-
Go学习之路:更多类型:struct、slice 和映射(DAY 2)
前引
周天辣 昨天全员核酸没有阳性 如果再有两天阴性的话 就有机会楼栋能解封啦 最好的情况希望能出现 周二能回去!
在寝室里闲着也是闲着 还是学一下go吧 把剩下的基础的给学完
希望好运伴随!
希望未来顺利
更多类型:struct、slice 和映射
1、指针
go语言中仍旧保持了有指针的特性 这个还是非常欣慰的
准确来说应该和c/c++差别并不大 唯一的差别是不能进行指针运算下面是例子
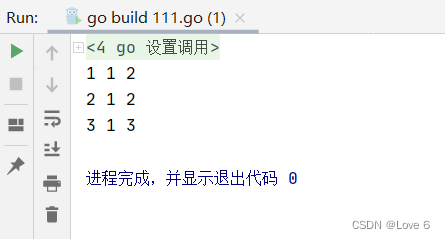
111.gopackage main import "fmt" func main() { i, j := 1, 2 p := &i fmt.Println(*p, i, j) p = &j fmt.Println(*p, i, j) *p = 3 fmt.Println(*p, i, j) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
运行效果
2.1、结构体/结构体命名(一)
命名方式相比于c语言有所不一样 其他的基本大致相同
type name struct然后从这里我自己去搜了10分钟的资料
发现go语言的内存分配和c++ 完全不一样
第一点 c++需要自己手动解决内存分配问题 而go语言是自动回收
第二点 go语言会自动分析该对象是否是需要分配内存 决定于内存逃逸行为 go语言的内存分析我刚刚又花了20分钟看了一下 发现不像是c++那样 什么对象是动态分配的 什么是静态分配(在栈中)定义的时候 自己都清楚 而是取决于当前对象是否能被外部引用 go语言还是偏向于分配栈对象的 但是对于没有办法确认是否会被外部引用时 只能放于堆中 用GC来管理关于内存分配问题 这个后面还要花很多事情去研究研究 下面写了很多 来看究竟结构体的内存分配情况 以及结构体的初始化
111.gopackage main import "fmt" type Node struct { val int next *Node } var global_ptr *Node func PtrGo() { global_ptr = &Node{} global_ptr.val = -1 } func main() { // 初始化1 var dummynode1 Node dummynode1.val = -1 //初始化为0后 再赋值 ptr1 := &dummynode1 fmt.Printf("%d %p %s%p %s%p %s\n", dummynode1.val, dummynode1.next, "ptr addr:", &ptr1, "struct addr:", ptr1 , "way 3") //初始化2 dummynode2 := Node{-1, nil} ptr2 := &dummynode2 fmt.Printf("%d %p %s%p %s%p %s\n", dummynode2.val, dummynode2.next, "ptr addr:", &ptr2, "struct addr:", ptr2, "way 3") //初始化3 dummynode3 := new(Node) dummynode3.val = -1 ptr3 := dummynode3 fmt.Printf("%d %p %s%p %s%p %s\n", dummynode3.val, dummynode3.next, "ptr addr:", &ptr3, "struct addr:", ptr3, "way 3") //初始化4 PtrGo() fmt.Printf("%d %p %s%p %s%p %s\n", global_ptr.val, global_ptr.next, "ptr addr:", &global_ptr, "struct addr:", global_ptr, "way 4") }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
运行效果

2.2、结构体/对象访问、指针访问、初始化规则(二)
结构体不管是指针还是直接对象访问结构体内部值 都是通过
.符号来访问 不用指针->来访问了
第二个 初始化规则 上面的方式已经写完了初始化的方式111.gopackage main import "fmt" type Node struct { val int next *Node } func main() { var dummynode1 = Node{-1, nil} fmt.Println(dummynode1) var dummynode2 = Node{val : -1} fmt.Println(dummynode2) var dummynode3 = Node{next : nil} dummynode3.val = -1 fmt.Println(dummynode3) dummynode4 := Node{-1, nil} fmt.Println(dummynode4) dummynode5 := new(Node) dummynode5.val = -1 fmt.Println(*dummynode5) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
运行效果
3、数组
构造方式和c语言类似 声明方式仍旧是golang化
简单的例子应用package main import "fmt" func main() { var strs [2]string strs[0] = "Hello," strs[1] = "World!" fmt.Println(strs[0], strs[1]) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
运行效果

数组的初始化办法
下面有这几种111.gopackage main import ( "fmt" ) func main() { var nums1 [10]int = [10]int {1, 2, 3} for i := 0; i < 10; i++ { fmt.Printf("%d ", nums1[i]) } fmt.Println() var nums2 = [10]int{1, 2, 3} for _, num := range nums2 { fmt.Printf("%d ", num) } fmt.Println() nums3 := [...]int{1, 2, 3} for _, num := range nums3 { fmt.Printf("%d ", num) } fmt.Println() nums4 := [10]int{0:1, 1:2, 2:3} for _, num := range nums4 { fmt.Printf("%d ", num) } fmt.Println() var nums5 [10]int nums5[0] = 1 nums5[1] = 2 nums5[2] = 3 for _, num := range nums5 { fmt.Printf("%d ", num) } fmt.Println() }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
运行效果

