
大家好,又见面了。
本文是笔者作为掘金技术社区签约作者的身份输出的缓存专栏系列内容,将会通过系列专题,讲清楚缓存的方方面面。如果感兴趣,欢迎关注以获取后续更新。
通过《重新认识下JVM级别的本地缓存框架Guava Cache——优秀从何而来》一文,我们知道了Guava Cache作为JVM级别的本地缓存组件的诸多暖心特性,也一步步地学习了在项目中集成并使用Guava Cache进行缓存相关操作。Guava Cache作为一款优秀的本地缓存组件,其内部很多实现机制与设计策略,同样值得开发人员深入的掌握与借鉴。
作为系列专栏,本篇文章我们将进一步探讨下Guava Cache 实现层面的一些逻辑与设计策略,让我们可以对Guava Cache整体有个更加明朗的认识。

数据回源与回填策略
前面我们介绍过,Guava Cache提供的是一种穿透型缓存模式,当缓存中没有获取到对应记录的时候,支持自动去源端获取数据并回填到缓存中。这里回源获取数据的策略有两种,即CacheLoader方式与Callable方式,两种方式适用于不同的场景,实际使用中可以按需选择。
下面一起看下这两种方式。
CacheLoader
CacheLoader适用于数据加载方式比较固定且统一的场景,在缓存容器创建的时候就需要指定此具体的加载逻辑。常见的使用方式如下:
public LoadingCache createUserCache() {
return CacheBuilder.newBuilder()
.build(new CacheLoader() {
@Override
public User load(String key) throws Exception {
System.out.println(key + "用户缓存不存在,尝试CacheLoader回源查找并回填...");
return userDao.getUser(key);
}
});
}
上述代码中,在使用CacheBuilder创建缓存容器的时候,如果在build()方法中传入一个CacheLoader实现类的方式,则最终创建出来的是一个LoadingCache具体类型的Cache容器:

默认情况下,我们需要继承CacheLoader类并实现其load抽象方法即可。

当然,CacheLoader类中还有一些其它的方法,我们也可以选择性的进行覆写来实现自己的自定义诉求。比如我们需要设定refreshAfterWrite来支持定时刷新的时候,就推荐覆写reload方法,提供一个异步数据加载能力,避免数据刷新操作对业务请求造成阻塞。

另外,有一点需要注意下,如果创建缓存的时候使用refreshAfterWrite指定了需要定时更新缓存数据内容,则必须在创建的时候指定CacheLoader实例,否则执行的时候会报错。因为在执行refresh操作的时候,必须调用CacheLoader对象的reload方法去执行数据的回源操作。

Callable
与CacheLoader不同,Callable的方式在每次数据获取请求中进行指定,可以在不同的调用场景中,分别指定并使用不同的数据获取策略,更加的灵活。
public static void main(String[] args) {
try {
GuavaCacheService cacheService = new GuavaCacheService();
Cache cache = cacheService.createCache();
String userId = "123";
// 获取userId, 获取不到的时候执行Callable进行回源
User user = cache.get(userId, () -> cacheService.queryUserFromDb(userId));
System.out.println("get对应用户信息:" + user);
} catch (Exception e) {
e.printStackTrace();
}
}
通过提供Callable实现函数并作为参数传递的方式,可以根据业务的需要,在不同业务调用场景下,指定使用不同的Callable回源策略。
不回源查询
前面介绍了基于CacheLoader方式自动回源,或者基于Callable方式显式回源的两种策略。但是实际使用缓存的时候,并非是缓存中获取不到数据时就一定需要去执行回源操作。
比如下面这个场景:
用户论坛中维护了个黑名单列表,每次用户登录的时候,需要先判断下是否在黑名单中,如果在则禁止登录。
因为论坛中黑名单用户占整体用户量的比重是极少的,也就是几乎绝大部分登录的时候去查询缓存都是无法命中黑名单缓存的。这种时候如果每次查询缓存中没有的情况下都去执行回源操作,那几乎等同于每次请求都需要去访问一次DB了,这显然是不合理的。
所以,为了支持这种场景的访问,Guava cache也提供了一种不会触发回源操作的访问方式。如下:
| 接口 | 功能说明 |
|---|---|
| getIfPresent | 从内存中查询,如果存在则返回对应值,不存在则返回null |
| getAllPresent | 批量从内存中查询,如果存在则返回存在的键值对,不存在的key则不出现在结果集里 |
上述两种接口,执行的时候仅会从当前内存中已有的缓存数据里面进行查询,不会触发回源的操作。
public static void main(String[] args) {
try {
GuavaCacheService cacheService = new GuavaCacheService();
Cache cache = cacheService.createCache();
