-
多线程 _ 基础篇 _ 线程安全问题【JavaEE初阶】
一、线程安全概述
1.1 什么是线程安全问题
线程安全问题 出现的 "罪魁祸首",正是 调度器的 随机调度 / 抢占式执行 这个过程
在随机调度之下,多线程程序执行的时候, 有无数种可能的排列方式
在这些排列顺序中,有的排列方式 逻辑是正确的,但是有的排列方式 可能会引出 bug
对于多线程并发时,会使程序出现 bug 的代码 称作线程不安全的代码,这就是线程安全问题
1.2 存在线程安全问题的实例
创建两个线程,让这两个线程 同时并发 对一个变量,自增 5w 次,最终预期能够一共自增 10w 次
- package thread;
- class Counter {
- public int count; //用来保存计数的变量
- public void increase() {
- count++;
- }
- }
- public class Demo9 {
- public static void main(String[] args) {
- //这个实例用来进行累加
- Counter counter = new Counter();
- Thread t1 = new Thread(() -> {
- for (int i = 0; i < 5_0000; i++) {
- counter.increase();
- }
- });
- Thread t2 = new Thread(() -> {
- for (int i = 0; i < 5_0000; i++) {
- counter.increase();
- }
- });
- t1.start();
- t2.start();
- try {
- t1.join();
- t2.join();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- System.out.println("count:" + counter.count);
- }
- }

二、线程安全问题及其解决办法
2.1 案例分析
按理来说,上述实例 运行的结果 count 应该等于 10w 吖~
可是 连续运行多次,就会发现 每一次运行的结果都不一样,但都是小于 10w,这是为什么呢?
这个就是 线程不安全的问题
其原因主要是:随机调度的顺序不一样,就导致程序运行的结果不一样
上述的 bug 是怎么形成的呢?
这个得需要站在硬件的角度来理解:
像 count++ 这一行代码,其实对应的是 三个机器指令:
- 首先 需要从内存中读取数据到 CPU,这个指令称为 load指令
- 其次 在 CPU 寄存器中,完成加法运算,这个指令称为 add指令
- 最后 把寄存器的指令 写回到内存中,这个指令称为 save指令
这里的 load 是把内存中的数据读到 寄存器里,add是在寄存器里面进行加法操作,save是把寄存器里面的值放回到内存
情况一:

情况二:

由于是多线程,所以有无数种情况 ~

总之,在无数中的排列顺序情况下,只有 "先执行完第一个线程,再执行完第二个线程" 以及 "先执行完第二个线程",再执行完第一个线程" 的这两种情况,是没有问题的
剩下的情况,全部都是和正确结果不匹配
操作系统的随机调度,其实不是 "真随机",而是 操作系统内核的调度器调度线程,其内部是有一套 逻辑 / 算法,来支持这一调度过程。即 每种出现的排列情况下不是均等的,所以不可以通过排列组合的情况下算出每种情况 出现的概率。
2.2 造成线程不安全的原因

