-
【Kafka】Kafka的重复消费和消息丢失问题
前言
在Kafka中,生产者(Producer)和消费者(Consumer)是通过发布订阅模式进行协作的,生产者将消息发送到Kafka集群,而消费者从Kafka集群中拉取消息进行消费,无论是生产者发送消息到Kafka集群还是消费者从Kafka集群中拉取消息进行消费,都是容易出现问题的,比较典型的就是消费端的重复消费问题、生产端和消费端产生的消息丢失问题。下面将对这两个问题出现的场景以及常见的解决方案进行讲解。
一、重复消费
1.1 重复消费出现的场景
重复消费出现的常见场景主要分为两种,一种是 Consumer在消费过程中,应用进程被强制kill掉或者发生异常退出(挂掉…),另一种则是Consumer消费的时间过长。
1.1.1 Consumer消费过程中,进程挂掉/异常退出
在Kafka消费端的使用中,位移(Offset)的提交有两种方式,自动提交和手动提交。自动提交情况下,当消费者拉取一批消息进行消费后,需要进行Offset的提交,在消费端提交Offset之前,Consumer挂掉了,当Consumer重启后再次拉取Offset,这时候拉取的依然是挂掉之前消费的Offset,因此造成重复消费的问题。在手动提交模式下,在提交代码调用之前,Consumer挂掉也会造成重复消费。
1.1.2 消费者消费时间过长
Kafka消费端的参数
max.poll.interval.ms定义了两次poll的最大间隔,它的默认值是 5 分钟,表示 Consumer 如果在 5 分钟之内无法消费完 poll方法返回的消息,那么Consumer 会主动发起“离开组”的请求。在离开消费组后,开始Rebalance,因此提交Offset失败。之后重新Rebalance,消费者再次分配Partition后,再次poll拉取消息依然从之前消费过的消息处开始消费,这样就造成重复消费。而且若不解决消费单次消费时间过长的问题,这部分消息可能会一直重复消费。
整体上来说,如果我们在消费中将消息数据处理入库,但是在执行Offset提交时,Kafka宕机或者网络原因等无法提交Offset,当我们重启服务或者Rebalance过程触发,Consumer将再次消费此消息数据。
1.2 重复消费解决方案
1.2.1 针对于消费端挂掉等原因造成的重复消费问题
这部分主要集中在消费端的编码层面,需要我们在设计代码时以幂等性的角度进行开发设计,保证同一数据无论进行多少次消费,所造成的结果都一样。处理方式可以在消息体中添加唯一标识(比如将消息生成md5保存到Mysql或者是Redis中,在处理消息前先检查下Mysql/Redis是否已经处理过该消息了),消费端进行确认此唯一标识是否已经消费过,如果消费过,则不进行之后处理。从而尽可能的避免了重复消费。
幂等角度大概两种实现:- 将唯一标识存入第三方介质(如Redis),要操作数据的时候先判断第三方介质(数据库或者缓存)有没有这个唯一标识。
- 将版本号(offset)存入到数据里面,然后再要操作数据的时候用这个版本号做乐观锁,当版本号大于原先的才能操作。
1.2.2 针对于Consumer消费时间过长带来的重复消费问题
- 提高单条消息的处理速度。例如对消息处理中比较耗时的操作可通过异步的方式进行处理、利用多线程处理等。
- 其次,在缩短单条消息消费时常的同时,根据实际场景可将
max.poll.interval.ms值设置大一点,避免不必要的rebalance,此外可适当减小max.poll.records的值,默认值是500,可根据实际消息速率适当调小。
二、消息丢失
在Kafka中,消息丢失在Kafka的生产端和消费端都会出现。在此之前我们先来了解一下生产者和消费者的原理。
2.1 生产端问题
生产者原理:
Kafka生产者生产消息后,会将消息发送到Kafka集群的Leader中,然后Kafka集群的Leader收到消息后会返回ACK确认消息给生产者Producer。主要拆解为以下几个步骤。- Producer先从Kafka集群找到该Partition的Leader。
- Producer将消息发送给Leader,Leader将该消息写入本地。
- Follwer从Leader pull消息,写入本地Log后Leader发送ACK。
- Leader 收到所有 ISR 中的 Replica 的 ACK 后,增加High Watermark,并向 Producer 发送 ACK。
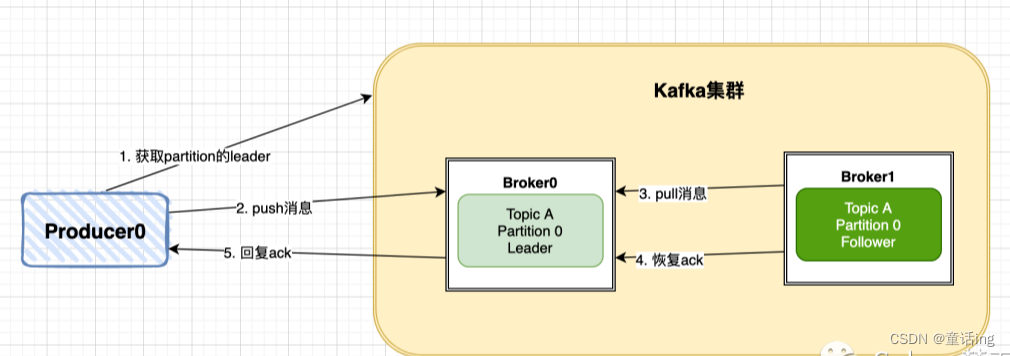
因此,Kafka集群(其实是分区的Leader)最终会返回一个ACK来确认Producer推送消息的结果,这里Kafka提供了三种模式: NoResponse RequiredAcks = 0:这个代表的就是不进行消息推送是否成功的确认。WaitForLocal RequiredAcks = 1:当local(Leader)确认接收成功后,就可以返回了。WaitForAll RequiredAcks = -1:当所有的Leader和Follower都接收成功时,才会返回。
因此这个配置的影响也分为下面三种情况:
- 设置为0,Producer不进行消息发送的确认,Kafka集群(Broker)可能由于一些原因并没有收到对应消息,从而引起消息丢失。
- 设置为1,Producer在确认到 Topic Leader 已经接收到消息后,完成发送,此时有可能 Follower 并没有接收到对应消息。此时如果 Leader 突然宕机,在经过选举之后,没有接到消息的 Follower 晋升为 Leader,从而引起消息丢失。
- 设置为-1,可以很好的确认Kafka集群是否已经完成消息的接收和本地化存储,并且可以在Producer发送失败时进行重试。
生产端解决消息丢失方案:
- 通过设置RequiredAcks模式来解决,选用WaitForAll(对应值为-1)可以保证数据推送成功,不过会影响延时。
- 引入重试机制,设置重试次数和重试间隔。
- 当然,最后就是使用Kafka的多副本机制保证Kafka集群本身的可靠性,确保当Leader挂掉之后能进行Follower选举晋升为新的Leader。
2.2 消费端问题
消费端的消息丢失问题:
消费端的消息丢失主要是因为在消费过程中出现了异常,但是对应消息的 Offset 已经提交,那么消费异常的消息将会丢失。
前面介绍过,Offset的提交包括手动提交和自动提交,可通过kafka.consumer.enable-auto-commit进行配置。
手动提交可以灵活的确认是否将本次消费数据的Offset进行提交,可以很好的避免消息丢失的情况。
自动提交是引起消息丢失的主要诱因。因为消息的消费并不会影响到Offset的提交。
大部分的解决方案为了尽可能的保证数据的完整性,都是尽量去选用手动提交的方式,当数据处理完之后再进行提交。
当然,在golang中我们主要使用sarama包的Kafka,sarama自动提交的原理是先进行标记,再进行提交,如下代码所示:type exampleConsumerGroupHandler struct{} func (exampleConsumerGroupHandler) Setup(_ ConsumerGroupSession) error { return nil } func (exampleConsumerGroupHandler) Cleanup(_ ConsumerGroupSession) error { return nil } func (h exampleConsumerGroupHandler) ConsumeClaim(sess ConsumerGroupSession, claim ConsumerGroupClaim) error { for msg := range claim.Messages() { fmt.Printf("Message topic:%q partition:%d offset:%d ", msg.Topic, msg.Partition, msg.Offset) // 标记消息已处理,sarama会自动提交 // 处理数据(如真正持久化mysql...) sess.MarkMessage(msg, "") } return nil- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
因此,我们完全可以在标记之前进行数据的处理,例如插入Mysql等,当出现插入成功后程序崩溃,下一次最多重复消费一次(因为还没标记,Offset没有提交),而不会因为Offset超前,导致应用层消息丢失了。
手动提交模式下当然是很灵活的控制的,但确实已经没必要了:
consumerConfig := sarama.NewConfig() consumerConfig.Version = sarama.V2_8_0_0 consumerConfig.Consumer.Return.Errors = false consumerConfig.Consumer.Offsets.AutoCommit.Enable = false // 禁用自动提交,改为手动 consumerConfig.Consumer.Offsets.Initial = sarama.OffsetNewest func (h msgConsumerGroup) ConsumeClaim(sess sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error { for msg := range claim.Messages() { fmt.Printf("%s Message topic:%q partition:%d offset:%d value:%s ", h.name, msg.Topic, msg.Partition, msg.Offset, string(msg.Value)) // 插入mysql.... // 手动提交模式下,也需要先进行标记 sess.MarkMessage(msg, "") consumerCount++ if consumerCount%3 == 0 { // 手动提交,不能频繁调用 t1 := time.Now().Nanosecond() sess.Commit() t2 := time.Now().Nanosecond() fmt.Println("commit cost:", (t2-t1)/(1000*1000), "ms") } } return nil }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
三、参考
1、Go语言如何操纵Kafka保证无消息丢失
2、kafka消息重复消费和消息丢失
3、sarama Kafka客户端生产者与消费者梳理
4、Kafka丢数据、重复消费、顺序消费的问题 -
相关阅读:
使用opencv qt 以及 tensorflow2 进行神经网络分类
基础架构之Redis
软件测试需求分析是什么?为什么需要进行测试需求分析?
算法通过村第十七关-贪心|青铜笔记|贪心也很简单呕
Git(一)Windows下安装及使用Git Bash
《数据结构与算法基础 by王卓老师》学习笔记——1.4算法与算法分析
什么牌子的蓝牙耳机耐用又便宜?好用的蓝牙耳机品牌推荐
带你一起理解什么是数据库分片?
如何找回误删的文件呢?
java毕业设计鑫通物流车辆调度系统mp4Mybatis+系统+数据库+调试部署
- 原文地址:https://blog.csdn.net/dl962454/article/details/128087396