-
Rust之常用集合(二):字符串(String)
开发环境
- Windows 10
- Rust 1.65.0

VS Code 1.73.1

项目工程
这里继续沿用上次工程rust-demo

用字符串存储UTF-8编码的文本
我们在之前的章节中讨论了字符串,但现在我们将更深入地研究它们。新的Rust人会因为三个原因而陷入字符串:Rust倾向于暴露可能的错误,字符串是比许多程序员认为的更复杂的数据结构,以及UTF-8。当您来自其他编程语言时,这些因素以一种看起来很困难的方式结合在一起。
我们在集合的上下文中讨论字符串,因为字符串是作为字节的集合实现的,加上一些在那些字节被解释为文本时提供有用功能的方法。在这一节中,我们将讨论每个集合类型对String的操作,比如创建、更新和读取。我们还将讨论String与其他集合的不同之处,即人和计算机解释String数据的方式不同,如何使String的索引变得复杂。
字符串
我们先来定义一下字符串这个词的含义。Rust在核心语言中只有一个字符串类型,那就是字符串切片str,通常以其借用的形式&str出现。在之前的章节中,我们谈到了字符串切片,它是对存储在其他地方的一些UTF-8编码的字符串数据的引用。例如,字符串字面意义存储在程序的二进制中,因此是字符串切片。
String类型是由Rust的标准库提供的,而不是编入核心语言的,它是一个可增长的、可变异的、自有的、UTF-8编码的字符串类型。当Rust人在Rust中提到 "字符串 "时,他们可能指的是String类型或字符串切片&str类型,而不仅仅是这些类型中的一个。虽然本节主要是关于String,但这两种类型在Rust的标准库中都被大量使用,而且String和字符串切片都是UTF-8编码的。
创建新字符串
许多与Vec
相同的操作也可以用在String上,因为String实际上是作为一个字节向量的封装器来实现的,有一些额外的保证、限制和能力。一个在Vec 和String中以同样方式工作的函数的例子是创建实例的new函数。如下例所示, - fn main() {
- let mut s = String::new(); // 创建字符串
- }
这一行创建了一个新的名为s的空字符串,然后我们可以将数据加载到其中。通常,我们会有一些想要开始字符串的初始数据。为此,我们使用to_string方法,该方法可用于任何实现Display特征的类型,就像字符串一样。如下所示,
- fn main() {
- let data = "initial contents";
- let s = data.to_string(); // 创建字符串s,并将data的值赋给s
- // 该方法也可以直接使用
- let s = "initial contents".to_string();
- }
这段代码创建了一个包含初始内容的字符串。
我们也可以使用函数String::from来从一个字符串字面创建一个字符串。下例中的代码等同于上例中使用to_string的代码。
- fn main() {
- let s = String::from("initial contents"); // 通过from函数创建并初始化字符串变量s
- }
由于字符串的用途非常多,我们可以使用许多不同的字符串通用API,为我们提供了很多选择。其中有些看起来是多余的,但它们都有自己的位置 在这种情况下,String::from和to_string做同样的事情,所以你选择哪个是风格和可读性的问题。
请记住,字符串是UTF-8编码的,所以我们可以在其中包含任何正确编码的数据,如下例所示。
- fn main() {
- let hello = String::from("السلام عليكم"); // 字符串创建示例
- print!("{}\n", hello);
- let hello = String::from("Dobrý den");
- print!("{}\n", hello);
- let hello = String::from("Hello");
- print!("{}\n", hello);
- let hello = String::from("שָׁלוֹם");
- print!("{}\n", hello);
- let hello = String::from("नमस्ते");
- print!("{}\n", hello);
- let hello = String::from("こんにちは");
- print!("{}\n", hello);
- let hello = String::from("안녕하세요");
- print!("{}\n", hello);
- let hello = String::from("你好");
- print!("{}\n", hello);
- let hello = String::from("Olá");
- print!("{}\n", hello);
- let hello = String::from("Здравствуйте");
- print!("{}\n", hello);
- let hello = String::from("Hola");
- print!("{}\n", hello);
- }
编译运行
cargo run结果
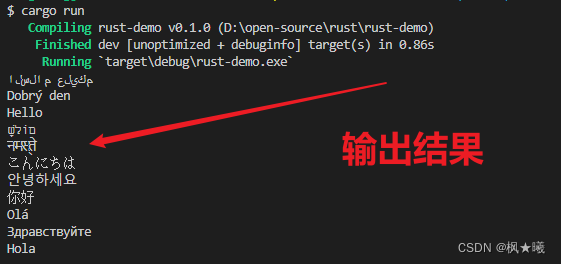
所有这些都是有效的String值。
更新字符串
如果你把更多的数据推入一个String,它的大小可以增长,它的内容可以改变,就像Vec
的内容一样。此外,你可以方便地使用+运算符或format!宏来连接String的值。 追加字符串:push_str和push
我们可以通过使用push_str方法追加一个String切片来增长一个字符串,下例所示。
- fn main() {
- let mut s = String::from("foo");
- s.push_str("bar"); // 追加字符串,push_str接口
- }
在这两行之后,s将包含foobar。push_str方法需要一个字符串切片,因为我们不一定要取得参数的所有权。例如,在下例中,我们希望在将s2的内容追加到s1后能够使用它。
- fn main() {
- let mut s1 = String::from("foo"); // 创建字符串s1
- let s2 = "bar"; // 初始化字符串s2
- s1.push_str(s2); // 将s2追加到s1
- println!("s2 is {}", s2);
- println!("s1 is {}", s1);
- }
编译运行
cargo run
如果push_str方法取得了s2的所有权,我们就不能在最后一行打印它的值。然而,这段代码正如我们所期望的那样工作。
push方法接受一个单一的字符作为参数并将其添加到String中。下例中使用push方法将字母 "l "添加到一个String中。
- fn main() {
- let mut s = String::from("lo");
- s.push('l'); // push接口
- println!("s is {}", s);
- }
编译运行
cargo run结果

