-
第十六章《正则表达式》第2节:正则表达式高级语义
正则表达式中出16.1小节所介绍的那些通配符外,还有贪婪模式、非贪婪模式、定位符、正反向预搜索、反向引用等概念,这些概念都属于正则表达式高级语义的范畴,使用高级语义能够定义出更为更为形式复杂的正则表达式,本小节将详细讲解正则表达式的高级语义。
16.2.1贪婪模式与非贪婪模式
16.1.4小节中曾经介绍过:如果定义了某类字符出现的次数,那么表达式引擎在完成匹配时会尽量以更多的字符完成匹配,例如:
- String str = "axxxaaxxxa";
- String result = str.replaceAll("a.+a","*");
以上代码希望把str中“以a开头并以a结尾”的一串字符替换为一个“*”,str中的“axxxa”的符合匹配条件,而str整个字符串也符合匹配条件,这种情况下表达式引擎会匹配str整个字符串,因此以上代码运行的结果是把str整体替换为一个“*”,这种尽量多匹配字符的匹配方式在专业上被成为“贪婪模式”。
实际上,正则表达式也可以用“非贪婪模式”完成匹配。所谓“非贪婪模式”就是指在完成匹配时尽量以更少的字符完成匹配,程序员只需要在表示出现次数的符号后面写一个?就可以。下面的【例16_10】对比了贪婪模式和以非贪婪模式匹配的效果。
【例16_10贪婪模式与非贪婪模式】
Exam16_10.java
- public class Exam16_10 {
- public static void main(String[] args) {
- String str = "鲁迅与藤野严九郎(注①:鲁迅在日本留学期间的老师)的朝夕相处," +
- "对其走上文坛产生过重要影响。" +
- "藤野毕业于爱知县立医学校(注②:今名古屋大学)," +
- "在鲁迅入学前的两个月他才升格为教授。";
- String result1 = str.replaceAll("\\(注.+\\)","");//①贪婪模式
- String result2 = str.replaceAll("\\(注.+?\\)","");//②非贪婪模式
- System.out.println(result1);
- System.out.println(result2);
- }
- }
【例16_10】中的str是一段包含注释的文字,现在希望通过替换的方式把注释去掉,正则表达式“\\(注.+\\)”表示以“(注”开头,以“)”结尾的一串字符,找到符合这样条件的字符后用空字符串替换它就能达到去除注释的效果。程序中语句①使用贪婪模式完成匹配,语句②使用非贪婪模式完成匹配。需要注意:在书写正则表达式时,一对小括号表示一个字符序列的整体,专业上把这个整体叫做“组”,因此小括号在正则表达式中也是有意义的特殊符号,需要用转义字符的形式书写。【例16_10】的运行结果如图16-10所示。

图16-10【例16_10】运行结果
从图16-10可以看出:使用贪婪模式完成匹配时,从注①一直匹配到了注②的右小括号,因此这种匹配方式不能正确的去除注释,而语句②使用非贪婪模式进行匹配时能够准确的把文中的注释去掉。
16.2.2定位符的使用
在实际开发过程中有时不仅仅要用正则表达式定义出目标字符串的结构特征,还要求定义出目标字符串出现的位置,定义目标字符串的位置必须使用正则表达式提供的定位符来完成。正则表达式中的定位符如表16-3所示
表16-3 正则表达式定位符
符号
功能
^
表示字符串开始的位置,在正则表达式中要出现在最前面,否则将被当作普通字符对待
$
表示字符串结束的位置,在正则表达式中要出现在最后面,否则将被当作普通字符对待
\b
表示紧邻空白字符,字符串的开头或结尾也被看作空白字符
\B
表示不与空白字符相邻,字符串的开头或结尾也被看作空白字符
表16-3所列出的定位符指出了正则表达式能够匹配字符串中位于哪一部分的子字符串,下面的【例16_11】展示了定位符在正则表达式中的作用。
【例16_11定位符的使用】
Exam16_11.java
- public class Exam16_11 {
- public static void main(String[] args) {
- String str = "aaayyyaaayyyaaa";
- //替换str中所有的aaa
- String result1 = str.replaceAll("aaa","*");
- //替换str中位于开头位置的aaa
- String result2 = str.replaceAll("^aaa","*");
- //替换str中位于结尾位置的aaa
- String result3 = str.replaceAll("aaa$","*");
- //替换str中空白字符右侧的aaa
- String result4 = str.replaceAll("\\baaa","*");
- //替换str中空白字符左侧的aaa
- String result5 = str.replaceAll("aaa\\b","*");
- //替换str中左侧没有空白字符的aaa
- String result6 = str.replaceAll("\\Baaa","*");
- //替换str中右侧没有空白字符的aaa
- String result7 = str.replaceAll("aaa\\B","*");
- System.out.println(result1);
- System.out.println(result2);
- System.out.println(result3);
- System.out.println(result4);
- System.out.println(result5);
- System.out.println(result6);
- System.out.println(result7);
- }
- }
【例16_11】的运行结果如图16-11所示。

图16-11【例16_11】运行结果
读者可以根据运行结果体会每种定位符的作用。
16.2.3正反向预搜索
16.2.2小节介绍的定位符虽然能够指出位于哪些字符旁边的字符串会完成匹配,但这些能用于定位的字符太过简单,程序中有时候还需要指出更复杂的字符或字符串作为定位标记,例如指定要匹配位于字符串“NT”左侧或右侧的某个字符串,在这种情况下,字符串“NT”就是定位标记。指定定位标记就需要用到正则表达式的正向或反向预搜索技术。
如果定位标记位于右侧,则这个预判的过程称为“正向预搜索”,反之,如果定位标记串位于左侧,则这个预判的过程成为“反向预搜索”。正向预搜索的符号是(?=),而反向预搜索的符号是(?<=)。实际上,无论是正向预搜索还是反向预搜索都有否定形式,所谓否定形式就是左边或右边不是某种指定的定位符。正向预搜索的符号是(?!),而反向预搜索的符号是(?
