-
Spring更加简单地存储Bean
目录
前提引入
我们可以回顾一下之前是怎么将Bean对象存储到Spring中,又是怎么从Spring中取出来的.
1.创建一个Spring项目
- 创建一个Maven项目
- 添加Spring依赖(spring-context,spring-beans)
- 创建一个启动类
2.将Bean对象存储到Spring中
- 首先先要创建出一个Bean对象(这里是要配置一个XML(spring-config.xml))
- 然后将Bean对象存储到Spring中
3.从Spring中取出Bean对象
- 利用getBean来获取Bean对象(也会有不同的方式 1.id(标识) 2.类型 3.id(标识) + 类型)
- 然后调用Bean对象的方法来使用Bean
上面是我们开篇Spring学习的怎么将Bean对象存储到Spring中,又是怎么从Spring中获取出Bean对象.那我们有没有更加简洁的方式来将Bean对象存储到Spring中和从Spring中取出Bean么?
答案是当然可以. 我们先来说如何简单地去存Bean对象到Spring中.
更加简单地存储Bean对象到Spring中
首先创建Spring项目那是必须的,第一步当然是省不了的..
我们再来看一看怎么根据以前存储的方式进行改进呢?
- 首先先要创建出一个Bean对象
- 然后将Bean对象存储到Spring中
既然要将Bean对象存储到Spring中,那么肯定是必须要有一个Bean对象的.这个是肯定改进不了的.
还有一个 是将Bean对象存储到Spring中的.
我们之前好像是这么做的,在Spring配置文件中,添加一个Bean标签,然后bean标签里面要填写属性信息,一个属性是Bean的标识id,一个是要将哪个类的对象存储到Spring中->也就是类型.
- "1.0" encoding="UTF-8"?>
- <beans xmlns="http://www.springframework.org/schema/beans"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://www.springframework.org/schema/beans
- http://www.springframework.org/schema/beans/spring-beans.xsd">
- <bean id = "user" class = "com.sfx.User">
- bean>
- beans>
这时我们以前的做法,每次存放一个Bean对象到Spring中都要添加一个Bean标签填写属性id+class.这步显然是很麻烦的,这步是可以改进的~~~
怎么进行改进呢 ?
context:component-scan
我们需要做一些前置工作,需要在Spring-config.xml(spring的配置文件)中在加上一个context:component-scan的标签(或者说是一个节点).
这样的一个节点 :
在创建Spring项目的时候在spring-config.xml(spring的配置文件)中配置这一行标签后,spring就会自动地去扫描base-package对应路径或者该路径下的字包的Java文件,如果扫描到该文件里包含这5大注解(@controller,@Service,@Rspository,@Component,@Configuration)的这些类,就将这些类注册为Spring中的Bean对象
base-package属性 : 告诉Spring要扫描的包,会扫描包含@controller,@Service,@Rspository,@Component,@Configuration)这5大类注解修饰的类
