-
浅析数据采集工具Flume
title: Flume系列
第一章 Flume基础理论
1.1 数据收集工具产生背景
Hadoop 业务的一般整体开发流程:
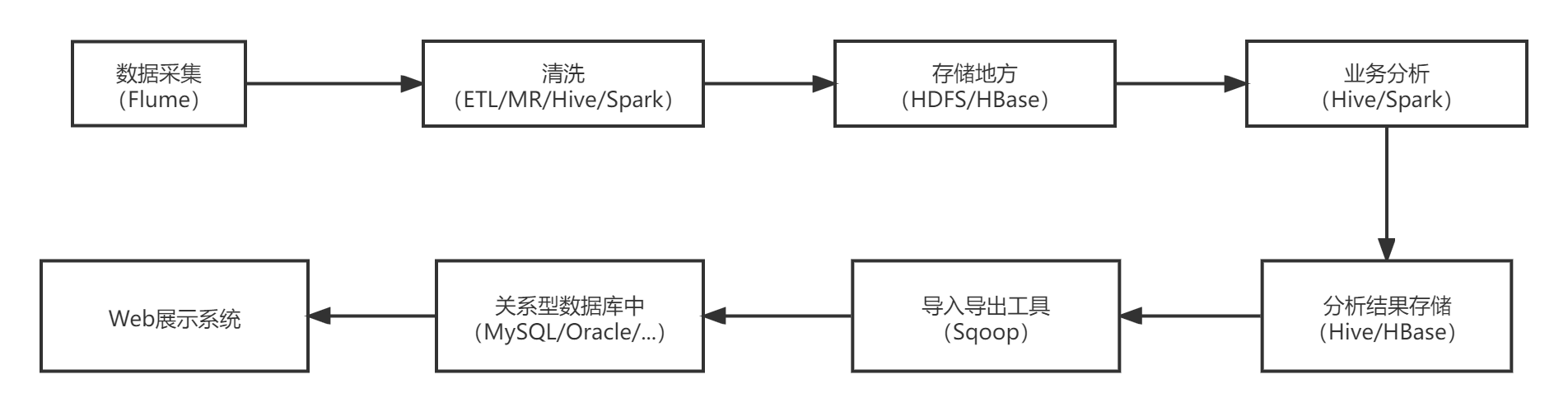
任何完整的大数据平台,一般都会包括以下的基本处理过程:
数据采集 数据 ETL 数据存储 数据计算/分析 数据展现- 1
- 2
- 3
- 4
- 5
其中,数据采集是所有数据系统必不可少的,随着大数据越来越被重视,数据采集的挑战也变的尤为突出。这其中包括:
数据源多种多样 数据量大,变化快 如何保证数据采集的可靠性的性能 如何避免重复数据 如何保证数据的质量- 1
- 2
- 3
- 4
- 5
我们今天就来看看当前可用的一些数据采集的产品,重点关注一些它们是如何做到高可靠, 高性能和高扩展。
总结:
数据的来源大体上包括:1、业务数据 2、爬取的网络公开数据 3、购买数据 4、自行采集日志数据- 1
- 2
- 3
- 4
1.1 Flume简介
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.- 1
Flume 是一个分布式、可靠、高可用的海量日志聚合系统,支持在系统中定制各类数据发送 方,用于收集数据,同时,Flume 提供对数据的简单处理,并写到各种数据接收方的能力。
1、 Apache Flume 是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统,和 Sqoop 同属于数据采集系统组件,但是 Sqoop 用来采集关系型数据库数据,而 Flume 用来采集流动型数据。
2、 Flume 名字来源于原始的近乎实时的日志数据采集工具,现在被广泛用于任何流事件数 据的采集,它支持从很多数据源聚合数据到 HDFS。
3、 一般的采集需求,通过对 flume 的简单配置即可实现。Flume 针对特殊场景也具备良好 的自定义扩展能力,因此,flume 可以适用于大部分的日常数据采集场景 。
4、 Flume 最初由 Cloudera 开发,在 2011 年贡献给了 Apache 基金会,2012 年变成了 Apache 的顶级项目。Flume OG(Original Generation)是 Flume 最初版本,后升级换代成 Flume NG(Next/New Generation)。
5、 Flume 的优势:可横向扩展、延展性、可靠性。
1.2 Flume版本
Flume 在 0.9.x and 1.x 之间有较大的架构调整:
1.x 版本之后的改称 Flume NG
0.9.x 版本称为 Flume OG,最后一个版本是 0.94,之后是由 Apache 进行了重构
N是New 和 O是OldFlume1.7版本要求:
Flume OG Old/Original Generation Flume NG New/Next Generation- 1
- 2

注意,上面是flume1.7的要求,其他版本要求可能会不一样!!
