-
跨越速运如何构建实时统一的运单分析
作者:张杰,跨越速运大数据架构师(本文为作者在 StarRocks Summit Asia 2022 上的分享)
作为大型现代化综合速运企业,跨越速运拥有 3000 多家服务网点 ,日均处理 30 多万票运单。海量运单数据涌来,统一 OLAP 引擎、建设实时数仓、将极速数据分析能力应用到多个场景,成为了跨越速运大数据部门的核心工作目标。
通过将 StarRocks 作为大数据引擎支持,跨越速运的单笔运单计算时长从 90 秒缩短到 4 秒,单位时间内订单计算量提升了 400%,每年节省了百万级成本开销。
本文就将着重分享跨越速运如何利用 StarRocks 构建统一极速的运单分析。主要内容包括:OLAP 引擎统一,实时数仓建设,多场景应用,总结和展望。
#01
OLAP 引擎统一
1、业务背景
跨越速运是一家主营“限时速运”服务的大型现代化综合速运企业,拥有“国家AAAAA级物流企业”、“国家级高新技术企业”、“中国物流行业 30 强优秀品牌”、“中国电商物流行业知名品牌”、“广东省诚信物流企业”等荣誉称号。跨越速运拥有员工 5万+ 名,服务网点 3000+ 家,覆盖城市 500+ 个, 日均处理 30万+ 票。
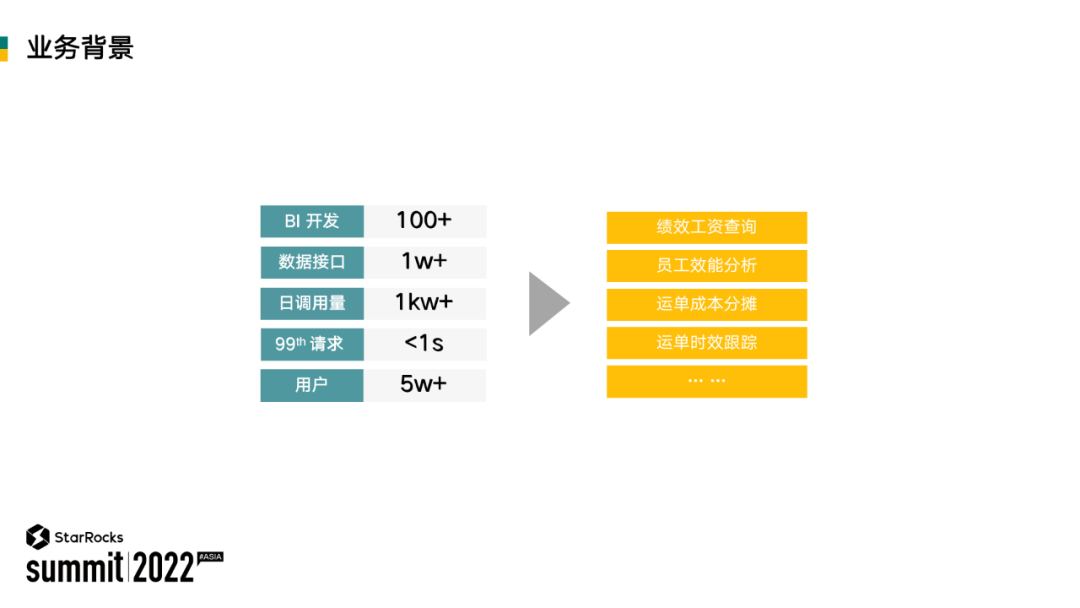
跨越速运的大数据中心提供了标准的大数据平台,为 Java 开发、基于场景的数据分析、定制化 BI 开发等需求提供了 100 多个相关基础工具、产品和服务组件。
集团大数据平台提供 1 万多个接口,客户可以使用这些接口来获取相关数据并开发实现所需的定制 IT 服务产品。平台所提供接口每天被调用的次数达到千万级数据量。
上游业务系统包括集团 ERP 系统或是业务移动端应用系统等对大数据平台的数据服务的时效性要求较高,99% 的响应时间都需要达到 1 秒以下。
大数据平台使用者包括整个集团所属的五万多名员工,涉及到所有的内外部生产数据,比如核算运单业务和绩效考核等等。
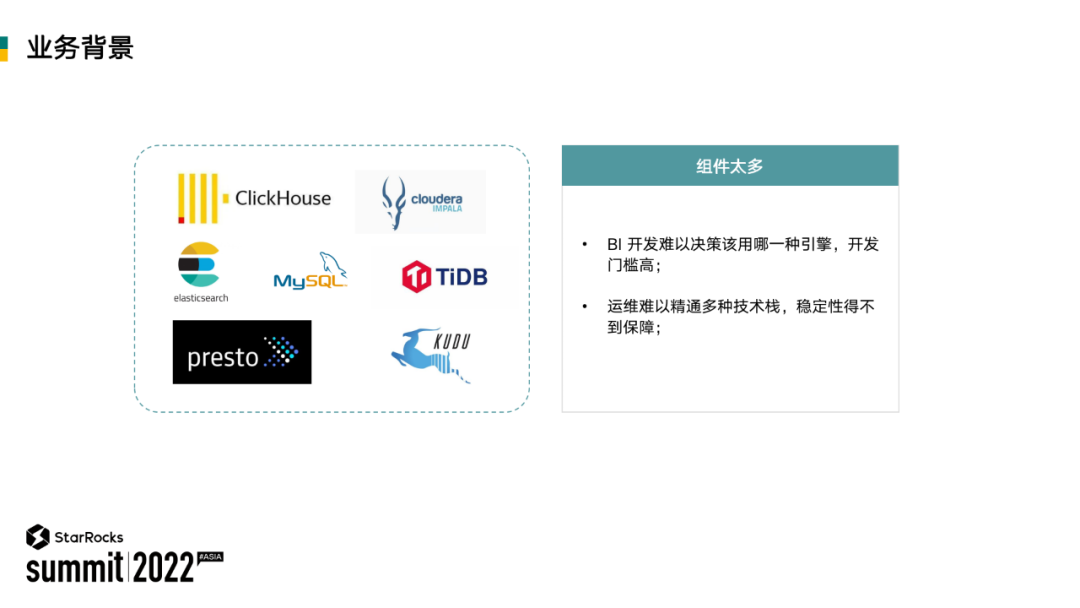
