-
c程序从编译开始到运行结束的过程
重温c语言
我们在linux平台下建立一个a.c文件,程序很简单,显示输出Please input your name:,然后让我们输入名字,最后调用了一个子函数输出hello,我们的名字
#includevoid hello(char * name); int main() { char name[16]={0}; printf("Please input your name:"); gets(name); hello(name); return 0; } void hello(char * name) { printf("hello,%s\n",name); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
从.c文件到可执行文件
gcc的编译过程
预处理(Preprocessing), 编译(Compilation), 汇编(Assemble), 链接(Linking)- 1
- 2
- 3
- 4
gcc编译C语言主要用到以下几个程序:C编译器gcc、汇编器as、链接器ld和二进制转换工具objcopy
gcc选项总结:
-E 只激活预处理,这个不生成文件,你需要把它重定向到一个输出文件里面 -S 编译到汇编语言不进行汇编和链接 -c 编译到目标代码 -o 文件输出到 文件 -static 此选项对生成的文件采用静态链接 -g 生成调试信息。GNU 调试器可利用该信息 -shared 此选项将尽量使用动态库,所以生成文件比较小,但是需要系统由动态库 -O0 -O1 -O2 -O3 编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高 -w 不生成任何警告信息 -Wall 生成所有警告信息(默认生成)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
1.预处理(Preprocessing)
由编译器完成,将所有的#include头文件以及宏定义替换成其真正的内容
gcc的预处理是预处理器cpp来完成的我们可以用以下指令对.c文件进行预处理:
gcc -E a.c -o a.i- 1
或者
cpp a.c -o a.i- 1
-o:代表输出到指定文件
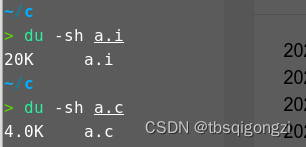
可以看到文件预处理后变大了很多
打开a.i文件发现是把我们用的头文件stdio.h所涉及的其他头文件以及宏定义,变量都引入了进来
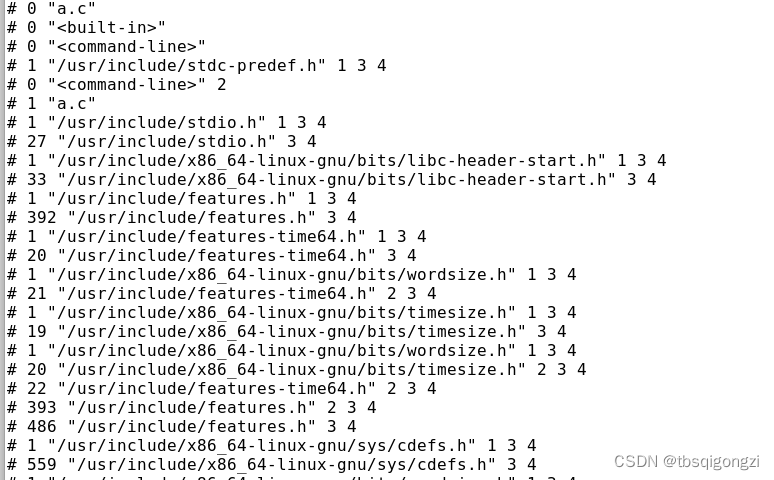

可以看到文件最后才是我们写的c代码,实际上我们能直接使用printf等函数是因为我们引用了一个头文件,使得我们可以少写很多代码,就相当于自己事先把一个自定义的函数写到一个文件里,下次再使用直接引用这个文件就可以了,而不用自己再把以前定义好的函数再抄一遍了,我们用的gcc编译器的预处理就帮助我们省略了抄定义好的函数,变量等东西这一步2.编译(Compilation)
由编译器完成,将经过预处理之后的程序转换成特定汇编代码的过程, 编译的命令如下:
gcc -S a.i -o a.s- 1

执行这一步程序会出现一个warning,警告:函数gets的隐式声明;你是说“fgets”吗?
