-
快排图文详解:快速排序算法的实现 - 【双边循环法与单边循环法 & 递归与非递归(栈的方式)的实现】
1.基本介绍
同冒泡排序一样,快速排序(Quicksort)也属于交换排序,通过元素之间的比较和交换位置来达到排序的目的。但快速排序是对冒泡排序的一种改进。
2.基本思想
关于基本思想,我们在这里先不考虑是如何具体实现的,先明白最终能达到什么样的效果。
不同的是,冒泡排序在每一轮中只把1个元素冒泡到数列的一端。
而快速排序则是 在每一轮排序前先挑选出一个
基准元素 pivot,并让其他比它大的元素移动到数列一边,比它小的元素移动到数列的另一边。📝 例如,我们规定 基准元素为待排序数组的第一个元素,使用快速排序后的数组结果为:

然后再按此方法对
左子数组和右子数组分别进行快速排序, 整个排序过程可以递归进行,直到最终的子数组都只有一个元素就不需要对该子数组进行排序,递归停止,实际就是通过分而治之的思想减少排序中交换和遍历的次数,以此达到整个数据变成有序序列。📚 分而治之:就是把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题……直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。这个技巧是很多高效算法的基础,如排序算法(快速排序,归并排序),傅立叶变换(快速傅立叶变换)……
分治法在每一层递归上都有三个步骤:
- 分解:将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题
- 解决:若子问题规模较小而容易被解决则直接解,否则递归地解各个子问题
- 合并:将各个子问题的解合并为原问题的解。

3.元素交换完成排序
明白了基本思想,选定了
基准值 pivot,我们主要的问题就是 每轮排序中如何实现基准值的左边都是小于或等于基准值的元素,基准值的右边是大于或等于基准值的元素。3.1 双边循环法
3.1.1 步骤一:如何完成一轮排序
3.1.1.1 思路分析
-
初始化
- 分别在数组的头尾设置两个指针
左指针 left和右指针 right,其中 left 和 right 的值是数组索引。 - 将头部元素作为
基准值 pivot,其中 pivot 的值是 数组索引。
- 分别在数组的头尾设置两个指针
-
先判断右指针和基准值,如果右指针指向的元素值 大于等于基准位置元素值 或者 不与左指针重合 就向前移动,否则停止移动。
-
再判断左指针和基准值,如果左指针指向的元素值 小于等于基准位置元素值 或者 不与右指针重合 就向后移动,否则停止移动。
-
判断是否左右指针是否重合
-
如果 未重合,交换左指针索引位置的元素值和右指针索引位置的元素值。交换完毕,再回到第二步依次往下执行(重复第2,3,4步的操作)。
📍 左指针找到的是比基准位置元素值大的数,右指针找到的是比基准位置元素值小的数。
将左右指针的索引位置元素值进行交换,就是把大的数放到数组右边,把小的数放到数组左边。那么最终的效果是:
- 数组的左边都是小于或等于基准位置元素值的数
- 数组的右边都是大于或等于基准位置元素值的数
-
如果 重合了,将重合指针索引位置的元素值与基准数位置的值进行交换。此轮排序结束。
❓ 重合了为什么将重合指针索引位置的元素值与基准数位置的值进行交换?