cache.put("123", new User("123", "123"));
cache.put("124", new User("124", "124"));
System.out.println(cache.getIfPresent("125"));
ImmutableMap allPresentUsers =
cache.getAllPresent(Stream.of("123", "124", "125").collect(Collectors.toList()));
System.out.println(allPresentUsers);
} catch (Exception e) {
e.printStackTrace();
}
}
执行后,输入结果如下:
null
{123=User(userName=123, userId=123), 124=User(userName=124, userId=124)}
Guava Cache的数据清理与加载刷新机制
在前面的CacheBuilder类中有提供了几种expire与refresh的方法,即expireAfterAccess、expireAfterWrite以及refreshAfterWrite。
这里我们对几个方法进行一些探讨。
数据过期
对于数据有过期时效诉求的场景,我们可以通过几种方式设定缓存的过期时间:
-
expireAfterAccess
-
expireAfterWrite
现在我们思考一个问题:数据过期之后,会立即被删除吗?在前面的文章中,我们自己构建本地缓存框架的时候,有介绍过缓存数据删除的几种机制:
| 删除机制 | 具体说明 |
|---|---|
| 主动删除 | 搞个定时线程不停的去扫描并清理所有已经过期的数据。 |
| 惰性删除 | 在数据访问的时候进行判断,如果过期则删除此数据。 |
| 两者结合 | 采用惰性删除为主,低频定时主动删除为兜底,兼顾处理性能与内存占用。 |
在Guava Cache中,为了最大限度的保证并发性,采用的是惰性删除的策略,而没有设计独立清理线程。所以这里我们就可以回答前面的问题,也即过期的数据,并非是立即被删除的,而是在get等操作访问缓存记录时触发过期数据的删除操作。
在get执行逻辑中进行数据过期清理以及重新回源加载的执行判断流程,可以简化为下图中的关键环节:

在执行get请求的时候,会先判断下当前查询的数据是否过期,如果已经过期,则会触发对当前操作的Segment的过期数据清理操作。
数据刷新
除了上述的2个过期时间设定方法,Guava Cache还提供了个refreshAfterWrite方法,用于设定定时自动refresh操作。项目中可能会有这么个情况:
为了提升性能,将最近访问系统的用户信息缓存起来,设定有效期30分钟。如果用户的角色出现变更,或者用户昵称、个性签名之类的发生更改,则需要最长等待30分钟缓存失效重新加载后才能够生效。
这种情况下,我们就可以在设定了过期时间的基础上,再设定一个每隔1分钟重新refresh的逻辑。这样既可以保证数据在缓存中的留存时长,又可以尽可能的缩短缓存变更生效的时间。这种情况,便该refreshAfterWrite登场了。

与expire清理逻辑相同,refresh操作依旧是采用一种被动触发的方式来实现。当get操作执行的时候会判断下如果创建时间已经超过了设定的刷新间隔,则会重新去执行一次数据的加载逻辑(前提是数据并没有过期)。
鉴于缓存读多写少的特点,Guava Cache在数据refresh操作执行的时候,采用了一种非阻塞式的加载逻辑,尽可能的保证并发场景下对读取线程的性能影响。
看下面的代码,模拟了两个并发请求同时请求一个需要刷新的数据的场景:
public static void main(String[] args) {
try {
LoadingCache cache =
CacheBuilder.newBuilder().refreshAfterWrite(1L, TimeUnit.SECONDS).build(new MyCacheLoader());
cache.put("123", new User("123", "ertyu"));
Thread.sleep(1100L);
Runnable task = () -> {
try {
System.out.println(Thread.currentThread().getId() + "线程开始执行查询操作");
User user = cache.get("123");
System.out.println(Thread.currentThread().getId() + "线程查询结果:" + user);
} catch (Exception e) {
e.printStackTrace();
}
};
CompletableFuture.allOf(
CompletableFuture.runAsync(task), CompletableFuture.runAsync(task)
).thenRunAsync(task).join();
} catch (Exception e) {
e.printStackTrace();
}
}
执行后,结果如下:
14线程开始执行查询操作
13线程开始执行查询操作
13线程查询结果:User(userName=ertyu, userId=123)
14线程执行CacheLoader.reload(),oldValue=User(userName=ertyu, userId=123)
14线程执行CacheLoader.load()...