为什么会出现这个呢,这是因为gcc编译器太强了,检测出我们使用了gets函数,然后说gets函数很危险,建议用fgets函数,这个问题在后面会讲我们先来查看一下编译好的汇编代码
.file "a.c" .text .section .rodata .LC0: .string "Please input your name:" .text .globl main .type main, @function main: .LFB0: .cfi_startproc endbr64 pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 subq $32, %rsp movq %fs:40, %rax movq %rax, -8(%rbp) xorl %eax, %eax movq $0, -32(%rbp) movq $0, -24(%rbp) leaq .LC0(%rip), %rax movq %rax, %rdi movl $0, %eax call printf@PLT leaq -32(%rbp), %rax movq %rax, %rdi movl $0, %eax call gets@PLT leaq -32(%rbp), %rax movq %rax, %rdi call hello movl $0, %eax movq -8(%rbp), %rdx subq %fs:40, %rdx je .L3 call __stack_chk_fail@PLT .L3: leave .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size main, .-main .section .rodata .LC1: .string "hello,%s\n" .text .globl hello .type hello, @function hello: .LFB1: .cfi_startproc endbr64 pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 subq $16, %rsp movq %rdi, -8(%rbp) movq -8(%rbp), %rax movq %rax, %rsi leaq .LC1(%rip), %rax movq %rax, %rdi movl $0, %eax call printf@PLT nop leave .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE1: .size hello, .-hello .ident "GCC: (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0" .section .note.GNU-stack,"",@progbits .section .note.gnu.property,"a" .align 8 .long 1f - 0f .long 4f - 1f .long 5 0: .string "GNU" 1: .align 8 .long 0xc0000002 .long 3f - 2f 2: .long 0x3 3: .align 8 4:- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
这是AT&T汇编语言,初学者可能看上去很复杂,暂且不看
接着往下走3.汇编(Assemble)
由汇编器完成,汇编过程将上一步的汇编代码转换成机器码(machine code),这一步产生了二进制的目标文件(.o文件)(ELF文件), gcc汇编过程通过as命令完成
gcc -c a.s -o a.o- 1
或者
as a.s -o a.o- 1
查看一下a.o

这已经把我们的汇编语言变成二进制目标代码(.o文件)了
.o文件又称对象文件,是可执行文件,是可重定向文件的一种,通常以ELF格式保存,里面包含了对各个函数的入口标记,描述,当程序要执行时还需要链接(link).链接就是把多个.o文件链成一个可执行文件。
中间插一段elf文件的内容番外篇1–ELF文件
ELF文件格式是linux下可执行文件的一种格式
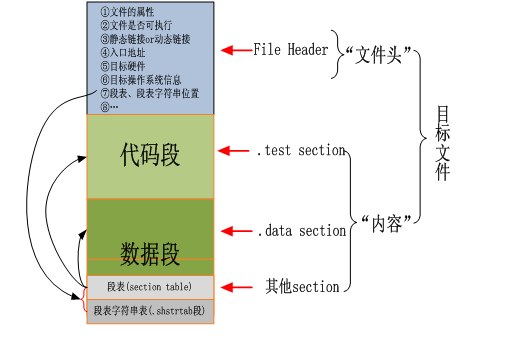
几种类型的ELF文件:
- 可重定位文件(Relocatable File):用户和其他目标文件一起创建可执行文件或者共享目标文件,例如lib*.a文件。
- 可执行文件(Executable File):用于生成进程映像,载入内存执行,例如编译好的可执行文件a.out。
