-
Scala012--Scala中的常用集合函数及操作Ⅲ
在之前的两篇中我已经将Scala中常用的集合和函数认识了大半,现在就只剩下了最后几个函数。
目录
一,grouped函数
grouped函数返回值为iterator迭代器,普通的打印是看不到具体的结果的,但是我们可以将集合序列转换成列表或者是数组,之后再通过foreach函数或者是for函数遍历打印出来即可。
源码中的grouped函数: def grouped(size: Int): Iterator[Repr] = for (xs <- iterator grouped size) yield { val b = newBuilder b ++= xs b.result() }现在我去使用具体的案例来对这个函数进一步了解。
1,按照元素分组(两两分组)
Array(1,2,3,4,5,6,7)
OUT===>
List(1, 2)
List(3, 4)
List(5, 6)
List(7)- scala> val arrDemo1=Array(1,2,3,4,5,6,7)
- arrDemo1: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7)
- scala> arrDemo1.grouped(2) // 对数组中的元素进行两两分组
- res19: Iterator[Array[Int]] =

如上,我发现返回的类型确实就是迭代器,这个时候并不能够看到分组之后的结果,,但是可以使用toList或者是toBuffer函数将迭代器转换成列表或者是数组:
scala> res19.toList // 将之前处理后的结果转换成列表集合序列
但是上面的结果并不是我想要的效果:
List(1, 2)
List(3, 4)
List(5, 6)
List(7)这个时候就可以使用foreach函数,在遍历列表中的数组时,将数组转换成列表再输出即可:
scala> res20.foreach(arr=>println(arr.toList)) // 在遍历列表时,将列表中嵌套的数组转换成列表类型
如上就实现了需求。
2,两两分组并输出结果
Array(1,2,3,4,5,6,7,8,9)
OUT===>
2
1
4
3
6
5
8
7
9从上面的输出结果可以发现不仅需要两两分组,还需要将分组后的数组进行反转,并遍历输出。
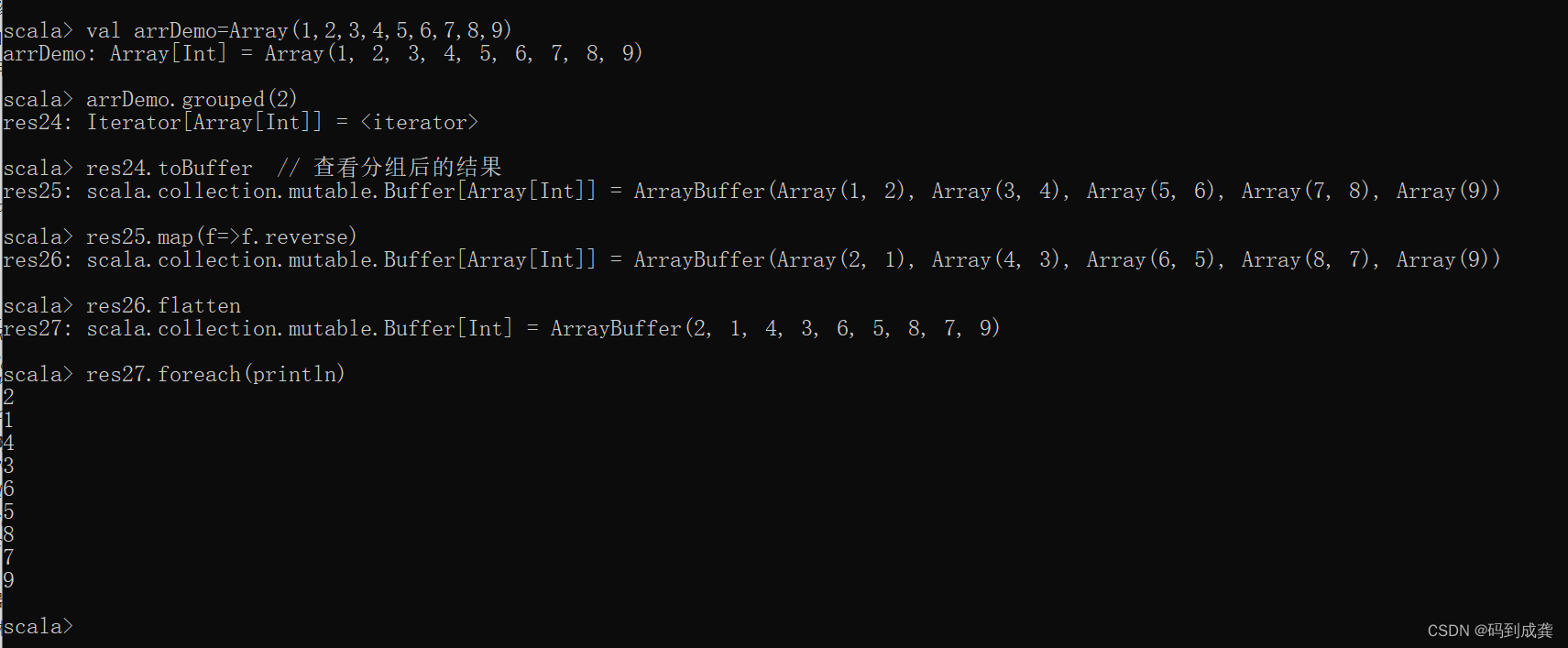
- scala> val arrDemo=Array(1,2,3,4,5,6,7,8,9)
- arrDemo: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
- scala> arrDemo.grouped(2) // 对数组中的元素进行两两组
- res24: Iterator[Array[Int]] =
- scala> res24.toBuffer // 查看分组后的结果
- res25: scala.collection.mutable.Buffer[Array[Int]] = ArrayBuffer(Array(1, 2), Array(3, 4), Array(5, 6), Array(7, 8), Array(9))
- scala> res25.map(f=>f.reverse) // 使用map函数,将数组中的每一个数组都进行反转
- res26: scala.collection.mutable.Buffer[Array[Int]] = ArrayBuffer(Array(2, 1), Array(4, 3), Array(6, 5), Array(8, 7), Array(9))
