-
10道不得不会的缓存面试题【缓存】
博主介绍: 🚀自媒体 JavaPub 独立维护人,全网粉丝15w+,csdn博客专家、java领域优质创作者,51ctoTOP10博主,知乎/掘金/华为云/阿里云/InfoQ等平台优质作者、专注于 Java、Go 技术领域和副业。🚀
最少必要面试题 ,获取《10万字301道Java经典面试题总结(附答案)》pdf,背题更方便,一文在手,面试我有
我是JavaPub,专注于面试、副业,技术人的成长记录。
以下是 缓存 面试题,相信大家都会有种及眼熟又陌生的感觉、看过可能在短暂的面试后又马上忘记了。JavaPub在这里整理这些容易忘记的重点知识及解答,
建议收藏,经常温习查阅。评论区见
缓存
说到缓存,首先你一定要对 Java容器、和 Redis 有一定了解,建议阅读《最少必要面试题》: 【Java容器篇】 【Redis篇】
1. 什么是缓存?
缓存,就是数据交换的缓冲区,针对服务对象的不同(本质就是不同的硬件)都可以构建缓存。而我们平时说的缓存,大多是指内存。
目的是, 把读写速度【慢】的介质的数据保存在读写速度【快】的介质中,从而提高读写速度,减少时间消耗。 例如:
- CPU 高速缓存 :高速缓存的读写速度远高于内存。
- CPU 读数据时,如果在高速缓存中找到所需数据,就不需要读内存
- CPU 写数据时,先写到高速缓存,再回写到内存。
- 磁盘缓存:磁盘缓存其实就把常用的磁盘数据保存在内存中,内存读写速度也是远高于磁盘的。
- 读数据,时从内存读取。
- 写数据时,可先写到内存,定时或定量回写到磁盘,或者是同步回写。
2. 为什么要用缓存?
使用缓存的目的,就是提升读写性能。而实际业务场景下,更多的是为了提升读性能,带来更好的性能,更高的并发量。
日常业务中,我们使用比较多的数据库是 MySQL ,缓存是 Redis 。Redis 比 MySQL 的读写性能好很多。那么,我们将 MySQL 的热点数据,缓存到 Redis 中,提升读取性能,也减小 MySQL 的读取压力。例如说:
- 论坛帖子的访问频率比较高,且要实时更新阅读量,使用 Redis 记录帖子的阅读量,可以提升性能和并发。
- 商品信息,数据更新的频率不高,但是读取的频率很高,特别是热门商品。
3. 请说说有哪些缓存算法?是否能手写一下 LRU 代码的实现?
缓存算法,比较常见的是三种:
- LRU(least recently used ,最近最少使用)
- LFU(Least Frequently used ,最不经常使用)
- FIFO(first in first out ,先进先出)
这里我们可以借助 LinkedHashMap 实现
public class LRULinkedMap<K,V> { /** * 最大缓存大小 */ private int cacheSize; private LinkedHashMap<K,V> cacheMap ; public LRULinkedMap(int cacheSize) { this.cacheSize = cacheSize; cacheMap = new LinkedHashMap(16,0.75F,true){ @Override protected boolean removeEldestEntry(Map.Entry eldest) { if (cacheSize + 1 == cacheMap.size()){ return true ; }else { return false ; } } }; } public void put(K key,V value){ cacheMap.put(key,value) ; } public V get(K key){ return cacheMap.get(key) ; } public Collection<Map.Entry<K, V>> getAll() { return new ArrayList<Map.Entry<K, V>>(cacheMap.entrySet()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
使用案例:
@Test public void put() throws Exception { LRULinkedMap<String,Integer> map = new LRULinkedMap(3) ; map.put("1",1); map.put("2",2); map.put("3",3); for (Map.Entry<String, Integer> e : map.getAll()){ System.out.print(e.getKey() + " : " + e.getValue() + "\t"); } System.out.println(""); map.put("4",4); for (Map.Entry<String, Integer> e : map.getAll()){ System.out.print(e.getKey() + " : " + e.getValue() + "\t"); } } //输出 1 : 1 2 : 2 3 : 3 2 : 2 3 : 3 4 : 4- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
4. 常见的常见的缓存工具和框架有哪些?
在 Java 后端开发中,常见的缓存工具和框架列举如下:
-
本地缓存:Guava LocalCache、Ehcache、Caffeine 。
Ehcache 的功能更加丰富,Caffeine 的性能要比 Guava LocalCache 好。
-
分布式缓存:Redis、Memcached、Tair 。
Redis 最为主流和常用。
5. 用了缓存之后,有哪些常见问题?
常见的问题,可列举如下:
写入问题
- 缓存何时写入?并且写时如何避免并发重复写入?
- 缓存如何失效?
- 缓存和 DB 的一致性如何保证?
经典三连问
- 如何避免缓存穿透的问题?
- 如何避免缓存击穿的问题?
- 如果避免缓存雪崩的问题?