4.1、切片/初始化切片
切片在还没有学习Go语言的时候就听说了其鼎鼎大名
所以我们还是来接触一下slice的底层实现 本质还是根据的数组的底层 可以说用指针来表示数组的开始位置
三个数据结构支持slice指针 size capacity
我认为如果是从数组切分出来的切片 不扩容 此时开销是最小的
但是如果要append元素 此时可以将其看作是c++ vector本质上扩容的机制还是另外申请容量
切片初始化的方法很多 为了后面使用起来更得心应手 还是挨个挨个列出来吧
111.gopackage main import ( "fmt" ) func main() { //初始化1 刚开始为空切片nil slice1 := []int{} fmt.Println("before append, length:", len(slice1), ", capacity:", cap(slice1)) for i := 0; i < 10; i++ { slice1 = append(slice1, i) } fmt.Println("after append 10 elems, length:", len(slice1), ", capacity:", cap(slice1)) for _, num := range slice1 { fmt.Printf("%d ", num) } fmt.Println("\n") nums2 := [10]int {1, 2, 3, 4, 5} slice2 := nums2[:4] //初始化2 左闭右开 0 - 3 size 4 cap 10 slice3 := nums2[1:] //初始化3 左闭右开 1 - 10 size 9 cap 9 slice4 := nums2[0:4:5] //初始化4 左闭右开 0 - 3 size 4 cap 5(5 - 0) slice5 := nums2[:] //初始化5 左闭右开 0 - 10 size 10 cap 10 fmt.Println("slice2 length:", len(slice2), ", capacity:", cap(slice2)) fmt.Println("slice3 length:", len(slice3), ", capacity:", cap(slice3)) fmt.Println("slice4 length:", len(slice4), ", capacity:", cap(slice4)) fmt.Println("slice5 length:", len(slice5), ", capacity:", cap(slice5)) slice6 := make([]int, 0, 10) //初始化6 size 0 cap 10 var slice7 = make([]int, 0, 10) // 初始化7 size 0 cap 10 var slice8[]int = make([]int, 0, 10) // 初始化8 size 0 cap 10 fmt.Println("slice6 length:", len(slice6), ", capacity:", cap(slice6)) fmt.Println("slice7 length:", len(slice7), ", capacity:", cap(slice7)) fmt.Println("slice8 length:", len(slice8), ", capacity:", cap(slice8)) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
运行效果

4.2、切片/切片引用数组
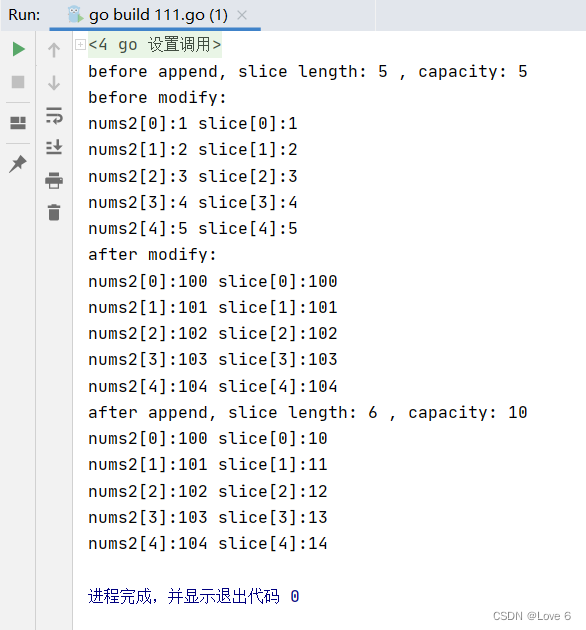
切片本质上就是指向底层的数组 可以是一开始就生成切片对象 也可以是生成了数组后 再在切片上面切
如果刚开始切片是基于数组 那么修改切片 本质就是修改数组 数组和切片共享的是同一块内存
而如果当切片append扩容后 超过了之前的切片的capacity 此时就会像vector一样 另外找一块内存地址 并且将当前的内容复制过去 此时切片其实本质和之前的数组就已经没关系了 下面例子可以很清晰的表示
111.gopackage main import ( "fmt" ) func main() { nums := [...]int {1, 2, 3, 4, 5} slice := nums[:] fmt.Println("before append, slice length:", len(slice), ", capacity:", cap(slice)) fmt.Println("before modify:") for index, num := range nums { fmt.Printf("nums2[%d]:%d slice[%d]:%d\n", index, num, index, slice[index]) } for i := 0; i < len(nums); i++ { slice[i] = i + 100 } fmt.Println("after modify:") for index, num := range nums { fmt.Printf("nums2[%d]:%d slice[%d]:%d\n", index, num, index, slice[index]) } slice = append(slice, 0) fmt.Println("after append, slice length:", len(slice), ", capacity:", cap(slice)) for i := 0; i < 5; i++ { slice[i] = i + 10 } for index, num := range nums { fmt.Printf("nums2[%d]:%d slice[%d]:%d\n", index, num, index, slice[index]) } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
运行效果
4.3、切片/切片的length和capacity
切片的length表示 当前切片中实际存在的长度
切片的cap表示 当前切片可扩容的长度切片如果基于 cap 可以扩容 当length == cap时 扩容则是2倍扩容
扩容底层有机制 后面我再详细看看但是如果切片基于其他切片 则cap最大只能是其他切片的cap 无法额外分配内存扩容
获取切片的length是由len()获取 capacity是由cap()获取
4.4、切片/Nil切片
如果是空切片 例如用
var slice1 []int生成切片
则为Nil切片 切片仅仅能和Nil切片作比较 不能与其他切片做比较111.gopackage main import "fmt" func main() { var slice1 []int if slice1 == nil { fmt.Println("Nil Slice") } else { fmt.Println("Non-Nil Slice") } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
运行效果