- scala> res26.flatten // 对结果进行扁平化操作
- res27: scala.collection.mutable.Buffer[Int] = ArrayBuffer(2, 1, 4, 3, 6, 5, 8, 7, 9)
- scala> res27.foreach(println) // 遍历数组
- 2
- 1
- 4
- 3
- 6
- 5
- 8
- 7
- 9
二,groupBy函数
groupBy函数相比于group函数,groupBy函数能够指定分组的依据是什么,而不是只能够进行两两分组,三三分组这些单调的操作。需要注意的是groupBy函数返回值为Map键值对类型。
groupBy函数的源码: def groupBy[K](f: A => K): immutable.Map[K, Repr] = { val m = mutable.Map.empty[K, Builder[A, Repr]] for (elem <- this) { val key = f(elem) val bldr = m.getOrElseUpdate(key, newBuilder) bldr += elem }接下来使用具体的代码和习题来更进一步了解该函数:
1,按照奇偶进行分组
Array(1,2,3,4,5,6,7,8)
OUT===>
Map(odd -> Array(1, 3, 5, 7), even -> Array(2, 4, 6, 8))
首先先定义一个数组:
scala> val arrDemo1=Array(1,2,3,4,5,6,7,8)之后就可以调用groupBy函数并向里面写入表达式:
- scala> arrDemo1.groupBy(
- | f => if (f %2==0) "even" else "odd") // 如果为偶数则分到even组,否则为odd组

如上,得到结果。
2, 按照单词首字母进行聚合
Array("hello","hi","haha","word","wangwu","tt","tom","a","aa","b")
OUT===>
Map(h -> Array(hello, hi, haha), w -> Array(word, wangwu), t -> Array(tt, tom)) Array(1, 3, 5, 7), true -> Array(2, 4, 6, 8))
字符串中获取首字母的函数为substring(0,1),之后将这个作为依据传入groupBy函数中即可:
- scala> val arr_str=Array("hello","hi","haha","word","wangwu","tt","tom","a","aa","b")
- arr_str: Array[String] = Array(hello, hi, haha, word, wangwu, tt, tom, a, aa, b)
- scala> arr_str.groupBy(f=>f.substring(0,1))
- res31: scala.collection.immutable.Map[String,Array[String]] = Map(t -> Array(tt, tom), a -> Array(a, aa), b -> Array(b), h -> Array(hello, hi, haha), w -> Array(word, wangwu))

