-
大数据中的R语言——中国大学MOOC课程笔记
第一章 R语言简介
1.1 简介

R的特性:
• 免费的
• 一个全面的统计研究平台
• 拥有顶尖水准的制图功能
• 一个可进行交互式数据分析和探索的强大平台
• 轻松地从各种类型的数据源导入数据,包括文本文件、数据库管理系统、统计软件,乃至专门的数据仓库
• 可运行于多种平台之上
• R最激动人心的一部分功能是通过可选模块的下载和安装来实现
的
• 目前有2500多个称为包(package)的用户贡献模块可从
http://cran.r-project.org/web/packages下载
1.2 包的安装与使用
第一次安装一个包,使用命令install.packages()即可
• 使用library()命令载入包,例如library(gclus)
使用包时常见的错误:
• 错误的大小写,例如:help(),Help(),HELP()是三个不同的函数
• 忘记使用必要的引号,例如:install.packages(gclus)会报错
• 函数调用时忘记使用括号,例如:使用help代替了help()
• 使用了尚未载入包中的函数,例如:要先载入gclus才能使用
order.clusters()
1.3 R中的基本操作


第二章 数据类型与结构
2.1 数据集
据构成的一个矩形数组称为数据集
查看R中所有内置的数据集
data(package = .packages(all.available = TRUE))
• 查看指定包中的数据集
data(package =“package name”)
• 查看某个数据集的信息
Help函数 or ?
2.2 创建矩阵
matrix(data,nrow,ncol,byrow,dimnames)
a_matrix<-matrix(1:12, nrow=4,dimnames=list(c("r1","r2","r3","r4"),c("c1","c2","c3") )- 1
2.3 访问矩阵

2.4 数组与数据框
数组是可以在两个以上的维度存储数据的R数据对象。
使用array函数创建数组:
array(data,dim,dimnames)- 1
数据框可以将不同的数据类型组合在一起的数据结构
使用data.frame函数创建数据框:
data.frame(col1,col2,col3,…)- 1
选取数据框的元素:
- 1 使用[ ],指定两个下标,类似矩阵的选取方法
- 2 可以指定列名访问
- **2** **使用$记号选取某个特定变量**- 1
2.5 attach() 和detach()
attach():将数据框添加到R的搜索路径中
detach(): 将数据框从搜索路径中移除
2.6 With()函数
功能:使R表达式位于数据框的作用环境中
with(mtcars,{summary(mpg) plot(mpg,disp)})- 1
2.7 实例标识符
patientdata <-data.frame(patientID, age,diabetes, status, row.names=patientID)- 1
- 2
通过定义数据框时指定rowname选项指定实例标识符
2.8 因子
用于对数据进行分类并将其存储为级别的数据对象

创建因子
1 使用函数factor()将原始表示类别的字符串映射到整数上
diabetes <- factor(diabetes)- 1
2 创建有序的因子型向量
status <- factor(status,ordered=TRUE)- 1
3 展示一个因子的所有水平
levels(status)- 1
列表
列表是可以包含多个不同数据元素的数据对象
使用list()函数创建列表:
Mylist <- list(obj1,obj2,obj3,…)- 1
创建列表的同时指定每一个列表项的名称
Mylist <- list(name=obj1,name2 = obj2,…)- 1
访问列表元素:
使用双重方括号、指明代表某个成份的数字或名称、使用一个方括号得到列表
Mylist[[2]] Mylist[[“ages”]] Mylist[2]- 1
- 2
- 3
2.9 数据的输入和数据集标注

从键盘输入数据:
- 使用edit()调出文本编辑器来进行数据的输入
第三章 图形
- 通过par()修改图形参数
par(optionname=value,optionname=name,…)- 1
不带参数时,将生成一个含当前图形参数设置的列表。
令参数no.readonly=TRUE,可以生成一个可修改的当前图形参
数列表。
以这种方式设定的参数值除非被再次修改,否则将会在会话结
束前一直有效。
- 在绘图函数中直接设置
plot(dose,drugA,type=”b”,lty=2,pch=17)- 1