- 共享目标文件(Shared Object File):用于和其他共享目标文件或者可重定位文件一起生成elf目标文件或者和执行文件一起创建进程映像,例如lib*.so文件。
- 核心转储文件(Core Dump File),当进程意外终止时,系统可以将该进程的地址空间内容及终止时的一些其他信息转储到核心转储文件,如linux下的coredump文件。
ELF文件作用:
ELF文件参与程序的连接(建立一个程序)和程序的执行(运行一个程序),所以可以从不同的角度来看待elf格式的文件:
- 如果用于编译和链接(可重定位文件),则编译器和链接器将把elf文件看作是节头表描述的节的集合,程序头表可选。
- 如果用于加载执行(可执行文件),则加载器则将把elf文件看作是程序头表描述的段的集合,一个段可能包含多个节,节头表可选。
- 如果是共享文件,则两者都含有。
ELF文件总体组成:
elf文件头描述elf文件的总体信息。包括:系统相关,类型相关,加载相关,链接相关。
- 系统相关表示:elf文件标识的魔术数,以及硬件和平台等相关信息,增加了elf文件的移植性,使交叉编译成为可能。
- 类型相关就是前面说的那个类型。
- 加载相关:包括程序头表相关信息。
- 链接相关:节头表相关信息。
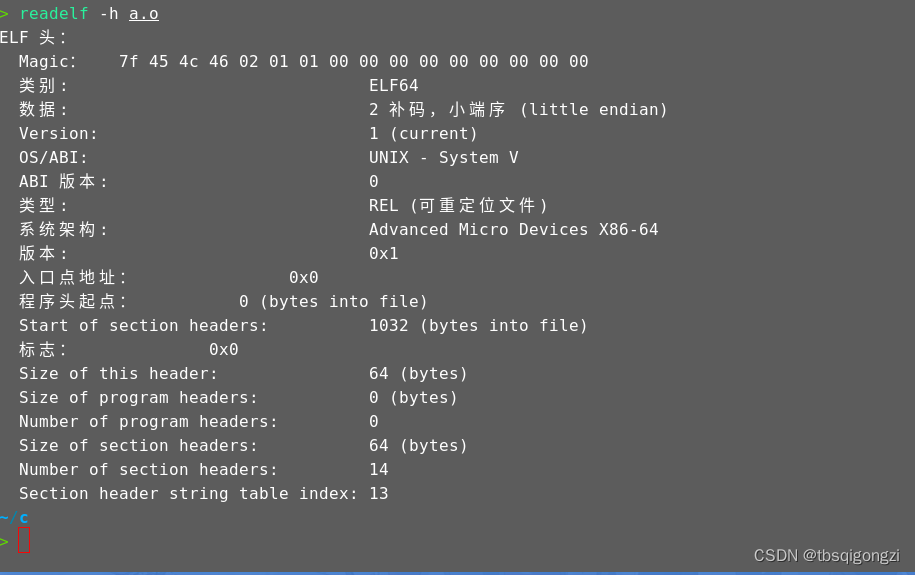
可以用readelf命令来查看elf文件信息
如查看elf文件头信息readelf -h a.o- 1
readelf命令解析
-a --all 显示全部信息,等价于 -h -l -S -s -r -d -V -A -I. -h --file-header 显示elf文件开始的文件头信息. -l --program-headers --segments 显示程序头(段头)信息(如果有的话)。 -S --section-headers --sections 显示节头信息(如果有的话)。 -g --section-groups 显示节组信息(如果有的话)。 -t --section-details 显示节的详细信息(-S的)。 -s --syms --symbols 显示符号表段中的项(如果有的话)。 -e --headers 显示全部头信息,等价于: -h -l -S -n --notes 显示note段(内核注释)的信息。 -r --relocs 显示可重定位段的信息。 -u --unwind 显示unwind段信息。当前只支持IA64 ELF的unwind段信息。 -d --dynamic 显示动态段的信息。 -V --version-info 显示版本段的信息。 -A --arch-specific 显示CPU构架信息。 -D --use-dynamic 使用动态段中的符号表显示符号,而不是使用符号段。 -x--hex-dump= 以16进制方式显示指定段内内容。number指定段表中段的索引,或字符串指定文件中的段名。 -w[liaprmfFsoR] or --debug-dump[=line,=info,=abbrev,=pubnames,=aranges,=macro,=frames,=frames-interp,=str,=loc,=Ranges] 显示调试段中指定的内容。 -I --histogram 显示符号的时候,显示bucket list长度的柱状图。 -v --version 显示readelf的版本信息。 -H --help 显示readelf所支持的命令行选项。 -W --wide 宽行输出。 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
elf文件格式先讲这些,接着往下看
4.链接(Linking)
链接过程实际上是把多个可重定位文件合并成一个可执行文件的过程。这个过程中最重要的两个步骤是符号解析和重定位。所谓的符号解析,就是将符号的定义和引用关联起来,而重定位就是给所有符号和指令添加运行时的地址的过程。
过程
- 确定符号引用关系(符号解析)
- 合并相关 .o 文件(重定位)
- 确定每个符号的地址(重定位)
- 在指令中填入新的地址(重定位)
我们的程序最终是要装载到运行内存中才可以执行的,所以需要规定一种文件格式来确定装载到内存后对应的地址
由链接器完成,链接分为两种:动态链接和静态链接
GCC默认情况下以动态库方式link静态链接
命令
gcc -static a.o -o a- 1
实际是gcc调用了ld链接器,因为程序需要链接很多系统文件,所以这里不推荐使用ld命令链接

这里出现gets函数比较危险,跟编译成汇编时一样的意思,先不管这里,后面再讲