如上,得到结果。
3,元组分组
List(("a", 10), ("b", 2), ("a", 3))
OUT===>
Map(a -> List((a,10), (a,3)), b -> List((b,2)))
如上,可以发现,分组的依据是对偶元组中的字母,也就是说我只需要获取到对偶元组中的字母即可:
- scala> val list_tup2=List(("a", 10), ("b", 2), ("a", 3))
- list_tup2: List[(String, Int)] = List((a,10), (b,2), (a,3))
- scala> list_tup2.groupBy(f=>f._1)
- res32: scala.collection.immutable.Map[String,List[(String, Int)]] = Map(b -> List((b,2)), a -> List((a,10), (a,3)))

如上,得到结果。
4,按照成绩分组
Array(("zhangsan",90),("lisi",80),("wangwu",49),("xiaoliu",28))
OUT===>
Map(true -> Array((zhangsan,90), (lisi,80)), false -> Array((wangwu,49), (xiaoliu,28)))
观察输出的结果可知,成绩分组的依据是按照成绩是否及格(及格表示大于60),因此,在获取到元组中的成绩之后,再将其与60进行比较即可(<60):
- scala> val arr_tup2=Array(("zhangsan",90),("lisi",80),("wangwu",49),("xiaoliu",28))
- arr_tup2: Array[(String, Int)] = Array((zhangsan,90), (lisi,80), (wangwu,49), (xiaoliu,28))
- scala> arr_tup2.groupBy(f=>if (f._2<60) true else false)
- res34: scala.collection.immutable.Map[Boolean,Array[(String, Int)]] = Map(false -> Array((zhangsan,90), (lisi,80)), true -> Array((wangwu,49), (xiaoliu,28)))

如上,得到结果。
三,mapValues函数
mapValues的源码: override def mapValues[C](f: B => C): Map[A, C] = new MappedValues(f) with DefaultMap[A, C]
mapValues函数其实有点像之前学map数据结构时,使用的keys和values函数的结合体。它能够获取到map集合序列中的键值对,并且能够通过键对键直接进行运算,返回的结果依旧时map集合序列,还是键值对的形式。接下来,我通过以下几道题对该函数的具体使用进一步加深理解。
1,对map中嵌套的数组进行求和
Map("a" -> List(1, 2, 3), "b" -> List(4, 5, 6))
OUT===>
Map(a -> 6, b -> 15)
观察上式可得两点:①返回的结果为键值对;②对map集合序列中的每一个列表都进行了求和。
接下来我们就可以知道使用的一定时mapValues函数(因为在map集合序列中只有该函数的返回值为键值对),之后使用该函数之后,传入的参数代表每一个key,之后由key得到每一个value(在这个例子中为每一个列表集合序列)。之后就可以开始敲代码:
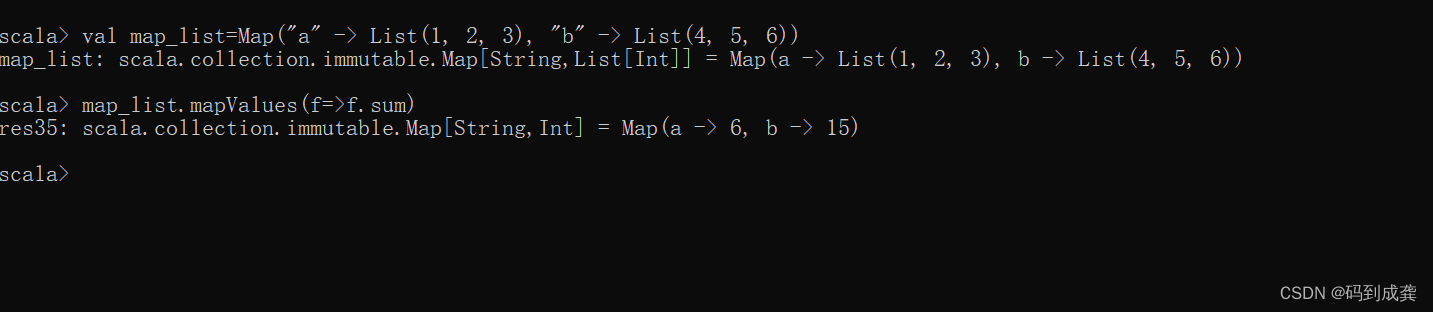
- scala> val map_list=Map("a" -> List(1, 2, 3), "b" -> List(4, 5, 6))
- map_list: scala.collection.immutable.Map[String,List[Int]] = Map(a -> List(1, 2, 3), b -> List(4, 5, 6))
- scala> map_list.mapValues(f=>f.sum)
- res35: scala.collection.immutable.Map[String,Int] = Map(a -> 6, b -> 15)
2,按照单词把元素分到一组,并获取每一组中元素个数
List(("a", 10), ("b", 2), ("a", 3))
OUT===>
Map(b -> 1, a -> 2)
我从输出可知:先使用groupBy函数按照元组中的第一个元素进行分组,之后再使用mapValues函数得到values有多少个:
- scala> list_tup2.groupBy(f=>f._1) // 根据元组中的第一个元素分组
- res37: scala.collection.immutable.Map[String,List[(String, Int)]] = Map(b -> List((b,2)), a -> List((a,10), (a,3)))
- scala> res37.mapValues(f=>f.size)
- res38: scala.collection.immutable.Map[String,Int] = Map(b -> 1, a -> 2)