6. 如何处理缓存穿透的问题
缓存穿透,是指查询一个一定不存在的数据,由于缓存是不命中时被动写,并且处于容错考虑,如果从 DB 查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到 DB 去查询,失去了缓存的意义。
在流量大时,可能 DB 就挂掉了,要是有人利用不存在的 key 频繁攻击我们的应用,这就是漏洞。如下图:
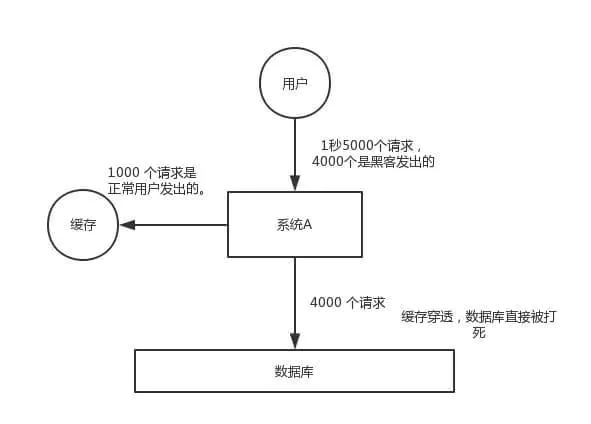
如何解决
有两种方案可以解决:
-
方案一,缓存空对象。
当从 DB 查询数据为空,我们仍然将这个空结果进行缓存,具体的值需要使用特殊的标识,能和真正缓存的数据区分开。另外,需要设置较短的过期时间,一般建议不要超过 5 分钟。 -
方案二,BloomFilter 布隆过滤器。
在缓存服务的基础上,构建 BloomFilter 数据结构,在 BloomFilter 中存储对应的 KEY 是否存在,如果存在,说明该 KEY 对应的值不为空。
如何选择
这两个方案,各有其优缺点。
缓存空对象 BloomFilter 布隆过滤器 适用场景 1、数据命中不高 2、保证一致性 1、数据命中不高, 2、数据相对固定、实时性低 维护成本 1、代码维护简单 2、需要过多的缓存空间 3、数据不一致 1、代码维护复杂,2、缓存空间占用小 实际情况下,使用方案二比较多。因为,相比方案一来说,更加节省内容,对缓存的负荷更小。
7. 如何处理缓存雪崩的问题
缓存雪崩,是指缓存由于某些原因无法提供服务( 例如,缓存挂掉了 ),所有请求全部达到 DB 中,导致 DB 负荷大增,最终挂掉的情况。
如何解决
预防和解决缓存雪崩的问题,可以从以下多个方面进行共同着手。
-
缓存高可用:通过搭建缓存的高可用,避免缓存挂掉导致无法提供服务的情况,从而降低出现缓存雪崩的情况。假设我们使用 Redis 作为缓存,则可以使用 Redis Sentinel 或 Redis Cluster 实现高可用。
-
本地缓存:如果使用本地缓存时,即使分布式缓存挂了,也可以将 DB 查询到的结果缓存到本地,避免后续请求全部到达 DB 中。如果我们使用 JVM ,则可以使用 Ehcache、Guava Cache 实现本地缓存的功能。
当然,引入本地缓存也会有相应的问题,例如说:
本地缓存的实时性怎么保证?
方案一,可以引入消息队列。在数据更新时,发布数据更新的消息;而进>程中有相应的消费者消费该消息,从而更新本地缓存。
方案二,设置较短的过期时间,请求时从 DB 重新拉取。
方案三,手动过期。-
请求 DB 限流: 通过限制 DB 的每秒请求数,避免把 DB 也打挂了。如果我们使用 Java ,则可以使用 Guava RateLimiter、Sentinel、Hystrix 实现限流的功能。这样至少能有两个好处:
- 可能有一部分用户,还可以使用,系统还没死透。
- 未来缓存服务恢复后,系统立即就已经恢复,无需再处理 DB 也挂掉的情况。
-
提前演练:在项目上线前,演练缓存宕掉后,应用以及后端的负载情况以及可能出现的问题,在此基础上做一些预案设定。
8. 如何处理缓存击穿的问题
缓存击穿,是指某个极度“热点”数据在某个时间点过期时,恰好在这个时间点对这个 KEY 有大量的并发请求过来,这些请求发现缓存过期一般都会从 DB 加载数据并回设到缓存,但是这个时候大并发的请求可能会瞬间 DB 压垮。
- 对于一些设置了过期时间的 KEY ,如果这些 KEY 可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑这个问题。
- 区别:
- 和缓存“雪崩“”的区别在于,前者针对某一 KEY 缓存,后者则是很多 KEY 。
- 和缓存“穿透“”的区别在于,这个 KEY 是真实存在对应的值的。
如何解决
有两种方案可以解决:
-
方案一,使用互斥锁。请求发现缓存不存在后,去查询 DB 前,使用分布式锁,保证有且只有一个线程去查询 DB ,并更新到缓存。
-
方案二,手动过期。缓存上从不设置过期时间,功能上将过期时间存在 KEY 对应的 VALUE 里。流程如下:
- 获取缓存。通过 VALUE 的过期时间,判断是否过期。如果未过期,则直接返回;如果已过期,继续往下执行。
- 通过一个后台的异步线程进行缓存的构建,也就是“手动”过期。通过后台的异步线程,保证有且只有一个线程去查询 DB。
- 同时,虽然 VALUE 已经过期,还是直接返回。通过这样的方式,保证服务的可用性,虽然损失了一定的时效性。
选择
这两个方案,各有其优缺点。
使用互斥锁 手动过期 优点 1、思路简单 2、保证一致性 1、性价最佳,用户无需等待 缺点 1、代码复杂度增大 2、存在死锁的风险 1、无法保证缓存一致性 9. 缓存和 DB 的一致性如何保证?
