(Collectors.toList());
- 这个和上面那个方法原理一样的只是换了一个调用方法而已。
代码运行结果
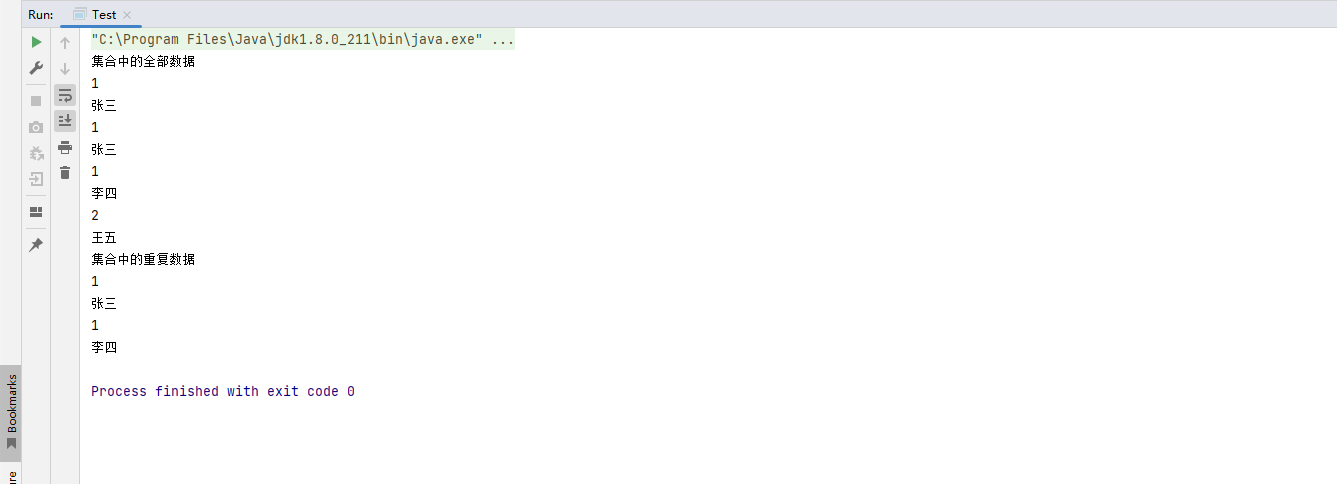
-
相关阅读:
【开源打印组件】vue-plugin-hiprint初体验
一个java文件的JVM之旅 | 京东物流技术团队
策略验证_指标买点分析技法_运用boll布林线指标选择买点
LeetCode刷题(python版)——Topic70. 爬楼梯
C# 第五章『面向对象』◆第8节:接口
VRRP简介
MAC配置VScode中C++项目debug环境
vscode远程调试Linux CUDA程序
Linux JumpServer 堡垒机远程访问
API阶段测试
- 原文地址:https://blog.csdn.net/weixin_45692705/article/details/128144013