对于静态链接而言,程序链接后的地址其实就是在装载进内存后,程序运行的地址
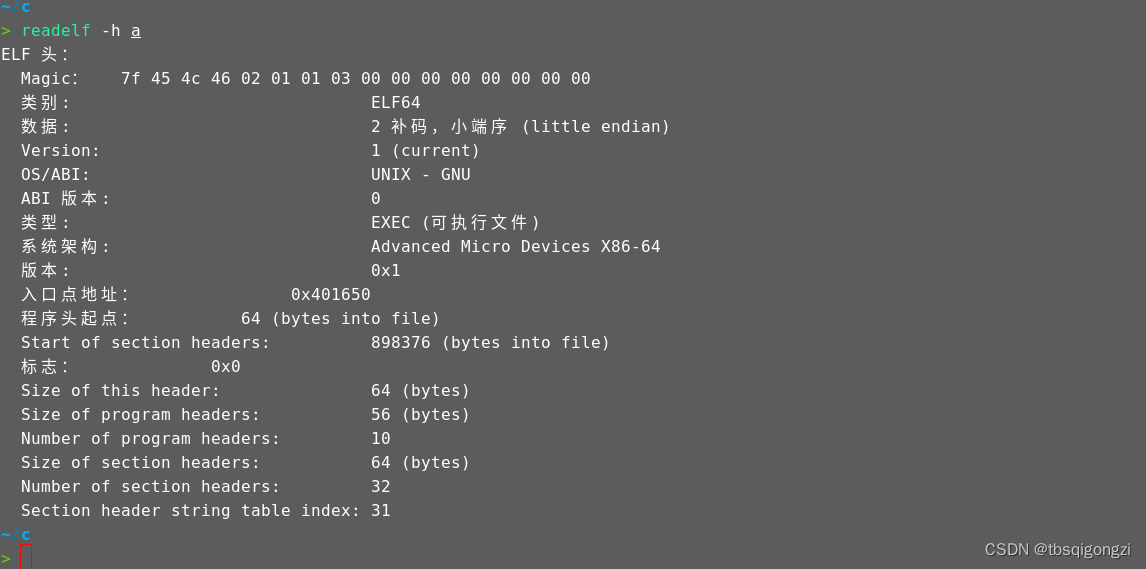

可以看到符号表已经有了地址,符号表在链接时已经重定位,当程序被装载进内存时,运行时所用的虚拟地址就是这个地址动态链接
GCC默认情况下以动态库方式link
gcc a.o -o a- 1

用readelf命令查看一下生成的ELF文件的信息
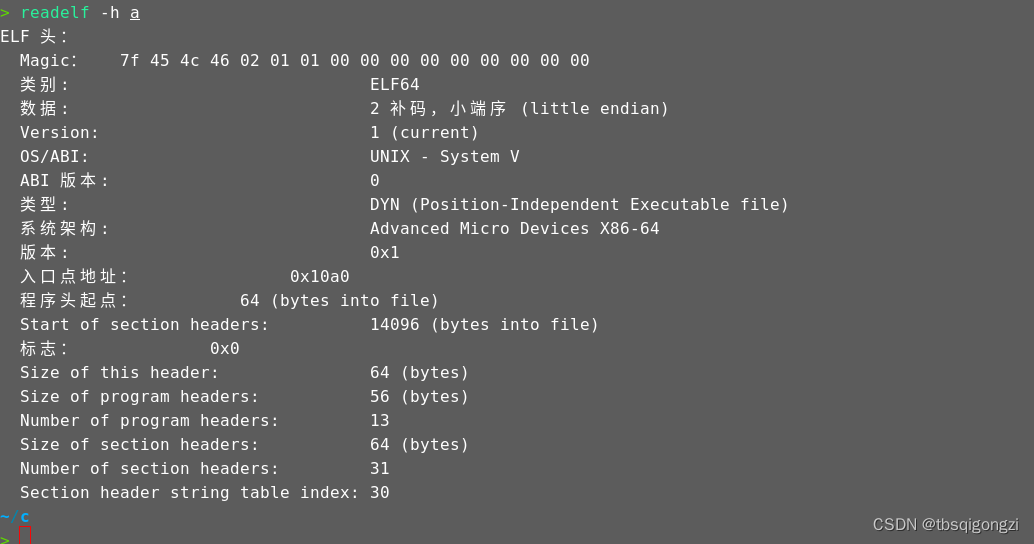

这里符号表的地址只是偏移地址(相对于ELF文件首地址的偏移),而ELF文件的首地址在程序装载进内存时才会分配,而动态符号表(.dynsym)的地址也没有分配,只有在程序运行时才会分配地址,这是动态链接的一个延迟绑定机制
查看程序节头信息会发现动态链接比静态链接多出几个符号表readelf -S a- 1
-
动态链接
There are 31 section headers, starting at offset 0x3710:
节头:
[号] 名称 类型 地址 偏移量
大小 全体大小 旗标 链接 信息 对齐
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .interp PROGBITS 0000000000000318 00000318
000000000000001c 0000000000000000 A 0 0 1
[ 2] .note.gnu.pr[…] NOTE 0000000000000338 00000338
0000000000000030 0000000000000000 A 0 0 8
[ 3] .note.gnu.bu[…] NOTE 0000000000000368 00000368
0000000000000024 0000000000000000 A 0 0 4
[ 4] .note.ABI-tag NOTE 000000000000038c 0000038c
0000000000000020 0000000000000000 A 0 0 4
[ 5] .gnu.hash GNU_HASH 00000000000003b0 000003b0
0000000000000024 0000000000000000 A 6 0 8
[ 6] .dynsym DYNSYM 00000000000003d8 000003d8
00000000000000d8 0000000000000018 A 7 1 8
[ 7] .dynstr STRTAB 00000000000004b0 000004b0
00000000000000af 0000000000000000 A 0 0 1
[ 8] .gnu.version VERSYM 0000000000000560 00000560
0000000000000012 0000000000000002 A 6 0 2
[ 9] .gnu.version_r VERNEED 0000000000000578 00000578
0000000000000040 0000000000000000 A 7 1 8
[10] .rela.dyn RELA 00000000000005b8 000005b8
00000000000000c0 0000000000000018 A 6 0 8
[11] .rela.plt RELA 0000000000000678 00000678
0000000000000048 0000000000000018 AI 6 24 8
[12] .init PROGBITS 0000000000001000 00001000
000000000000001b 0000000000000000 AX 0 0 4
[13] .plt PROGBITS 0000000000001020 00001020
0000000000000040 0000000000000010 AX 0 0 16
[14] .plt.got PROGBITS 0000000000001060 00001060
0000000000000010 0000000000000010 AX 0 0 16
[15] .plt.sec PROGBITS 0000000000001070 00001070
0000000000000030 0000000000000010 AX 0 0 16
[16] .text PROGBITS 00000000000010a0 000010a0
000000000000018e 0000000000000000 AX 0 0 16
