-
矩池云|GPU 分布式使用教程之 TensorFlow
GPU 分布式使用教程之 TensorFlow
TensorFlow 提供了6种策略实现分布式计算,各个策略详情请参考官方文档。本文档使用 MirroredStrategy 实现单机多卡分布式,MultiWorkerMirroredStrategy 实现多机多卡分布式计算。
选择机器
-
单机多卡分布式:租用同个计算节点的多张卡即可。
-
多机多卡分布式:需要先申请开通 分布式集群 功能,点击这里申请开通,在租用时,请选择带有如图所示图标的机器。没有这个图标的机器不支持加入分布式网络。
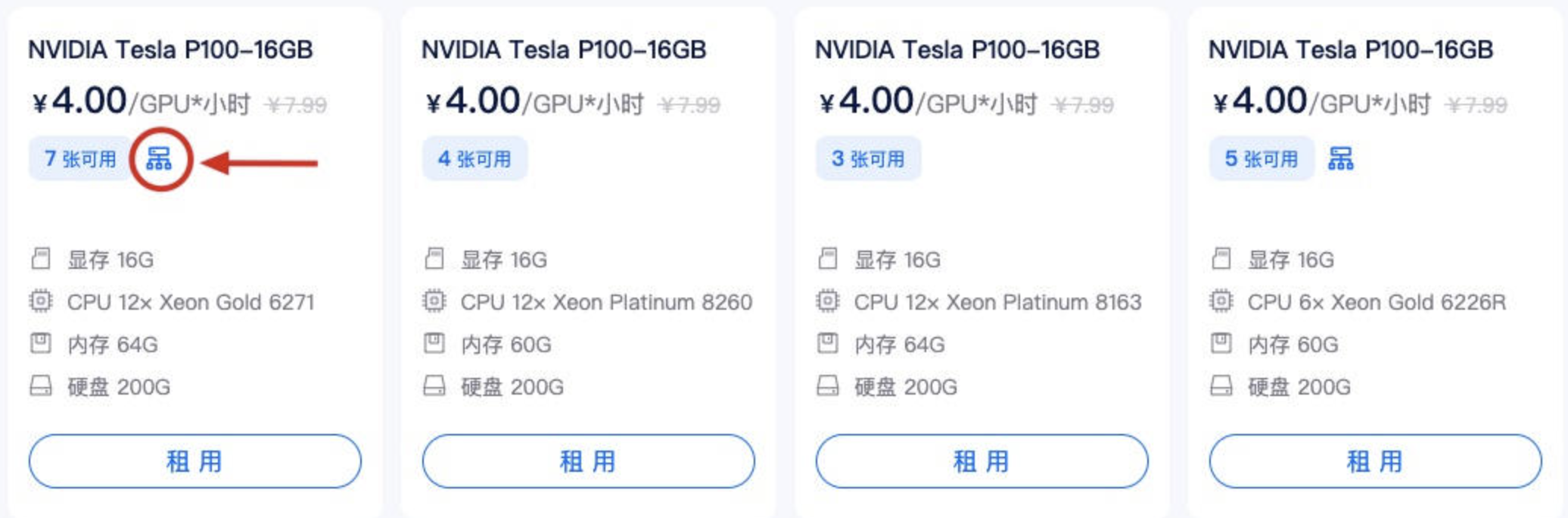
单机多卡
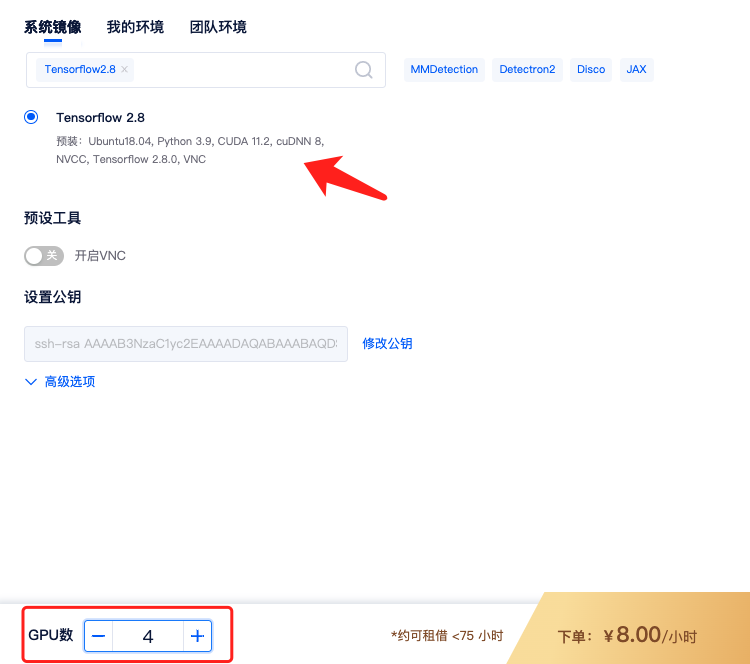
1)租用机器: 为实现TensorFlow的单机多卡分布式,首先,您需要按正常流程租用GPU,如单节点 4 卡 A2000,选择TensorFlow镜像,如TensorFlow2.8镜像。
租用的时候 GPU 数设置成 4,即表示 4 卡,对应显存、内存等配置也会翻倍。
2)适配代码: 单机多卡分布式使用 MirroredStrategy 需对脚本进行相应修改,点击下载测试代码(将下面代码写入机器中的一个 .py 文件即可,如:tf-demo.py ):
3)运行代码: 进入运行脚本所在目录,输入命令行,如:
# 进入脚本目录 cd /mnt/test/multi-card/tf # 解压数据集到当前目录 unzip /public/tensorflow_datasets/cats_vs_dogs/kagglecatsanddogs_3367a.zip -d ./cats_vs_dogs # 安装缺的依赖包 pip install tensorflow_datasets # 运行程序 python tf-demo.py- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4)查看GPU使用情况: 租用界面点击
详情按钮即可查看 GPU、CPU使用情况。从截图中可以看到 4 个显卡都有使用到。
多机多卡