一)操作系统的 随机调度 / 抢占式执行
这个是 万恶之源、罪魁祸首!!
这个是 操作系统内核 实现的时候,就是这样设计的,因此是我们改不了的,无能为力的。
二) 多个线程 修改 同一个变量
- 如果只是一个线程修改变量,没有线程安全问题;
- 如果是多个线程读同一个变量,也没有线程安全问题;
- 如果是多个线程修改不同的变量,还是没有线程安全问题;
- 但是,多个线程修改同一个变量,那就有了线程安全问题了;
所以,在写代码的时候,我们可以针对这个要点进行控制(可以通过调整程序的设计,来去规避 多个线程修改同一个变量)
但是,此时的 "规避方法" 是有适用范围的,不是所有的场景都可以规避掉(这个得要看具体的场景)
三)有些修改操作,不是 原子的修改,更容易触发 线程安全问题~
不可拆分的最小单位 就叫做原子
如:赋值操作来修改(=,只对应一条机器指令),就是视为原子的~
像之前通过 ++操作 来修改(对应三条机器指令),就不是原子的~
四)内存可见性 引起的线程安全问题~
内存可见性所存在的场景是:一个线程读、一个线程写的场景
- package thread;
- import java.util.Scanner;
- public class Demo16 {
- //写一个 内部类,此时这个内部类 就处在 Demo16 的内部,就可以解决 前面已经写过 Counter 的问题
- static class Counter {
- public int flg = 0;
- }
- public static void main(String[] args) {
- Counter counter = new Counter();
- Thread t1 = new Thread(() -> {
- while (counter.flg == 0) {
- //执行循环,但是此处循环 啥都不做
- }
- System.out.println("t1循环结束");
- });
- t1.start();
- Thread t2 = new Thread(() -> {
- //让用户输入一个数字,赋值给 flg
- Scanner scanner = new Scanner(System.in);
- System.out.println("请输入一个整数:");
- counter.flg = scanner.nextInt();
- });
- t2.start();
- }
- }
预期效果:t2线程 输入一个非零的整数后,此时 t1线程 循环结束,随之进程结束~
实际结果:
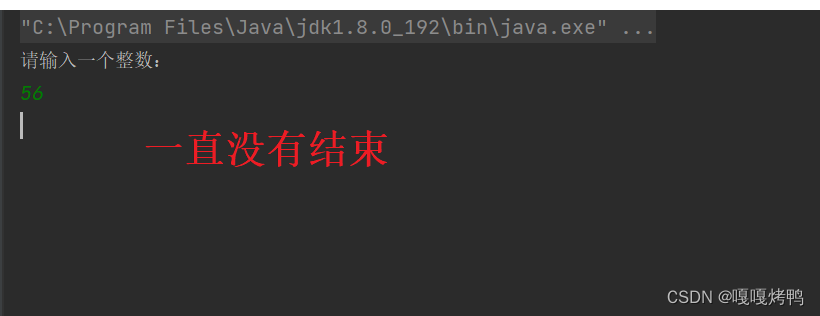
分析:
t1线程的工作:
- load 读取内存的数据到 CPU 的寄存器
- cmp 把寄存器的值和0比较,根据比较结果,决定下一步往哪个地方执行
- 反复进行,频繁进行 (一秒钟可以执行百万次以上)
由于load比cmp慢很多, 读内存比读 CPU寄存器 慢上几千倍、上万倍,意味着 t1线程 的主要操作就在 load上,但是 每一次load读取到的值没有变化,于是JVM 决定进行优化,就相当于 只从内存中只读取一次数据,后续就直接从寄存器里面 进行反复 test 就好了 。
内存可见性问题:一个线程针对一个变量进行读取操作,同时另一个线程针对这个变量进行修改,此时,读到的值不一定是修改之后的值。(这个读线程没有感知到变量的变化)
编译器看到这个线程(t1线程)对变量 flg 也没有做修改,于是就进行了优化操作 。但是,这里出现了一个特殊情况,有其他的线程(t2线程)对这个变量做出了修改
但是,t1线程 仍然是 采用之前的数据来读寄存器,此时 读到的数据和内存的数据是不一致的,这种情况就叫做 内存可见性问题(即 内存改了,但是线程没有看见;或者说,没有及时读取到内存中的最新数据)
归根结底是 编译器JVM在多线程环境下优化产生了误判,此时就需要程序员手动干涉了。
内存可见性的解决办法 —— volatile关键字
由于 编译器优化,是属于编译器自带的功能,正常来说,程序员并不好干预
但是 因为上述的场景,编译器知道自己可能会出现误判,因此就给程序猿提供了一个 干预优化的途径 —— volatile关键字~
给flag这个变量加上 volatile 关键字,就是告诉编译器,这个变量是“易变的”,一定要每次都重新读取这个变量的内存内容,不要进行优化了。
这个关键字是写到要修改的变量上,要保证哪个变量的内存可见性 就往哪个变量里面加


注意 :volatile 可以修饰变量的位置,也是在 public 左右
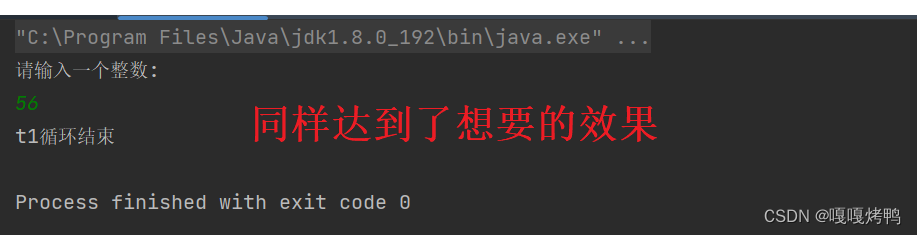
此时,运行结果:

volatile 操作 相当于是 显示得禁止了编译器进行上述优化,相当于是给这个对应的变量加上了 "内存屏障"(特殊的二进制指令),JVM 再读取这个变量的时候,因为内存屏障的存在,就知道每次都要重新读取这个变量的内容,而不是草率的进行优化了
虽然频繁的读取内存,使得速度变慢了,但是数据却是算的对了
关于编译器的优化:
- 编译器的优化是根据代码的实际情况来运行的,在一开始的代码中,由于循环体是空,所以循环的转速极快,导致了 读内存的操作非常频繁,所以就出发了优化
- 但是,如果在循环体中加上 sleep,让循环转速一下子就慢了,读取内存的操作 就不是特别频繁了,就不会被触发优化了 。
- 所以说,编译器到底什么时候会优化,仍然是一个 "玄学"问题,它内部有一个完整的优化体系,但是也不关咱们啥事。由于咱们也不好确定 什么时候优化,什么时候不优化,所以还得要在必要的时候加上 volatile
- package thread;
- import java.util.Scanner;
- public class Demo16 {
- //写一个 内部类,此时这个内部类 就处在 Demo16 的内部,就可以解决 前面已经写过 Counter 的问题
- static class Counter {
- public int flg = 0;
- }
- public static void main(String[] args) {
- Counter counter = new Counter();
- Thread t1 = new Thread(() -> {
- while (counter.flg == 0) {
- //执行循环,此处加上 sleep 操作
- try {
- Thread.sleep(100);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- System.out.println("t1循环结束");
- });
- t1.start();
- Thread t2 = new Thread(() -> {
- //让用户输入一个数字,赋值给 flg
- Scanner scanner = new Scanner(System.in);
- System.out.println("请输入一个整数:");
- counter.flg = scanner.nextInt();
- });
- t2.start();
- }
- }
注意:
- volatile关键字 保证的是 内存可见性 的问题,它不保证原子性的问题~
- volatile 解决的是 一个线程读、一个线程写 的问题~
- 当然,volatile 也可以解决指令重排序的问题~
- synchronized 保证的是 原子性的问题,解决的是 两个线程写 的问题~
五)指令重排序,也可能引起线程不安全
指令重排序,也是 操作系统 / 编译器 / JVM 的优化操作。它调整的是代码的执行顺序,以此来达到加快速度的效果
比如说,张三媳妇 要张三去到超市买一些蔬菜,并且给了他一张清单:
西红柿、鸡蛋、茄子、小芹菜
 调整顺序后,也是符合张三媳妇 对张三的要求:买到了四样菜,并且效率也是得到了提高~
调整顺序后,也是符合张三媳妇 对张三的要求:买到了四样菜,并且效率也是得到了提高~至于买的过程是什么样子的,张三媳妇并不关心~
这个就叫做 指令重排序!!!
可惜的是 指令重排序也会引发线程不安全~
如:

此处,就容易出现指令重排序引入的问题:
2 和 3 的顺序是可以重排的。在单线程下,调换这两的顺序是没有影响的;但是如果在多线程条件下,那就会出现多线程不安全:
假设 另一个线程,尝试读取 t 的引用,
如果按照 2、3的顺序,第二个线程读到 t 为非null 的时候,此时 t 就一定是一个有效对象;
如果按照 3、2的顺序,第二个线程读到 t 为非null 的时候,仍然可能是一个无效对象
总结:
线程安全问题出现的五种原因(前三种原因 是更普遍的 ):
- 系统的随机调度(万恶之源、无能为力)
- 多个线程同时修改同一个变量(部分规避)
- 修改操作不是原子的(有办法改善的)
后两种原因,是 编译器 / JVM / 操作系统 搞出的幺蛾子(但是 总体上来说还是利大于弊的)
- 内存可见性
- 指令重排序
编译器 / JVM / 操作系统 误判了,导致把不应该优化的地方给优化了,逻辑就变了,bug 就出现了(当然,后两种原因 也可以用 volatile关键字 来进行解决)
2.3 线程加锁 synchronized 操作解决 原子性问题
现在先重点来介绍一下 解决线程安全问题出现的第三种原因的方法(原子性),通过 加锁操作,来把一些不是原子的操作打包成一个原子的操作!!!
加锁在 Java 中有很多方式来实现,其中最常用的就是 synchronized
2.3.1 使用 synchronized关键字 进行加锁
synchronized 从字面意思上翻译叫做 "同步",其实 实际上它所起的是 互斥的效果~
在一开始的时候,列举了一个典型的线程不安全的例子:创建两个线程,让这两个线程同时并发 对一个变量,自增 5w 次,最终预期能够一共自增 10w 次~
- package thread;
- class Counter {
- public int count; //用来保存计数的变量
- public void increase() {
- count++;
- }
- }
- public class Demo14 {
- public static void main(String[] args) {
- //这个实例用来进行累加
- Counter counter = new Counter();
- Thread t1 = new Thread(() -> {
- for (int i = 0; i < 5_0000; i++) {
- counter.increase();
- }
- });
- Thread t2 = new Thread(() -> {
- for (int i = 0; i < 5_0000; i++) {
- counter.increase();
- }
- });
- t1.start();
- t2.start();
- try {
- t1.join();
- t2.join();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- System.out.println("count:" + counter.count);
- }
- }
那么,怎么使用 synchronized关键字 来解决这个线程不安全的问题呢?
—— 很简单,我们在上面的 increase() 方法 前面加上 synchronized关键字即可(写在 void 之前都可以):

