斐波那契散列和hashMap实践#
适合的场景:抽奖(游戏、轮盘、活动促销等等)
如果有不对的地方,欢迎指正!
HashMap实现数据散列:#
配置项目,引入pom.xml:
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.58version>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
<version>3.8version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>cn.hutoolgroupId>
<artifactId>hutool-allartifactId>
<version>5.8.5version>
dependency>
前置条件:
- 存放数组:128位
- 100个数据进行散列
- 若有hash冲突,使用拉链法
首先,初始化100个随机数,这里采用雪花算法snowFlake,采用灵活注解引用,声明为Component,
简单了解下SnowFlake工具类实现方式:
import com.example.containstest.containsTestDemo.mapper.FileNameAndType;
import com.example.containstest.containsTestDemo.mapper.FileNameInsertMapper;
import com.example.containstest.containsTestDemo.pojo.DatagenertionDao;
import com.example.containstest.containsTestDemo.pojo.FileNameType;
import com.example.containstest.containsTestDemo.utils.SnowFlake;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
@Component
public class SnowFlake implements IIdGenerator {
private Snowflake snowflake;
@PostConstruct
public void init(){
// 0 ~ 31 位,可以采用配置的方式使用
long workerId;
try {
workerId = NetUtil.ipv4ToLong(NetUtil.getLocalhostStr());
}catch (Exception e){
workerId = NetUtil.getLocalhostStr().hashCode();
}
workerId = workerId >> 16 & 31;
long dataCenterId = 1L;
snowflake = IdUtil.createSnowflake(workerId,dataCenterId);
}
@Override
public long nextId() {
return snowflake.nextId();
}
}
循环100,取其随机数保存列表中:
List list = new ArrayList<>();
//保存idx和重复的值
Map map = new HashMap<>();
for(int i = 0; i < 101; i++){
list.add(String.valueOf(snowFlake.nextId()));
}
创建数据散列到的数组大小,这里取128
//定义要存放的数组 模拟初始化为128
String[] res = new String[128];
遍历保存的数组,计算出当前数值的hash值,然后到数组对应的下标处对应;
- 为空。当前
key赋值到该数组下标值 - 不为空,表示
hash冲突,这里采用字符串拼接模拟碰撞后使用的拉链法 map存储对应idx和key值- 对重复的散列的值进行排序输出
for(String key : list){
//计算hash值,未使用扰动函数
int idx = key.hashCode() & (res.length - 1);
log.info("key的值{},idx的值{}",key,idx);
if(null == res[idx]){
res[idx] = key;
continue;
}
res[idx] = res[idx] +"->" + key;
map.put(idx,res[idx]);
}
//排序
mapSort(map);
map排序:
private void mapSort(Map map) {
// 按照Map的键进行排序
Map sortedMap = map.entrySet().stream()
.sorted(Map.Entry.comparingByKey())
.collect(
Collectors.toMap(
Map.Entry::getKey,
Map.Entry::getValue,
(oldVal, newVal) -> oldVal,
LinkedHashMap::new
)
);
log.info("====>HashMap散列算法碰撞数据:{}",JSON.toJSONString(sortedMap));
}
未使用扰动函数HashMap散列输出结果展示:
{
28: "1596415617815183397->1596415617815183430",
29: "1596415617815183398->1596415617815183431",
30: "1596415617815183399->1596415617815183432",
59: "1596415617815183363->1596415617815183440",
60: "1596415617815183364->1596415617815183441",
61: "1596415617815183365->1596415617815183442",
62: "1596415617815183366->1596415617815183443",
63: "1596415617815183367->1596415617815183400->1596415617815183444",
64: "1596415617815183368->1596415617815183401->1596415617815183445",
65: "1596415617815183369->1596415617815183402->1596415617815183446",
66: "1596415617815183403->1596415617815183447",
67: "1596415617815183404->1596415617815183448",
68: "1596415617815183405->1596415617815183449",
90: "1596415617815183373->1596415617815183450",
91: "1596415617815183374->1596415617815183451",
92: "1596415617815183375->1596415617815183452",
93: "1596415617815183376->1596415617815183453",
94: "1596415617815183377->1596415617815183410->1596415617815183454",
95: "1596415617815183378->1596415617815183411->1596415617815183455",
96: "1596415617815183379->1596415617815183412->1596415617815183456",
97: "1596415617815183413->1596415617815183457",
98: "1596415617815183414->1596415617815183458",
99: "1596415617815183415->1596415617815183459",
121: "1596415617815183383->1596415617815183460",
125: "1596415617815183387->1596415617815183420",
126: "1596415617815183388->1596415617815183421",
127: "1596415617815183389->1596415617815183422"
}
针对上述代码,修改int idx = key.hashCode() & (res.length - 1);为下面:
int idx = (res.length - 1) & (key.hashCode() ^ (key.hashCode() >>> 16));
使用扰动函数HashMap散列输出结果展示:
{
44: "1596518378456121344->1596518378456121388",
67: "1596518378460315650->1596518378460315694",
72: "1596518378456121351->1596518378456121395",
73: "1596518378456121350->1596518378456121394",
83: "1596518378456121345->1596518378456121389",
92: "1596518378460315651->1596518378460315695",
93: "1596518378460315652->1596518378460315696"
}
从对比结果可以看到,加入扰动函数后hash碰撞减少了很多。
斐波那契散列算法#
前置条件:
- 生成模拟数据:随机且不重复的100个数
- 声明散列数组:大小128
- 若有hash冲突,保存map,方便数据查看
静态变量声明:
//黄金分割点
private static final int HASH_INCREMENT = 0x61c88647;
private static int range = 100;
按照惯例,初始化数组,模拟数据;
List listThreadLocal = new ArrayList<>();
Map map = new HashMap<>();
//定义要存放的数组 模拟初始化为128
Integer[] result = new Integer[128];
result = getNumber(range);
//......