集团业务信息化早期,由于数据量和业务场景都相对较少,MySQL 被用来满足实际需要。后来随着数据量增多,场景增多,加入了大数据查询引擎 Presto 和易扩展 ES 引擎的相关使用,来满足大规模数据存贮和查询的需求。
后期又为了满足实时性需求,加入了 Impala + Kudu 的引擎,也加入 TiDB 的引擎,即便当时存在多种引擎的支持,但是在多表关联查询和大宽表聚合查询上的性能仍然存在一定的问题。
再后来加入了 ClickHouse,虽然在查询性能上得到了较大提升,但是也带了新的问题,比如维护性的工作增加、开发模式改变等,并且 ClickHouse 在多表关联查询的功能表现上较弱,无法满足实际业务需求。
基于以上变化,最后造成的局面就是 BI 开发人员在进行业务场景开发时需要判断到底需要哪种引擎来实现需求,出现了引擎选择困难。并且系统运维也需要对多种大数据引擎都有一定了解,才能满足维持系统稳定性的工作需求,变相增加了工作压力和响应了工作效率。
下图展示了使用 Presto 大数据查询引擎时,查询时间的表现,可以看到性能并不理想,工作时间段内 3 秒、5 秒等超时情况非常多,大量时间被花费在 SQL 性能优化上。

2、查询引擎选型
为了解决大数据平台引擎选择困难和运维保障要求高的技术痛点,大数据团队于 2021 年下半年做了要进行引擎收敛的决策。大数据团队根据实际运单场景和历史经验,并且使用同样的硬件机器和数据集,定义了满足自身需求的 Benchmark 标准,要求所选引擎既要有好的查询性能,又要能支持数据实时更新,满足实时报表的需求。
如下为性能测试结果对比图,可以看到 StarRocks 的表现要优于其他三种引擎。

3、引擎收敛
最终大数据团队保留了两个引擎,ES 引擎和 StarRocks 引擎。
ES 引擎可以解决大规模数据的明细查询问题,比如针对几个月或者是整年的数据明细下钻,数据并发查询等。
StarRocks 引擎则有以下优点:
-
AP 查询性能优异,市面上难有对手。
-
兼容 MySQL 协议,对集团上游的系统完美结合,直接连接 MySQL 驱动即可完成连接,相关查询语法与 MySQL 兼容。
-
支持主键更新模型,可以解决实时问题。
-
