-
【Python】Python 中实现数据序列化
一、前言
首先,要了解什么是序列化,请参考我的另一篇文章:序列化与反序列化介绍
本文主要介绍 Python 中的数据序列化,主要介绍 Python 内置的几个用于进行数据序列化的模块。
二、为什么要进行序列化
每种编程语言都有各自的数据类型,其中面向对象的编程语言还允许开发者自定义数据类型(如:自定义类),Python也是一样。很多时候我们会有这样的需求:
- 网络传输数据:把内存中的各种数据类型的数据通过网络传送给其它机器或客户端。
- 数据存储:把内存中的各种数据类型的数据保存到本地磁盘持久化。
如果要将一个系统内的数据通过网络传输给其它系统或客户端,我们通常都需要先把这些数据转化为字符串或字节串,而且需要规定一种统一的数据格式才能让数据接收端正确解析并理解这些数据的含义。XML 是早期被广泛使用的数据交换格式,在早期的系统集成论文中经常可以看到它的身影;如今大家使用更多的数据交换格式是JSON(Javascript Object Notation),它是一种轻量级的数据交换格式。JSON相对于XML而言,更加加单、易于阅读和编写,同时也易于机器解析和生成。除此之外,我们也可以自定义内部使用的数据交换格式。
如果是想把数据持久化到本地磁盘,这部分数据通常只是供系统内部使用,因此数据转换协议以及转换后的数据格式也就不要求是标准、统一的,只要本系统内部能够正确识别即可。但是,系统内部的转换协议通常会随着编程语言版本的升级而发生变化(改进算法、提高效率),因此通常会涉及转换协议与编程语言的版本兼容问题,下面的pickle协议就是这样一个例子。
三、Python 中的数据序列化
本节要介绍的就是Python内置的几个用于进行数据序列化的模块:
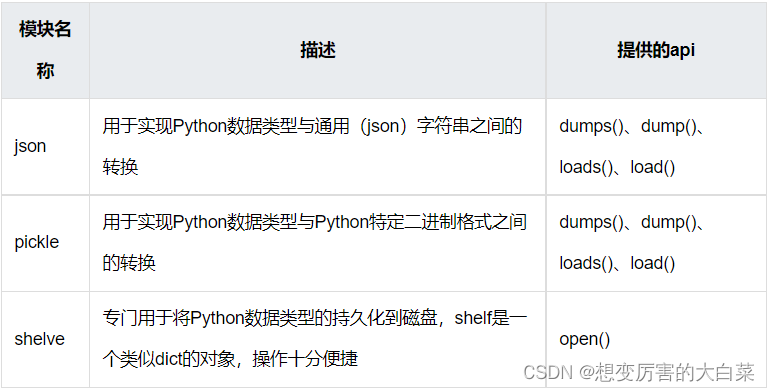
1. json模块
大部分编程语言都会提供处理 json 数据的接口,Python 2.6开始加入了 json 模块,且把它作为一个内置模块提供,无需下载即可使用。
Python的 JSON 模块中,序列化与反序列化的过程分别叫做:encoding 和 decoding:
- encoding: 把 Python 对象转换成 JSON 字符串
- decoding: 把 JSON 字符串转换成 python 对象
json模块提供了以下两个方法来进行序列化和反序列化操作:

除此之外,json模块还提供了两个额外的方法允许我们直接将序列化后得到的 json 数据保存到文件中,以及直接读取文件中的 json 数据进行反序列化操作:

2. pickle模块
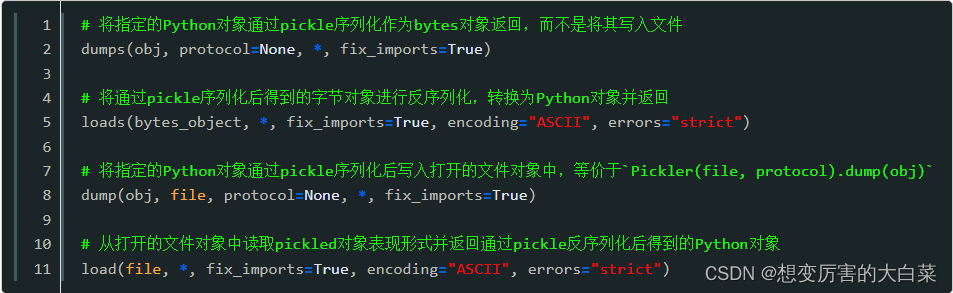
pickle 模块实现了用于对 Python 对象结构进行序列化和反序列化的二进制协议,与 json 模块不同的是 pickle 模块序列化和反序列化的过程分别叫做 pickling 和 unpickling:
- pickling:是将 Python 对象转换为字节流的过程
- unpickling: 是将字节流二进制文件或字节对象转换回 Python 对象的过程
pickle模块与json模块对比:
- JSON是一种文本序列化格式(它输出的是unicode文件,大多数时候会被编码为utf-8),而pickle是一个二进制序列化格式;
- JOSN是我们可以读懂的数据格式,而pickle是二进制格式,我们无法读懂;
- JSON是与特定的编程语言或系统无关的,且它在Python生态系统之外被广泛使用,而pickle使用的数据格式是特定于Python的;
- 默认情况下,JSON只能表示Python内建数据类型,对于自定义数据类型需要一些额外的工作来完成;pickle可以直接表示大量的Python数据类型,包括自定数据类型(其中,许多是通过巧妙地使用Python内省功能自动实现的;复杂的情况可以通过实现specific object API来解决)
pickle 模块提供的几个序列化/反序列化的函数与 json 模块基本一致:
3. shelve模块
shelve是一个简单的数据存储方案,类似 key-value 数据库,可以很方便的保存 python 对象,其内部是通过 pickle 协议来实现数据序列化。shelve只有一个 open() 函数,这个函数用于打开指定的文件(一个持久的字典),然后返回一个shelf 对象。shelf 是一种持久的、类似字典的对象。它与“dbm”的不同之处在于,其 values 值可以是任意基本 Python 对象–pickle 模块可以处理的任何数据。这包括大多数类实例、递归数据类型和包含很多共享子对象的对象。keys 还是普通的字符串。

flag 参数表示打开数据存储文件的格式,可取值与 dbm.open() 函数一致: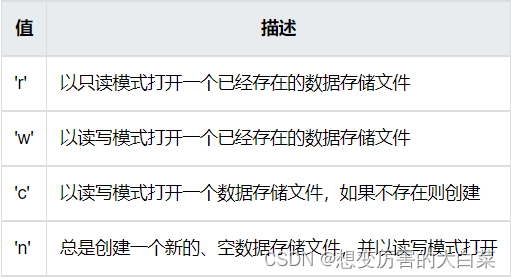
protocol 参数表示序列化数据所使用的协议版本,默认是pickle v3;
writeback 参数表示是否开启回写功能。我们可以把 shelf 对象当 dict 来使用–存储、更改、查询某个 key 对应的数据,当操作完成之后,调用shelf 对象的 close() 函数即可。当然,也可以使用上下文管理器(with语句),避免每次都要手动调用 close() 方法。
4. 总结
1. 对比
- json模块常用于编写web接口,将Python数据转换为通用的json格式传递给其它系统或客户端;也可以用于将Python数据保存到本地文件中,缺点是明文保存,保密性差。另外,如果需要保存费内置数据类型需要编写额外的转换函数或自定义类。
- pickle模块和shelve模块由于使用其特有的序列化协议,其序列化之后的数据只能被Python识别,因此只能用于Python系统内部。另外,Python 2.x 和 Python 3.x 默认使用的序列化协议也不同,如果需要互相兼容需要在序列化时通过protocol参数指定协议版本。除了上面这些缺点外,pickle模块和shelve模块相对于json模块的优点在于对于自定义数据类型可以直接序列化和反序列化,不需要编写额外的转换函数或类。
- shelve模块可以看做是pickle模块的升级版,因为shelve使用的就是pickle的序列化协议,但是shelve比pickle提供的操作方式更加简单、方便。shelve模块相对于其它两个模块在将Python数据持久化到本地磁盘时有一个很明显的优点就是,它允许我们可以像操作dict一样操作被序列化的数据,而不必一次性的保存或读取所有数据。
2. 建议
- 需要与外部系统交互时用json模块;
- 需要将少量、简单Python数据持久化到本地磁盘文件时可以考虑用pickle模块;
- 需要将大量Python数据持久化到本地磁盘文件或需要一些简单的类似数据库的增删改查功能时,可以考虑用shelve模块。
参考链接
-
相关阅读:
如何完美解决前端数字计算精度丢失与数字格式化问题?
原生 JS 实现 HTML 转 Markdown,以及其实现逻辑(html2md.js 或 html2markdown.js)
【SpringSecurity】九、Base64与JWT
工作流实战之Activiti7
安卓开发基础知识-补习8
单片机卡死的几大原因、分析、解决
组合计数训练题解
shell(19): shell脚本for循环(nmon监控)2
C/S - Exploits 学习笔记
制造业数字化系统国产替代如何做?
- 原文地址:https://blog.csdn.net/weixin_44211968/article/details/128117771