我们先考虑一下 left 和 right 指针重合的两种情况:
1️⃣ right 指针的移动导致两指针重合:
经过上一轮循环后,此时 left 指针所指的元素一定是小于或等于 基准元素值的(即使此时是第一轮循环,left也是指向头部元素,肯定满足小于等于基准元素值),因此我们将 头部元素值 与 left指针指向的值交换依旧可以满足 左子树组是全小于等于 基准元素值的,右子数组是全大于等于基准元素值的,并且两个子数组的分隔索引就是left和right重合的索引位置。
2️⃣ left 指针的移动导致两指针重合:
left指针移动,说明此时在执行思路分析的第三步,因为我们在思路分析的时候是先判断右指针和基准元素值的大小即第二步,所以此时右指针指向的值一定是小于等于基准元素值的。因此left移动后与right指针重合,我们将 头部元素值 与 left指针指向的值交换依旧可以满足 左子树组是全小于等于 基准元素值的,右子数组是全大于等于基准元素值的,并且两个子数组的分隔索引就是left和right重合的索引位置。
💬 我们可以得出一个结论:两指针重合时,一定满足重合位置的元素值一定小于或等于基准元素值。
因此重合后将 left指向的元素 和 头部元素(基准索引值)进行交换:
- 不仅让左子数组依旧全部是 小于等于 基准索引值的 元素
- 而且将 重合后的left和right指向的位置成为了左子数组 和 右子数组 的分隔位置,解决了我们在第三节刚开始时提出的问题 - 每轮排序中如何实现基准值的左边都是小于或等于基准值的元素,基准值的右边是大于或等于基准值的元素。
这个就很巧妙了,我们也就完成了这一轮的排序。
-
3.1.1.2 图解过程

3.1.1.3 代码实现
package sort; /** * @author 狐狸半面添 * @create 2022-11-29 2:32 */ public class QuickSort { public static void main(String[] args) { int[] arr = {4, 7, 6, 5, 3, 2, 8, 1}; //对 arr 数组进行排序,指定了要对索引在 [0,arr.length-1] 内的元素进行一轮排序 quickSort(arr, 0, arr.length - 1); //输出结果:3 1 2 4 5 6 8 7 for (int i : arr) { System.out.print(i + "\t"); } } /** * 功能:对 数组索引在 [first, last] 范围内的元素进行一轮排序 * * @param arr 待排序的数组 * @param first 待排序数组的第一个元素的索引值,我们规定该索引的元素值也是基准值 * @param last 待排序数组的最后一个元素的索引值 */ public static void quickSort(int[] arr, int first, int last) { //定义一个中间变量 int temp; //定义左指针,初始值为待排序数组的头部 int left = first; //定义右指针,初始值为待排序数组的尾部 int right = last; while (true) { //先判断右指针和基准值,如果右指针指向的元素值 大于等于基准元素值 或者 不与左指针重合 就向前移动,否则停止移动。 while (arr[right] >= arr[first] && left < right) { right--; } //再判断左指针和基准值,如果左指针指向的元素值 小于等于基准元素值 或者 不与右指针重合 就向后移动,否则停止移动。 while (arr[left] <= arr[first] && left < right) { left++; } //判断是否重合 if (left < right) { //1.如果没有重合,就交换左右指针的值,继续下一次循环移动指针 temp = arr[left]; arr[left] = arr[right]; arr[right] = temp; } else { //2.如果重合,则将重合指针索引位置的元素值与基准数位置的值进行交换,本轮排序结束 temp = arr[left]; arr[left] = arr[first]; arr[first] = temp; break; } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