此时,我们再执行程序,发现无论再运行多少次,发现运行结果是正确的了:

那么,为什么加锁之后,就可以来实现 线程安全的保障呢?
LOCK 这个指令是互斥的,当 线程t1 进行 LOCK 之后,t2 也尝试 LOCK,那么 t2 的 LOCK 就不会直接成功!!!

2.3.2 synchronized 使用示例
(一)synchronized 直接修饰普通方法
- public synchronized void methond() {
- //......
- }
(二)synchronized 修饰静态方法
- public synchronized static void method() {
- //.....
- }
(三)修饰代码块
- public void method() {
- synchronized (this) {
- //.....
- }
- }
() 里面的 this 指的是:是针对哪个对象进行加锁 。加锁操作,是针对一个对象来进行的 。
我们要重点理解,synchronized 锁:
- 两个线程竞争同一把锁,才会出现锁竞争/锁冲突(一个线程能够获取到锁,另一个线程阻塞等待,等待到上一个线程解锁了,它才能获取锁成功)
- 两个线程尝试使用两把不同的锁,是不会产生阻塞的(两个线程都能获取到各自的锁,就不会阻塞等待了)
- 两个线程,一个线程加锁,一个线程不加锁,这个时候也是没有锁竞争的
注意:
- 在Java里,任何一个对象,都可以用来做锁的对象,都可以放在 synchronized() 的括号中;其它的主流语言都是专门搞了一类特殊的对象,用来作为锁的对象(大部分的正常对象不能用来加锁)!
- 每个对象,内存空间中都会有一个特殊的区域 —— 对象头(JVM自带的,对象的一些特殊的信息)
- synchronized 写到普通方法上相当于是对 this(可创建出多个实例) 进行加锁,synchronized 写到静态方法上 相当于是对类对象(整个 JVM 里只有一个) 进行加锁,synchronized (类名.class)~

2.3.3 可重入问题
synchronized 同步块对同一条线程来说是可重入的,不会出现自己把自己锁死的问题。
什么是可重入呢?答:一个线程针对同一个对象,连续加锁两次是否会有问题,没问题就是可重入,有问题就是不可重入。

synchronized 为了避免上述的死锁问题,就设置成可重入的。
三、Java标准库里面的线程安全类
在Java标准库里面,很多线程都是不安全的,如:例如,ArrayList,LinkedList,HashMap,TreeMap,HashSet,TreeSet,StringBuilder~
当然,还是有一些是已经内置synchronized加锁,相对来说安全点,如:Vector (不推荐使用),HashTable (不推荐使用),ConcurrentHashMap (推荐),StringBuffer,String~
需要注意的是,加锁也是有代价的,它会牺牲很大的运行速度(毕竟,加锁涉及到了一些线程的阻塞等待,以及 线程的调度),所以可以视为,一旦使用了锁,我们的代码基本上就和 "高性能" 说再见了
四、wait 和 notify 关键字
前面已经介绍到,线程它是随机调度的,这个随机性很讨厌,我们希望可以控制线程的执行顺序
我们已经可以用 join关键字来控制线程结束的顺序, 但是,我们仍希望让两个线程按照既定的顺序配合执行。wait 和 notify 关键字就可以做到这个效果,相比于 jion,它们可以更好的控制线程之间的执行顺序。
- wait 叫做 "等待",调用 wait 的线程,就会进入线程阻塞等待的状态(即 Waiting状态)
- notify 叫做 "通知 / 唤醒",调用 notify 的线程,就可以把对应的 wait 线程给唤醒(即 从阻塞状态恢复回就绪状态)
既然有join和sleep了,为什么还要有wait?
使用join,是必须要t1彻底执行完,t2才能执行,达不到 t1干50%的活,就让t2来干的 效果
使用sleep,指定一个休眠时间,但是t1执行的这些活,到底需要多少时间,是不好估计的
而使用wait和sleep可以更好的解决上述问题
wait 、notify和 notifyall 都是 Object 的成员方法(随便哪个对象都可以调用)
比如说:如果有 o1.wait(); 那么 o1.notify()就可以唤醒调用 o1.wait() 的线程,而 o2.notify() 是不能够唤醒调用 o1.wait() 的线程的
4.1 wait() 方法
wait进行阻塞:某个线程调用wait方法,就会进入阻塞状态,此时就处在WAITING
线程.wait(); wait不加任何参数,就是死等直到notify唤醒他
wait() 内部的执行过程:
- 释放锁
- 等待通知
- 当通知到达后,就会被唤醒,并且尝试重新获取锁
wait() 一上来就要释放锁,这就说明 在调用 wait 之前,就需要先拿到锁;
换句话说,wait 必须要放到 synchronized 中使用,并且 synchronized 加锁的对象 和 调用 wait 方法的对象 是同一个对象~