本文使用版本链接:http://flume.apache.org/releases/content/1.7.0/FlumeUserGuide.html
官网链接:http://flume.apache.org/
Flume1.9 版本要求:
System Requirements
Java Runtime Environment - Java 1.8 or later Memory - Sufficient memory for configurations used by sources, channels or sinks Disk Space - Sufficient disk space for configurations used by channels or sinks Directory Permissions - Read/Write permissions for directories used by agent- 1
- 2
- 3
- 4
第二章 Flume体系结构/核心组件
agent:能独立执行一个数据收集任务的JVM进程 source : agent中的一个用来跟数据源对接的服务 channel : agent内部的一个中转组件 sink : agent中的一个用来跟数据目的地对接的服务 event: 消息流转的一个载体/对象 header body 常见source的类型 Avro source :接收网络端口中的数据 exec source: 监听文件新增内容 tail -f spooldir source :监控文件夹的,如果这个文件夹里面的文件发送了变化,就可以采集 Taildir source: 多目录多文件实时监控 常见的channel的类型 memory : 内存中 , 快 , 但不安全 file : 相对来说安全些,但是效率低些 jdbc: 使用数据库进行数据的保存 常见的sink的类型 logger 做测试使用 HDFS 离线数据的sink 一般 Kafka 流式数据的sink 以上仅仅是常见的一些,官网中有完整的。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
2.1 介绍
Flume 的数据流由事件(Event)贯穿始终。事件是 Flume 的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些 Event 由 Agent 外部的 Source 生成,当 Source 捕获事 件后会进行特定的格式化,然后 Source 会把事件推入(单个或多个)Channel 中。你可以把 Channel 看作是一个缓冲区,它将保存事件直到 Sink 处理完该事件。Sink 负责持久化日志或 者把事件推向另一个 Source。
Flume 以 agent 为最小的独立运行单位
一个 agent 就是一个 JVM
单 agent 由 Source、Sink 和 Channel 三大组件构成。
如下面官网图片
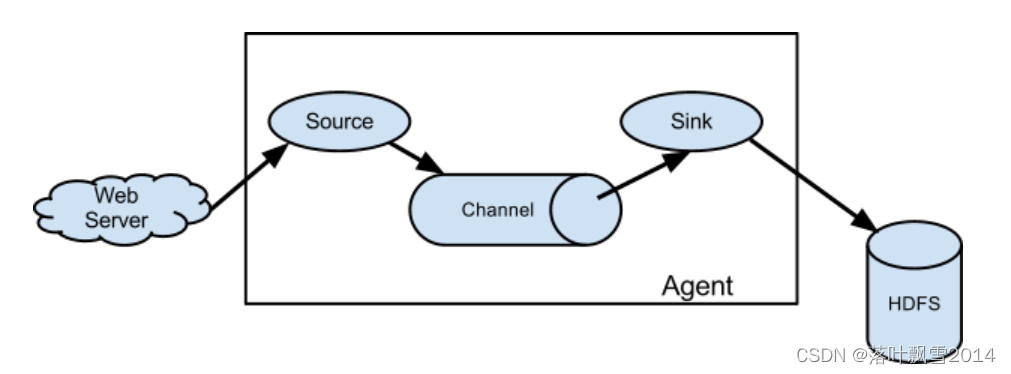
解释:

2.2 Flume三大核心组件
Event
Event 是 Flume 数据传输的基本单元。
Flume 以事件的形式将数据从源头传送到最终的目的地。
Event 由可选的 header 和载有数据的一个 byte array 构成。
载有的数据对 flume 是不透明的。
Header 是容纳了 key-value 字符串对的无序集合,key 在集合内是唯一的。
Header 可以在上下文路由中使用扩展。Client
Client 是一个将原始 log 包装成 events 并且发送他们到一个或多个 agent 的实体
目的是从数据源系统中解耦 Flume
在 Flume 的拓扑结构中不是必须的Agent
一个 Agent 包含 source,channel,sink 和其他组件。
它利用这些组件将 events 从一个节点传输到另一个节点或最终目的地。
Agent 是 flume 流的基础部分。
Flume为这些组件提供了配置,声明周期管理,监控支持。Agent 之 Source
Source 负责接收 event 或通过特殊机制产生 event,并将 events 批量的放到一个或多个
包含 event 驱动和轮询两种类型
不同类型的 Source
与系统集成的 Source:Syslog,Netcat,监测目录池
自动生成事件的 Source:Exec
用于 Agent 和 Agent 之间通信的 IPC source:avro,thrift
Source 必须至少和一个 channel 关联Agent 之 Channel
Channel 位于 Source 和 Sink 之间,用于缓存进来的 event
当 sink 成功的将 event 发送到下一个的 channel 或最终目的,event 从 channel 删除
不同的 channel 提供的持久化水平也是不一样的
Memory Channel:volatile(不稳定的)
File Channel:基于 WAL(预写式日志 Write-Ahead Logging)实现
JDBC Channel:基于嵌入式 database 实现
Channel 支持事务,提供较弱的顺序保证
可以和任何数量的 source 和 sink 工作Agent 之 Sink
