-
ImageNet classification with deep convolutional neural networks
使用深度卷积神经网络进行ImageNet图像分类
目录
1.引言
2012年被认为是深度学习复兴之始,当时来自多伦多大学的Hinton(深度学习三巨头之一)和他的学生Alex Krizhevsky提出了一个名叫“AlexNet”的神经网络结构,该结构在当年的ImageNet LSVRC-2012竞赛一举夺冠,并以此开启了深度学习的热潮。
2.网络结构
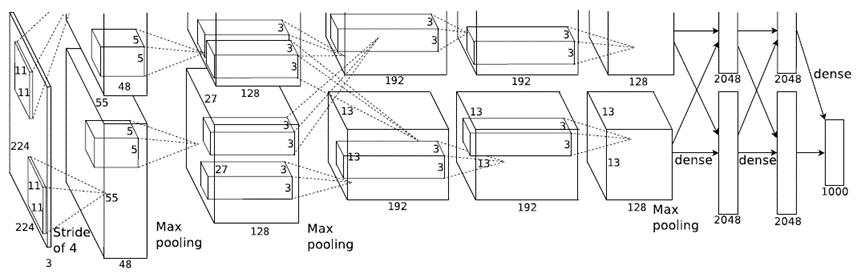
网络包含8个层:前5层为卷积层,后3层为全连接层,最后一个全连接层的输出被送到一个1000路的softmax分类器。
2.1 小细节
- 原论文中,AlexNet的输入图像尺寸是224x224x3,但是实际图像尺寸为227x227x3。
- 因为计算量太大,使用了两台GPU进行训练,并只在确定的层之间交互(注意看卷积核映射虚线:第2、第4和第5个卷积层的内核,仅连接到位于同一GPU上的前一层中的内核映射,第三个卷积层的内核连接到第二层的所有内核映射。)

(最好跟着流程算一遍)
2.2 代码部分
- #01:定义网络结构:在__init__构造函数中申明各个层的定义,在forward中实现层之间的连接关系
- class AlexNet(nn.Module):
- def __init__(self,num_classes):
- super().__init__()
- self.conv1=nn.Sequential(
- nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=0),
- nn.BatchNorm2d(96), #BN加在激活函数前面或后面
- nn.ReLU(inplace=True), #inplace=True将上层网络传递下来的tensor直接进行修改,来节省运算内寸
- nn.MaxPool2d(kernel_size=3, stride=2)
- )
- self.conv2=nn.Sequential(
- nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, stride=1,padding=2), nn.BatchNorm2d(256),
- nn.BatchNorm2d(256)
- nn.ReLU(inplace=True),
- nn.MaxPool2d(3,2)
- )
- self.conv3=nn.Sequential(
- nn.Conv2d(in_channels=256,out_channels=384,kernel_size=3,stride=1,padding=1),
- nn.BatchNorm2d(384),
- nn.ReLU(inplace=True)
- )
- self.conv4=nn.Sequential(
- nn.Conv2d(in_channels=384,out_channels=384,kernel_size=3,stride=1,padding=1),
- nn.BatchNorm2d(384),
- nn.ReLU(inplace=True)
- )
- self.conv5=nn.Sequential(
- nn.Conv2d(in_channels=384,out_channels=256,kernel_size=3,padding=1),
- nn.BatchNorm2d(256),
- nn.ReLU(inplace=True),
- nn.MaxPool2d(3,2)
- )
- self.fc=nn.Sequential(
- nn.Linear(in_features=9216,out_features=4096),
- nn.ReLU(inplace=True),
- nn.Dropout(0.5),
- nn.Linear(in_features=4096, out_features=4096),
- nn.ReLU(inplace=True),
- nn.Dropout(0.5),
- nn.Linear(in_features=4096, out_features=num_classes),
- )
- def forward(self,x):
- x=self.conv1(x)
- x=self.conv2(x)
- x=self.conv3(x)
- x=self.conv4(x)
- x=self.conv5(x)
- x=x.view(x.size(0),-1) #x=torch.flatten(x,start_dim=1)
- x=self.fc(x)
- return x
3. 创新点
3.1 非线性激活函数ReLU(提速)
ReLU的收敛速度要快于sigmoid与tanh,因为后两者存在饱和区,在饱和区的梯度变化缓慢甚至出现梯度消失
3.2 多GPU训练(提速)
单个GPU的内存限制了网络的训练规模,采用多GPU协同训练,可以大大提高AlexNet的训练速度。
3.3局部响应归一化(增强泛化能力,已不再使用)
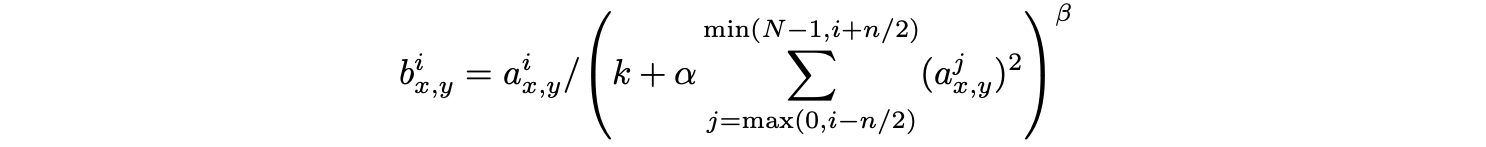
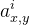 表示第
表示第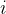 片特征图在位置
片特征图在位置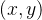 运用激活函数 ReLU 后的输出。n 是同一位置上临近的 feature map 的数目,N 是特征图的总数。
运用激活函数 ReLU 后的输出。n 是同一位置上临近的 feature map 的数目,N 是特征图的总数。- 参数 k,n,α,β 都是超参数。k=2,n=5,α=10-4,β=0.75。
- k是为了防止分母为0

