-
组织机器学习代码
组织机器学习代码
从note本转移到 Python 脚本时组织代码。
Intuition
有组织的代码就是有可读的、可重现的、健壮的代码。您的团队、经理,最重要的是,您未来的自己,将感谢您为组织工作付出的最初努力。在本课中,将讨论如何将代码从note本迁移和组织到 Python 脚本。
Editor
在开始编码之前,需要一个空间来完成它。代码编辑器有多种选择,例如VSCode、Atom、Sublime、PyCharm、Vim等,它们都提供独特的功能,同时提供代码编辑和执行的基本操作。由于 VSCode 的简单性、多语言支持、附加组件和不断增长的行业采用,将使用 VSCode 来编辑和执行代码。
欢迎您使用任何编辑器,但将使用一些可能特定于 VSCode 的附加组件。
-
从源代码为您的系统安装 VSCode: https ://code.visualstudio.com/ -
打开命令面板(在 mac F1上是Cmd++ Shift)P→ 输入“首选项:打开设置(UI)”→ 点击Enter -
调整您想要的任何相关设置(间距、字体大小等) -
安装 VSCode 扩展(使用编辑器左侧面板上的乐高积木图标)
推荐的 VSCode 扩展
我建议安装这些扩展,你可以通过复制/粘贴这个命令:
code --install-extension 74th.monokai-charcoal-high-contrast
code --install-extension alefragnani.project-manager
code --install-extension bierner.markdown-preview-github-styles
code --install-extension bradgashler.htmltagwrap
code --install-extension christian-kohler.path-intellisense
code --install-extension euskadi31.json-pretty-printer
code --install-extension formulahendry.auto-close-tag
code --install-extension formulahendry.auto-rename-tag
code --install-extension kamikillerto.vscode-colorize
code --install-extension mechatroner.rainbow-csv
code --install-extension mikestead.dotenv
code --install-extension mohsen1.prettify-json
code --install-extension ms-azuretools.vscode-docker
code --install-extension ms-python.python
code --install-extension ms-python.vscode-pylance
code --install-extension ms-vscode.sublime-keybindings
code --install-extension njpwerner.autodocstring
code --install-extension PKief.material-icon-theme
code --install-extension redhat.vscode-yaml
code --install-extension ritwickdey.live-sass
code --install-extension ritwickdey.LiveServer
code --install-extension shardulm94.trailing-spaces
code --install-extension streetsidesoftware.code-spell-checker
code --install-extension zhuangtongfa.material-theme- 1
如果您添加自己的扩展并希望与他人共享,只需运行此命令即可生成命令列表:- 1
一旦设置好 VSCode,就可以开始创建项目目录,将使用它来组织所有的脚本。启动项目的方式有很多种,但推荐以下方式:
-
使用终端创建目录 (
mkdir)。 -
切换到您刚刚创建的项目目录 (
cd)。 -
通过键入从此目录启动 VSCode
code .要使用命令直接从终端打开 VSCode ,请打开命令面板(或在 mac 上为+ + )→ 输入“Shell 命令:在 PATH 中安装‘代码’命令”→点击→重新启动终端。
code $PATH``F1CmdShiftPEnter -
在 VSCode (
View>Terminal) 中打开一个终端,以根据需要继续创建脚本 (touch) 或其他子目录 (mkdir)。
代码 设置
自述文件
将从一个
README.md文件开始组织,该文件将提供有关目录中的文件的信息、执行操作的说明等。将不断更新此文件,以便可以为将来的信息编目。touch README.md让从添加用于创建虚拟环境的说明开始:
# Inside README.md
python3 -m venv venv
source venv/bin/activate
python3 -m pip install pip setuptools wheel
python3 -m pip install -e .- 1
如果您按下位于编辑器右上角的预览按钮(下图中红色圆圈中的按钮),您可以看到
README.md当为git推送到远程主机时会是什么样子。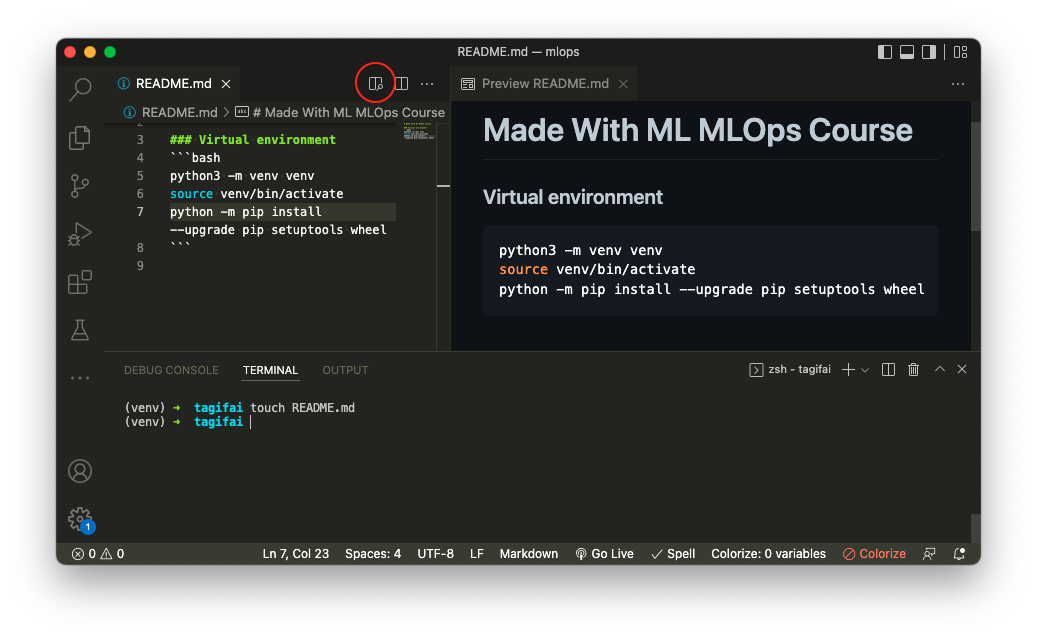
自述文件 配置
接下来,将创建一个名为的配置目录
config,可以在其中存储应用程序所需的组件。在此目录中,将创建一个config.py和一个args.json.mkdir config
touch config/main.py config/args.json- 1
config/
├── args.json - arguments
└── config.py - configuration setup- 1
在 内部
config.py,将添加代码来定义关键目录位置(将在以后的课程中根据需要添加更多配置):# config.py
from pathlib import Path
# Directories
BASE_DIR = Path(__file__).parent.parent.absolute()
CONFIG_DIR = Path(BASE_DIR, "config")- 1
在里面
args.json,将添加与数据处理和模型训练相关的参数。{
"shuffle": true,
"subset": null,
"min_freq": 75,
"lower": true,
"stem": false,
"analyzer": "char",
"ngram_max_range": 7,
"alpha": 1e-4,
"learning_rate": 1e-1,
"power_t": 0.1
}- 1
操作
将从
tagifai在项目目录 (mlops) 中创建包目录 ( ) 开始。在这个包目录中,将创建一个main.py文件来定义希望能够执行的核心操作。mkdir tagifai
touch tagifai/main.py- 1
tagifai/
└── main.py - training/optimization pipelines
`- 1
当将代码从note本移动到下面
main.py适当的脚本时,将在内部定义这些核心操作:-
elt_data:提取、加载和转换数据。 -
optimize:调整超参数以针对目标进行优化。 -
train_model:使用优化研究中的最佳参数训练模型。 -
load_artifacts:从给定的运行中加载经过训练的工件。 -
predict_tag:预测给定输入的标签。
Utilities
在开始从note本中移动代码之前,应该有意识地了解如何将功能移动到脚本中。note本内有临时进程是很常见的,因为只要note本在运行,它就会保持状态。例如,可以像这样在note本中设置种子:
# Set seeds
np.random.seed(seed)
random.seed(seed)- 1
但在脚本中,应该将此功能包装为一个干净、可重用的函数,并带有适当的参数:
def set_seeds(seed=42):
"""Set seeds for reproducibility."""