多机多卡使用需要先申请开通 分布式集群 功能,点击这里申请开通
1)租用机器: 首先,您需要按正常流程租用 GPU,除了上文提到的通过图标直接选择支持分布式集群的机器外,还可以在主机市场筛选栏选择
支持分布式集群筛选,然后选择自己需要的机器租用即可。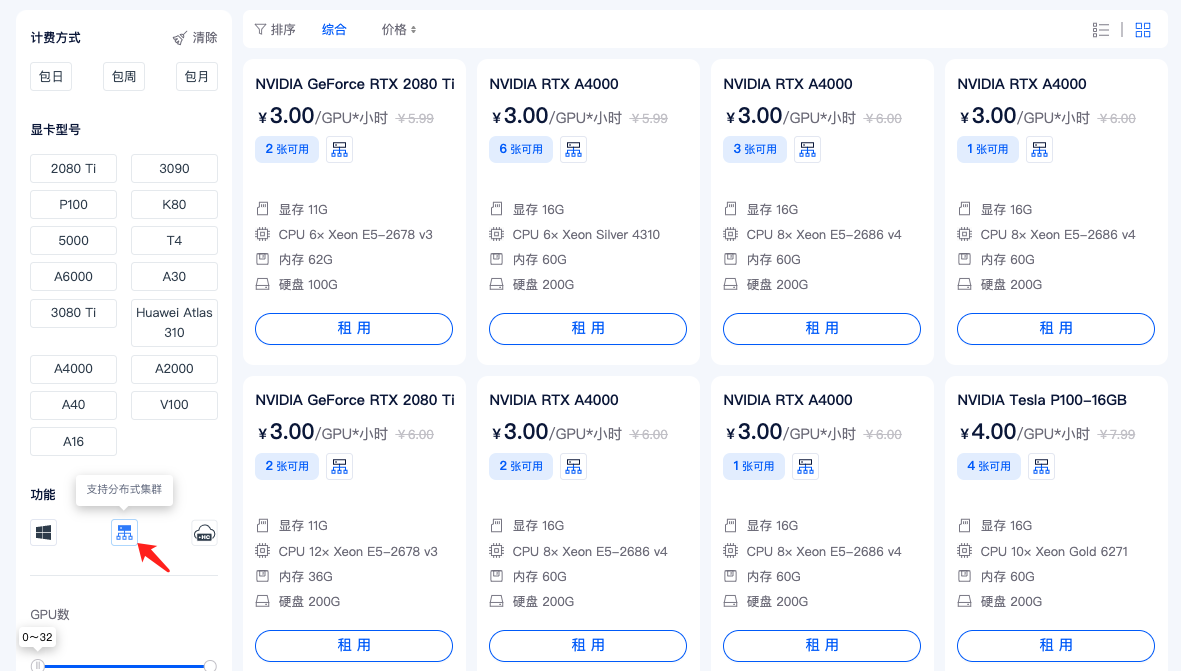
如两个计算节点,租用两台 A2000 4,共计 8 卡。选择相同的 TensorFlow 镜像,如 TensorFlow2.8 镜像。

注意: 单机多卡中每个节点的 GPU 卡数应该一样,才能都使用上,机器类型也最好一样。
2)创建集群: 进入 【个人中心】 — 【我的租用】 — 【分布式集群】。
分布式集群需要先进行申请,申请通过后,点击【添加集群】- 【添加机器】—【确定】。
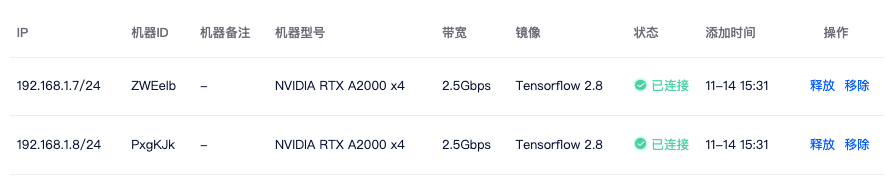
3)添加机器: 点击集群页面添加机器按钮,勾选要加入集群的机器,点击确定,即可将租用机器添加到集群。

添加机器成功后,系统会给每个节点分配集群 IP,当状态为已连接时,代表机器间可相互通信。
4)添加机器: 登录任一节点。因密钥由您掌握,故需由您按以下步骤完成节点间的ssh连通:
ssh-keygen -t rsa # 一路默认,生成公私钥 ssh-copy-id root@其他节点IP #分发给其他节点,输入对应密钥。IP可在我的集群页面查看,如192.168.1.1- 1
- 2
5)适配代码: 注意和单机多卡不同,多机多卡使用了 MultiWorkerMirroredStrategy,并配置了’TF_CONFIG’网络设置:
os.environ['TF_CONFIG'] = json.dumps({ 'cluster': { 'worker': ["192.168.1.7:20005", "192.168.1.8:20006"] }, 'task': {'type': 'worker', 'index':0} })- 1
- 2
- 3
- 4
- 5
- 6
其中 cluster 包含了全部节点的IP和端口信息,所有节点此部分相同;task包含当前节点的角色,例如节点一为worker 0,节点二为worker 1。