举一个例子:
i = 10, N = 96 时,第 i=10 个卷积核在位置(x,y)处的取值为
,它的局部响应归一化过程如下:用
除以第 8、9、10、11、12 片特征图位置(x,y)处的取值平方求和。
也就是跨通道的一个 Normalization 操作

局部响应归一化(local response normalization,LRN)的思想来源于生物学中的“侧抑制”,是某个神经元受到刺激而产生兴奋时,再刺激相近的神经元,则后者所发生的兴奋对前者产生的抑制作用。也就是说,侧抑制是指相邻的感受器之间能够互相抑制的现象。采用LRN的目的是为了将数据分布调整到合理的范围内,便于计算处理,从而提高泛化能力。
3.4重叠池化(轻微防止过拟合/提高准确率,不再使用)
AlexNet 全部使用最大池化的方式,避免了平均池化所带来的模糊化的效果,并且步长 < 池化核的大小,这样一来池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。论文采用参数stride=2,kernelsize=3
此前的 CNN 一直使用平均池化的操作。
3.5 数据增强(防止过拟合)
alexnet中采用两种数据增强的策略
- 训练时从256x256的原图中随机提取224x224的图片以及水平翻转,数据集扩大了2048倍
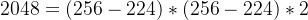
即一张256x256的图像随机裁剪出224x224的图像有( 256 − 224 ) ∗ ( 256 − 224 ) 种可能,再做一次水平翻转则有( 256 − 224 ) ∗ ( 256 − 224 ) ∗ 2 = 2048 种可能
在测试时,网络通过提取5个224*224的块(四个角的图像块和中心的图像块)和他们的水平映射(因此总计10个图像块)来做预测,并将网络Softmax层在10个块上作的预测进行平均。
- 改变训练集图片RGB通道的强度,在此之前需要对原始RGB图像进行主成分分析
![[I_{xy}^{R},I_{xy}^{G},I_{xy}^{B}]=[I_{xy}^{R},I_{xy}^{G},I_{xy}^{B}]^{T}+[p1,p2,p3][a1\lambda 1,a2\lambda 2,a3\lambda 3]^{T}](https://1000bd.com/contentImg/2024/04/16/a2a4169d04d049d6.png)
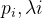 为RGB像素值的3x3协方差矩阵,
为RGB像素值的3x3协方差矩阵,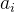 是均值为0标准差为0.1的高斯扰动。个人推测应该是先对RGB图像resize成3x(256x256),归一化后根据协方差公式得到3x3矩阵,再利用奇异值分解得到特征值λ和特征向量p
是均值为0标准差为0.1的高斯扰动。个人推测应该是先对RGB图像resize成3x(256x256),归一化后根据协方差公式得到3x3矩阵,再利用奇异值分解得到特征值λ和特征向量p
3.6 dropoutalexnet在前两层全连接层前使用了dropout,以0.5的概率使得每个隐藏层的神经元输出0,既不参与前向传播,也不参与反向传播。这种方法弱化了神经元之间的依赖性。
4.参考:
1、【深度学习论文 01-1】AlexNet论文翻译 - 最菜程序员Sxx - 博客园2、卷积神经网络超详细介绍_呆呆的猫的博客-CSDN博客_卷积神经网络
3、目标识别基础——alexnet模型(代码复现详解)_哔哩哔哩_bilibili
4、AlexNet 中的 LRN(Local Response Normalization) 是什么 - 知乎
-
相关阅读:
喷淋式蒸发器
C++&QT day10
[论文笔记]MacBERT
出海 SaaS 企业增长修炼手册2:Kyligence 落地 PLG 是如何避坑的?
如何创建自己的Spring Boot Starter并为其编写单元测试
AERMOD模型在大气环境影响评价中的实践
Flink学习第六天——Flink常见的运行部署模式介绍和运行流程浅析
点击标签给文本域(Textarea)赋值,文本域支持手动输入
论文解读《Measuring and Relieving the Over-smoothing Problem for Graph NeuralNetworks from the Topological View》
【布局优化】基于帝国企鹅算法求解潮流计算的电力系统总线优化问题附matlab代码
- 原文地址:https://blog.csdn.net/qq_41427793/article/details/128116157