【例16_12正反向预搜索】
Exam16_12.java
- public class Exam16_12 {
- public static void main(String[] args) {
- String str = "AwindowsNT BwindowsXP Cwindows7 Dwindows8";
- //替换str中所有的windows
- String result1 = str.replaceAll("windows","*");
- //替换str中右侧为NT的windows(正向)
- String result2 = str.replaceAll("windows(?=NT)","*");
- //替换str中右侧为NT或XP的windows(正向)
- String result3 = str.replaceAll("windows(?=NT|XP)","*");
- //替换str中右侧为数字的windows(正向)
- String result4 = str.replaceAll("windows(?=\\d)","*");
- //替换str中右侧不是数字的windows(正向)
- String result5 = str.replaceAll("windows(?!\\d)","*");
- //替换str中左侧为A的windows(反向)
- String result6 = str.replaceAll("(?<=A)windows","*");
- //替换str中左侧为不是A的的windows(反向)
- String result7 = str.replaceAll("(?,"*");
- System.out.println(result1);
- System.out.println(result2);
- System.out.println(result3);
- System.out.println(result4);
- System.out.println(result5);
- System.out.println(result6);
- System.out.println(result7);
- }
- }
【例16_12】的运行结果如图16-12所示。

图16-12【例16_12】运行结果
16.2.4反向引用
正则表达式可以被人为的划分成多个部分,程序员只需要把每一个部分用小括号括起来即可,也就是说,表达式引擎认为每个小括号中的内容都是被划分出来的一部分,而每个部分都会按照小括号从左到右的顺序自动被编号为1、2、3...。如果括号发生嵌套,则优先对外层括号进行编号。当划分出每一部分之后,就可以定义出某一部分再次出现的位置和顺序,这种技术称为“反向引用”。程序员只需要以“\数字”的形式就能标注出表达式的各个部分。例如:
(.)(.)\\2\\1在这个正则表达式中,第一个“.”表示任意字符,而它被小括号括起来,所以它就是第一部分,第二个“.”也是任意字符,它也被小括号括起来,由于这对小括号按顺序排在第二位,所以小括号中的“.”是第二部分。紧接着出现的“\\2”表示与第二部分相同的字符,也就是说第二部分在此位置又出现一次,而“\\1”表示与第一部分相同的字符,也即第一部分在此位置又出现一次。从整体来看,这个正则表达式匹配由4个字符组成且呈对称形式的字符串,例如“abba”、“effe”等。
使用反向引用还能定义出连续的几个相同字符,例如:
(.)\\1{3,}在这个正则表达式的开头是一个“.”,它被小括号括起来,因此是第一部分,后面的“\\1”表示第一部分在此位置出现,再后面的“{3,}”与第一部分相同的字符表示至少出现3次,加上开头“.”定义的第一部分,第一部分至少出现4次,由因此从整体来看,这个正则表达式能够匹配连续的4个或4个以上连续的相同字符组成的字符串,例如“aaaa”、“bbbbb”等。
当小括号发生嵌套时,优先对外层括号进行编号,例如:
((a)b)\\1在这个表达式中,外层括号被优先编号,也就是说“\\1”表示的是“ab”(注意:“\\1”并不表示“(a)b”,因为小括号没有以转义字符形式出现)因此这个表达式匹配“abab”。
当外层括号的后面又有一对括号时,先对外层括号内部的括号进行编号,再对外层括号后面的括号进行编号,例如:
((a)b)(c)\\2在这个表达式中,括住“(a)b”的是外层括号,且它最先出现,因此它被编为1号,而外层括号中括住“a”的内层括号先于扩展“c”的括号编号,因此“\\2”代表“a”而不是“c”,因此这个正则表达式匹配“abca”。下面的【例16_13】展示了如何使用反向引用技术定义出各种特征的字符串。
【例16_13反向引用】
- Exam16_13.java
- public class Exam16_13 {
- public static void main(String[] args) {
- String str = "abbaqwedddd";