3.1.2 步骤二:递归完成对子数组的排序
3.1.2.1 思路分析
递归:一个含直接或间接调用本函数语句的函数称之为递归函数,它必须满足以下两个条件:
- 在每一次调用自己时,必须是(在某种意义上)更接近于解
- 必须有一个终止处理或计算的准则
📝 我们以具体示例分析一下,调用步骤一的方法对数组可以完成第一轮排序:
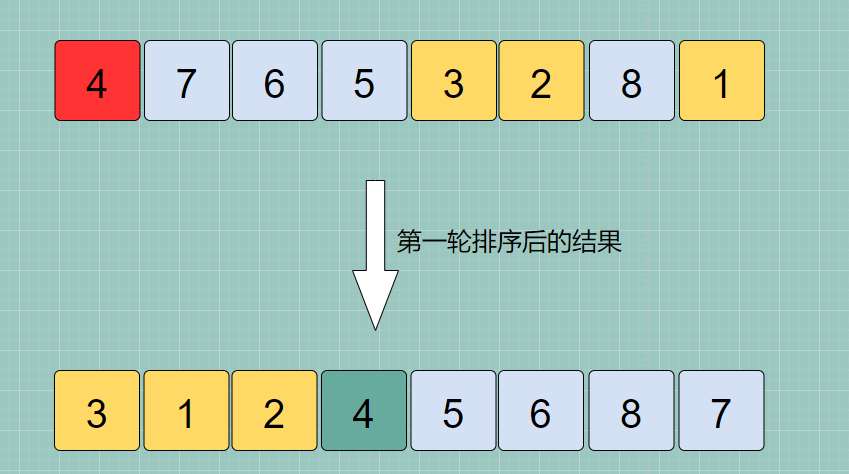
此时的 left 和 right 指针肯定都是指向 基准元素值为“4” 的索引位置的,那么接下来我们需要对基准索引位置的
左子数组 [3,1,2]与右子数组 [5,6,8,7]分别采取同第一轮排序时相同的策略(方法)分别进行排序:- 左子数组:基准索引元素值为 3 ,left 指向的元素值时 3 ,right 指向的元素值时 2
- 左子数组:基准索引元素值为 5 ,left 指向的元素值时 5 ,right 指向的元素值时 7
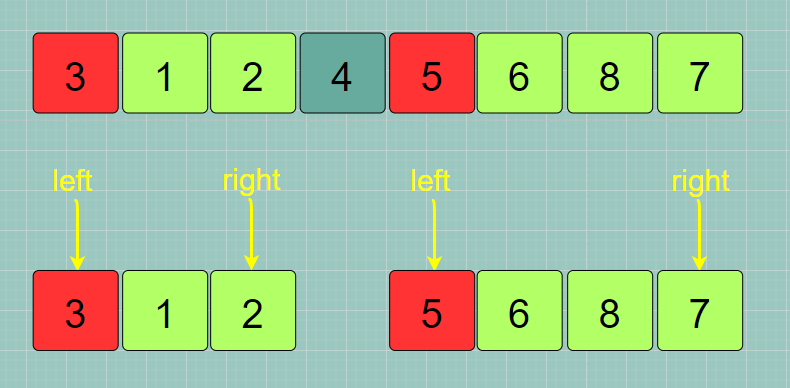
当最后的左子数组和右子数组没有元素或者只有一个元素时就不需要对该左子数组或右子数组进行排序了,这也就是递归终止的条件。
3.1.2.2 图解过程

3.1.2.3 代码实现
实现递归对子数组进行排序,我们只需要对
quickSort(int[] arr, int first, int last)的代码进行改进即可。package sort; /** * @author 狐狸半面添 * @create 2022-11-29 2:32 */ public class QuickSort { public static void main(String[] args) { int[] arr = {4, 7, 6, 5, 3, 2, 8, 1}; //对 arr 数组进行排序,指定了要对索引在 [0,arr.length-1] 内的元素进行一轮排序 quickSort(arr, 0, arr.length - 1); //输出:1 2 3 4 5 6 7 8 for (int i : arr) { System.out.print(i + "\t"); } } /** * 功能:对 数组索引在 [first, last] 范围内的元素进行一轮排序 * * @param arr 待排序的数组 * @param first 待排序数组的第一个元素的索引值,我们规定该索引的元素值也是基准值 * @param last 待排序数组的最后一个元素的索引值 */ public static void quickSort(int[] arr, int first, int last) { /* quickSort方法是对 索引在[first, last]范围内的元素进行排序, - 1.如果 first == last 说明此时只有一个元素了,很明显,一个元素是没有排序的必要的,因此直接退出 quickSort 方法即可,递归终止 - 2.如果 first > last 说明此时是没有元素的,那也不需要排序,递归终止 */ if(first >= last){ return; } //定义一个中间变量 int temp; //定义左指针,初始值为待排序数组的头部 int left = first; //定义右指针,初始值为待排序数组的尾部 int right = last; while (true) { //先判断右指针和基准值,如果右指针指向的元素值 大于等于基准元素值 或者 不与左指针重合 就向前移动,否则停止移动。 while (arr[right] >= arr[first] && left < right) { right--; } //再判断左指针和基准值,如果左指针指向的元素值 小于等于基准元素值 或者 不与右指针重合 就向后移动,否则停止移动。 while (arr[left] <= arr[first] && left < right) { left++; } //判断是否重合 if (left < right) { //1.如果没有重合,就交换左右指针的值,继续下一次循环移动指针 temp = arr[left]; arr[left] = arr[right]; arr[right] = temp; } else { //2.