4.2 notify() 方法
notify() 内部执行的过程:进行通知~
- package thread;
- import java.util.Scanner;
- //创建两个线程,一个线程调用 wait,一个线程调用 notify
- public class Demo18 {
- //这个对象用来作为锁对象
- public static Object locker = new Object();
- public static void main(String[] args) {
- Thread waitTask = new Thread(() -> {
- synchronized (locker) {
- System.out.println("wait 开始");
- try {
- locker.wait();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- System.out.println("wait 结束");
- }
- });
- waitTask.start();
- //创建一个用来 通知/唤醒 的线程
- Thread notifyTask = new Thread(() -> {
- //让用户来控制,用户输入内容后,再执行通知~
- Scanner scanner = new Scanner(System.in);
- System.out.println("输入任意内容,开始通知:");
- //next 会阻塞,直到用户真正输入内容以后
- scanner.next();
- synchronized (locker) {
- System.out.println("notify 开始");
- locker.notify();
- System.out.println("notify 结束");
- }
- });
- notifyTask.start();
- }
- }
运行结果:

当然,wait 和 notify 机制,还能够有效避免 "线程饿死"的问题
线程饿死:有些情况下,调度器可能分配的不均匀,导致 有些线程反复占用 CPU,导致有些线程始终捞不着 CPU......
线程在拿到锁之后,判定当下的任务是否可以进行;如果可以进行,那么就干活;如果不可以进行,那么就 wait;等到合适的时候(条件满足的时候)就再继续执行(notify) / 再继续参与竞争锁

注意:
- notify 在调用的时候,会尝试唤醒进行通知,如果当前对象没有在其他线程里 wait,也不会有副作用
- 如果 wait 是一个对象,notify 是另一个对象,则没啥用,无法被唤醒

4.3 notifyAll() 方法
当然,在 Java 中,还有一个唤醒线程的方法 —— notifyAll() 方法~
当有多个线程等待的时候,notify 是从若干个线程里面随机挑选一个唤醒,是一次唤醒一个;而 notifyAll 则是直接唤醒所有线程,再有这些线程去竞争锁
举个例子理解 notify 和 notifyAll 的区别:
notify 只是唤醒等待队列中的一个线程,其他的线程还是 需要乖乖的等着,如:

而 notifyAll 则是一下子将这些线程全部唤醒,这些进程则需要重新竞争锁,如:

由于 最终的结果 notifyAll 还是只能进去一个线程,并且 其他的线程还可能出现 "线程饿死" 的情况,所以说 一般的还是 notifyAll 用的比较少~
4.4 wait 和 sleep 的对比
wait 和 sleep都会让线程进入阻塞状态。
但是,阻塞的原因和目的不同,进入的状态也不同,被唤醒的条件也不同。
- wait 是用来控制线程之间的执行先后顺序,而 sleep 在实际开发中实际很少会用到(等待的时间太固定了,如果有突发情况 想提前唤醒并不是那么容易)
- wait 进入的是 Waiting 状态,sleep 进入的是 Time Waiting 状态
- wait 是主动被唤醒,而 sleep 是时间到了就会自动被唤醒
- wait 其实是涵盖了 sleep 的功能,即可以死等,也可以等待最大时间,所以一般在实际开发中用的多的是 sleep
- notify唤醒wait不会有任何异常(这是正常的业务逻辑) interrupt唤醒sleep则是出异常了(表示一个出问题了的逻辑)
-
相关阅读:
快速求完全二叉树的节点个数
网易云音乐项目
PTA 7-199 水仙花求和
应用链的崛起将带来哪些风险与机遇?
【Python接口自动化】--深入了解HTTP接口基本组成和网页构建原理
springboot升级过程中踩坑定位分析记录 | 京东云技术团队
[acwing周赛复盘] 第 64 场周赛20220813
十年磨一剑,奋进新征程!麒麟信安在上交所科创板成功上市
基于深度残差网络与人脸关键点的表情识别
服务器CPU和电脑的CPU区别是什么
- 原文地址:https://blog.csdn.net/m0_65601072/article/details/128085841