4.5、切片/设置为二维切片/切片添加元素
切片使用范围更多 当作vector
append添加元素二维切片
[][]string{}slice := [][]string{} slice = append(slice, []string{}) fmt.Println(len(slice[0]), cap(slice[0]))- 1
- 2
- 3
5、Range
对于切片或者有序序列
可以
Range用法如下 可用_代替range不用的值package main import "fmt" func main() { slice := [][]string{} slice = append(slice, []string{}) for index, str := range slice { fmt.Println(index, str) } for _, str := range slice { fmt.Println(str) } for index, _ := range slice { fmt.Println(index) } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
6.1、映射/map的初始化
就像是
c++中的map底层是用红黑树实现的
初始化map的方式map[key_type]value_type111.gopackage main import "fmt" func main() { map_ := map[string]int{} var m = make(map[string]int) map_["gogo"] = 1 map_["thanks"] = 2 m["gogo"] = 1 m["thanks"] = 2 fmt.Println(map_["gogo"], map_["thanks"]) fmt.Println(m["gogo"], m["thanks"]) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
6.2、映射/映射的基本操作
下面的操作包括 插入值 删除值 查找值
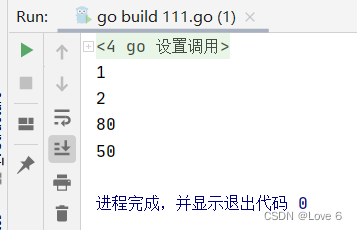
package main import "fmt" func main() { map_ := map[string]int{} map_["gogo"] = 1 map_["thanks"] = 2 elem, ok := map_["gogo"] fmt.Println(elem, ok) elem, ok = map_["go"] fmt.Println(elem, ok) map_["gogo"] = 3 elem, ok = map_["gogo"] fmt.Println(elem, ok) delete(map_, "gogo") elem, ok = map_["gogo"] fmt.Println(elem, ok) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
运行效果

7.1、函数/函数值
函数可以生成为类似于
c++的可执行函数对象 或者可以捆绑的执行函数对象package main import "fmt" func mul(x int, z int) int { return x * z } func mulfunc(func_ func(int, int) int, z int) int { return func_(3, 5) * z } func main() { funcobj := func(x, y int) int { return x * y } fmt.Println(funcobj(2, 3)) fmt.Println(mul(funcobj(2, 3), 20)) fmt.Println(mulfunc(funcobj, 20)) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
运行效果

7.2、函数/函数闭包
刚刚仔细去看了一下 发现并没有那么好理解
用我的话来解释一下 闭包内部声明的参数 其参数的声明期是和函数闭包对象的生命期一样的
并且返回一个匿名函数 之后匿名函数也可以使用之前声明的函数对象下面是简单的使用例子 后续复杂的使用还要再琢磨琢磨
111.gopackage main import "fmt" func add() func() int { i := 0 return func() int { i += 1 return i } } func deleter(x int) func(x int) int { i := 100 return func(x int) int { i -= x return i } } func main() { Adder := add() fmt.Println(Adder()) fmt.Println(Adder()) Deleter := deleter(10) fmt.Println(Deleter(20)) fmt.Println(Deleter(30)) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
运行效果
-
相关阅读:
upload-labs靶场通关指南(5-8关)
<C++>多态之纯虚函数与抽象类,学习不一样的析构函数
【C++面向对象侯捷下】4. pointer-like classes,关于智能指针 | 5. function-like classes,所谓仿函数
vscode中格式化C++代码缩进的方法
基于C语言实现进度条 | 附源码
我的自编全线连线计算程序目前世界领先技术水平
C++-openssl-aes-加密解密
c#字段和属性的区别
利用navicat定时传输数据到另一个库
网页设计期末作业,基于HTML+CSS+JavaScript超酷超炫的汽车类企业网站(6页)
- 原文地址:https://blog.csdn.net/qq_37500516/article/details/128063600