- "1.0" encoding="UTF-8"?>
- <beans xmlns="http://www.springframework.org/schema/beans"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xmlns:content="http://www.springframework.org/schema/context"
- xsi:schemaLocation="http://www.springframework.org/schema/beans
- http://www.springframework.org/schema/beans/spring-beans.xsd
- http://www.springframework.org/schema/context
- https://www.springframework.org/schema/context/spring-context.xsd">
- <content:component-scan base-package="com.sfx">
- content:component-scan>
- beans>
没错,在Spring中更加简便的方式就是使用注解.
既然我们知道在spring配置文件中添加一个节点,spring就会扫描base-package指定的包的路径或者子包下的java类有没有加那5大类注解,如果加了5大注解将这些类注册为Spring中的Bean对象
将Bean存储到Spring中用到的注解
我们接下来讲一讲spring用到的注解
如果要想bean对象存储到Spring中,在spring有两种类型的注解 分别是方法注解和类注解
5大类注解 : @controller,@Service,@Rspository,@Component,@Configuration
方法注解 : @Bean
我们先讲一下这5大类注解都有什么作用呢 ? 再来说一说为什么会有这么多类注解?
Controller
controller 就是控制器的意思,也为控制器存储.controller层就是当前端发送数据给后端的时候,所要经过的第一层.Controller层主要是验证前端传递的参数,就好像安检一样,如果传递的不对,就不会继续往下执行了.
Service
Service为服务的意思,服务存储,
service 是应用层对外提供的接口,主要进行服务的编排和汇总
怎么理解编排 ?
就比如现在有两个操作,你是先干哪个,后干哪个呢?
举一个具体的例子 : 你要做一个业务,就是用户在修改头像的时候,同时要给用户加5个积分.
编排就是 我是先进行修改图像,在加积分 或者是先加积分 在修改头像--->这两个的顺序就是进行编排
怎么理解汇总 ?
就比如你要对数据库表进行操作,那么对数据库表操作的接口都是在服务层.或者说这些接口都在一个Service方法里面. Service不实现具体的操作,就好像志愿者一样,你告诉他你要干什么,他就会告诉你接下来要做些什么.
Repository
Repository 是仓库的意思,准确地来说是数据仓库,直接操作数据库的,进行数据表的操作
Component
Component 是组件的意思,不是进行业务操作,根业务不相关的.一种通用化的工具类
比如密码类 这个是与业务不相关的.
Configuration
Configuration主要是放着一些项目中的配置.项目中的所有配置都放在Configuration层.
这5大类注解都是可以将类注册为Spring中的Bean,将对象/Bean存放在Spring中
使用Controller类注解将对象存到Spring中.