14线程执行CacheLoader.load()结束...
14线程查询结果:User(userName=97qx6, userId=123)
15线程开始执行查询操作
15线程查询结果:User(userName=97qx6, userId=123)
从执行结果可以看出,两个并发同时请求的线程只有1个执行了load数据操作,且两个线程所获取到的结果是不一样的。具体而言,可以概括为如下几点:
-
同一时刻仅允许一个线程执行数据重新加载操作,并阻塞等待重新加载完成之后该线程的查询请求才会返回对应的新值作为结果。
-
当一个线程正在阻塞执行
refresh数据刷新操作的时候,其它线程此时来执行get请求的时候,会判断下数据需要refresh操作,但是因为没有获取到refresh执行锁,这些其它线程的请求不会被阻塞等待refresh完成,而是立刻返回当前refresh前的旧值。 -
当执行refresh的线程操作完成后,此时另一个线程再去执行get请求的时候,会判断无需refresh,直接返回当前内存中的当前值即可。
上述的过程,按照时间轴的维度来看,可以囊括成如下的执行过程:
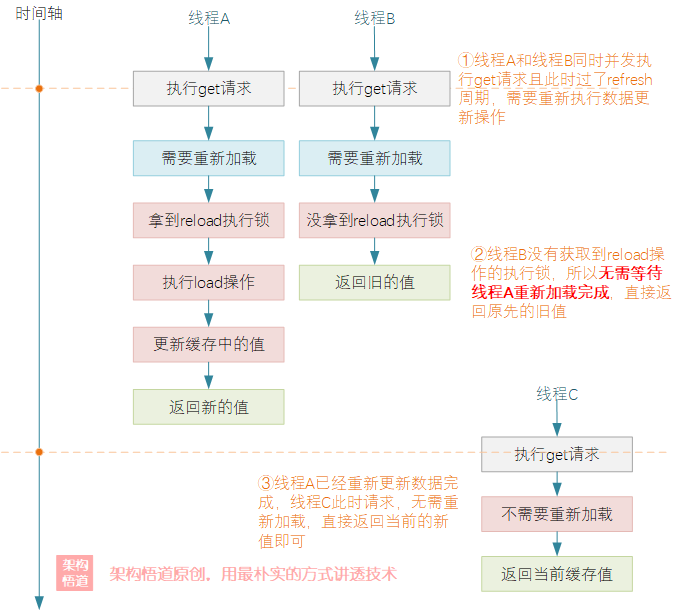
数据expire与refresh关系
expire与refresh在某些实现逻辑上有一定的相似度,很多的文章中介绍的时候甚至很直白的说refresh比expire更好,因为其不会阻塞业务端的请求。个人认为这种看法有点片面,从单纯的字面含义上也可以看出这两种机制不是互斥的、而是一种相互补充的存在,并不存在谁比谁更好这一说,关键要看具体是应用场景。

expire操作就是采用的一种严苛的更新锁定机制,当一个线程执行数据重新加载的时候,其余的线程则阻塞等待。refresh操作执行过程中不会阻塞其余线程的get查询操作,会直接返回旧值。这样的设计各有利弊:
| 操作 | 优势 | 弊端 |
|---|---|---|
| expire | 有效防止缓存击穿问题,且阻塞等待的方式可以保证业务层面获取到的缓存数据的强一致性。 | 高并发场景下,如果回源的耗时较长,会导致多个读线程被阻塞等待,影响整体的并发效率。 |
| refresh | 可以最大限度的保证查询操作的执行效率,避免过多的线程被阻塞等待。 | 多个线程并发请求同一个key对应的缓存值拿到的结果可能不一致,在对于一致性要求特别严苛的业务场景下可能会引发问题。 |
Guava Cache中的expire与fefresh两种机制,给人的另一个困惑点在于:两者都是被动触发的数据加载逻辑,不管是expire还是refresh,只要超过指定的时间间隔,其实都是依旧存在与内存中,等有新的请求查询的时候,都会执行自动的最新数据加载操作。那这两个实际使用而言,仅仅只需要依据是否需要阻塞加载这个维度来抉择?