- R****中创建连续型颜色向量的函数
1 rainbow()
2 heat.colors()
3 terrain.colors
4 topo.colors
5 cm.colors()
6 gray()
- 文本设定与图形的设定



- 设置坐标轴和文本标注



- 添加刻度线、参考线和图例
使用Hmisc包中的minor.tick()函数添加刻度线。
abline(h=yvalues,v=xvalues) 添加参考线。
图例的调用格式与参数含义:
legend(location,title,legend,…) ⁻ location: 可以使用x,y坐标定位图例,也可用关键字 "bottomright", "bottom", "bottomleft", "left", "topleft", "top", "topright", "right" and "center"等来放置图例。 ⁻ title: 图例标题的字符串 ⁻ legend: 图例标签组成的字符型向量- 1
- 2
- 3
- 4
- 5
- 6
- 文本标注

- 图形的组合
使用par()函数进行组合:在par()函数中使用图形参数mfrow=c(rows,cols)来创建按行填充的,行数为rows、列数为cols的图形矩阵或者是按列填充的矩阵。
使用layout函数进行组合:layout(mat),使用widths和heights两个参数精确控制每幅图形的大小。
第四章 数据管理
4.1 变量
• 变量名←表达式:“表达式”部分可以包含多种运算符和函数

问题:有一个名为mydata的数据框,其中的变量为x1和x2,如何:
• 创建一个新变量sumx,存储以上两个变量的加和,
• 并创建一个新变量meanx,存储这两个变量的均值。


变量的重编码
根据同一个变量(和/或其他变量)的现有值创建新值的过程。



变量的重命名
方法1:调用一个交互式的编辑器: fix(leadership)
方法2:以编程方式, reshape包中有一个rename()函数
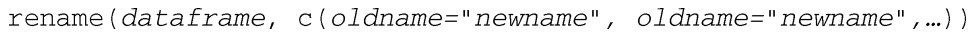
方法3:names()函数,示例: date重命名为为testDate, q5重命名为item1到item5。
4.2 缺失值
缺失值记号
• NA (Not Available,不可用)表示缺失值。
• NaN (Not a Number,非数值)表示不可能出现的值。
is.na()函数
•第一,缺失值是不可比较的,即便是与缺失值自身的比较。
•第二,R并不把无限的或者不可能出现的数值标记成缺失值。
na.omit()函数删除所有含有缺失数据的观测
类型转换
R中提供了一系列用来判断某个对象的数据类型和将其转换为另
一种数据类型的函数
• is.datatype()这样的函数返回TRUE或FALSE
• as.datatype()这样的函数将其参数转换为对应的类型

4.3 数据排序
order()函数:对一个数据框进行排序
• 默认的排序顺序是升序
• 排序变量的前边加一个减号(-)即可得到降序的排序结果
4.4 数据集的合并
1 向数据框中添加列(变量)
• merge()函数
• bind()函数
2 向数据框中添加行(观测)
• rbind()函数
数据集的合并-添加列
• merge()函数
• 横向合并两个数据框(数据集)
• 例如:将dataframeA和dataframeB按照ID进行合并
total<-merge(dataframeA, dataframeB, by=“ID”)- 1
• cbind()函数
• 不需要指定一个公共索引,直接横向合并两个矩阵或数据框
total<-cbind(dataframeA, dataframeB)- 1
数据集的合并-添加行
• rbind()函数
• 纵向合并两个数据框(数据集)
• 两个数据框必须拥有相同的变量,不过它们的顺序不必一定相同
• 如果dataframeA中拥有dataframeB中没有的变量,合并之前做以下某一
种处理:
• 删除dataframeA中的多余变量
• 在dataframeB中创建追加的变量并将其值设为NA(缺失)
total<-rbind(dataframeA, dataframeB)- 1
4.5 数据集取子集