- //和前端进行交互的第一层(主要验证前端传递过来的参数-->进行校验和验证==>相当于安检的作用)
- @Controller
- public class UserController {
- public void sayHello(){
- System.out.println("do UserController!!!");
- }
- }
使用Service类注解将对象存储到Spring中
- //主要是进行服务的编排和汇总
- @Service
- public class UserService {
- public void doUserService(){
- System.out.println("do UserService()!!!");
- }
- }
使用类注解Repository将对象存储到Spring中
- //数据仓库 ,直接来操作数据库的,做一些数据表的操作
- @Repository
- public class UserRepository {
- public void doUserRepository(){
- System.out.println("do User Repository()!!!");
- }
- }
使用类注解Component将对象存储到Spring中
- //组件 一种通用化的工具类 与业务无关
- @Component
- public class UserComponent {
- public void doUserComponent(){
- System.out.println("do doUserComponent()!!!");
- }
- }
使用类注解Configuration将对象存储到Spring中
- //配置 ,所有的项目配置都放在Configuration层
- @Configuration
- public class UserConfiguration {
- public void doUserConfiguration(){
- System.out.println("do UserConfiguration()!!!");
- }
- }
这五大类注解都有什么关系呢 ?
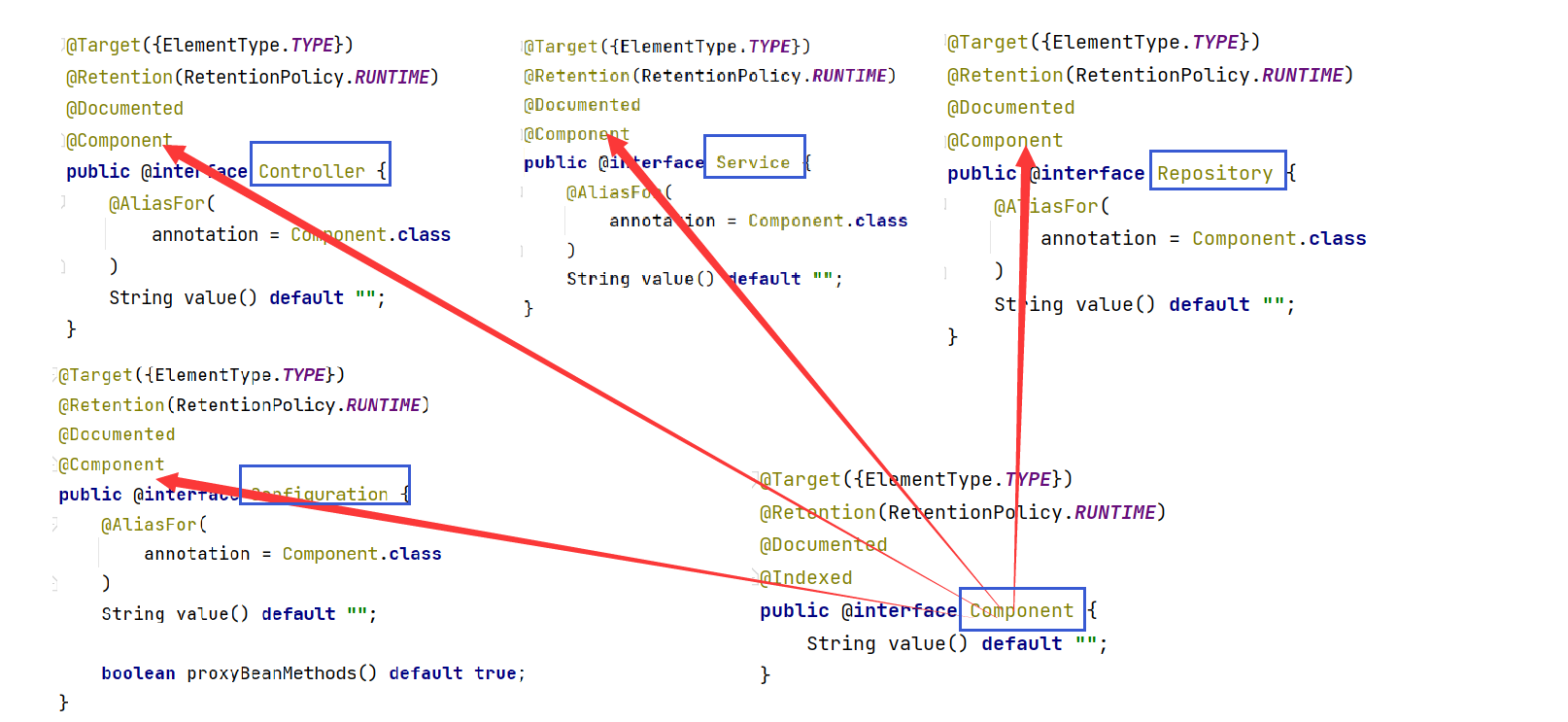
可以发现Controller , Service , Repository, Configuration.这四大注解都用到了Component注解,都是基于Componenet注解的,是Component的子类,它们都可以将Bean存储到Spring中.
为什么要有这么多类注解有什么作用么 ?
有这么多类注解,是为了让程序员很好地区分哪一层的作用是什么.用途是什么,就比如咱们国家就把区域划分为省,市,县,区......为了更好地区分.这样做的目的可以让我们的程序更加的精细化,如果出错了方便去对应的层去查找错误,程序员看到这一层就知道这一层是干什么的,程序可读性更好.
比如 看到 Controller层就知道是与前端进行交互的第一层,主要用来校验前端发来的参数
看到Service层就知道它是服务层,进行服务的编排和汇总,看到Repository就知道它是持久层,直接可以操作数据库的.看到Component就知道它主要是放着通用化的工具类,看到Configuration层就知道它是放着项目的所有配置的.
Bean命名规则
我们总结一下Bean的名称命名规则,在上面的文章里面并没有将,那个Bean名称(id)就默认使用的是原类名首字母小写.
那是不是所有的Bean名称都遵循按照原类名首字母小写的规则呢?
我们重新来演示一下 普通类名(正常类名都是都字母大写的-->大驼峰的形式)