结果显示,s将包含lol。
格式化字符串:用 "+"运算符或 "format!宏
通常情况下,你会想把两个现有的字符串结合起来。一种方法是使用+运算符,如下例所示。
- fn main() {
- let s1 = String::from("Hello, ");
- let s2 = String::from("world!");
- let s3 = s1 + &s2; // + 运算符
- println!("s3 is {}", s3);
- }
编译运行
cargo run结果

字符串s3将包含Hello, world!。s1在添加后不再有效的原因,以及我们使用对s2的引用的原因,都与我们使用+运算符时调用的方法的签名有关。+操作符使用add方法,其签名看起来像这样。
fn add(self, s: &str) -> String {在标准库中,你会看到使用泛型和关联类型定义的add。在这里,我们用具体的类型来代替,这就是我们用String值调用这个方法时的情况。我们将在后续章节讨论泛型。这个签名为我们提供了理解+运算符的棘手部分所需的线索。
首先,s2有一个&,意味着我们要把第二个字符串的引用添加到第一个字符串中。这是因为add函数中的s参数:我们只能把一个&str加到一个String上;我们不能把两个String值加在一起。但是等等--&s2的类型是&String,而不是&str,正如add的第二个参数所指定的那样。那么,为什么上例会被编译?
我们能够在调用add时使用&s2的原因是,编译器可以将&String参数强制变成&str。当我们调用add方法时,Rust使用了一个deref coercion,在这里它把&s2变成了&s2[...]。我们将在后续章节更深入地讨论deref coercion。因为add并没有取得s参数的所有权,所以s2在这个操作之后仍然是一个有效的String。
第二,我们可以在签名中看到,add取得了self的所有权,因为self没有&。这意味着上例中的s1将被移到add调用中,此后将不再有效。因此,尽管let s3 = s1 + &s2;看起来会复制两个字符串并创建一个新的字符串,但这个语句实际上取得了s1的所有权,附加了s2内容的副本,然后返回结果的所有权。换句话说,它看起来是在做大量的拷贝,但其实不是;实现起来比拷贝更有效率。
如果我们需要串联多个字符串,那么+运算符的行为就会变得很不方便。
- fn main() {
- let s1 = String::from("tic");
- let s2 = String::from("tac");
- let s3 = String::from("toe");
- let s = s1 + "-" + &s2 + "-" + &s3; // 多字符串追加
- println!("s is {}", s);
- }
编译运行
cargo run结果