[17] .fini PROGBITS 0000000000001230 00001230
000000000000000d 0000000000000000 AX 0 0 4
[18] .rodata PROGBITS 0000000000002000 00002000
0000000000000026 0000000000000000 A 0 0 4
[19] .eh_frame_hdr PROGBITS 0000000000002028 00002028
000000000000003c 0000000000000000 A 0 0 4
[20] .eh_frame PROGBITS 0000000000002068 00002068
00000000000000cc 0000000000000000 A 0 0 8
[21] .init_array INIT_ARRAY 0000000000003da8 00002da8
0000000000000008 0000000000000008 WA 0 0 8
[22] .fini_array FINI_ARRAY 0000000000003db0 00002db0
0000000000000008 0000000000000008 WA 0 0 8
[23] .dynamic DYNAMIC 0000000000003db8 00002db8
00000000000001f0 0000000000000010 WA 7 0 8
[24] .got PROGBITS 0000000000003fa8 00002fa8
0000000000000058 0000000000000008 WA 0 0 8
[25] .data PROGBITS 0000000000004000 00003000
0000000000000010 0000000000000000 WA 0 0 8
[26] .bss NOBITS 0000000000004010 00003010
0000000000000008 0000000000000000 WA 0 0 1
[27] .comment PROGBITS 0000000000000000 00003010
000000000000002b 0000000000000001 MS 0 0 1
[28] .symtab SYMTAB 0000000000000000 00003040
00000000000003a8 0000000000000018 29 18 8
[29] .strtab STRTAB 0000000000000000 000033e8
000000000000020b 0000000000000000 0 0 1
[30] .shstrtab STRTAB 0000000000000000 000035f3
000000000000011a 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
D (mbind), l (large), p (processor specific) -
静态链接
There are 32 section headers, starting at offset 0xdb548:
节头:
[号] 名称 类型 地址 偏移量
大小 全体大小 旗标 链接 信息 对齐
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .note.gnu.pr[…] NOTE 0000000000400270 00000270
0000000000000030 0000000000000000 A 0 0 8
[ 2] .note.gnu.bu[…] NOTE 00000000004002a0 000002a0
0000000000000024 0000000000000000 A 0 0 4
[ 3] .note.ABI-tag NOTE 00000000004002c4 000002c4
0000000000000020 0000000000000000 A 0 0 4
[ 4] .rela.plt RELA 00000000004002e8 000002e8
0000000000000240 0000000000000018 AI 29 20 8
[ 5] .init PROGBITS 0000000000401000 00001000
000000000000001b 0000000000000000 AX 0 0 4
[ 6] .plt PROGBITS 0000000000401020 00001020
