-
[论文精读|博士论文]面向文本数据的关系抽取关键技术研究
电子科技大学 2022.3.15博士论文
- 实体关系的方向性语义缺失,使得关系的判别缺乏对文本蕴含语义特征的利用
提出——基于句法关系的方向敏感型句子级关系抽取算法
- 利用依存句法树结构信息
- 构建双向依存路径结构(新的文本策略解决过度剪裁)
- 额外构建了平行的注意力机制
- 文档级实体关系证据隐含,支持实体关系的语义难以被感知
提出——基于文本片段间语篇关系的文档级关系抽取方法
- 利用文本片段之间蕴含的语篇关系构建文档图
- 利用文档图构建里实体对间的语义关联
- 利用语篇关系选择合适的、隐含的证据
- 利用实体感知注意力机制,推理实体对间的关系
- 实体关系的关键性语义难以被挖掘,需要长距离的实体间构建有效的语义依赖关系
提出——基于句法与语篇关系融合的文档级关系抽取方法
- 利用语篇关系与句法关系构造字符级的文档图,使用斯坦纳树算法抽取最小生成树形成关键字符路径,获得与实体对嘴相关的语义依赖
- 在文字和图形两个层面构建了双层注意力权重值来增强关键字符的语义特征表达
- 训练过程中后置部署提高模型性能
基础介绍
监督关系抽取
基于特征向量
- 词汇特征:文本中词汇或词的属性,如全拼与缩写的关系
- 句法特征:最常见的是词性特征:实词、虚词、量词等
- 语义特征:指单一字符或多字符进行语义分类的结果,如牛顿发现了万有引力,判断是否是发现的关系,可以解决数据稀疏问题,缓解语义多样性带来的语义混淆问题
- 语篇特征:句子与句子之间的关系或片段之间的关系
基于核函数
不需要手工构造特征向量空间,核函数包括树、图、序列等
基于深度学习
-
CNN: 并行效能较好,能在关系抽取中高效地抽取到多个局部的语言结构特性
-
RNN:它能够综合考虑数据的前后关联关系,因此对于长文本、时序类信息具有较好的处理能力
-
GNN: 括通过依存句法树、共指关系图等方式来实现抽取
-
LSTM\GRU等
弱监督关系抽取
半监督学习(主动学习)
远程监督学习(主流)
- 假设一:“如果两个已经存在既定关系的实体对出现在某些句子中,那么所有句子描述的就都是这个关系”
改进假设一的方法:
- 假设二:“如果两个已经存在既定关系的实体对出现在某些句子集合中,那么至少有一个句子描述的是这个关系”