-选入观测:
取第1行到第3行(前三个观测): newdata->leadership[1:3,] newdata 取所有30岁以上的男性: newdata <- leadership[leadership$gender=="M" & leadership$age > 30,]- 1
- 2
- 3
- 4
- 5
使用whichj进行选择:

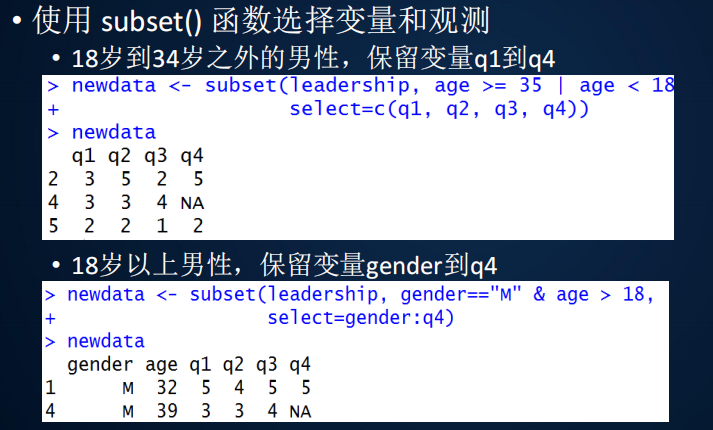
使用subset()函数进行选择
随机抽样
sample() 函数能够让你从数据集中(有放回或无放回地)抽取大
小为 n 的一个随机样本
• 第一个参数是一个由要从中抽样的元素组成的向量
• 第二个参数是要抽取的元素数量
• 第三个参数表示无放回抽样
mysample<- leadership[sample(1:nrow(leadership),3, replace=FALSE),]>- 1
第五章 高 级 数 据 管 理
5.1数值与字符处理函数
数学函数
函数 描述 代码示例 运行结果 abs(x) x的绝对值 abs(-4) 4 sqrt(x) x的平方根 sqrt(25) 5 ceiling(x) 不小于x的最小整数 ceiling(3.475) 4 floor(x) 不大于x的最大整数 floor(3.475) 3 trunc(x) 向0的方向截取x的整数部分 trunc(5.99) 5 round(x, digits=n) 将x舍入为指定位的小数 round(3.475,digits=2) 3.48 signif(x, digits=n) 将x舍入为指定的有效数字位数 signif(3.475, digits=2) 3.5 cos(x)、sin(x)、tan(x) x的余弦、正弦和正切值 cos(2) -0.416 acos(x)、asin(x)、atan(x) x的反余弦、反正弦和反正切值 acos(-0.416) 2 函数 描述 代码示例 代码运行结果 log(x, base=n) 对x取n为底的对数 log(10,2) 3.32 log(x) 自然对数 log(10) 2.3 log10(x) 常用对数 log10(100) 2 exp(x) 指数函数 exp(2) 7.39 统计函数
函数 描述 代码示例 代码运行结果 mean(x) 平均值 mean(c(1,2,3,4)) 2.5 median(x) 中位数 median(c(1,2,3,4)) 2.5 sd(x) 标准差 sd(c(1,2,3,4)) 1.29 var(x) 方差 var(c(1,2,3,4)) 1.67 mad(x) 绝对中位差 mad(c(1,2,3,4)) 1.48 quantile(x, probs) 求分位数。其中x为待求分位 数的数值型向量, probs为一 个由[0,1]之间的概率值组成 的数值向量 y<- quantile(x, c(.3,.84)) range(x) 求域值 如 果 : x<-c(1,2,3,4) 则range(x) 14 sum(x) 求和 sum(c(1,2,3,4)) 10 函数 描述 代码示例 运行结果 diff(x, lag=n) 滞后差分,lag指明滞后几项,默认的 lag值为1 x<-c(1,5,23,29) diff(x) 4,18,6 min(x) 最小值 十 min(c(1,2,3,4)) max(x) 最大值 + max(c(1,2,3,4)) 4 scale(x, center = TRUE, scale=TRUE) 为数据对象x按列进行中心化 (center=TRUE)或者标准化 (center=TRUE, scale=TRUE) 概率分布函数
分布名称 缩写 分布名称 缩写 Beta分布 beta Logistic分布 logis 二项分布 binom 多项分布 multinom 柯西分布 cauchy 负二项分布 nbinom (非中心)卡方分布 chisq 正态分布 norm 指数分布 exp 泊松分布 pois F分布 f Wilcoxon符号秩分布 signrank Gamma分布 gamma t分布 t 几何分布 geom 均匀分布 unif 超几何分布 hyper Weibull分布 weibull 对数正态分布 lnorm Wilcoxon秩和分布 wilcox 
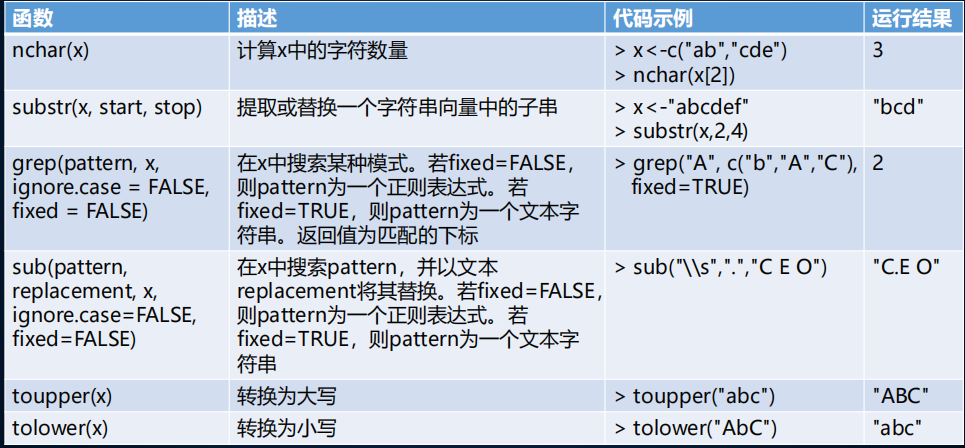
5.2 字 符 处 理 函 数