Sink 负责将 event 传输到下一级或最终目的地,成功后将 event 从 channel 移除
不同类型的 sink ,比如 HDFS,HBase2.3 Flume经典部署方案
1、单Agent采集数据
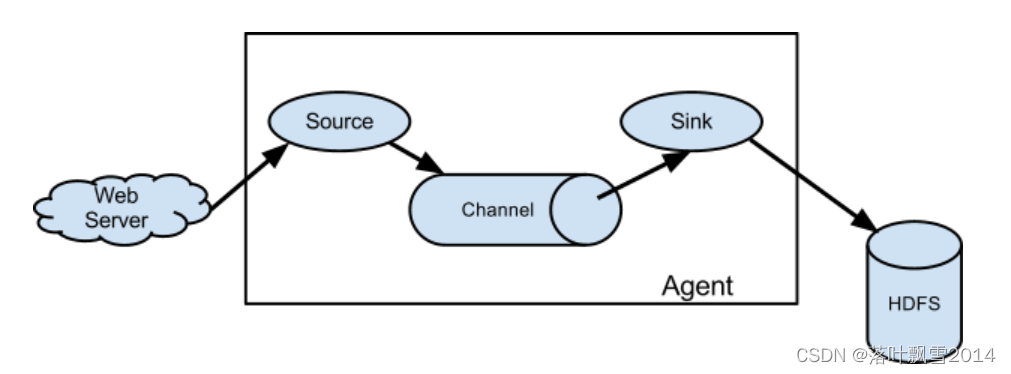
由一个 agent 负责把从 web server 中收集数据到 HDFS 。
2、多Agent串联
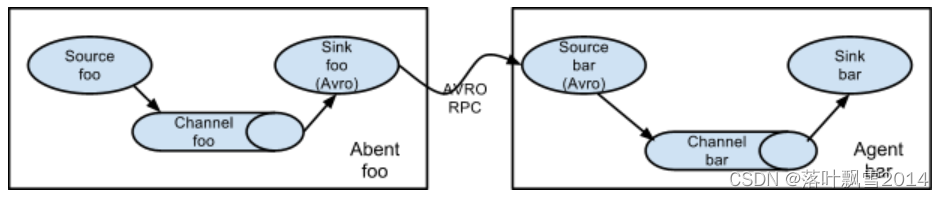
在收集数据的过程中,可以让多个 agent 串联起来,形成一条 event 数据线,进行传输,但 是注意的是:相邻两个 agent 的前一个 agent 的 sink 类型要和后一个 agent 的 source 类型一 致。
3、多Agent合并串联
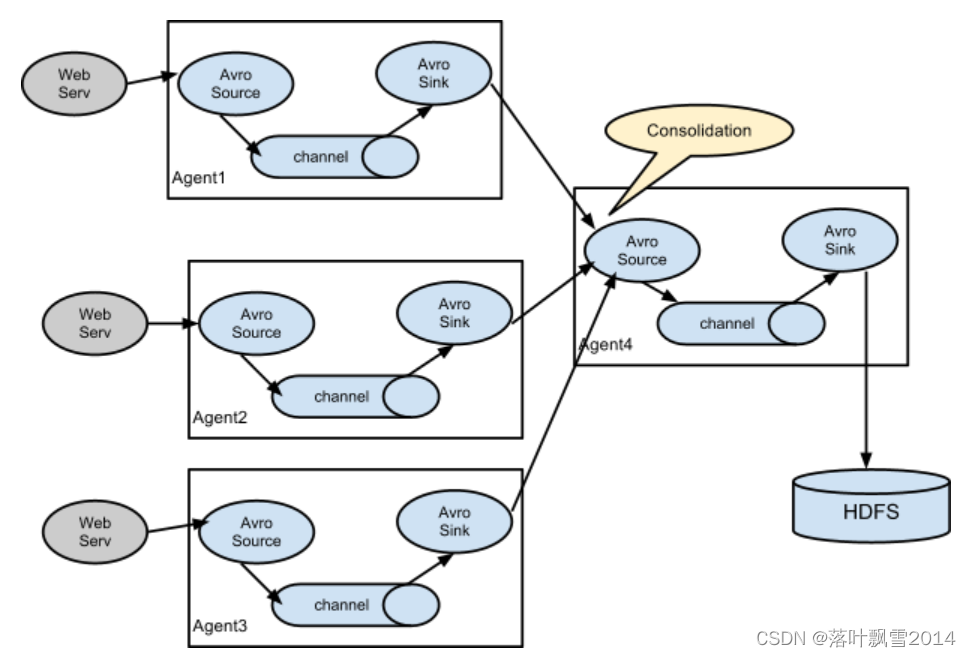
多个 agent 串联,并联成一个复杂的 数据收集架构。反映了 flume 的部署灵活。并且针对关键节点,还可以进行高可用配置。
4、多路复用
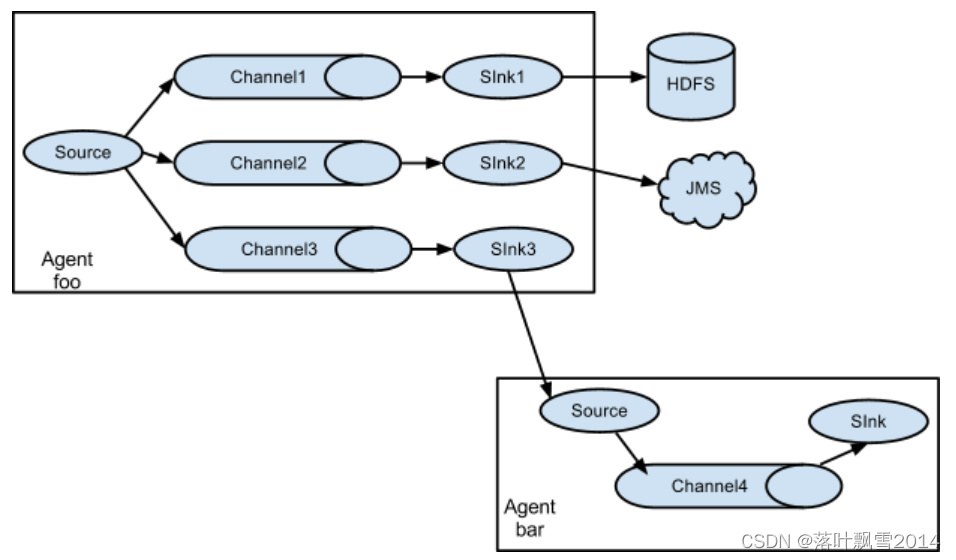
一份数据流,可以被复制成多份数据流,交给多个不同组件进行处理。一般用于一边永久存储一边进行计算。
第三章 Flume安装及案例
3.1 安装部署
3.1.1 Flume1.7安装部署
1、将apache-flume-1.7.0-bin.tar.gz上传到hadoop0的/software目录下,并解压
[root@hadoop0 software]# tar -zxvf apache-flume-1.7.0-bin.tar.gz- 1
2、重命名为flume
[root@hadoop0 software]# mv apache-flume-1.7.0-bin flume- 1
3、修改flume-env.sh文件
[root@hadoop0 conf]# mv flume-env.sh.template flume-env.sh- 1
然后vim flume-env.sh,修改jdk路径
export JAVA_HOME=/software/jdk- 1
3.1.2 Flume1.9安装部署
1、将apache-flume-1.9.0-bin.tar.gz上传到hadoop10的/software目录下,并解压
[root@hadoop10 software]# tar -zxvf apache-flume-1.9.0-bin.tar.gz- 1
2、重命名为flume
[root@hadoop10 software]# mv apache-flume-1.9.0-bin flume- 1
3、修改flume-env.sh文件
[root@hadoop10 conf]# mv flume-env.sh.template flume-env.sh- 1
然后vim flume-env.sh,修改jdk路径
export JAVA_HOME=/software/jdk- 1
4、看看Flume版本
[root@hadoop10 bin]# flume-ng version Flume 1.9.0 Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git Revision: d4fcab4f501d41597bc616921329a4339f73585e Compiled by fszabo on Mon Dec 17 20:45:25 CET 2018 From source with checksum 35db629a3bda49d23e9b3690c80737f9 [root@hadoop10 bin]# pwd /software/flume/bin [root@hadoop10 bin]#- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.2 案例
3.2.1 监控端口数据(官方案例)
1、在flume的目录下面创建文件夹 [root@hadoop0 flume]# mkdir job [root@hadoop0 flume]# cd job 2、定义配置文件telnet-logger.conf [root@hadoop0 job]# vim telnet-logger.conf 添加内容如下: # example.conf: A single-node Flume configuration # Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 3、先开启flume监听端口 退到flume目录 官方样例:bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console 实际操作: bin/flume-ng agent --conf conf/ --name a1 --conf-file job/telnet-logger.conf -Dflume.root.logger=INFO,console 4、执行telnet localhost 44444 telnet localhost 44444 会先报找不到telnet [root@hadoop10 flume]# telnet localhost 44444 bash: telnet: command not found... [root@hadoop10 flume]# 然后执行yum -y install telnet 5、发送命令测试即可- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