0000000000000180 0000000000000000 AX 0 0 16
[ 7] .text PROGBITS 00000000004011c0 000011c0
0000000000095138 0000000000000000 AX 0 0 64
[ 8] __libc_freeres_fn PROGBITS 0000000000496300 00096300
00000000000014cd 0000000000000000 AX 0 0 16
[ 9] .fini PROGBITS 00000000004977d0 000977d0
000000000000000d 0000000000000000 AX 0 0 4
[10] .rodata PROGBITS 0000000000498000 00098000
000000000001cb2c 0000000000000000 A 0 0 32
[11] .stapsdt.base PROGBITS 00000000004b4b2c 000b4b2c
0000000000000001 0000000000000000 A 0 0 1
[12] .eh_frame PROGBITS 00000000004b4b30 000b4b30
000000000000b928 0000000000000000 A 0 0 8
[13] .gcc_except_table PROGBITS 00000000004c0458 000c0458
0000000000000122 0000000000000000 A 0 0 1
[14] .tdata PROGBITS 00000000004c17b0 000c07b0
0000000000000020 0000000000000000 WAT 0 0 8
[15] .tbss NOBITS 00000000004c17d0 000c07d0
0000000000000048 0000000000000000 WAT 0 0 8
[16] .init_array INIT_ARRAY 00000000004c17d0 000c07d0
0000000000000008 0000000000000008 WA 0 0 8
[17] .fini_array FINI_ARRAY 00000000004c17d8 000c07d8
0000000000000008 0000000000000008 WA 0 0 8
[18] .data.rel.ro PROGBITS 00000000004c17e0 000c07e0
0000000000003788 0000000000000000 WA 0 0 32
[19] .got PROGBITS 00000000004c4f68 000c3f68
0000000000000098 0000000000000000 WA 0 0 8
[20] .got.plt PROGBITS 00000000004c5000 000c4000
00000000000000d8 0000000000000008 WA 0 0 8
[21] .data PROGBITS 00000000004c50e0 000c40e0
00000000000019e0 0000000000000000 WA 0 0 32
[22] __libc_subfreeres PROGBITS 00000000004c6ac0 000c5ac0
0000000000000048 0000000000000000 WAR 0 0 8
[23] __libc_IO_vtables PROGBITS 00000000004c6b20 000c5b20
0000000000000768 0000000000000000 WA 0 0 32
[24] __libc_atexit PROGBITS 00000000004c7288 000c6288
0000000000000008 0000000000000000 WAR 0 0 8
[25] .bss NOBITS 00000000004c72a0 000c6290
0000000000005980 0000000000000000 WA 0 0 32
[26] __libc_freer[…] NOBITS 00000000004ccc20 000c6290
0000000000000020 0000000000000000 WA 0 0 8
[27] .comment PROGBITS 0000000000000000 000c6290