支持多种类型的外表,支持联邦查询,支持 ES 外表、Hive 外表、集群之间的外表等更多场景。
-
集群维护简单,对第三方组件依赖较少。
-
集成了大数据平台相关工具,比如数据加载工具 Stream Load 和 Spark Load 等,优化了数据导入,比如上亿数据量导入时间从几小时缩短到几分钟。

4、最终收益
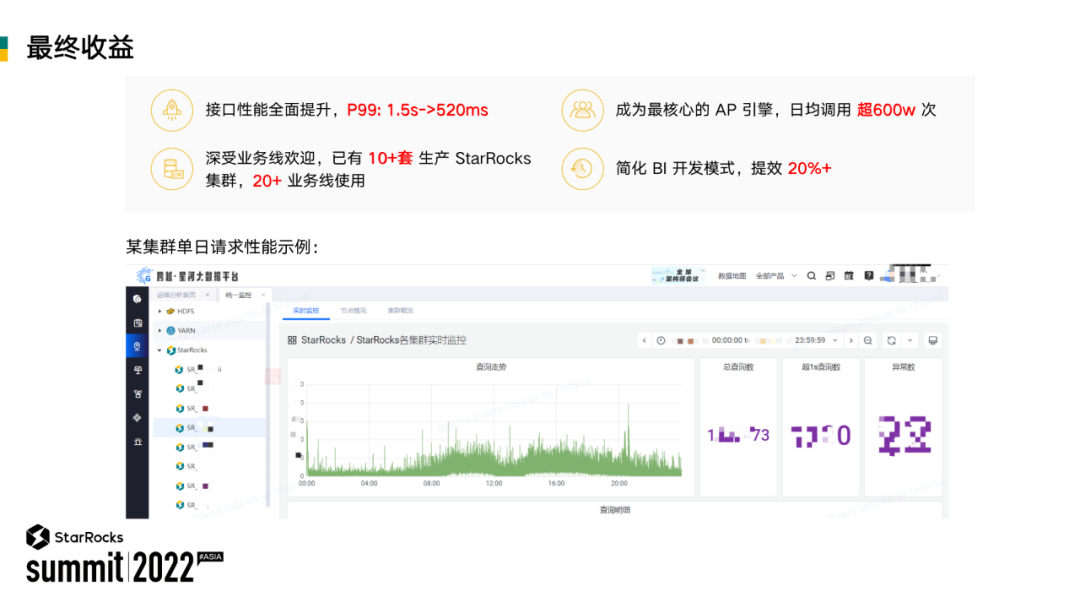
引擎收敛的结果在以下各个方面都比较突出:
-
引擎变化带来的业务接口查询速度提升,接口查询速度达到毫秒级。一方面 BI 开发人员不用在 SQL 优化上花费太多时间,从而把精力放到业务理解上。用户在使用上体验提升,无延迟等待感。
-
成为核心引擎,日均调用 600万+ 次,10+ 套 StarRocks 集群满足了 20 多个业务的需求。
-
简化了 BI 开发模式,比如开发人员不需要把时间消耗在引擎选择上,加快开发进度。之前的架构中需要 ETL 过程所操作的数据预处理工具也可以通过 StarRocks 引擎上来实现。效能提升了 20%。
#02
实时数仓建设
1、运单分析-背景
大数据中心需要汇总上游各个业务系统数据,如销售、物流、绩效工时等相关数据,融合成大的运单宽表给到用户使用,下游包括 ERP 铸剑系统、BI 工具和星河大数据平台。
数据使用中就会遇到一些问题:
-
字段多,合并效率低
-
多维度分析 SQL 性能有待提升

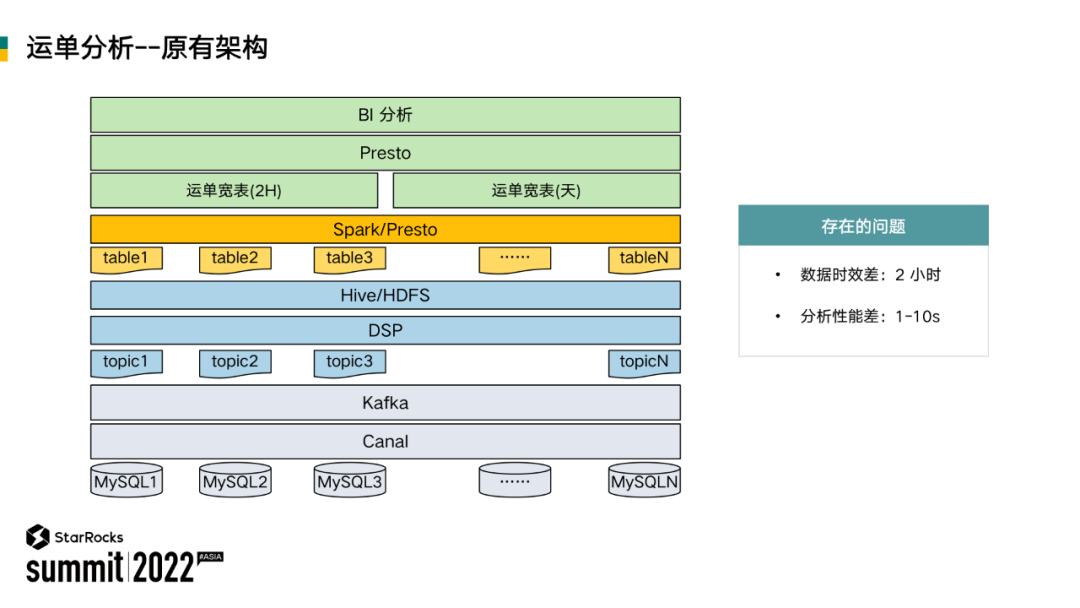
2、运单分析-原有架构
在原有数据处理架构中,数据都是来自上游各个业务系统的 MySQL。通过 Binlog 用 Canal 工具同步到 Kafka,再通过一些自建的数据同步的工具,将数据同步到 Hive 的表上。这些数据是 5 分钟更新。基于这些更新,我们又做了离线处理逻辑,做宽表的合并,由最先的每天提供一次缩短到 2 个小时,无法再缩短。并且宽表中做数据查询速度也要 1 秒到 10 秒,查询延迟感较为明显,不能满足预期,使用体验较差。
3、运单分析-现有架构