针对于上述配置telnet-logger.conf文件的内容的解释:
# example.conf: A single-node Flume configuration # Name the components on this agent #a1: 表示的是agent的名字 a1.sources = r1 #r1 : 表示的是a1的输入源 a1.sinks = k1 #k1 : 表示的a1的输出目的地 a1.channels = c1 #c1 : 表示的a1的缓冲区 # Describe/configure the source #配置source a1.sources.r1.type = netcat #表示a1的输入源r1的类型是netcat类型 a1.sources.r1.bind = localhost #表示a1监听的主机 a1.sources.r1.port = 44444 #表示a1监听的端口号 # Describe the sink #描述sink a1.sinks.k1.type = logger #表示a1的输入目的地k1的类型是logger # Use a channel which buffers events in memory a1.channels.c1.type = memory #表示a1的channel的类型是memory类型 a1.channels.c1.capacity = 1000 #表示a1的channel总容量1000个event a1.channels.c1.transactionCapacity = 100 #表示a1的channel传输的时候收集到了100个event以后再去提交事务 # Bind the source and sink to the channel a1.sources.r1.channels = c1 #表示将r1和c1 连接起来 a1.sinks.k1.channel = c1 #表示将k1和c1 连接起来 3、先开启flume监听端口 退到flume目录 官方样例:bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=INFO,console 实际操作:bin/flume-ng agent --conf conf/ --name a1 --conf-file job/telnet-logger.conf -Dflume.root.logger=INFO,console bin/flume-ng agent --conf conf/ --name a1 --conf-file job/telnet-logger2.conf -Dflume.root.logger=INFO,console 参数说明: --conf conf : 表示配置文件在conf目录 --name a1 : 表示给agent起名为a1 --conf-file job/telnet-logger.conf : flume本次启动所要读取的配置文件在job文件夹下面的telnet-logger.conf文件 -Dflume.root.logger=INFO,console : -D 表示flume运行时候的动态修改flume.root.logger参数值,并将日志打印到控制台,级别是INFO级别。 日志级别: log、info、warn、error- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
3.2.2 监控目录中的文件到HDFS
1、创建配置文件dir-hdfs.conf 在job目录下面 vim dir-hdfs.conf 添加下面的内容: a3.sources = r3 a3.sinks = k3 a3.channels = c3 # Describe/configure the source a3.sources.r3.type = spooldir a3.sources.r3.spoolDir = /software/flume/upload a3.sources.r3.fileSuffix = .COMPLETED a3.sources.r3.fileHeader = true a3.sources.r3.ignorePattern = ([^ ]*\.tmp) # Describe the sink a3.sinks.k3.type = hdfs a3.sinks.k3.hdfs.path = hdfs://hadoop10:8020/flume/upload/%Y%m%d/%H a3.sinks.k3.hdfs.filePrefix = upload- a3.sinks.k3.hdfs.round = true a3.sinks.k3.hdfs.roundValue = 1 a3.sinks.k3.hdfs.roundUnit = hour a3.sinks.k3.hdfs.useLocalTimeStamp = true a3.sinks.k3.hdfs.batchSize = 100 a3.sinks.k3.hdfs.fileType = DataStream a3.sinks.k3.hdfs.rollInterval = 600 a3.sinks.k3.hdfs.rollSize = 134217700 a3.sinks.k3.hdfs.rollCount = 0 a3.sinks.k3.hdfs.minBlockReplicas = 1 # Use a channel which buffers events in memory a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3 2、启动监控目录命令 bin/flume-ng agent --conf conf/ --name a3 --conf-file job/dir-hdfs.conf- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