//-----方法
/**
* 随机生成100以内不重复的数
* @param total
* @return
*/
public static Integer[] getNumber(int total){
Integer[] NumberBox = new Integer[total]; //容器A
Integer[] rtnNumber = new Integer[total]; //容器B
for (int i = 0; i < total; i++){
NumberBox[i] = i; //先把N个数放入容器A中
}
Integer end = total - 1;
for (int j = 0; j < total; j++){
int num = new Random().nextInt(end + 1); //取随机数
rtnNumber[j] = NumberBox[num]; //把随机数放入容器B
NumberBox[num] = NumberBox[end]; //把容器A中最后一个数覆盖所取的随机数
end--; //缩小随机数所取范围
}
return rtnNumber; //返回int型数组
}
遍历模拟的数据,通过源码阅读,可以找到new ThreadLocal
注意点,threadLocal实现主要是在ThreadLoacalMap中
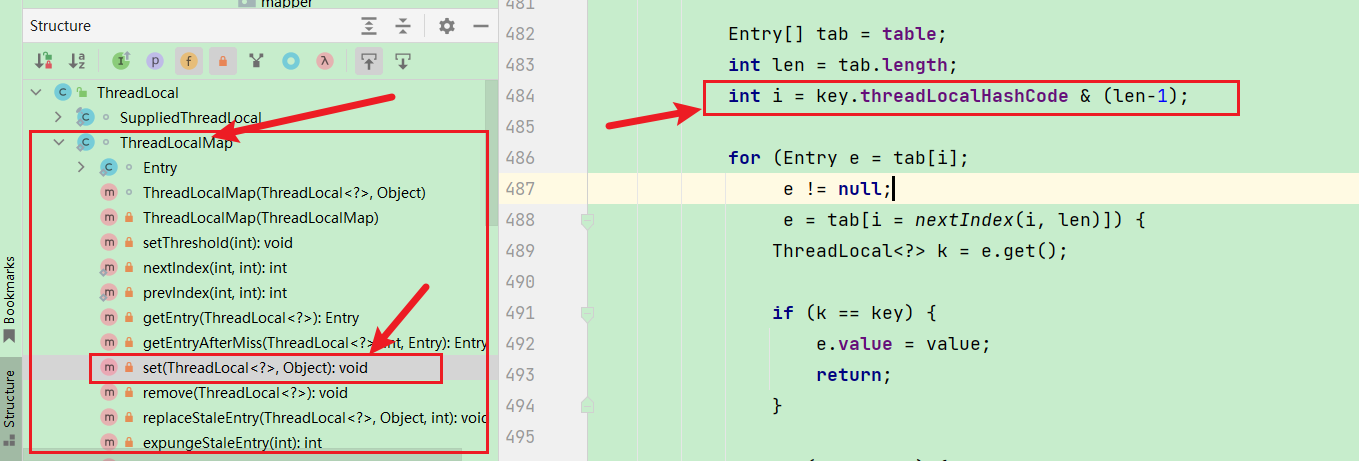
//2
private final int threadLocalHashCode = nextHashCode();
//4 默认值0
private static AtomicInteger nextHashCode = new AtomicInteger();
//3步骤使用
private static final int HASH_INCREMENT = 0x61c88647;
//3
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
//key和len是外部传入 1
int i = key.threadLocalHashCode & (len-1);
可以看到每次计算哈希值的时候,都会加一次HASH_INCREMENT黄金分割点,来更好的散列数据,然后模拟该操作:代码如下
for(int i = 0; i < listThreadLocal.size(); i++){
hashCode = listThreadLocal.get(i) * HASH_INCREMENT + HASH_INCREMENT;
Integer idx = (hashCode & 127);
log.info("key的值{},idx的值{}",listThreadLocal.get(i),idx);
if(null == result[idx]){
result[idx] = listThreadLocal.get(i);
continue;
}
String idxInRes = map.get(idx);
String idxInRess = idxInRes + "->" + listThreadLocal.get(i);
map.put(idx,idxInRess);
}
进行冲突后重复值排序
//map排序
if(CollectionUtil.isEmpty(map)){
log.info("斐波那契额散列数据集:{}",JSON.toJSONString(result));
System.out.println("===》无重复数据,不需要排序");
return;
}
mapSort(map);
使用斐波那契散列算法输出结果展示:
斐波那契额散列数据集:38,15,29,22,55,86,70,64,47,32,67,7,60,85,97,95,58,46,14,83,12,72,18,96,36,20,76,59,6,33,50,30,23,42,81,31,66,71,82,61,53,84,41,45,74,63,89,77,90,16,8,37,1,62,65,99,51,78,91,39,5,57,27,56,44,13,92,25,0,24,80,3,94,26,40,34,73,35,88,2,87,11,93,54,69,68,10,17,43,48,19,9,79,21,98,52,4,28,75,49]
===》无重复数据,不需要排序
由上我们可以看到,没有重复的数据,全部比较完美的散列到不同的地方。
参考文章:#
https://blog.csdn.net/qq_26327971/article/details/104757316