其他实用函数:

5.3 控制流语句
语句(statement)是一条单独的R语句或一组复合语句(包含
在花括号{ } 中的一组R语句,使用分号分隔)
• 条件(cond)是一条最终被解析为真(TRUE)或假(FALSE)
的表达式
• 表达式(expr)是一条数值或字符串的求值语句
• 序列(seq)是一个数值或字符串序列



5.4 自定义函数
自定义函数的一般形式: myfunction <- function(arg1, arg2……){statements return (object)}- 1
- 2
第六章 基本图形
条形图
使用barplot()绘制
➢格式:barplot(height)
• height是一个向量或者一个矩阵
−向量:简单条形图
−矩阵:堆积条形图
• 默认绘制垂直条形图

➢棘状图:一种特殊的条形图,对堆砌条形图进行了重缩放,这样
每个条形的高度均为1,每一段的高度表示比例。
➢使用vcd包中的spine()函数绘制
➢格式:spine(height,…)
饼图
➢使用pie函数绘制
➢格式:pie(x,labels)
• x:非负数值向量,表示每个扇形的面积
• labels:各扇形标签的字符型向量
扇形图
➢使用plotrix包中的fan.plot函数绘制
➢格式:fan.plot(x,labels)
• X:非负数值向量,表示每个扇形的面积
• labels:各扇形标签的字符型向量
➢扇形张开角的大小表示相对比例关系
直方图

核密度图
用于描述连续型随机变量概率密度的一种方法
使用density()生成核密度估计值
density(x)
一般与绘图函数连用:plot(density(x))