在这一点上,s将是tic-tac-toe。由于所有的 "+"和""字符,我们很难看到发生了什么事。对于更复杂的字符串组合,我们可以改用format!宏。
- fn main() {
- let s1 = String::from("tic");
- let s2 = String::from("tac");
- let s3 = String::from("toe");
- let s = format!("{}-{}-{}", s1, s2, s3); // format!宏
- println!("s is {}", s);
- }
编译运行
cargo run结果

这段代码还将s设置为tic-tac-toe。format!宏的工作原理与println!类似,但它不是将输出打印到屏幕上,而是返回一个包含内容的字符串。使用format! 的代码版本更容易阅读,由format! 宏生成的代码使用了引用,这样这个调用就不会占用任何参数的所有权。
对字符串进行索引
在许多其他编程语言中,通过索引来访问字符串中的单个字符是一种有效的、常见的操作。然而,如果你试图用Rust中的索引语法访问字符串的一部分,你会得到一个错误。请看下例中的无效代码。
- fn main() {
- let s1 = String::from("hello");
- let h = s1[0];
- }
编译
cargo run
这个错误和注释说明了问题。Rust字符串不支持索引。但为什么不呢?为了回答这个问题,我们需要讨论Rust如何在内存中存储字符串。
内部表述
字符串是对Vec
的一个封装。让我们看看上例中的一些正确编码的UTF-8示例字符串。首先是这个。 let hello = String::from("Hola");在这种情况下,len将是4,这意味着存储 "Hola "字符串的向量有4个字节长。当用UTF-8编码时,每个字母需要1个字节。然而,下面一行可能会让你吃惊。(请注意,这个字符串以大写的西里尔字母Ze开始,而不是阿拉伯数字3)。
let hello = String::from("Здравствуйте");当被问及这个字符串有多长时,你可能会说12。事实上,Rust的答案是24:这是UTF-8编码 "Здравствуйте "所需的字节数,因为该字符串中的每个Unicode标量值需要2个字节的存储空间。因此,对字符串字节的索引并不总是与有效的Unicode标量值相关。为了证明这一点,请看这个无效的Rust代码。
- let hello = "Здравствуйте";
- let answer = &hello[0];
你已经知道answer不会是З,第一个字母。当用UTF-8编码时,З的第一个字节是208,第二个字节是151,所以看起来answer实际上应该是208,但是208本身不是一个有效的字符。如果用户要求得到这个字符串的第一个字母,返回208可能不是他们想要的;但是,这是Rust在字节索引0处的唯一数据。用户一般不希望返回字节值,即使字符串只包含拉丁字母:如果&"hello"[0]是返回字节值的有效代码,它将返回104,而不是h。
那么答案是,为了避免返回一个意外的值,造成可能无法立即发现的bug,Rust根本不编译这段代码,并在开发过程的早期防止误解。
字节和标量值以及字母簇
关于UTF-8的另一点是,从Rust的角度来看,实际上有三种相关的方式来看待字符串:作为字节、标量值和字素簇(最接近于我们所说的字母)。
如果我们看一下用Devanagari文字写的印地语单词 "नमस्ते",它被存储为一个u8值的向量,看起来像这样。
- [224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164,
- 224, 165, 135]
这就是18个字节,也是计算机最终存储这些数据的方式。如果我们把它们看成Unicode标量值,也就是Rust的char类型,这些字节看起来是这样的。
['न', 'म', 'स', '्', 'त', 'े']这里有六个char值,但第四个和第六个不是字母:它们是本身没有意义的变音符号。最后,如果我们把它们看作是字素簇,我们会得到一个人所说的组成印地语单词的四个字母。
["न", "म", "स्", "ते"]Rust提供了不同的方式来解释计算机存储的原始字符串数据,这样每个程序都可以选择它所需要的解释,无论数据是用什么人类语言。