如果重合,则将重合指针索引位置的元素值与基准数位置的值进行交换,本轮排序结束 temp = arr[left]; arr[left] = arr[first]; arr[first] = temp; break; } } /* 退出了while循环,说明 left 指针 和 right 指针 已经重合。 对 [first, last]范围内的元素完成一轮排序后, 此时 左子数组即索引在 [first, left - 1] 的元素都是小于等于当前基准元素值的 右子数组即索引在 [left + 1, last] 的元素都是大于等于当前基准元素值的 那么我们只需要分别再对左子数组和右子数组分别进行排序即可 */ quickSort(arr,first,left-1); quickSort(arr,left+1,last); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
3.2 单边循环法
双边循环法从数组的两边交替遍历原数组,虽然更加直观,但是代码实现相对繁琐。而单边循环法则简单得多,只从数组的一边对元素进行遍历和交换。
当然,两种方法的目的是相同的,即:每轮排序后 基准值的左边都是小于或等于基准值的元素,基准值的右边是大于或等于基准值的元素。
3.2.1 思路分析
3.2.1.1 对于每轮排序的操作
-
初始化
- 将头部元素作为
基准值 pivot,其中 pivot 的值是 数组索引。 - 定义
mark指针初始时指向头部位置,作用是:保证 索引从头部位置的下一个位置到mark位置 的元素都是小于基准元素值的。font - 定义
travel指针初始时指向头部位置的下一个位置,作用是:遍历当前数组
- 将头部元素作为
-
travel指针向后移动,找到第一个小于基准元素值的元素 或 指针超出数组最大索引,就停止移动
-
判断 travel 是否超出当前数组最大索引
-
如果未超出:mark指针向后移动一位,travel 和 mark 指针指向的值进行交换,再回到第二步继续循环操作
首先我们需要明白排序的目的:把所有比基准值小或等于的元素放到数组左边,把所有比基准值大或等于的元素放到数组左边。
travel指针 每次找到一个比基准值小的,就将 此时travel指向的元素放到数组左边,这时候我们的mark指针就起到了作用。
我们规定并始终保证 索引从头部位置的下一个位置到mark位置 的元素都是小于基准元素值的。 。因此将 mark指针 每次向后移动一位后,指向的元素一定是travel指针跳过的那些大于等于基准元素值的元素。此时将 mark指向的值和travel指向的值交换可以达到两个目的:
- 比基准元素值小的移到了左边,即再次保证了 索引从头部位置的下一个位置到mark位置 的元素都是小于基准元素值的。
- 比基准元素值大或等于的(不包括头部元素)移到了右边。
-
如果超出:将 mark 指针指向的值 与 头部元素值(基准元素值)进行交换,本次排序完成。
📍 对于 存在上一次循环,即mark指针不是指向头部元素的分析:
因为 mark指针 在完成上一轮循环的交换后一定是指向小于基准值的元素,保证了索引从头部位置的下一个位置到mark位置 的元素都是小于基准元素值的。那么mark指针的右边肯定都是大于等于基准值的。
所以,如果我们将 mark 指针指向的值 与 头部元素值(基准元素值)进行交换,可以达到三个效果:
- 索引从头部位置到(mark-1)位置 的元素都是小于基准索引值的
- mark 位置的元素值变成了 基准元素值
- 索引从(mark+1)位置到 尾部位置 的元素都是大于等于基准索引值的
我们也就达到了排序的目的:每轮排序后 基准值的左边都是小于或等于基准值的元素,基准值的右边是大于或等于基准值的元素。
📍 对于 不存在上一次循环,即mark指针指向的是头部元素的分析:
我们依旧可以进行交换,自己交换自己不会改变什么。并且这种情况说明当前数组并不存在比基准元素值小的元素,使得头部元素的右边都是大于等于基准元素值的。
-
3.2.1.2 递归完成对子数组的排序
我们需要明白,双边循环法和单边循环法不同的只是每一轮排序的方式,但最终的效果都会是一样的,即每轮排序后 基准值的左边都是小于或等于基准值的元素,基准值的右边是大于或等于基准值的元素。
因此,我们在之前双边循环法里的步骤二的代码实现并不需要改变,只需要改变双边循环法的步骤一的代码实现即可!!!