并非如此。
expire存在的意义更多的是一种数据生命周期终结的意味,超过了expire有效期的数据,虽然依旧会存在于内存中,但是在一些触发了cleanUp操作的情况下,是会被释放掉以减少内存占用的。而refresh则仅仅只是执行数据更新,框架无法判断是否需要从内存释放掉,会始终占据内存。
所以在具体使用时,需要根据场景综合判断:
-
数据需要永久存储,且不会变更,这种情况下
expire和refresh都并不需要设定 -
数据极少变更,或者对变更的感知诉求不强,且并发请求同一个key的竞争压力不大,直接使用
expire即可 -
数据无需过期,但是可能会被修改,需要及时感知并更新缓存数据,直接使用
refresh -
数据需要过期(避免不再使用的数据始终留在内存中)、也需要在有效期内尽可能保证数据的更新一致性,则采用
expire与refresh两者结合。
对于expire与refresh结合使用的场景,两者的时间间隔设置,需要注意:
expire时间设定要大于refresh时间,否则的话refresh将永远没有机会执行
Guava Cache并发能力支持
采用分段锁降低锁争夺
前面我们提过Guava Cache支持多线程环境下的安全访问。我们知道锁的粒度越大,多线程请求的时候对锁的竞争压力越大,对性能的影响越大。而如果将锁的粒度拆分小一些,这样同时请求到同一把锁的概率就会降低,这样线程间争夺锁的竞争压力就会降低。
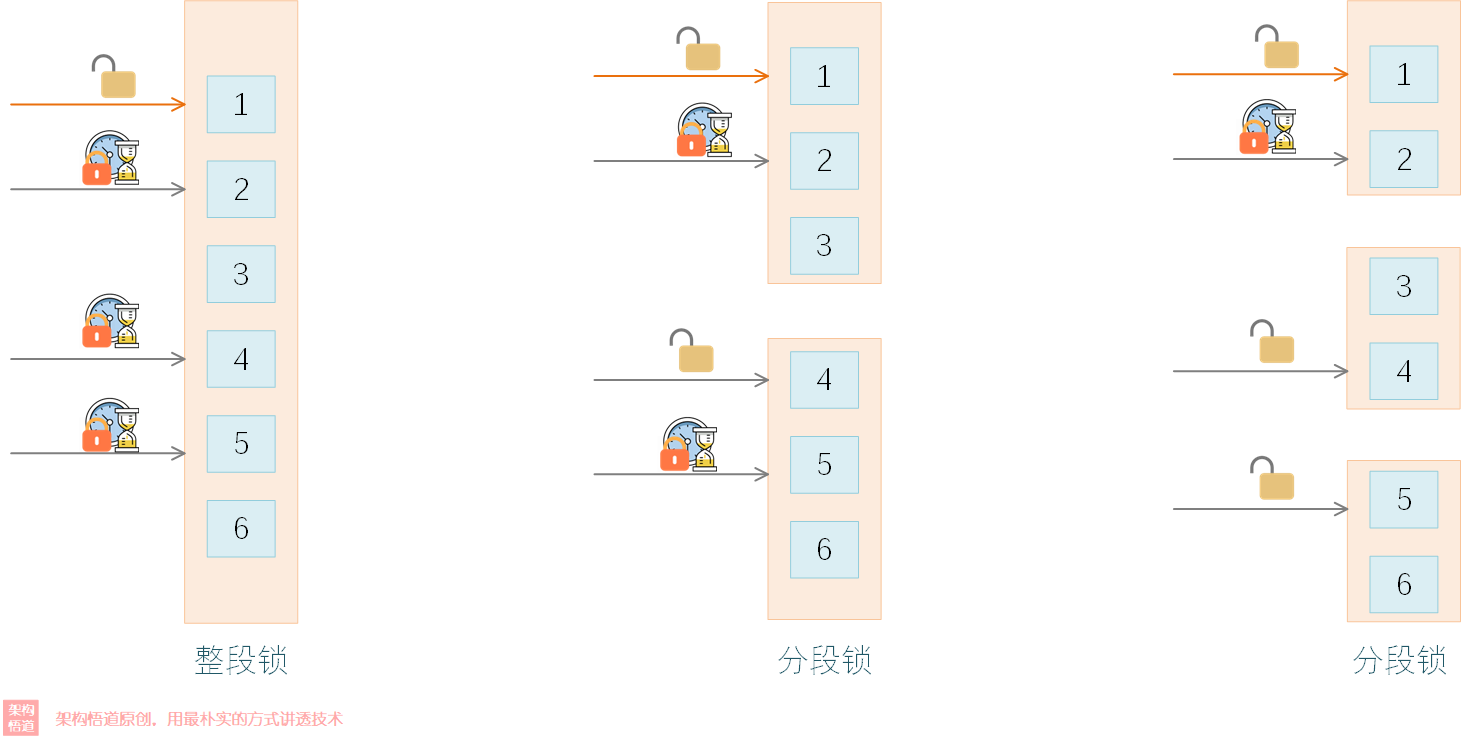
Guava Cache中采用的也就是这种分段锁策略来降低锁的粒度,可以在创建缓存容器的时候使用concurrencyLevel来指定允许的最大并发线程数,使得线程安全的前提下尽可能的减少锁争夺。而concurrencyLevel值与分段Segment的数量之间也存在一定的关系,这个关系相对来说会比较复杂、且受是否限制总容量等因素的影响,源码中这部分的计算逻辑可以看下:
int segmentShift = 0;
int segmentCount = 1;
while (segmentCount < concurrencyLevel && (!evictsBySize() || segmentCount * 20 <= maxWeight)) {
++segmentShift;
segmentCount <<= 1;
}
根据上述的控制逻辑代码,可以将segmentCount的取值约束概括为下面几点:
-
segmentCount 是 2 的整数倍
-
segmentCount 最大可能为
(concurrencyLevel -1)*2 -
如果有按照权重设置容量,则segmentCount不得超过总权重值的
1/20