产生原因
主要有两种情况,会导致缓存和 DB 的一致性问题:
- 并发的场景下,导致读取老的 DB 数据,更新到缓存中。
主要指的是,更新 DB 数据之前,先删除 Cache 的数据。在低并发量下没什么问题,但是在高并发下,就会存在问题。在(删除 Cache 的数据, 和更新 DB 数据)时间之间,恰好有一个请求,我们如果使用被动读,因为此时 DB 数据还是老的,又会将老的数据写入到 Cache 中。
- 缓存和 DB 的操作,不在一个事务中,可能只有一个 DB 操作成功,而另一个 Cache 操作失败,导致不一致。
当然,有一点我们要注意,缓存和 DB 的一致性,我们指的更多的是最终一致性。我们使用缓存只要是提高读操作的性能,真正在写操作的业务逻辑,还是以数据库为准。例如说,我们可能缓存用户钱包的余额在缓存中,在前端查询钱包余额时,读取缓存,在使用钱包余额时,读取数据库。
解决方案
在开始说解决方案之前,胖友先看看如下几篇文章,可能有一丢丢多,保持耐心。
当然无论哪种方案,比较重要的就是解决两个问题:
-
- 将缓存可能存在的并行写,实现串行写。
-
- 实现数据的最终一致性。
- 先淘汰缓存,再写数据库
因为先淘汰缓存,所以数据的最终一致性是可以得到有效的保证的。为什么呢?先淘汰缓存,即使写数据库发生异常,也就是下次缓存读取时,多读取一次数据库。
那么,我们需要解决缓存并行写,实现串行写。比较简单的方式,引入分布式锁。
- 在写请求时,先淘汰缓存之前,先获取该分布式锁。
- 在读请求时,发现缓存不存在时,先获取分布式锁。
- 先写数据库,再更新缓存
按照 “先写数据库,再更新缓存”,我们要保证 DB 和缓存的操作,能够在 “同一个事务”中,从而实现最终一致性
10. 什么是缓存预热?如何实现缓存预热?
缓存预热
在刚启动的缓存系统中,如果缓存中没有任何数据,如果依靠用户请求的方式重建缓存数据,那么对数据库的压力非常大,而且系统的性能开销也是巨大的。
此时,最好的策略是启动时就把热点数据加载好。这样,用户请求时,直接读取的就是缓存的数据,而无需去读取 DB 重建缓存数据。举个例子,热门的或者推荐的商品,需要提前预热到缓存中。
如何实现
一般来说,有如下几种方式来实现:
- 数据量不大时,项目启动时,自动进行初始化。
- 写个修复数据脚本,手动执行该脚本。
- 写个管理界面,可以手动点击,预热对应的数据到缓存中。
拓展:缓存数据的淘汰策略有哪些?
除了缓存服务器自带的缓存自动失效策略之外,我们还可以根据具体的业务需求进行自定义的“手动”缓存淘汰,常见的策略有两种:
- 定时去清理过期的缓存。
- 当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。
两者各有优劣,第一种的缺点是维护大量缓存的 key 是比较麻烦的,第二种的缺点就是每次用户请求过来都要判断缓存失效,逻辑相对比较复杂!Redis 的缓存淘汰策略就是很好的实践方式。
具体用哪种方案,大家可以根据自己的应用场景来权衡。
低谷蓄力
最少必要面试题

关注公众号,回复1024,获取Java学习路线思维导图、加入源码计划学习交流群 - CPU 高速缓存 :高速缓存的读写速度远高于内存。
-
相关阅读:
UnitTest 参数化---Parameterized安装
什么是机器学习特征工程?【数据集特征抽取(字典,文本TF-Idf)、特征预处理(标准化,归一化)、特征降维(低方差,相关系数,PCA)】
大数据面试题之MapReduce(1)
java基于Springboot+vue的宾馆酒店民宿入住管理平台系统 前后端分离elementui
踩坑——Doris,Can‘t get Kerberos realm, cause by: Can‘t get Kerberos realm
MyBatis操作数据库实现
Primavera Unifier 21.12.4~21.12.7.0疑似漏洞
Codeforces Round #813 (Div. 2)A.B.C
【k8s相关资源api操作】
前端入门(二)Vue2到Vue3
- 原文地址:https://blog.csdn.net/qq_40374604/article/details/128123061