3.2.2 图解每轮排序操作
对于每轮排序的操作,如果只是文字描述你可能比较难理解,我们对第一次排序的过程进行图解分析,你再结合上面的思路分析,来看看是怎样一个原理与过程:
💬 特别注意观察 索引从头部位置的下一个位置到mark位置 的元素值与基准元素值的大小关系

3.2.3 代码实现
package sort; /** * @author 狐狸半面添 * @create 2022-11-29 2:32 */ public class QuickSort { public static void main(String[] args) { int[] arr = {4, 7, 6, 5, 3, 2, 8, 1}; //对 arr 数组进行排序,指定了要对索引在 [0,arr.length-1] 内的元素进行一轮排序 quickSort(arr, 0, arr.length - 1); //输出:1 2 3 4 5 6 7 8 for (int i : arr) { System.out.print(i + "\t"); } } /** * 功能:对 数组索引在 [first, last] 范围内的元素进行一轮排序 * * @param arr 待排序的数组 * @param first 待排序数组的第一个元素的索引值,我们规定该索引的元素值也是基准值 * @param last 待排序数组的最后一个元素的索引值 */ public static void quickSort(int[] arr, int first, int last) { /* quickSort方法是对 索引在[first, last]范围内的元素进行排序, - 1.如果 first == last 说明此时只有一个元素了,很明显,一个元素是没有排序的必要的,因此直接退出 quickSort 方法即可,递归终止 - 2.如果 first > last 说明此时是没有元素的,那也不需要排序,递归终止 */ if (first >= last) { return; } //定义一个中间变量 int temp; //定义mark指针,初始值为待排序数组的头部 int mark = first; //定义travel指针,初始值为待排序数组的头部位置 + 1,作用是对数组进行遍历 int travel = first + 1; // 遍历当前数组 while (true) { //travel指针向后移动,找到第一个小于基准元素值的元素 或 指针超出数组最大索引,就停止移动 while (travel <= last && arr[travel] >= arr[first]) { travel++; } /* 判断 travel 是否超出当前数组最大索引 - 如果未超出:mark指针向后移动一位,travel 和 mark 指针指向的值进行交换,travel向后移动,再回到第二步继续循环操作 - 如果超出:将 mark 指针指向的值 与 头部元素值(基准元素值)进行交换,本次排序完成。 */ if(travel <= last){ //未超出 mark++; temp = arr[travel]; arr[travel] = arr[mark]; arr[mark] = temp; //发生交换后,travel需要向后移动一位 //这个必须写,是针对于 mark == travel的情况下,arr[travel]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
3.2.4 另一种代码实现
根本的思路与第一种是一样的,但是会更为清晰,如果你明白了上面的,那下面的也不会很难理解:
package sort; /** * @author 狐狸半面添 * @create 2022-11-29 2:32 */ public class QuickSort { public static void main(String[] args) { int[] arr = {4, 7, 6, 5, 3, 2, 8, 1}; //对 arr 数组进行排序,指定了要对索引在 [0,arr.length-1] 内的元素进行一轮排序 quickSort(arr, 0, arr.length - 1); //输出:1 2 3 4 5 6 7 8 for (int i : arr) { System.out.print(i + "\t"); } } /** * 功能:对 数组索引在 [first, last] 范围内的元素进行一轮排序 * * @param arr 待排序的数组 * @param first 待排序数组的第一个元素的索引值,我们规定该索引的元素值也是基准值 * @param last 待排序数组的最后一个元素的索引值 */ public static void quickSort(int[] arr, int first, int last) { /* quickSort方法是对 索引在[first, last]范围内的元素进行排序, - 1.如果 first == last 说明此时只有一个元素了,很明显,一个元素是没有排序的必要的,因此直接退出 quickSort 方法即可,递归终止 - 2.如果 first > last 说明此时是没有元素的,那也不需要排序,递归终止 */ if (first >= last) { return; } //定义一个中间变量 int temp; //定义mark指针,初始值为待排序数组的头部 int mark = first; //定义travel指针,初始值为待排序数组的头部位置 + 1,作用是对数组进行遍历 int travel = first + 1; // 遍历当前数组 for(;travel<=last;travel++){ if(arr[travel]<arr[first]){ //找到了比基准元素值小的数,就交换 mark++; temp = arr[travel]; arr[travel] = arr[mark]; arr[mark] = temp; } } //遍历完毕,将 mark指向的值 与 头部元素值(基准元素值)进行交换 temp = arr[mark]; arr[mark] = arr[first]; arr[first] = temp; /* 对 [first, last]范围内的元素完成一轮排序后, 此时 左子数组即索引在 [first, mark - 1] 的元素都是小于当前基准元素值的(注意与双边循环法不同,不存在等于基准元素值的,等于的都在右子数组) 右子数组即索引在 [mark + 1, last] 的元素都是大于等于当前基准元素值的 那么我们只需要分别再对左子数组和右子数组分别进行排序即可 */ quickSort(arr, first, mark - 1); quickSort(arr, mark + 1, last); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
4.非递归实现双边/单边循环法
我们已经给出了三种递归方式的代码实现,由于递归的代码操作都是一样的,因此在这里我们就只将双边循环法的代码改造为非递归的方式,其他两种也是同理操作即可。
4.1 说明
绝大多数的递归逻辑,都可以使用栈的方式来代替。
代码中一层一层的方法调用,本身就是用来一个方法调用栈。每次进入一个新方法,就相当于入栈;每次有方法返回,就相当于出栈。所以,可以把原来的递归实现转化成一个栈的实现,在栈中存储每一次方法调用的参数。
4.2 代码实现