从源码中可以比较清晰的看出这一点,Guava Cache在put写操作的时候,会首先计算出key对应的hash值,然后根据hash值来确定数据应该写入到哪个Segment中,进而对该Segment加锁执行写入操作。
@Override
public V put(K key, V value) {
// ... 省略部分逻辑
int hash = hash(key);
return segmentFor(hash).put(key, hash, value, false);
}
@Nullable
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
// ... 省略具体逻辑
} finally {
unlock();
postWriteCleanup();
}
}
根据上述源码也可以得出一个结论,concurrencyLevel只是一个理想状态下的最大同时并发数,也取决于同一时间的操作请求是否会平均的分散在各个不同的Segment中。极端情况下,如果多个线程操作的目标对象都在同一个分片中时,那么只有1个线程可以持锁执行,其余线程都会阻塞等待。

实际使用中,比较推荐的是将concurrencyLevel设置为CPU核数的2倍,以获得较优的并发性能。当然,concurrencyLevel也不是可以随意设置的,从其源码设置里面可以看出,允许的最大值为65536。
static final int MAX_SEGMENTS = 1 << 16; // 65536
LocalCache(CacheBuildersuper K, ? super V> builder, @Nullable CacheLoadersuper K, V> loader) {
concurrencyLevel = Math.min(builder.getConcurrencyLevel(), MAX_SEGMENTS);
// ... 省略其余逻辑
}
佛系抢锁策略
在put等写操作场景下,Guava Cache采用的是上述分段锁的策略,通过优化锁的粒度,来提升并发的性能。但是加锁毕竟还是对性能有一定的影响的,为了追求更加极致的性能表现,在get等读操作自身并没有发现加锁操作 —— 但是Guava Cache的get等处理逻辑也并非是纯粹的只读操作,它还兼具触发数据淘汰清理操作的删除逻辑,所以只在判断需要执行清理的时候才会尝试去佛系抢锁。
那么它是如何减少抢锁的几率的呢?从源码中可以看出,并非是每次请求都会去触发cleanUp操作,而是会尝试积攒一定次数之后再去尝试清理:
static final int DRAIN_THRESHOLD = 0x3F;
void postReadCleanup() {
if ((readCount.incrementAndGet() & DRAIN_THRESHOLD) == 0) {