点击下载测试代码(将下面代码写入机器中的一个 .py 文件即可,如:tf-demo2.py ):
6)运行程序: 登录主节点,进入运行脚本所在目录,输入命令行,如:
# 进入脚本目录 cd /mnt/test/multi-card/tf # 解压数据集到当前目录 unzip /public/tensorflow_datasets/cats_vs_dogs/kagglecatsanddogs_3367a.zip -d ./cats_vs_dogs # 安装缺的依赖包 pip install tensorflow_datasets # 运行程序 python tf-demo2.py --num_workers 2 --worker_no 0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
测试代码中,
--num_workers指定节点数(总共2个节点),用于设定batch_size,--worker_no指定节点顺序(主节点故为0号)。登录剩余节点,运行:
cd /mnt/test/multi-card/tf python tf-demo2.py --num_workers 2 --worker_no 1- 1
- 2
其中,
--worker_no指定节点顺序(第二个节点故为1号),如有更多节点,需做相应修改,其他参数不用修改。运行后,系统会自动连接并运行训练任务。7)查看GPU使用情况: 租用界面点击
详情按钮即可查看 GPU、CPU使用情况。

-
-
相关阅读:
基于袋獾算法的无人机航迹规划-附代码
Cesium 根据鼠标点击生成点击点的坐标信息
Transformer论文精读
力扣刷题日记——哈希
深入理解Elasticsearch中的Match Phrase查询
Python 函数进阶-高阶函数
「Java 数据结构和算法」:图文详解---中缀表达式转后缀表达式。
【信息安全】-虚拟专用网络
@ControllerAdvice 注解使用及原理探究
Flutter pubspec.yaml 配置文件
- 原文地址:https://blog.csdn.net/weixin_48344945/article/details/128097332