package sort; import java.util.HashMap; import java.util.Map; import java.util.Stack; /** * @author 狐狸半面添 * @create 2022-11-29 2:32 */ public class QuickSort { public static void main(String[] args) { int[] arr = {4, 7, 6, 5, 3, 2, 8, 1}; //对 arr 数组进行排序,指定了要对索引在 [0,arr.length-1] 内的元素进行一轮排序 quickSortByStack(arr, 0, arr.length - 1); //输出:1 2 3 4 5 6 7 8 for (int i : arr) { System.out.print(i + "\t"); } } public static void quickSortByStack(int[] arr, int first, int last) { //用一个集合栈来代替递归的函数栈 Stack<Map<String, Integer>> quickSortStack = new Stack<>(); //整个数列的起止下标,以 哈希的形式入栈 Map<String, Integer> rootParam = new HashMap<>(2); rootParam.put("firstIndex", first); rootParam.put("lastIndex", last); quickSortStack.push(rootParam); //基准位置索引 int pivot; //循环结束的条件为栈空 while (!quickSortStack.isEmpty()) { Map<String, Integer> param = quickSortStack.pop(); int firstIndex = param.get("firstIndex"); int lastIndex = param.get("lastIndex"); pivot = quickSort(arr, firstIndex, lastIndex); if (pivot != -1) { //将左子数组和右子数组加入到栈中 Map<String, Integer> leftArrParam = new HashMap<>(2); leftArrParam.put("firstIndex", firstIndex); leftArrParam.put("lastIndex", pivot - 1); quickSortStack.push(leftArrParam); Map<String, Integer> rightArrParam = new HashMap<>(2); rightArrParam.put("firstIndex", pivot + 1); rightArrParam.put("lastIndex", lastIndex); quickSortStack.push(rightArrParam); } } } /** * 功能:对 数组索引在 [first, last] 范围内的元素进行一轮排序 * * @param arr 待排序的数组 * @param first 待排序数组的第一个元素的索引值,我们规定该索引的元素值也是基准值 * @param last 待排序数组的最后一个元素的索引值 * @return 最终的基准位置索引 */ public static int quickSort(int[] arr, int first, int last) { /* quickSort方法是对 索引在[first, last]范围内的元素进行排序, - 1.