我们再来演示一下 如何原类名是开头两个字母都是大写的呢?

但是当我们将Bean名称改为原类名就不一样了

Bean命名规则源码分析
对于这种问题,我们搞不清楚可以看一看源码.但是由于代码太多,我们只能技巧性的去找对应的源码.
我们遇到的问题就是 : 当我们使用不同的类名的时候,Bean的名称也是不同的.这个时候我们试着在Idea中搜索BeanName看有没有收获...




我们现在就可以总结一下 :
当原类名的前两个字母是大写的情况下,那么Bean的名称就是原类名.
否则的话Bean的名称就是原类名首字母小写.
我们也可以使用一下源码的那个方法检验一下

Bean注解
Bean注解就是将方法返回的对象存储/注册 到Spring中.

那么,怎么取从Spring中取对象呢 ??
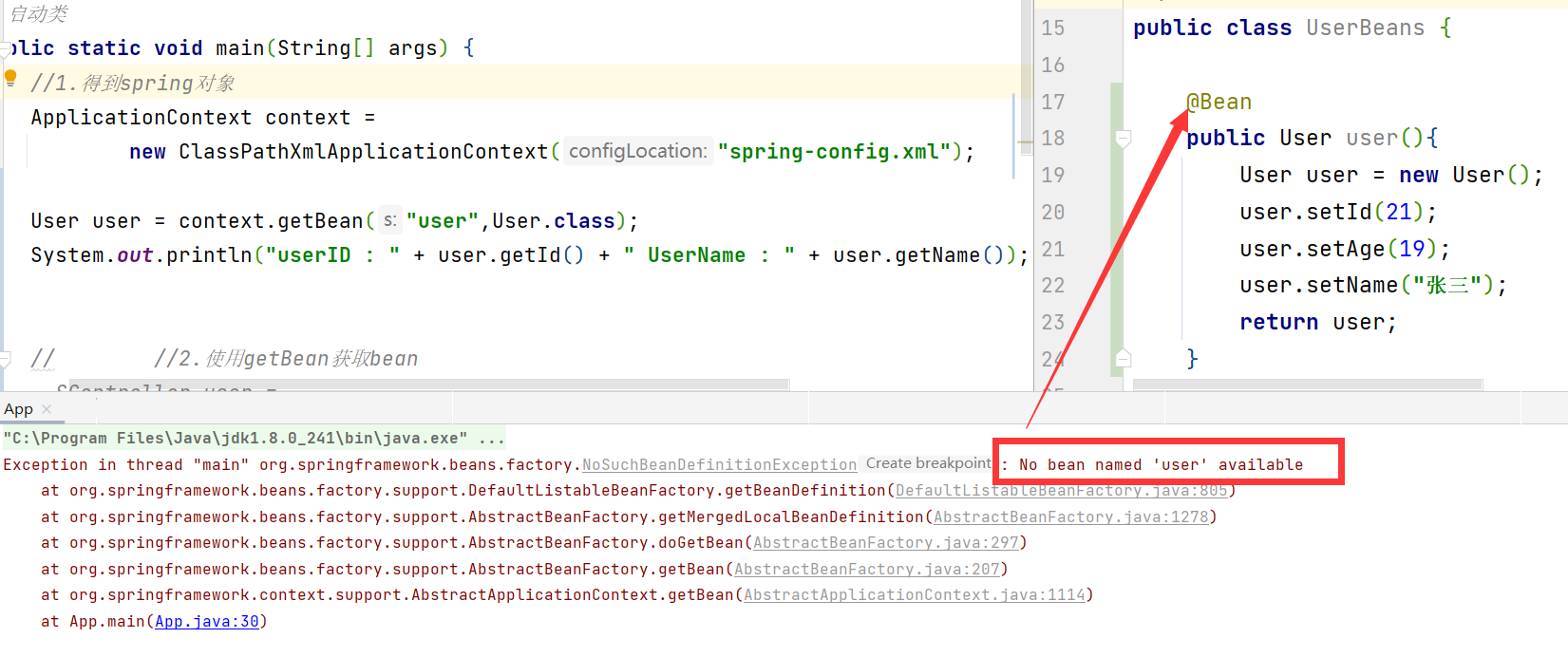
为什么没有存到Spring中呢 ??
答案是我们在使用@Bean注解的时候 就要与 类注解搭配使用.