➢常用于比较组间差异
➢使用sm包的sm.density.compare()函数向图形叠加多组核密度
图
➢使用格式:
• sm.density.compare(x,factor)
• x是一个数值型向量
• factor是一个分组变量
箱线图
又称盒须图,通过绘制连续型变量的5数总括来描述了连
续型变量的分布。
使用boxplot函数绘制箱线图:
boxplot(x,…)- 1
如何得到中位数、最大值、最小值、上下四分位数
boxplot.stats(x)- 1
展示单个变量或分组变量:
boxplot(formula,data=dataframe) formula:一个公式,形如y~A dataframe:提供数据的数据框或列表数 varwidth:为TRUE时,箱线图的宽度与其样本大小的平方根成正比 horizontal:为TRUE可以反转坐标轴的方向- 1
- 2
- 3
- 4
- 5
小提琴图
箱线图的一个变种,是箱线图和核密度图的结合
使用vioplot函数绘制:
vioplot(x1,x2,…,names=,col= ) • x1,x2,…:要绘制的一个或多个数值向量 • names:小提琴图中标签的字符向量 • col:一个颜色向量,指定每副小提琴图的颜色- 1
- 2
- 3
- 4

点图
一种在简单水平刻度上绘制大量有标签值的方法
使用dotchart()函数绘制:
dotchart(x,labels=) x:数值型向量 labels:由每个点的标签组成的向量 可选参数:groups,gcolor,cex- 1
- 2
- 3
- 4

注意:点图整的分好组以后超级好看 值得深入学习。
第七章 基本统计分析
7.1 描述性统计分析
使用summary()计算描述性统计量

使用sapply()计算所选择的任意描述性统计量

• n 观测数
• mean 均值
• stdev 标准差
• skew 偏度
• kurtosis 峰度
使用aggregate()分组获取描述性统计量:

使用by()分组计算描述性统计量:

7.2 频数表和列联表

• 一维列联表 • 生成简单的频数统计表:mytable <- table(Arthritis$Improved) • 查看治疗效果:mytable • 查看治疗效果的比例: prop.table(mytable) • 查看治疗效果的百分比:prop.table(mytable)*100 • 求和:margin.table(mytable) • 求和,将结果加入表中:addmargins(mytable) • 二维列联表 • 使用table()创建二维列联表: table(Arthritis$Treatment,Arthritis$Improved) • 使用xtabs()创建二维列联表: mytable <- xtabs(~Treatment+Improved, Arthritis); • 生成边际频数:margin.table(mytable, 1); margin.table(mytable,2) • 生成边际比例:prop.table(mytable,1)*100;prop.table(mytable,2)*100 • 查看每个单元格所占比例: prop.table(mytable) • 添加边际和: addmargins(mytable) • 添加边际比例和: addmargins(prop.table(mytable) ) • 仅添加了各行的比例和: addmargins(prop.table(mytable,1),2 ) • 仅添加了各列的比例和: addmargins(prop.table(mytable,2),1 ) • 三方包gmodels中的CrossTable()函数: CrossTable(Arthritis$Treatment,Arthritis$Improved) • 多维列联表 • 使用table()创建多维列联表: with(Arthritis,table(Treatment, Sex, Improved)) • 使用xtabs创建多维列联表: mytable <- xtabs(~Treatment+Sex+Improved, data=Arthritis) • 使用ftable()对三维列表输出格式进行美化: ftable(mytable) • 为治疗情况、性别和改善情况生成了边际频数:margin.table(mytable,1); margin.table(mytable,1);margin.table(mytable,1) • 为治疗情况× 改善情况分组的边际频数,由不同性别的单元加和而成: margin.table(mytable,c(1,3)) • 每个Treatment × Sex组合中各类改善情况的比例: ftable(prop.table(mytable, c(1,2 )))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
独立性检验
R提供了多种检验类别型变量独立性的方法
• 卡方独立性检验
• chisq.test( )函数可对二维表的行变量进行卡方独立性检验。
• Fisher精确检验
• fisher.test( )函数可进行FIsher精确检验。
• Cochran-Mantel-Haenszel检验
• mentelhaen.test( )函数可用来进行Cochran-Mantel-Haenszel卡方检验。
对二维表的行变量和列变量进行卡方独立性检验。示例: 1. mytable <- xtabs(~ Treatment + Improved, data = Arthritis) chisq.test(mytable) • p<0.01,患者接收的治疗和改善的水平可能存在某种关系 2. mytable <- xtabs(~ Improved + Sex, data = Arthritis) chisq.test(mytable) • p>0.05,患者性别和改善情况之间互相独立 • Fisher精确检验的原假设是:边界固定的列联表中行和列是相互 独立的。 例: mytable <- xtabs(~ Treatment + Improved, data = Arthritis) fisher.test(mytable) 进行Cochran—Mantel—Haenszel卡方检验,其原假设是,两个名 义变量在第三个变量的每一层中都是条件独立的。例: mytable <- xtabs(~ Treatment + Improved + Sex, data = Arthritis) mantelhaen.test(mytable)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
相关性度量
assocstats()函数可以用来计算二维列联表的phi系数、列联系数和
Cramer’s V系数。
mytable <- xtabs(~ Treatment + Improved, data = Arthritis) assocstats(mytable)- 1
- 2
相关的类型-Pearson、pearman、Kendall:
• Pearson积差相关系数衡量了两个定量变量之间的线性相关程度
• Spearman等级相关系数则衡量分级定序变量之间的相关程度
• Kendall’s Tau相关系数也是一种非参数的等级相关度量
偏相关是指在控制一个或多个定量变量时,另外两个定量变量之
间的相互关系。
pcor(c(1,5,2,3,6),cov(states))- 1
另外,polycor包中的hetcor( )函数可以计算一种混合的相关矩阵,其中
包括:
• 数值型变量的Pearson积差相关系数、
• 数值型变量和有序变量之间的多系列相关系数、
• 有序变量之间的多分格相关系数以及二分变量之间的四分相关系数。
相关性检验(重要)
得到相关系数后,进行统计显著性检验
• 常用的厡假设为变量间不相关(即总体的相关系数为0)
cor.test( )函数 • 对单个的Pearson、Spearman和Kendall相关系数进行检验。 • 使用格式: cor.test(x, y, alternative = , method = ) • x和y为要检验相关性的变量, • alternative则用来指定进行双侧检验或单侧检验(取值为“two.side”、 "less"或"greater"), • method用以指定要计算的相关类型- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
独立样本的t检验:
针对变量为连续型的组间比较,并假设其呈正态分布。
• 检验的调用格式,其中y是一个数值型变量, x是一个二分变量:
t. test (y ~ x, data)
非独立样本的t检验
• 假定组间的差异呈正态分布
• 检验的调用格式为, y1和y2为两个非独立组的数值向量 :
t. test(y1, y2, paired = TRUE)
Wilcoxon秩和检验
若两组数据独立,可以使用Wilcoxon秩和检验来评估观测是否是从相
同的概率分布中抽得的。
• 调用格式为:wilcox.test(y ~ x, data)
• 其中的y是数值型变量,x是一个二分变量。
第八章回归分析

R中,拟合线性模型最基本的函数是lm():
myfit <- lm(formula, data) • formula指要拟合的模型形式 lm()函数中formula的形式一般为 Y~X1+X2+…+Xk • data是一个数据框,包含了用于拟合模型的数据 • myfit是结果对象,存储在一个列表中- 1
- 2
- 3
- 4


-
相关阅读:
用低代码打造CRM系统 实现客户个性化管理
记录错误 Method com/mchange/v2/c3p0/impl/NewProxyResultSet.isClosed()Z is abstract
电脑计算机xinput1_3.dll丢失的解决方法分享,四种修复手段解决问题
MySQL笔记之Checkpoint机制
linux驱动之设备树语法(2)
研究者 如何思考
JAVA计算机毕业设计电子商城系统Mybatis+源码+数据库+lw文档+系统+调试部署
opencv 的应用(1)
跳表与红黑树
3D着色器(OpenGL)
- 原文地址:https://blog.csdn.net/qq_41520353/article/details/128067607