如果 first == last 说明此时只有一个元素了,很明显,一个元素是没有排序的必要的,因此直接退出 quickSort 方法即可 - 2.如果 first > last 说明此时是没有元素的,那也不需要排序 */ if (first >= last) { return -1; } //定义一个中间变量 int temp; //定义左指针,初始值为待排序数组的头部 int left = first; //定义右指针,初始值为待排序数组的尾部 int right = last; while (true) { //先判断右指针和基准值,如果右指针指向的元素值 大于等于基准元素值 或者 不与左指针重合 就向前移动,否则停止移动。 while (arr[right] >= arr[first] && left < right) { right--; } //再判断左指针和基准值,如果左指针指向的元素值 小于等于基准元素值 或者 不与右指针重合 就向后移动,否则停止移动。 while (arr[left] <= arr[first] && left < right) { left++; } //判断是否重合 if (left < right) { //1.如果没有重合,就交换左右指针的值,继续下一次循环移动指针 temp = arr[left]; arr[left] = arr[right]; arr[right] = temp; } else { //2.如果重合,则将重合指针索引位置的元素值与基准数位置的值进行交换,本轮排序结束 temp = arr[left]; arr[left] = arr[first]; arr[first] = temp; break; } } return left; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
5.快速排序在一个极端情况下的问题
在我们之前写的规则与代码中,都是将数组的第一个元素作为基准。这种选择在绝大多数情况下是没有问题的。但是,如果有一个原本是逆序的队列,期望使用快速排序形成顺序队列,会发生什么呢?
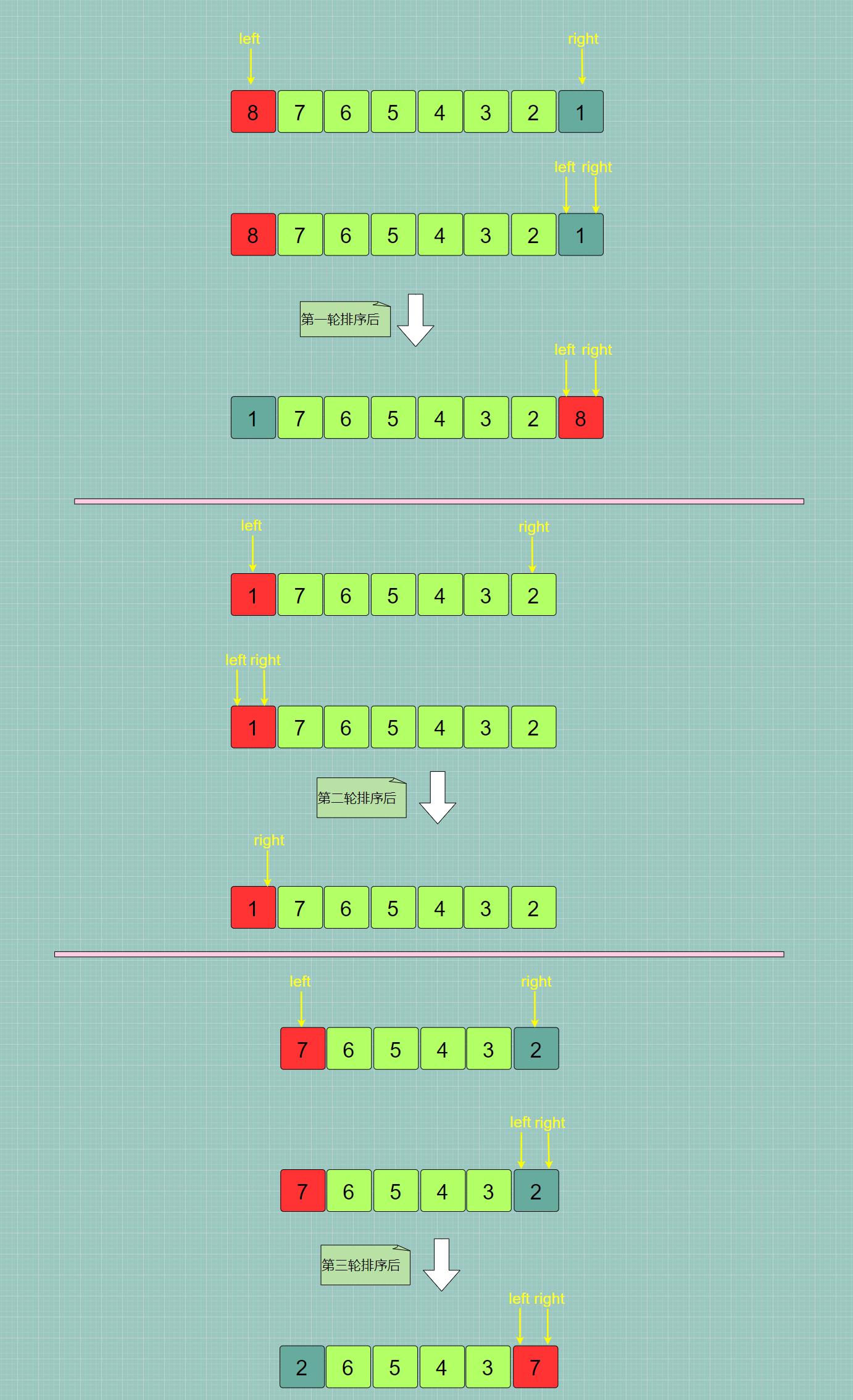
可以看到,整个数组并没有被很好的分成两半,基准元素的最终位置总是在最左边或者最右边,而不在中间,无法发挥分治法的优势。因此在这种极端情况下,快速排序需要进行 n 轮,时间复杂度退化为 O ( n 2 ) O(n^2) O(n2)
应该怎样避免呢?我们可以随机选择一个元素作为基准元素,并让该基准元素和数组首元素交换位置。这样首元素就成了基准元素。
这样一来,即使在数列完全逆序的情况下,也能有效地将数列分成两部分。
当然,即使是随机选择基准元素,也会有极小的可能宣导数列的最小值或最大值,同样会影响分治的效果。
6.快速排序的时间复杂度
通过上述的分析,我们就可以知道快速排序的平均时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn) ,但最坏情况下的时间复杂度是 O ( n 2 ) O(n^2) O(n2)
-
相关阅读:
【C进阶】动态内存管理
Python:>、>>、&、&& 的区别与用法
Java IO流 要点
C#关键字汇总
javascript基础七:说说你对Javascript中作用域的理解?
基于RFID的自动化仓储设备研发项目可行性研究报告
【前端攻城师之JS基础】02JS对象基础
【leetcode】【剑指offer Ⅱ】065. 最短的单词编码
JAVA 单例模式
身份证读卡器Qt语言实现Linux系统开发集成
- 原文地址:https://blog.csdn.net/qq_62982856/article/details/128108211