四,diff,union,intersect函数
1,diff函数
diff函数的源码: def diff[B >: A](that: GenSeq[B]): Repr = { val occ = occCounts(that.seq) val b = newBuilder for (x <- this) { val ox = occ(x) // Avoid multiple map lookups if (ox == 0) b += x else occ(x) = ox - 1 } b.result() }diff函数主要是用于两个集合序列中的比较。例如:集合1.diff(集合2),如果集合1中有集合2中没有的元素,那么返回值就会是集合2中没有的元素。接下来我们使用代码来一探究竟。
需要用到的两个集合序列:
- scala> arrDemo
- res41: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9)
- scala> arrDemo1
- res42: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8)

之后让arrDemo集合去调用diff函数并于arrDemo2集合进行比较,那么结果就会是(9):
scala> arrDemo.diff(arrDemo1)
如果是让arrDemo集合去调用diff函数并于arrDemo2集合进行比较,那么结果就会是空:

因为arrDemo1中的元素arrDemo中都有,所以与arrDemo之间就没有任何元素的差异。
2,union函数
union函数源码: override def union[B >: A, That](that: GenSeq[B])(implicit bf: CanBuildFrom[Repr, B, That]): That = this ++ that
union函数就像是MySQL中的外连接一样,主要是用于合并两个集合序列的,不管是不是重复都会将所有的元素添加到一起,并返回一个型的集合序列:
scala> arrDemo.union(arrDemo1)
3,intersect函数
intersect函数源码: def intersect[B >: A](that: GenSeq[B]): Repr = { val occ = occCounts(that.seq) val b = newBuilder for (x <- this) { val ox = occ(x) // Avoid multiple map lookups if (ox > 0) { b += x occ(x) = ox - 1 } } b.result() }intersect:横断;相交;交叉;横穿;贯穿
该函数主要是取两个集合的交集,即获取相同的元素,并返回一个新的集合序列:
scala> arrDemo.intersect(arrDemo1)
以上就是集合序列中常用的所有函数,如果有问题请在评论区留言。
-
相关阅读:
vue打包耗时显示插件安装、遇到插件版本不兼容问题以及解决方案
【电气介数】电气介数及考虑HVDC和FACTS元件的电气介数计算
【JavaWeb】Servlet系列 --- 关于一个web站点的欢迎页面
【Linux】——基操指令(一)
项目实战:中央控制器实现(1)-基本功能实现-调用Controller中的方法
中兴交换机ZXR10-2950配置
C语言程序设计-8 函 数
嘉立创EDA专业版--指定位置加客编
广东启动“粤企质量提升工作会议” 着力提升产品和服务质量
rac节点停止和启动
- 原文地址:https://blog.csdn.net/weixin_53046747/article/details/128087837