- 假设三:“如果两个已经存在既定关系的实体对出现在某些句子集合中,那么这些句子总是能够隐形或显性地表达这个关系”
- 依托深度学习的方法:
-
- 改进编码器的方法:从特征抽取器出发
- 句子级降噪:从数据集角度降低负样本对模型的影响
-
- 增强特征表达:通过注意力机制提升
-
- 引入外部知识:使用外部的库
-
- 即插即用方法:1.强化学习框架,删掉错误标记的句子 2.对抗学习框架,使用GAN提前对正负样本进行分类
总之,弱监督学习能够在语料成本高的问题发挥作用
无监督关系抽取
可以脱离标记数据
- 基于分布假设理论,使用聚类的方法,用频率最高的词作为关系名称
- 通过限定性聚类使用同类型预料、通过统计过滤掉多重关系实体对
缺乏明确的语义信息难以归一化
开放域关系抽取
更关注跨领域的应用
首先,通过启发式规则构造数据集,训练一个贝叶斯分类器
其次,利用单向抽取器产生的所有实体对与关系组合成三元组,选择高置信度元组
最后,为每个三元组分配一个概率,以高频词作为最终结果
词嵌入:是将文字转化为低维稠密向量,以避免数据稀疏、无意义、高纬度等问题。常用的方法有Word2vec等。
位置嵌入:为关系抽取模型提供了一种统一的感知字符位置的方法。句子级关系抽取
是实体关系抽取的最小粒度
- 序列方法:将文本直接按照序列方式进行处理,从早期的用单一网络到后期使用多重网络进行复合使用
- 依存句法树法: Syntacitc Dependency tree,SDT。能够有效获取文本中字符间句法依赖信息,其由依存句法树结构构成,有利于文本降噪,字符间依存关系提高实体关系判别的准确率
文档级关系抽取
文档级关系抽取过程需要更多考虑因素
1.解决实体间相互指代的问题 2.解决长距离语义依赖 3.增强提及的语义表达问题- 序列方法:直接迁移句子的序列方法效果较差
- 文档图法:具有更大的灵活性,早期的文档图是由一段文本中的字符节点以及句内依存边、句间邻接边、依
存语篇边、实体共指边构成的图形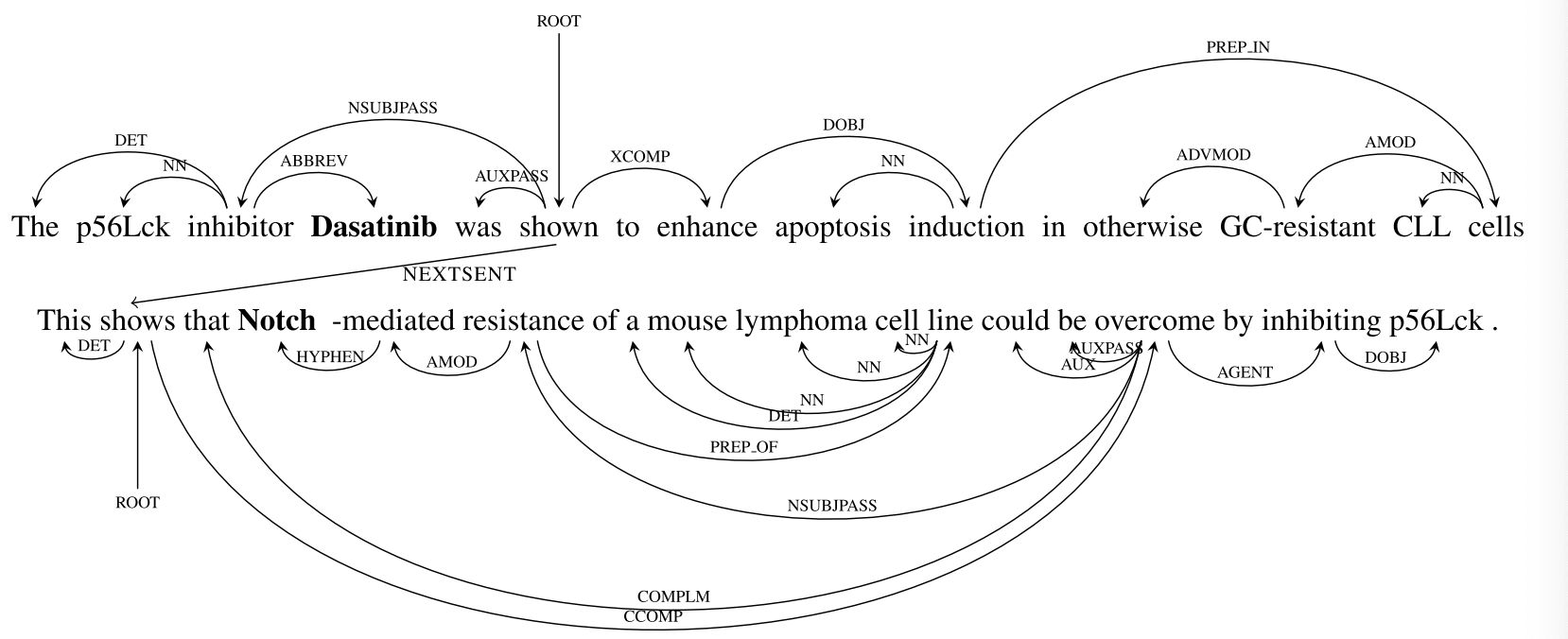
研究内容
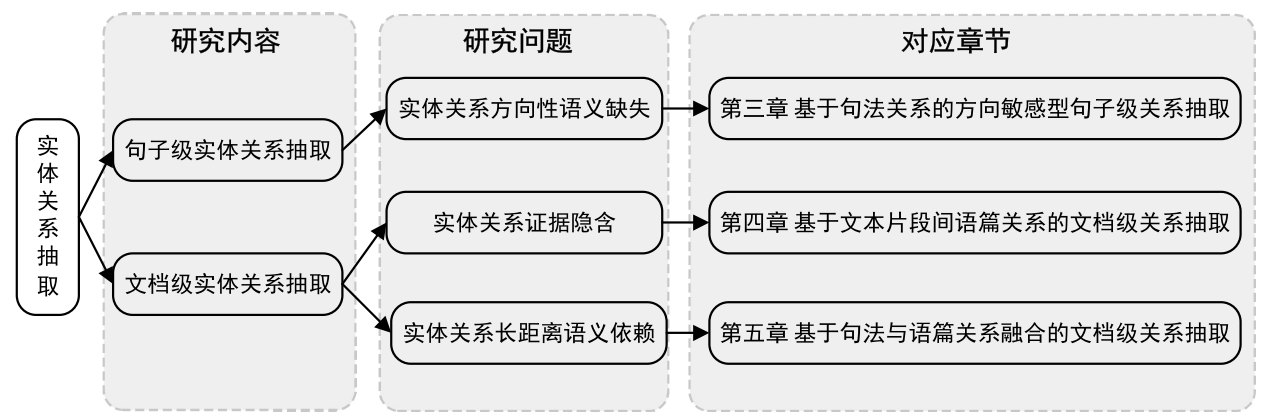
利用文本自身知识增强实体关系的语义表达
设计了一种基于依存句法数结构的方向性敏感型关系抽取模型,该模型构建了具有方向差异性的双向依存路径结构,利用LSTM提取其中的高阶信息,并利用注意力机制捕获差异特点