np.random.seed(seed)
random.seed(seed)- 1
可以将所有这些存储在包目录中的一个
utils.py文件中。tagifaitouch tagifai/utils.pytagifai/
├── main.py - training/optimization pipelines
└── utils.py - supplementary utilities- 1
项目
在将代码从note本迁移到脚本时,最好根据实用程序进行组织。例如,可以为数据处理、训练、评估、预测等 ML 开发的各个阶段创建脚本:
将创建不同的 python 文件来包装数据和 ML 功能:
cd tagifai
touch data.py train.py evaluate.py predict.py- 1
tagifai/
├── data.py - data processing utilities
├── evaluate.py - evaluation components
├── main.py - training/optimization pipelines
├── predict.py - inference utilities
├── train.py - training utilities
└── utils.py - supplementary utilities- 1
可能在其他项目中有其他脚本,因为它们是必要的。例如,通常有一个
models.py脚本,在 Pytorch、Tensorflow 等中定义显式模型架构。以这种方式组织代码库也使更容易理解(或修改)代码库。本可以将所有代码放入一个
main.py脚本中,但随着项目的增长,将很难在一个整体文件中导航。另一方面,可以通过分解data.py为split.py、preprocess.py等来假设更细粒度的立场。如果有多种拆分、预处理等方式(例如 ML 操作库),这可能更有意义,但是对于任务,在这个更高级别的组织中就足够了。原则
通过下面的迁移过程,将反复使用几个核心软件工程原则。
将功能包装到函数中
如何决定何时将特定代码行包装为一个单独的函数?函数应该是原子的,因为它们每个都有单一的职责,这样就可以轻松地测试它们。如果不是,需要将它们拆分成更细粒度的单元。例如,可以用这些行替换项目中的标签:
oos_tags = [item for item in df.tag.unique() if item not in tags_dict.keys()]
df.tag = df.tag.apply(lambda x: "other" if x in oos_tags else x)- 1
────相比────
def replace_oos_tags(df, tags_dict):
"""Replace out of scope (oos) tags."""
oos_tags = [item for item in df.tag.unique() if item not in tags_dict.keys()]
df.tag = df.tag.apply(lambda x: "other" if x in oos_tags else x)
return df- 1
最好将它们包装为一个单独的函数,因为可能想要:
-
在项目的其他部分或其他项目中重复此功能。 -
测试这些标签实际上是否被正确替换。
组合广义函数
Specific
def replace_oos_tags(df, tags_dict):
"""Replace out of scope (oos) tags."""
oos_tags = [item for item in df.tag.unique() if item not in tags_dict.keys()]
df.tag = df.tag.apply(lambda x: "other" if x in oos_tags else x)
return df- 1
────相比────
Generalized
def replace_oos_labels(df, labels, label_col, oos_label="other"):
"""Replace out of scope (oos) labels."""
oos_tags = [item for item in df[label_col].unique() if item not in labels]
df[label_col] = df[label_col].apply(lambda x: oos_label if x in oos_tags else x)
return df- 1
这样当列的名称发生变化或者想用不同的标签替换时,很容易调整代码。这还包括在函数中使用通用名称,例如
label而不是特定标签列的名称(例如tag)。它还允许其他人在他们的用例中重用此功能。但是,重要的是不要强行泛化,如果它涉及大量的努力。如果看到类似的功能再次出现,可以稍后再花时间
本文主体源自以下链接:
@article{madewithml, author = {Goku Mohandas}, title = { Made With ML }, howpublished = {\url{https://madewithml.com/}}, year = {2022} }
本文由 mdnice 多平台发布
-
-
相关阅读:
怎么找到没有广告的安全浏览器?这款干净实用
【Java|golang】2351. 第一个出现两次的字母
从0开始学c语言-32-自定义类型:结构体,枚举,联合
WMS仓储管理系统如何实现供应链协同
(热门)智慧社区助力实现社区数字化转型
基于JavaWEB+MySQL的学生成绩综合管理系统
js将两张图片合并成一张图片
模型预处理层介绍(1) - Discretization
【Unity】万人同屏高级篇, BRG & Jobs实战应用, 海量物体同屏
软件设计师——5系统开发基础
- 原文地址:https://blog.csdn.net/hengfanz/article/details/128105242
