-
Airflow用于ETL的四种基本运行模式, 2022-11-20
(2022.11.20 Sun)
基本运行模式(pattern)是data pipeline使用Airflow的DAG的不同结构,基本模式有如下四种 :- 序列Sequence
- 平行拆分Parallel split
- 同步Synchronisation
- 单选Exclusive choice
序列模式
序列模式即若干task按先后顺序依次执行,在运行代码上 表示为
task_1 >> task_2 >> ...。- dag = DAG(
- dag_id='sequential_pattern',
- default_args={
- 'start_date': utils.dates.days_ago(1),
- },
- schedule_interval=None,
- )
- with dag:
- read_input = DummyOperator(task_id='read_input')
- aggregate_data = DummyOperator(task_id='generate_data')
- write_to_redshift = DummyOperator(task_id='write_to_redshift')
- read_input >> aggregate_data >> write_to_redshift
Parallel split
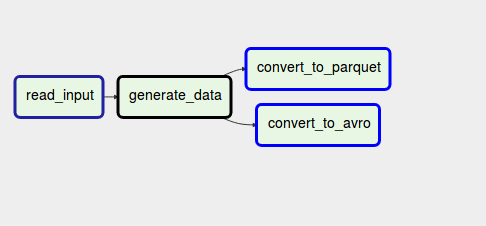
parallel split
parallel split模式用于在分支的情况。比如当数据集备好之后,需要被加载进入多个不同的tasks,且都是同一个pipeline中,如同数据进入不同的分支。
分支在DAG中的表示为
task_1 >> [task_2, task_3]
案例如- dag = DAG(
- dag_id='pattern_parallel_split',
- default_args={
- 'start_date': utils.dates.days_ago(1),
- },
- schedule_interval=None,
- )
- with dag:
- read_input = DummyOperator(task_id='read_input')
- aggregate_data = DummyOperator(task_id='generate_data')
- convert_to_parquet = DummyOperator(task_id='convert_to_parquet')
- convert_to_avro = DummyOperator(task_id='convert_to_avro')
- read_input >> aggregate_data >> [convert_to_parquet, convert_to_avro]
Sychronisation
与parallel split相似,在同步模式中,不同branch的结果汇聚(reconciliation)在一个task中,不同的branch执行并行计算,并将结果整合。

synchronization
DAG的代码表达中,同步模式可拆解为在每个
for loop中执行顺序模式,即- for xx in xxx:
- task_0 >> task_i >> task_2
代码实例
- dag = DAG(
- dag_id='pattern_synchronization',
- default_args={
- 'start_date': utils.dates.days_ago(1),
- },
- schedule_interval=None,
- )
- with dag:
- convert_to_parquet = DummyOperator(task_id='convert_to_parquet')
- for hour in range(0, 24):
- read_input = DummyOperator(task_id='read_input_hour_{}'.format(hour))
- aggregate_data = DummyOperator(task_id='generate_data_hour_{}'.format(hour))
- read_input >> aggregate_data >> convert_to_parquet
单选
根据预先设定的条件,在分支部分选择不同的task执行。

exclusive choice
在Apache Airflow中,可通过
BranchOpertor对象执行分支单选命令。BranchOperator对象指定的方法,其返回值可用于指定对分支的选择,而task_id用于标识分支的名字。参考如下案例。- dag = DAG(
- dag_id='pattern_exclusive_choice',
- default_args={
- 'start_date': utils.dates.days_ago(1),
- },
- schedule_interval=None,
- )
- with dag:
- def route_task():
- execution_date = context['execution_date']
- return 'convert_to_parquet'if execution_date.minute % 2 == 0 else 'convert_to_avro'
- read_input = DummyOperator(task_id='read_input')
- aggregate_data = DummyOperator(task_id='generate_data')
- route_to_format = BranchPythonOperator(task_id='route_to_format', python_callable=route_task)
- convert_to_parquet = DummyOperator(task_id='convert_to_parquet')
- convert_to_avro = DummyOperator(task_id='convert_to_avro')
- read_input >> aggregate_data >> route_to_format >> [convert_to_parquet, convert_to_avro]
Reference
1 ETL data patterns with Apache Airflow, waitingforcode, by BARTOSZ KONIECZNY
-
相关阅读:
剑指offer(C++)-JZ67:把字符串转换成整数atoi(算法-模拟)
1151 LCA in a Binary Tree
基于SSH的周报管理系统
猿创征文 | 使用Jquery封装的AJAX请求数据
【C++深入浅出】日期类的实现
Camtasia2024免费版mac电脑录屏软件
Taurus.MVC 微服务框架 入门开发教程:项目集成:2、客户端:ASP.NET Core(C#)项目集成:应用中心。
【PAT甲级 - C++题解】1062 Talent and Virtue
想要写出好的测试用例,先要学会测试设计
redis问题归纳
- 原文地址:https://blog.csdn.net/weixin_45892228/article/details/128066550