- 模型将句子转换为
最短依存路径结构,并设计基于实体和依存树树根的三点裁剪方法保留文本中重要信息 - 模型利用基于双向依存路径的多尺度卷积网络构建
双向依存路径中的信息特征路径中的信息特征 - 模型利用LSTM的实体表征信息与卷积网络的双向依存路径信息的差异性,通过注意力机制
标注实体间语义的方向性字符特征,增强实体方向性语义表示。
如何标识文档中支持实体语义关系的隐含证据
从文档中蕴含的语篇关系入手,将其作为外部知识引入到模型中,利用这类知识建模文档中各片段的支撑关系,并通过这种关系标记隐含的数据并推理实体间关系
- 模型通过语篇解析器将文档
划分成文本片段,并通过外部知识标记片段间的语篇逻辑关系形成异构的语篇文档图 - 模型使用GNN在语篇文档图中提取
实体结点和文本片段结点的特征信息 - 模型使用
实体对间路径上的文本片段集合作为证据集合,并利用基于实体的感知注意力机制在证据集合中去标记重要文本片段,形成推理过程并汇聚成为高阶证据特征
如何寻找文档中实体间关键的语义依赖路径
通过引入句法关系与语篇关系构建了字符层面的文档图,并将句子层面的降噪模式引入到文档图。
- 模型将文档依次按照
句子粒度和整体粒度分开解析为依存句法树集合和单个依存语篇树 - 将依存句法树集合按照
依存语篇树规则连接成依存句法树森林,形成字符级层面的文档图 - 利用
斯坦纳树算法以文档中的实体为终端结点构造最小生成树,实现了文档图层面的文本降噪,构建了多个实体共指间的最短语义依赖 - 利用GNN抽取降噪后的文档图中
实体特征,并结合双层注意力机制和反向部署方法改进模型性能
-
相关阅读:
998. Maximum Binary Tree II
CAS:183896-00-6 (Biotin-PEG3-C3-NH2) PEG衍生物
Python 接口测试框架
C++ 函数
总结一下前后端分离业务流程
A-Level经济真题(7)
身份证实名认证接口的三种方式、C#实名认证接口
TIDB-PD-RECOVER的恢复方式
超大规模云数据中心对存储的诉求有哪些?
【计算机网络微课堂】5.9 TCP报文段的首部格式
- 原文地址:https://blog.csdn.net/Dream__Y/article/details/128070379