为什么在使用@Bean注解的时候就要与类注解搭配使用呢 ?
这个原因根我们要设置一个scan-basePackage的节点是一样的. 我们在回忆一下为啥会在spring的配置文件设置这样的一个节点呢 ? 那就是因为,为了提高Spring的性能,加了这个节点我们只会扫描指定包下的路径或者子包带有类注解的类,这样就不同扫描所有包下的所有类.(当然如果不加那个节点也不会扫描所有包下的所有类,会直接报错的,要不就得传统的存Bean对象==>加Bean标签).
对于这个Bean注解也是一样的效果,我们并不是所有的类的方法返回的对象都要存到Spring中,这时不太可能的,所以加上类注解,就代表可能这个类低下有某个方法返回的对象要存放到Spring中的.也是为了提高Spring的性能,这样只会在加了类注解下的类看有没有方法加了Bean注解,然后将方法返回的Bean对象存到Spring中.
@Bean注解的命名规则难道与类注解的Bean的命名规则是一样的么 ?
我们来检验一下,当我们的方法名变得时候呢 ?

所以在使用Bean注解的时候,它的命名规则又是与类注解的Bean的命名规则不一样了.
对于Bean注解,它的命名规则是使用方法名字

为啥在使用类注解的时候Bean的名称是类名,使用方法注解的时候Bean的名称是方法名呢 ?
- 对于类注解 :
我们一般在使用类的时候,一般一个项目低下的类名是不同的,所以这样能够区分出来,一般每个类名都是不相同的. 所以使用类注解的时候Bean名称是类名....
- 对于方法注解 :
我们不能在使用类注解的Bean的命名方式了,因为方法返回的对象要存到Spring中,对于方法来说返回值是可以重复返回的,这样就无法进行区分了,而一般对于同一个类里面的方法一般是不同的,所以,使用方法名来作为Bean的名称,当然肯定有一些特殊情况,我们接下来来解决.
Bean重命名
对于使用方法注解来说,特殊情况也是有很多的.
比如如果不同的类名使用相同的方法呢 ? 那该将谁存到Spring中呢 ?

这其实就不符合我们常规了,我们如果想把StudentUserBeans的user1存到Spring中呢 ? 这时就出问题了.
这时我们就可以将Bean进行重命名.

对于Spring来说,在Spring内部其实是有一个key-value形式的来存储Bean.
类似于mmp key为 bean的类型或者bean的名称 value 为 object(多个标识(key)指向一个对象)
方法注解 :
key : 方法名
value :方法返回的对象
类注解 :
key : 类名
value : 类本身
对于 Bean的重命名的时候由三种方式
@Bean(name = "xxxx");
@Bean(value = "xxxx")
@Bean("")
@Bean(name = {xxx,xxxx,xxxx}) 可以起多个名字
同一个类里面方法重载怎么存储Bean呢 ?

当方法重载的时候,也就是方法带有参数的时候,由于Spring初始化的时候,不能进行传参所以只能使用在无参的方法中.
Bean重命名之后还可以使用原来的方法名作为Bean的名称么 ?

Bean注解总结
- Bean注解要结合类注解一起使用
- 使用bean注解时候,bean的名称是方法名
- 在使用bean注解的时候,方法不能有参数,因为Spring在初始化的时候不能有参数
- 使用bean注解的时候可以进行Bean的重命名,有4种方法进行Bean的重命名.
-
相关阅读:
第十二章 Spring MVC 框架扩展和SSM框架整合(2023版本IDEA)
辉芒微IO单片机FT60F12F-MRB
Docker专题(二)之 操作Docker容器
红米电脑硬盘剪切
七夕节赚取徽章啦
牛客每日刷题之二叉树
礼物道具投票系统源码 可以无限多开 吸粉神器 附带完整的搭建教程
3DEXPERIENCE许可管理流程:高效、合规、易行的软件许可方案
JavaSE学习文档(上)
自动识别验证码实现系统自动登录(可扩展实现无人自动化操作,如领取各个平台的优惠券),不依赖第三方可以支持离线识别处理,附源码可直接运行
- 原文地址:https://blog.csdn.net/m0_61210742/article/details/128104779