- //替换所有长度为4且左右对称的字符串
- String result1 = str.replaceAll("(.)(.)\\2\\1","*");
- //替换同一字符连续出现4次的字符串
- String result2 = str.replaceAll("(.)\\1{3}","*");
- System.out.println(result1);
- System.out.println(result2);
- }
- }
【例16_13】的运行结果如图16-13所示。
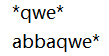
图16-13【例16_13】运行结果
从图16-13可以看出:str中的“dddd”既是左右对称的字符串,又是同一字符连续出现4次的字符串。
16.2.5设置匹配模式
16.2.1小节曾经讲解过贪婪模式和非贪婪模式,这两种模式是用来设定在完成匹配的过程中是包含更多的字符还是包含更少的字符。而本小节要介绍的匹配模式能够从其他方面来设定正则表达式的匹配方式,例如在匹配过程中是否忽略字母的大小写等。每一种匹配模式都有特定的标识符,如表16-4所示。
表16-4匹配模式标识符
标识符
意义
(?i)
匹配过程中忽略大小写
(?u)
忽略大小写的范围扩大到整个Unicode字符集
(?m)
匹配过程中把换行符(\n)也看成是一行的结尾
(?s)
允许.匹配换行符
(?x)
忽略正则表达式中的的空白字符
表16-4所列出的这些标识符能够指定正则表达式匹配目标字符串的方式,下面的【例16_14】展示了匹配模式标识符的使用效果。
【例16_14匹配模式标识符】
Exam16_14.java
- public class Exam16_14 {
- public static void main(String[] args) {
- //替换字母a、b或c,忽略大小写
- String str1 = "xyzAubvcopq";
- String result1 = str1.replaceAll("(?i)[abc]","*");//①
- System.out.println("result1=="+result1);
- //允许.匹配换行符
- String str2 = "\n";
- String result2 = str2.replaceAll("(?s).","*");//②
- System.out.println("result2=="+result2);
- //忽略正则表达式中的空白字符
- String str3 = "abcd";
- String result3 = str3.replaceAll("(?x)a b c","*");//③
- System.out.println("result3=="+result3);
- //允许换行符作为一行的结束
- String str4 = "abb\ncdd";
- String result4 = str4.replaceAll("(?m)\\w$","*");//④
- System.out.println("result4=="+result4);
- }
- }
为演示各种模式标识符的作用,【例16_14】使用了4个字符串进行替换操作,并标识出了每个代表替换结果的字符串名称。【例16_14】的运行结果如图16-14所示。
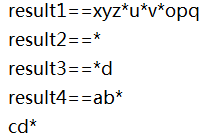
图16-14【例16_14】运行结果
下面逐一对每一次替换结果进行分析。语句①用“(?i)”指定替换字母a、b、c时不区分大小写,所以str1中大写字母A也被替换为“*”。
语句②用“(?s)”指定“.”也能匹配换行符,所以字符串中仅有的换行符“\n”被替换为“*”。
语句③用“(?x)”指定忽略正则表达式中的空白字符,因此正则表达式“a b c”能够匹配str3中的“abc”并把它们替换为一个“*”。
语句④用“(?m)”指定把换行符当作一行的结束,并且“\\w$”表示一行末尾的那个字符,因此能够把str4中“\n”前面的字母b替换为“*”。由于“\n”起到换行作用,所以后半部的“cd*”被打印到下一行,并且可以看出:str4末尾的字母d因处于字符串的末尾也被替换为“*”。
除阅读文章外,各位小伙伴还可以点击这里观看我在本站的视频课程学习Java!
-
相关阅读:
Python | Django 为什么要使用 WSGI?
socket套接字——TCP协议
许战海战略文库|隆基绿能,光伏龙头如何走出战略无人区?
C++零碎记录(十三)
MyBatis框架
vis实现类知识图谱的拓扑图
云原生微服务-理论篇
策略验证_指标买点分析技法_运用KDJ随机指标选择买点
《疯狂塔防物语》新一轮边玩边赚活动来了,仅面向战斗卡 NFT 持有人开放!
Hudi查询类型/视图总结
- 原文地址:https://blog.csdn.net/shalimu/article/details/128118025