000000000000002b 0000000000000001 MS 0 0 1
[28] .note.stapsdt NOTE 0000000000000000 000c62bc
0000000000001648 0000000000000000 0 0 4
[29] .symtab SYMTAB 0000000000000000 000c7908
000000000000c480 0000000000000018 30 770 8
[30] .strtab STRTAB 0000000000000000 000d3d88
0000000000007668 0000000000000000 0 0 1
[31] .shstrtab STRTAB 0000000000000000 000db3f0
0000000000000157 0000000000000000 0 0 1
这是因为它们的重定向机制不同
先来说一下两个符号表-
1.全局偏移表(GOT):存放外部函数地址的数据段。
-
2.程序连接表(PLT):用来获取数据段记录的外部函数地址的代码。
print_banner: printf@plt: printf@got: 0xf7e835f0 :
… jmp *printf@got 0xf7e835f0 …
call printf@plt ret
… …可执行文件 PLT表 GOT表 glibc中的printf函数
GOT是一个存储外部库函数的表
PLT则是由代码片段组成的,每个代码片段都跳转到GOT表中的一个具体的函数调用
这里讲一下重定位
番外篇2–重定位
链接时重定位–静态链接
链接阶段是将一个或多个中间文件(.o文件)通过链接器将它们链接成一个可执行文件,主要做的事情有
对各个中间文件的同名section进行合并 对代码段,数据段等进行地址分配 进行链接时重定位- 1
- 2
- 3
- 4
- 5
两种情况:
如果是在其他中间文件中已经定义了的函数,链接阶段可以直接重定位到函数地址 如果是在动态库中定义了的函数,链接阶段无法直接重定位到函数地址,只能生成额外的小片段代码,也就是PLT表,然后重定位到该代码片段- 1
- 2
- 3
运行时重定位–动态链接
运行后加载动态库,把动态库中的相应函数地址填入GOT表,由于PLT表是跳转到GOT表的,这就构成了运行时重定位
延迟重定位–动态链接
只有动态库函数在被调用时,才会进行地址解析和重定位工作,这时候动态库函数的地址才会被写入到GOT表项中

第一步由函数调用跳入到PLT表中,然后第二步PLT表跳到GOT表中,可以看到第三步由GOT表回跳到PLT表中,这时候进行压栈,把代表函数的ID压栈,接着第四步跳转到公共的PLT表项中,第5步进入到GOT表中,然后_dl_runtime_resolve对动态函数进行地址解析和重定位,第七步把动态函数真实的地址写入到GOT表项中,然后执行函数并返回。解释下dynamic段,link_map和_dl_runtime_resolve
dynamic段:提供动态链接的信息,例如动态链接中各个表的位置
link_map:已加载库的链表,由动态库函数的地址构成的链表
_dl_runtime_resolve:在第一次运行时进行地址解析和重定位工作
可以看到,第一步还是由函数调用跳入到PLT表,但是第二步跳入到GOT表中时,由于这个时候该表项已经是动态函数的真实地址了,所以可以直接执行然后返回。
对于动态函数的调用,第一次要经过地址解析和回写到GOT表项中,第二次直接调用即可
运行可执行文件
装载进内存
程序编译链接完成后是保存在硬盘中的,当用户执行该程序的时候,该程序(ELF可执行文件)会被加载器按照program header table(可执行文件头)的描述将程序的代码段和数据段从硬盘加载到内存中。
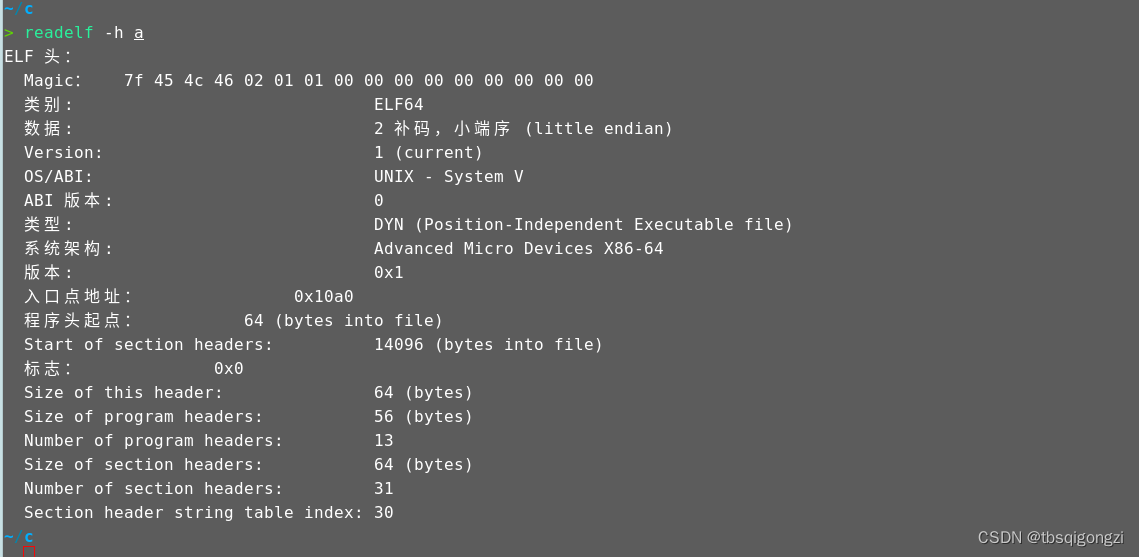
如果是静态链接就是直接将各个段的地址写入内存,如果是动态链接就先随机分配一个地址给ELF文件头,作为首地址,然后ELF文件其他数据根据偏移量确定地址。
这里的地址都是虚拟地址,在运行内存中有着许多进程,每个进程又包含至少一个线程
进程
这里讲一下进程与线程番外篇3–进程与线程
gcc编译好的ELF可执行文件叫程序
那么运行时的程序就叫做进程,进程之间通过 TCP/IP 端口实现交互进程是申请一块内存空间,将数据放到内存空间中去, 是申请数据的过程
是最小的资源管理单元而线程就是进程的子集,多个线程共享同一块内存(由进程向操作系统申请),通过共享的内存空间来进行交互
是进程的一条流水线, 只用来执行程序,而不涉及到申请资源, 是程序的实际执行者