针对于上述配置dir-hdfs.conf文件的内容的解释:
1、创建配置文件dir-hdfs.conf 在job目录下面 vim dir-hdfs.conf 添加下面的内容: a3.sources = r3 #定义source为r3 a3.sinks = k3 #定义sink为k3 a3.channels = c3 #定义channel为c3 # Describe/configure the source #配置source相关的信息 a3.sources.r3.type = spooldir #定义source的类型是spooldir类型 a3.sources.r3.spoolDir = /software/flume/upload #定义监控的具体的目录 a3.sources.r3.fileSuffix = .COMPLETED #文件上传完了之后的后缀 a3.sources.r3.fileHeader = true #是否有文件头 a3.sources.r3.ignorePattern = ([^ ]*\.tmp) #忽略以tmp结尾的文件,不进行上传 # Describe the sink #配置sink相关的信息 a3.sinks.k3.type = hdfs #定义sink的类型是hdfs a3.sinks.k3.hdfs.path = hdfs://hadoop10:8020/flume/upload/%Y%m%d/%H #文件上传到hdfs的具体的目录 a3.sinks.k3.hdfs.filePrefix = upload- #文件上传到hdfs之后的前缀 a3.sinks.k3.hdfs.round = true #是否按照时间滚动生成文件 a3.sinks.k3.hdfs.roundValue = 1 #多长时间单位创建一个新的文件 a3.sinks.k3.hdfs.roundUnit = hour #时间单位 a3.sinks.k3.hdfs.useLocalTimeStamp = true #是否使用本地时间 a3.sinks.k3.hdfs.batchSize = 100 #积累多少个event才刷写到hdfs一次 a3.sinks.k3.hdfs.fileType = DataStream #文件类型 a3.sinks.k3.hdfs.rollInterval = 600 #多久生成新文件 a3.sinks.k3.hdfs.rollSize = 134217700 #多大生成新文件 a3.sinks.k3.hdfs.rollCount = 0 #多少event生成新文件 a3.sinks.k3.hdfs.minBlockReplicas = 1 #副本数 # Use a channel which buffers events in memory a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3 2、启动监控目录命令 bin/flume-ng agent --conf conf/ --name a3 --conf-file job/dir-hdfs.conf- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
在执行上面的命令过程中遇到的了一点点小问题:
...... SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] Exception in thread "SinkRunner-PollingRunner-DefaultSinkProcessor" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V at org.apache.hadoop.conf.Configuration.set(Configuration.java:1357) at org.apache.hadoop.conf.Configuration.set(Configuration.java:1338) at org.apache.hadoop.conf.Configuration.setBoolean(Configuration.java:1679) at org.apache.flume.sink.hdfs.BucketWriter.open(BucketWriter.java:221) at org.apache.flume.sink.hdfs.BucketWriter.append(BucketWriter.java:572) at org.apache.flume.sink.hdfs.HDFSEventSink.process(HDFSEventSink.java:412) at org.apache.flume.sink.DefaultSinkProcessor.process(DefaultSinkProcessor.java:67) at org.apache.flume.SinkRunner$PollingRunner.run(SinkRunner.java:145) at java.lang.Thread.run(Thread.java:748)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