cleanUp();
}
}
在高并发场景下,如果查询请求量巨大的情况下,即使按照上述的情况限制每次达到一定请求数量之后才去执行清理操作,依旧可能会出现多个get操作线程同时去抢锁执行清理操作的情况,这样岂不是依旧会阻塞这些读取请求的处理吗?
继续看下源码:
void cleanUp() {
long now = map.ticker.read();
runLockedCleanup(now);
runUnlockedCleanup();
}
void runLockedCleanup(long now) {
// 尝试请求锁,请求到就处理,请求不到就放弃
if (tryLock()) {
try {
// ... 省略部分逻辑
readCount.set(0);
} finally {
unlock();
}
}
}
可以看到源码中采用的是tryLock方法来尝试去抢锁,如果抢到锁就继续后续的操作,如果没抢到锁就不做任何清理操作,直接返回 —— 这也是为什么前面将其形容为“佛系抢锁”的缘由。这样的小细节中也可以看出Google码农们还是有点内功修为的。
承前启后 —— Caffeine Cache
技术的更新迭代始终没有停歇的时候,Guava工具包作为Google家族的优秀成员,在很多方面提供了非常优秀的能力支持。随着JAVA8的普及,Google也基于语言的新特性,对Guava Cache部分进行了重新实现,形成了后来的Caffeine Cache,并在SpringBoot2.x中取代了Guava Cache。
下一篇文章中,我们将一起再聊一聊令人上瘾的Caffeine Cache。
小结回顾
好啦,关于Guava Cache中的典型实现机制与核心设计策略,就介绍到这里了。至此,我们完成了Guava Cache从简单会用到深度剖析的全过程,不知道小伙伴们是否对Guava Cache有了全新的认识了呢?关于Guava Cache,你是否有自己的一些想法与见解呢?欢迎评论区一起交流下,期待和各位小伙伴们一起切磋、共同成长。
📣 补充说明1 :
本文属于《深入理解缓存原理与实战设计》系列专栏的内容之一。该专栏围绕缓存这个宏大命题进行展开阐述,全方位、系统性地深度剖析各种缓存实现策略与原理、以及缓存的各种用法、各种问题应对策略,并一起探讨下缓存设计的哲学。
如果有兴趣,也欢迎关注此专栏。
📣 补充说明2 :
- 关于本文中涉及的演示代码的完整示例,我已经整理并提交到github中,如果您有需要,可以自取:https://github.com/veezean/JavaBasicSkills
我是悟道,聊技术、又不仅仅聊技术~
如果觉得有用,请点赞 + 关注让我感受到您的支持。也可以关注下我的公众号【架构悟道】,获取更及时的更新。
期待与你一起探讨,一起成长为更好的自己。