最小的执行单元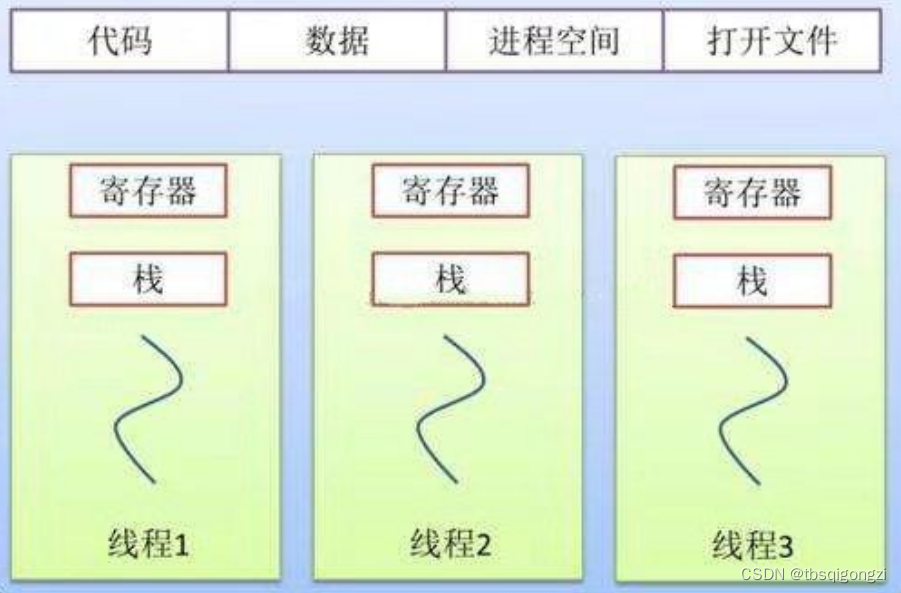
总的来说,程序要运行,需要先向操作系统申请一段内存作为进程
进程空间的内存分配
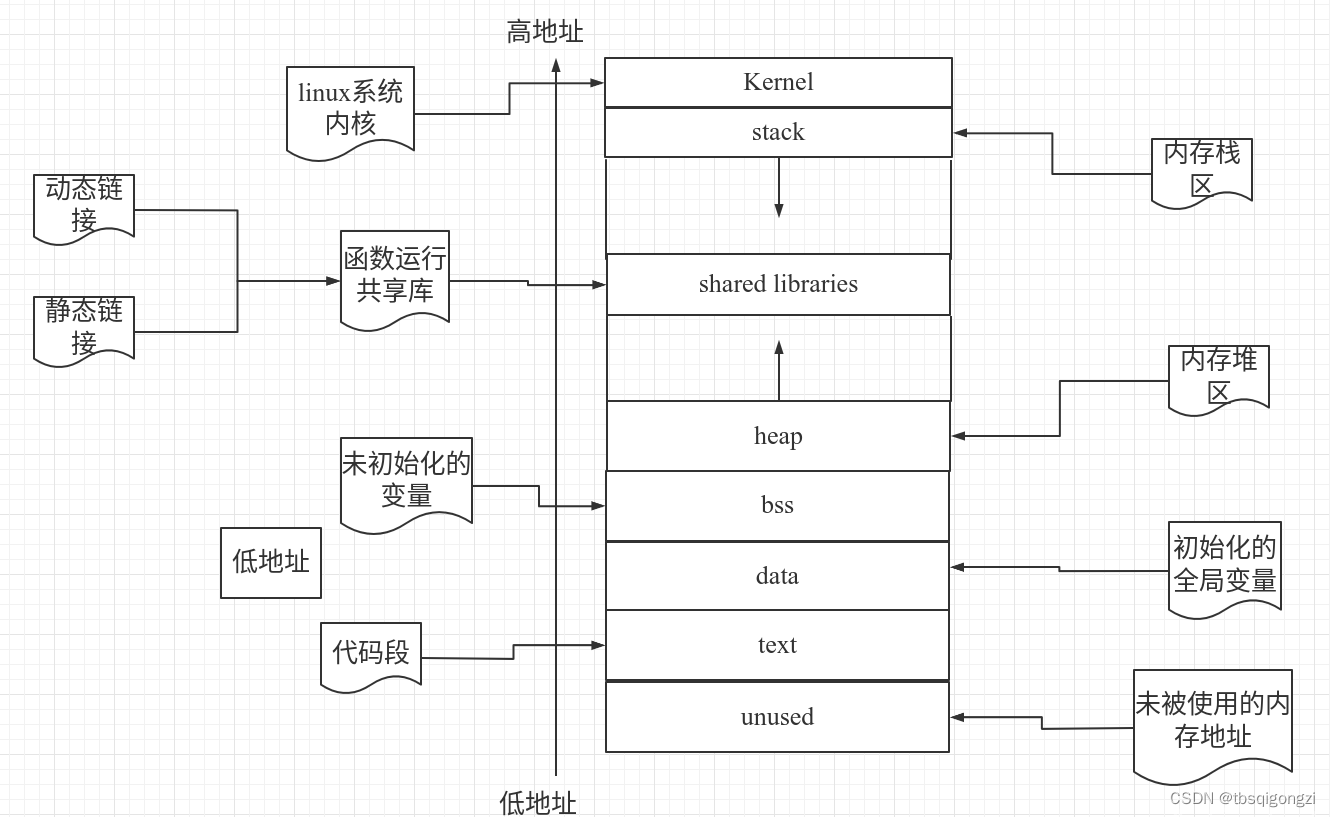
对于linux来说,从 Linux 内核的角度来看,进程和线程都是一样的。
系统调用fork()可以新建一个子进程,函数pthread()可以新建一个线程。但无论线程还是进程,都是用task_struct结构表示的,,唯一的区别就是共享的数据区域不同。
Linux 系统将线程看做共享数据的进程番外篇4–函数调用栈(线程栈)
函数调用经常是嵌套的,在同一时刻,堆栈中会有多个函数的信息。每个未完成运行的函数占用一个独立的连续区域,称作栈帧(Stack Frame)。栈帧是堆栈的逻辑片段,当调用函数时逻辑栈帧被压入堆栈, 当函数返回时逻辑栈帧被从堆栈中弹出。栈帧存放着函数参数,局部变量及恢复前一栈帧所需要的数据等。
栈帧的边界由栈帧基地址指针EBP和堆栈指针ESP界定(指针存放在相应寄存器中)。EBP指向当前栈帧底部(高地址),在当前栈帧内位置固定;ESP指向当前栈帧顶部(低地址),当程序执行时ESP会随着数据的入栈和出栈而移动。因此函数中对大部分数据的访问都基于EBP进行。函数调用时入栈顺序为
实参N~1 → 主调函数返回地址→主调函数帧基指针EBP → 被调函数局部变量1~N- 1

对于我们刚写的的hello.c来说,大概是这样的
CPU开始运行程序
上面说进程向系统申请了一段内存,gcc编译生成的ELF可执行文件会将自己数据映射到这段内存上,而线程作为进程的执行单位拥有自己的堆栈,栈上有一个个栈帧来临时存储数据。
CPU运行程序的过程就是执行一条条指令的过程,这些指令就是gcc编译链接成的ELF可执行文件里的指令(也就是.text段里的代码段的机器代码)。- cpu的程序寄存器存放着要执行的下一条指令的地址,通过这个地址去访问下一条指令,
- 指令寄存器读取下一条指令,
- 逻辑运算单元通过分析各个寄存器中的数据去执行指令,
- 之后程序寄存器中的值进行自加,执行下一指令的地址,如此循环下去,执行完整个程序。
栈帧的创建和销毁也是通过CPU执行ELF文件里的代码段中的指令实现的。

番外篇5–虚拟内存与内存寻址
- 操作系统会提供一种机制,将不同进程的虚拟地址和不同内存的物理地址映射起来。我们上面看到的地址其实都是虚拟地址,这一段虚拟地址对应的物理地址可能是不连续的。
- CPU访问内存时,进程持有的虚拟地址会通过 CPU 芯片中的内存管理单元(MMU)的映射关系,来转换变成物理地址,然后再通过物理地址访问内存。
- MMU的转换分两个阶段,分段机制和分页机制,分段把虚拟地址转换为线性地址,分页把线性地址转换为物理地址。
结语
至此,c程序从编译开始到运行结束的过程就结束了。
到这里就可以解释gcc进行第二步操作编译时和静态链接时的警告了。
我们再看一下我们的a.c文件#includevoid hello(char * name); int main() { char name[16]={0}; printf("Please input your name:"); gets(name); hello(name); return 0; } void hello(char * name) { printf("hello,%s\n",name); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
我们的name数组只有16字节大小,gets函数可以输入超过16字节的数据,根据函数调用栈的原理,name数组存放的位置与main返回地址是挨着的,如果输入过长的数据可能会破坏返回地址的数据,致使程序返回到一个错误的地址,如果这个地址无意义,程序不能正常退出,就会报错,如果这个地址被我们设置成一个特定的有恶意代码的地址,程序就会去执行我们的恶意代码,造成危险。所以gcc向我们发送警告,让我们使用fgets函数来限制输入字节为16字节以内。
-
相关阅读:
C++学习第四天(类与对象下)
Java Double compare()方法具有什么功能呢?
如何设置从小程序跳转到其它小程序
Kaldi语音识别工具编译问题记录(踩坑记录)
EasyRAFT
【已解决】VS2008下MFC程序如何设置多语言
什么是jsp,对于jsp的详细理解
【餐厅点餐平台|三】模块设计
C++模板编程(14)---名称查询(Looking Up Names)
项目第一天
- 原文地址:https://blog.csdn.net/tbsqigongzi/article/details/128137047