现有数据架构处理中,宽表的字段合并交由 HBase 进行处理,上游可能有几十个 topic,利用 HBase CDC 的功能,将宽表的所有字段反向同步回 Kafka,就只有一个 topic 了,再用实时的 Flink 写到 StarRocks 中。基于 StarRocks 我们构建了运单实时宽表,所有运单分析都是基于 StarRocks 来做数据分析,在 StarRocks 我们接入了自己的 BI 工具。这样整个链路的时效从 2 小时缩短到 5 秒以内,并且数据接口查询速度变为 3 秒以内,提升非常明显。

4、运单分析-收益
目前实时数仓的查询性能比 Presto 提升了 300%,并且最新的 StarRocks 采用了 PK 模型(Primary Key Model),比之前的 UK 模型(Unique Key Model)在性能上提升了 200%。
另外,我们使用了 Flink StarRocks Connector,能够把数据实时地写入到 StarRocks 中去,能够按主键整行更新,并且整个链路更新时效小于 5 秒。

#03
多应用场景
运转成本优化项目,其目标是实现每笔订单运转成本最优。如下所示,从业务数据中抽取运单数据,实时同步到中间引擎上,原来使用的是 Impala+Kudu,后面替换成了 StarRocks。数据在计算引擎汇聚后,我们用 Java 程序做系统调用,去计算最优运转方式,推荐给业务方,辅助其决策。
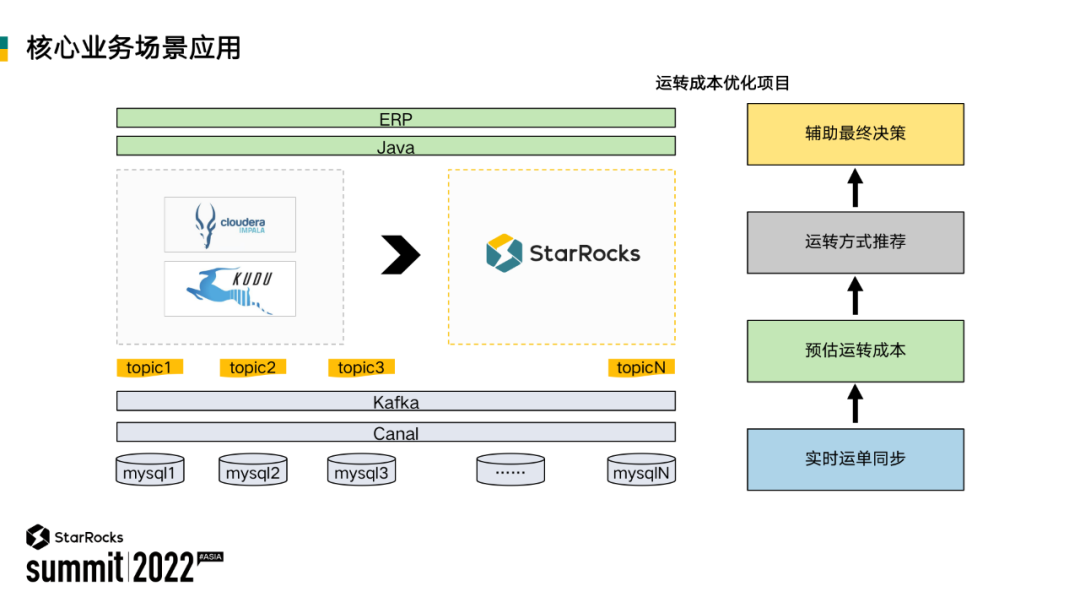
如下图所示,业务最优的计算逻辑是在始发地和目的地之间寻找最经济路线,从而节省相关不必要成本。比如一笔订单从深圳发往东莞,正常流程是收件、分拨进入中转场,再一级级派送给用户,环节繁多。但其实始发地与目的地之间距离很近,通过直达的方式,可以节省很多成本。
采用 Java 调用,中间计算过程由 StarRocks 去实现,主要利用了 StarRocks 微批的能力和并发的能力。
通过新的 StarRocks 大数据引擎支持,最新的单笔运单计算时长从以前的 90 秒缩短到现在的 4 秒。并且由于其强大的批处理能力和并发计算能力,单位时间内订单计算量提升了 400%。
以前需要 15 台大数据节点来支持运单计算任务,现在使用 4 台新型大数据引擎就能完成需求。通过单笔运单优化,每年节省百万级成本开销。