解决方案:将lib文件夹下的guava-11.0.2.jar删除以兼容Hadoop的版本。可以通过重命名的方式注释掉即可(实现删除的效果)。
[root@hadoop10 lib]# mv guava-11.0.2.jar guava-11.0.2.jar.backup- 1
3.2.3 监控文件到HDFS
1、创建一个自动化文件 [root@hadoop0 job]# vim mydateauto.sh 写入: #!/bin/bash while true do echo `date` sleep 1 done 然后运行测试: [root@hadoop0 job]# sh mydateauto.sh Wed Aug 19 18:34:19 CST 2020 Wed Aug 19 18:34:20 CST 2020 然后修改配置,将输出的日志追加到某个文件中 #!/bin/bash while true do echo `date` >> /software/flume/mydate.txt sleep 1 done 再次执行[root@hadoop0 job]# sh mydateauto.sh 就会在flume的文件夹下面生成了mydate.txt文件 通过tail -f mydate.txt 查看 再次执行sh mydateauto.sh 查看输出。 2、创建配置vim file-hdfs.conf # Name the components on this agent a2.sources = r2 a2.sinks = k2 a2.channels = c2 # Describe/configure the source a2.sources.r2.type = exec a2.sources.r2.command = tail -F /software/flume/mydate.txt a2.sources.r2.shell = /bin/bash -c # Describe the sink a2.sinks.k2.type = hdfs a2.sinks.k2.hdfs.path = hdfs://hadoop10:8020/flume/%Y%m%d/%H a2.sinks.k2.hdfs.filePrefix = logs- a2.sinks.k2.hdfs.round = true a2.sinks.k2.hdfs.roundValue = 1 a2.sinks.k2.hdfs.roundUnit = hour a2.sinks.k2.hdfs.useLocalTimeStamp = true a2.sinks.k2.hdfs.batchSize = 1000 a2.sinks.k2.hdfs.fileType = DataStream a2.sinks.k2.hdfs.rollInterval = 600 a2.sinks.k2.hdfs.rollSize = 134217700 a2.sinks.k2.hdfs.rollCount = 0 a2.sinks.k2.hdfs.minBlockReplicas = 1 # Use a channel which buffers events in memory a2.channels.c2.type = memory a2.channels.c2.capacity = 1000 a2.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r2.channels = c2 a2.sinks.k2.channel = c2 3、启动 bin/flume-ng agent --conf conf/ --name a2 --conf-file job/file-hdfs.conf- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
针对于上述配置file-hdfs.conf文件的内容的解释:
# Name the components on this agent a2.sources = r2 #定义source为r2 a2.sinks = k2 #定义sink为k2 a2.channels = c2 #定义channel为c2 # Describe/configure the source a2.sources.r2.type = exec #定义source的类型是exec 可执行命令 a2.sources.r2.command = tail -F /software/flume/mydate.txt #具体文件位置 a2.sources.r2.shell = /bin/bash -c #命令开头 # Describe the sink #sink相关配置 a2.sinks.k2.type = hdfs #定义sink的类型是hdfs a2.sinks.k2.hdfs.path = hdfs://hadoop10:8020/flume/%Y%m%d/%H #具体的位置 a2.sinks.k2.hdfs.filePrefix = logs- a2.sinks.k2.hdfs.round = true a2.sinks.k2.hdfs.roundValue = 1 a2.sinks.k2.hdfs.roundUnit = hour a2.sinks.k2.hdfs.useLocalTimeStamp = true a2.sinks.k2.hdfs.batchSize = 100 a2.sinks.k2.hdfs.fileType = DataStream a2.sinks.k2.hdfs.rollInterval = 600 #单位是秒!! a2.sinks.k2.hdfs.rollSize = 134217700 a2.sinks.k2.hdfs.rollCount = 0 a2.sinks.k2.hdfs.minBlockReplicas = 1 # Use a channel which buffers events in memory a2.channels.c2.type = memory a2.channels.c2.capacity = 1000 a2.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r2.channels = c2 a2.sinks.k2.channel = c2 3、启动 bin/flume-ng agent --conf conf/ --name a2 --conf-file job/file-hdfs.conf- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
过程中遇到的一点点小问题:

18 Oct 2021 14:32:24,340 INFO [conf-file-poller-0] (org.apache.flume.sink.DefaultSinkFactory.create:42) - Creating instance of sink: k2, type: hdfs 18 Oct 2021 14:32:24,348 ERROR [conf-file-poller-0] (org.apache.flume.node.AbstractConfigurationProvider.loadSinks:469) - Sink k2 has been removed due to an error during configuration java.lang.InstantiationException: Incompatible sink and channel settings defined. sink's batch size is greater than the channels transaction capacity. Sink: k2, batch size = 1000, channel c2, transaction capacity = 100 at org.apache.flume.node.AbstractConfigurationProvider.checkSinkChannelCompatibility(AbstractConfigurationProvider.java:403) at org.apache.flume.node.AbstractConfigurationProvider.loadSinks(AbstractConfigurationProvider.java:462) at org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:106) at org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:145) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
解决方案:
问题原因:原因其实很明了了,就是字面的意思,channel 与 sink的设置不匹配,sink的batch size大于channel的transaction capacity 解决方案:将a2.sinks.k2.hdfs.batchSize设置为小于等于100 。 或者注释掉也可以。- 1
- 2
3.2.4 多目录多文件实时监控(Taildir Source)
与前面使用到的Source的对比
Spooldir Source 用于同步新文件,但不适合对实时追加日志的文件进行监听并同步。 Exec source 用于监控一个实时追加的文件,不能实现断点续传; Taildir Source 用于监听多个实时追加的文件,并且能够实现断点续传。- 1
- 2
- 3
操作案例:
1、在job下面创建 vim taildir-hdfs.conf a3.sources = r3 a3.sinks = k3 a3.channels = c3 # Describe/configure the source a3.sources.r3.type = TAILDIR a3.sources.r3.positionFile = /software/flume/taildir.json a3.sources.r3.filegroups = f1 f2 a3.sources.r3.filegroups.f1 = /software/flume/taildirtest/filedir/.*file.* a3.sources.r3.filegroups.f2 = /software/flume/taildirtest/logdir/.*log.* # Describe the sink a3.sinks.k3.type = hdfs a3.sinks.k3.hdfs.path = hdfs://hadoop10:8020/flume/uploadtaildir/%Y%m%d/%H a3.sinks.k3.hdfs.filePrefix = upload- a3.sinks.k3.hdfs.round = true a3.sinks.k3.hdfs.roundValue = 1 a3.sinks.k3.hdfs.roundUnit = hour a3.sinks.k3.hdfs.useLocalTimeStamp = true a3.sinks.k3.hdfs.batchSize = 100 a3.sinks.k3.hdfs.fileType = DataStream a3.sinks.k3.hdfs.rollInterval = 600 a3.sinks.k3.hdfs.rollSize = 134217700 a3.sinks.k3.hdfs.rollCount = 0 a3.sinks.k3.hdfs.minBlockReplicas = 1 # Use a channel which buffers events in memory a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3 2、创建文件文件夹,注意需要在启动之前创建监控的文件夹 [root@hadoop10 flume]# mkdir taildirtest [root@hadoop10 flume]# cd taildirtest/ [root@hadoop10 taildirtest]# ll total 0 [root@hadoop10 taildirtest]# mkdir filedir [root@hadoop10 taildirtest]# mkdir logdir [root@hadoop10 taildirtest]# ll total 0 drwxr-xr-x. 2 root root 6 Oct 18 16:44 filedir drwxr-xr-x. 2 root root 6 Oct 18 16:45 logdir [root@hadoop10 taildirtest]# vim file.txt [root@hadoop10 taildirtest]# vim log.txt [root@hadoop10 taildirtest]# ll total 8 drwxr-xr-x. 2 root root 6 Oct 18 16:44 filedir -rw-r--r--. 1 root root 35 Oct 18 16:45 file.txt drwxr-xr-x. 2 root root 6 Oct 18 16:45 logdir -rw-r--r--. 1 root root 35 Oct 18 16:46 log.txt 3、启动监控目录命令 bin/flume-ng agent --conf conf/ --name a3 --conf-file job/taildir-hdfs.conf 4、测试 [root@hadoop10 taildirtest]# cp file.txt filedir/ [root@hadoop10 taildirtest]# cp log.txt logdir/ [root@hadoop10 taildirtest]# cd filedir/ [root@hadoop10 filedir]# echo hello1 >> file.txt [root@hadoop10 filedir]# cd ../logdir/ [root@hadoop10 logdir]# echo hello2 >> log.txt [root@hadoop10 logdir]#- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014B站: https://space.bilibili.com/1523287361 点击打开链接
微博地址: http://weibo.com/luoyepiaoxue2014 点击打开链接 -
相关阅读:
你真的了解黑客吗?
webview的使用说明
【Linux】应用层协议序列化和反序列化
ArrayList常用Api分析及注意事项
【探索Linux】—— 强大的命令行工具 P.9(进程地址空间)
springboot+vue学生信息管理系统学籍 成绩 选课 奖惩,奖学金缴费idea maven mysql
京东11.11真便宜闭眼买,联合众品牌共倡“真低价”
当GPT遇到程序分析:在GPTScan中实现智能合约逻辑漏洞检测
Hive-启动与操作(2)
数字营销(一)客户画像浅谈
- 原文地址:https://blog.csdn.net/luoyepiaoxue2014/article/details/128062066