-
G1D28-hinge loss fuction-RAGA pre总结-DeBERTa-杂七杂八visio&mathtype&excel
一、hinge loss和交叉熵对比
(一 )hinge loss主要思想
让正确分类和错误分类的距离达到λ。λ用于控制两种分类样本之间的距离。
(二)对比学习
自监督学习的一种,不依赖标注数据进行学习。蛮有意思的,但是今天没时间了!!有时间再细看!
二、deberta
(一)作图
(二)segment embedding
1、segment embedding
https://segmentfault.com/a/1190000021817185
Bert可以完成两个句子级别的任务。segmentembedding是为此设计的一种嵌入方法。
是bert里的一种标记方法,告诉模型,这是两个句子。
具体方法为,分别标记0、1

2、token embedding
对于token embedding来说,
(1)先要分词
(2)插入[CLS]和[SEP]
(3)做词级别的embedding3、position embedding
初衷是因为transformer不能像rnn一样学习到顺序。
对于同一个词(在不同位置),学习得到的东西是一样的,所以得给一些位置信息的提示(三)relative position embedding
自己看着公式想了一会,发现上网查查就懂啦
https://jaketae.github.io/study/relative-positional-encoding/
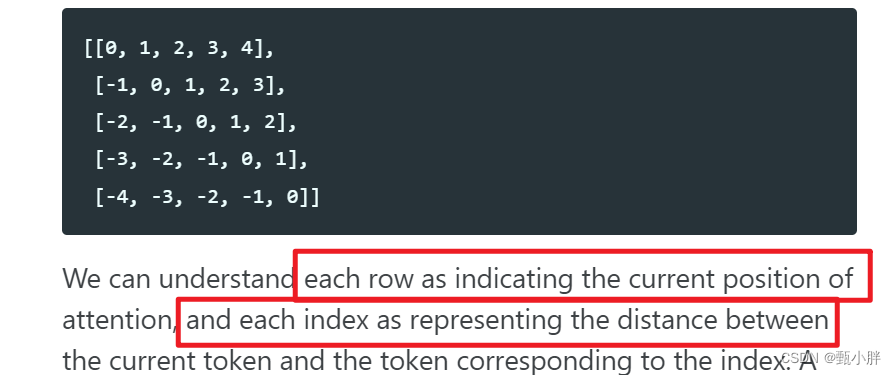
这个relative position matrix,每一行代表注意力看的是哪个token,每一个index代表不同token距离attention发出者的位置。https://zhuanlan.zhihu.com/p/364828960

(四)scale
scale是batch_norm中的。主要是做缩放的。
三、presentation
(一)总结
今天终于做了RAGA的pre,自己讲的时候感觉不太清楚,没有提纲挈领的感觉。
1、下次pre要提前明确每一页slide要完成什么目的,写下来
2、讲完做些总结。(二)同学建议
emm,做图的同学给了还不错的评价。记录下来叭,还蛮开心的,至少有点contribution~
1、“师姐太强了,深入浅出,第一个全听懂的。 ----------
我觉得都讲到位了”
2、
N、杂
(一)文件查杀
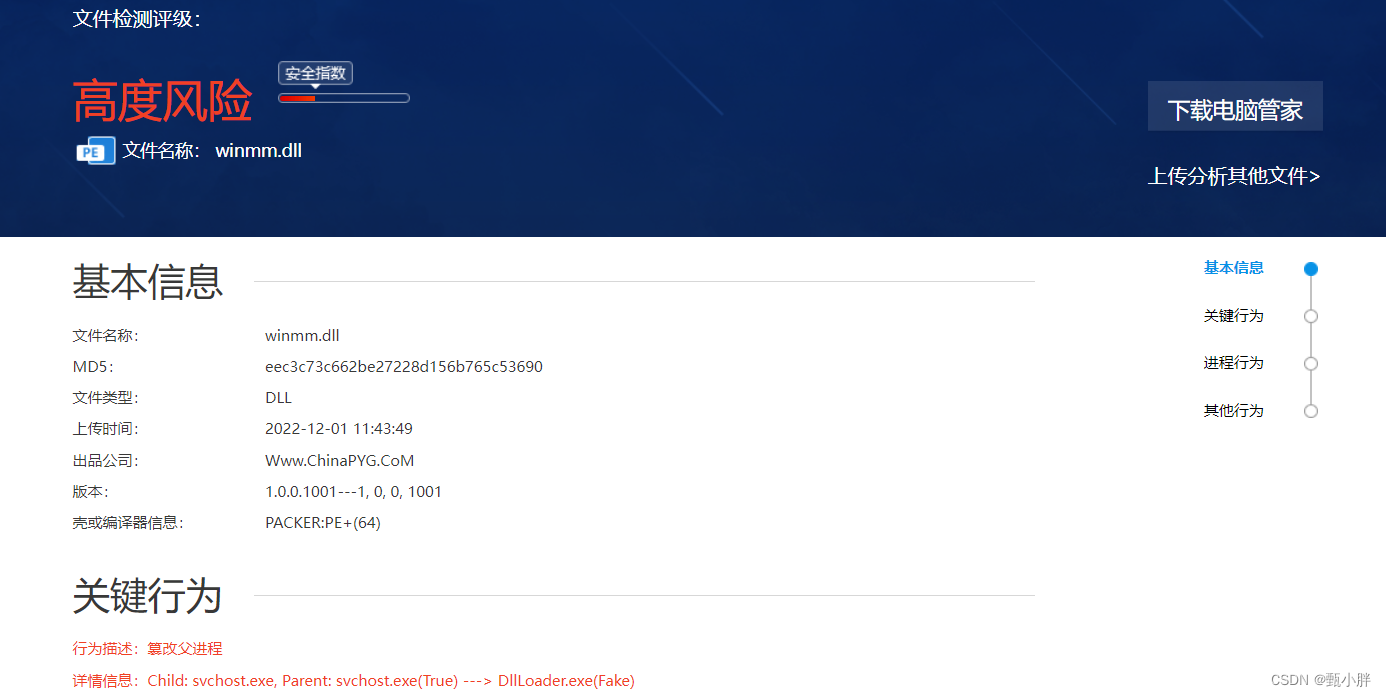
下载文件,被拦了,可以查杀一下,新思路欸!!
看不懂emmm
(二)给友友装mathtype
(三)取色器
(四)visio到处pdf公式变形
用打印存为pdf就不会变形啦~
另外svg就是可缩放矢量图ps:在家坐着真的后背好痛啊
(五)excel绘制柱状图
emm好像是插入数据?挺方便的~
-
相关阅读:
PyTorch for Audio + Music Processing(2/3/4/5/6/7) :构建数据集和提取音频特征
vue中scoped原理与样式穿透原理
boost之跨平台 错误处理
智能微型断路器在道路照明、园区照明、隧道照明中的应用-安科瑞 时丽花
Vim基础用法,最常用、最实用的命令介绍(保姆级教程)
CentOS 7 部署Jellyfin详细教程
Domino服务器SSL证书安装指南
深度学习(12)之模型训练[训练集、验证集、过拟合、欠拟合]
【MyBatis】MyBatis 理论 40 问(二)
正则表达式
- 原文地址:https://blog.csdn.net/weixin_45252975/article/details/128126573