#04
总结与展望
1. 过往经验
利用 StarRocks 的极致 AP 性能,对之前的五六套大数据引擎做了收敛。
StarRocks 大数据引擎中的主键模型实现了所需的实时数仓分析场景,带来了较好的使用体验,并且在核心业务场景上实现了成本的降低。
2. 未来尝试
未来将在以下三个方面进一步挖掘新引擎的价值:
-
将使用新特性来验证资源隔离问题,进而减少集群的数量,降低成本,减少维护人员压力。
-
基于新引擎,探索准实时性问题的解决方案。
-
解决版本一致性问题,统一各个场景下新引擎的使用版本,降低维护复杂度和降低风险发生概率,提升集群稳定性。
关于 StarRocks
StarRocks 创立两年多来,一直专注打造世界顶级的新一代极速全场景 MPP 数据库,帮助企业建立“极速统一”的数据分析新范式,助力企业全面数字化经营。
当前已经帮助腾讯、携程、顺丰、Airbnb 、滴滴、京东、众安保险等超过 170 家大型用户构建了全新的数据分析能力,生产环境中稳定运行的 StarRocks 服务器数目达数千台。
2021 年 9 月,StarRocks 源代码开放,在 GitHub 上的星数已超过 3600 个。StarRocks 的全球社区飞速成长,至今已有超百位贡献者,社群用户突破 7000 人,吸引几十家国内外行业头部企业参与共建。
-
-
相关阅读:
网络安全:个人信息保护,企业信息安全,国家网络安全的重要性
主流接口测试框架对比
linux centos7 rpm 安装 mysql5.7
【电源专题】开关电源中的电感电流测量
哎,又跟HR在小群吵了一架!
RAW图像处理软件Capture One 23 Enterprise mac中文版功能特点
没有root权限如何通过apt安装deb软件
UG\NX二次开发 获取所有子部件,封装两个函数
安装新操作系统需要注意的问题
Jackson ImmunoResearch通过 SDS-PAGE 进行蛋白质分离
- 原文地址:https://blog.csdn.net/StarRocks/article/details/128113376