Rust不允许我们在一个String中建立索引来获得一个字符的最后一个原因是,索引操作预计总是需要恒定的时间 (O(1))。但是用一个String不可能保证这样的性能,因为Rust必须从开始到索引的内容中走一遍,以确定有多少个有效字符。
字符串切片
对字符串进行索引往往是一个坏主意,因为不清楚字符串索引操作的返回类型应该是什么:一个字节值、一个字符、一个字素簇,还是一个字符串片断。因此,如果你真的需要使用索引来创建字符串片,Rust会要求你更加具体。
与使用[]与单个数字进行索引相比,你可以使用[]与一个范围来创建一个包含特定字节的字符串切片。
- #![allow(unused)]
- fn main() {
- let hello = "Здравствуйте";
- let s = &hello[0..4]; // 字符串切片
- }
这里,s将是一个&str,包含了字符串的前4个字节。早些时候,我们提到这些字符中的每一个都是2个字节,这意味着s将是Зд。
如果我们试图用&hello[0..1]这样的东西只对一个字符的部分字节进行切分,Rust会在运行时出现恐慌,就像在向量中访问一个无效的索引一样。
- #![allow(unused)]
- fn main() {
- let hello = "Здравствуйте";
- let s = &hello[0..1];
- }
编译
cargo run
你应该谨慎地使用范围来创建字符串片,因为这样做会使你的程序崩溃。
字符串迭代
对字符串片段进行操作的最好方法是明确说明你要的是字符还是字节。对于单个Unicode标量值,使用chars方法。在 "Зд "上调用chars,可以分离并返回两个char类型的值,你可以对结果进行迭代以访问每个元素。
- #![allow(unused)]
- fn main() {
- for c in "Зд".chars() {
- println!("{}", c);
- }
- }
编译运行
cargo run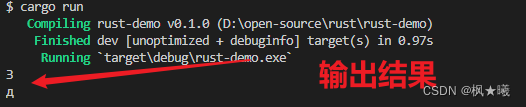
或者,字节方法返回每个原始字节,这可能适合你的领域。
- #![allow(unused)]
- fn main() {
- for b in "Зд".bytes() {
- println!("{}", b);
- }
- }
编译运行
cargo run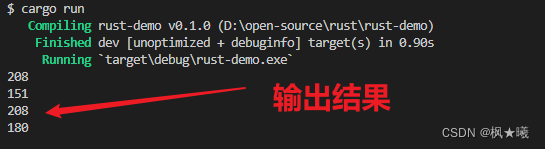
但一定要记住,有效的Unicode标量值可能由1个以上的字节组成。
像Devanagari脚本那样从字符串中获取字素簇是很复杂的,所以标准库没有提供这个功能。如果你需要这个功能,可以在crates.io上找到crates。
字符串并不简单
总而言之,字符串是复杂的。不同的编程语言对如何向程序员展示这种复杂性做出了不同的选择。Rust选择将正确处理String数据作为所有Rust程序的默认行为,这意味着程序员必须在处理UTF-8数据上花费更多心思。这种权衡使字符串的复杂性比其他编程语言更明显,但它可以防止你在开发周期的后期处理涉及非ASCII字符的错误。
好消息是,标准库提供了很多基于String和&str类型的功能,以帮助正确处理这些复杂的情况。请务必查看文档,了解有用的方法,如用于在字符串中搜索的contains和用于用另一个字符串替换部分字符串的replace。
本章重点
- 字符串的概念
- 创建字符串,以及初始化字符串
- 更新字符串,push_str和push的使用
- 字符串连接和格式化:+操作符和format!宏
- 字符串索引及注意事项
- 字符串切片及注意使用范围
- 字符串的迭代
-
相关阅读:
高等数学(第七版)同济大学 总习题三(后10题) 个人解答
Android 按钮点击设置静音
如何购买并配置华为云服务器?
【PAT(甲级)】1068 Find More Coins
Text-to-SQL小白入门(六)Awesome-Text2SQL项目介绍
Linux安装MySQL8.0
【JavaWeb】登录页面记住密码,账号或密码错误
决策树剪枝:解决模型过拟合【决策树、机器学习】
Maven项目构建工具
MongoDB 分片集群
- 原文地址:https://blog.csdn.net/md521/article/details/128078324
