-
递归和排序算法的应用
一、递归常见问题和注意事项
1. 堆栈溢出;
2. 警惕重复运算:
可以使用一个数据结构(散列表)将已经计算过的f(k)保存起来,每当调用到f(k)时,先产看下是否已经求结果,从而避免重复计算。
3. 将递归代码修改为非递归代码二、冒泡、插入、选择排序
时间复杂度都是O(n^2);
**稳定性:**原序列中相同值得元素,经过排序后前后顺序不变;
**原地排序:**空间复杂度O(1);冒泡排序:每次便利剩余的全部找出剩余最小的值;
插入排序:前面是有序的,从后面序列拿出最前面的元素插入到前面有序队列中合适的位置。分为已排序空间和未排序空间;
选择排序:分为已排序空间和未排序空间,从未排序空间找出最小值放入已排序空间的末尾;插入排序相对于冒泡排序的优势?
冒泡排序中数据的交换操作: if (a[j] > a[j+1]) { // 交换 int tmp = a[j]; a[j] = a[j+1]; a[j+1] = tmp; flag = true; } 插入排序中数据的移动操作: if (a[j] > value) { a[j+1] = a[j]; // 数据移动 } else { break; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
使用冒泡排序需要K次交换操作,每次交换需要3次赋值语句,所需时间为3*k,而插入排序只需要K个时间。
三、归并排序和快速排序
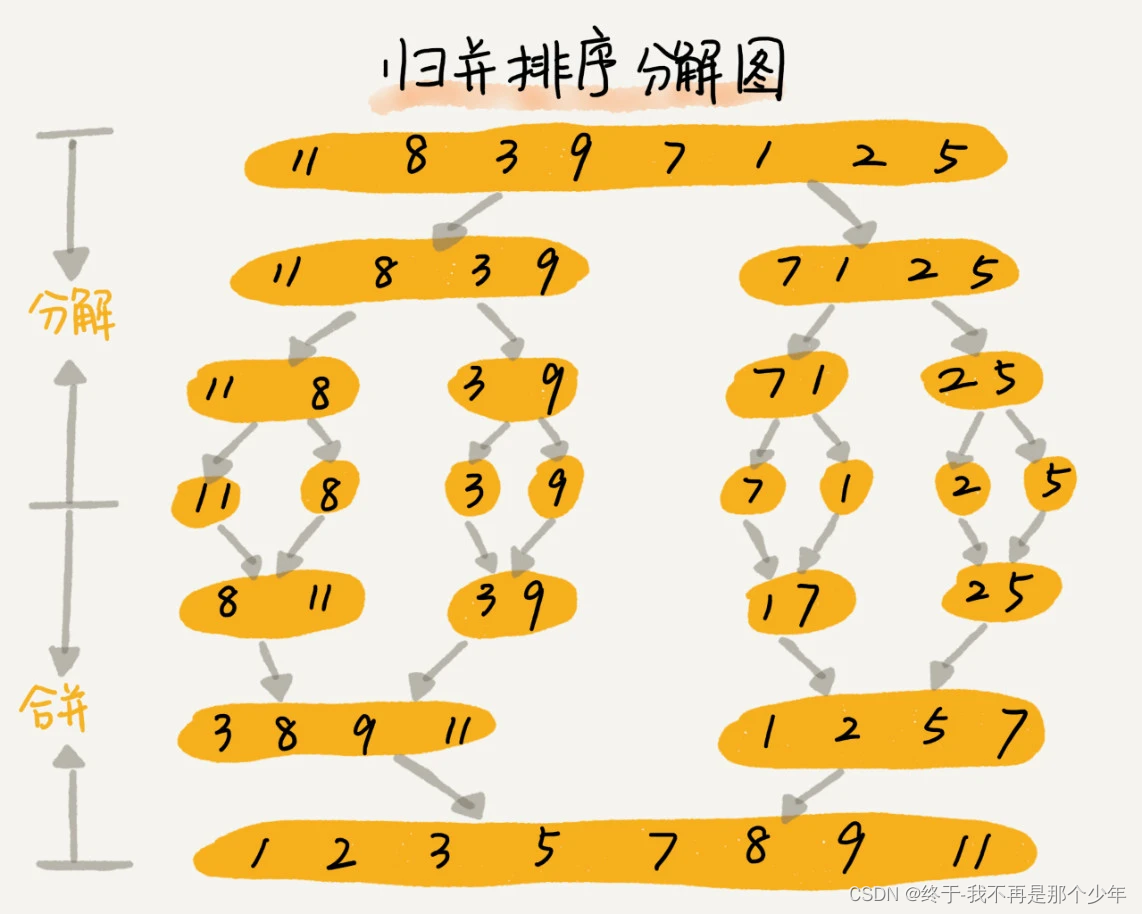
归并排序:先分解,再合并。将数组采用递归的思想从中间分解拆分,知道不能拆分,然后再将拆分的进行排序后合并,使用分治思想。
归并排序可以使稳定排序
// 归并排序算法, A是数组,n表示数组大小 merge_sort(A, n) { merge_sort_c(A, 0, n-1) } // 递归调用函数 merge_sort_c(A, p, r) { // 递归终止条件 if p >= r then return // 取p到r之间的中间位置q q = (p+r) / 2 // 分治递归 merge_sort_c(A, p, q) merge_sort_c(A, q+1, r) // 将A[p...q]和A[q+1...r]合并为A[p...r] merge(A[p...r], A[p...q], A[q+1...r]) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
merge()函数伪代码,merge()函数可以借用哨兵编程简化。
merge(A[p...r], A[p...q], A[q+1...r]) { var i := p,j := q+1,k := 0 // 初始化变量i, j, k var tmp := new array[0...r-p] // 申请一个大小跟A[p...r]一样的临时数组 while i<=q AND j<=r do { if A[i] <= A[j] { tmp[k++] = A[i++] // i++等于i:=i+1 } else { tmp[k++] = A[j++] } } // 判断哪个子数组中有剩余的数据 var start := i,end := q if j<=r then start := j, end:=r // 将剩余的数据拷贝到临时数组tmp while start <= end do { tmp[k++] = A[start++] } // 将tmp中的数组拷贝回A[p...r] for i:=0 to r-p do { A[p+i] = tmp[i] } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
在merge()合并函数需要临时空间,所以空间复杂度为O(n)。
快速排序:
快速排序是由上到下处理问题,利用原地分区,所以空间复杂度是O(1),不是稳定的排序算法。快速排序重点是选择合适的pivot,否可有可能导致时间复杂度退化到O(n^2)

// 快速排序,A是数组,n表示数组的大小 quick_sort(A, n) { quick_sort_c(A, 0, n-1) } // 快速排序递归函数,p,r为下标 quick_sort_c(A, p, r) { if p >= r then return q = partition(A, p, r) // 获取分区点 quick_sort_c(A, p, q-1) quick_sort_c(A, q+1, r) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
partition()分区函数函数
partition(A, p, r) { pivot := A[r] i := p for j := p to r-1 do { if A[j] < pivot { swap A[i] with A[j] i := i+1 } } swap A[i] with A[r] return i- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
四、排序的思考问题
1、现在有 10 个接口访问日志文件,每个日志文件大小约 300MB,每个文件里的日志都是按照时间戳从小到大排序的。希望将这 10 个较小的日志文件,合并为 1 个日志文件,合并之后的日志仍然按照时间戳从小到大排列。如果处理上述排序任务的机器内存只有 1GB,有什么好的解决思路,能“快速”地将这 10 个日志文件合并吗?
最大时间戳的最小值这一点很关键 保证了当前取出来的数据是未排序种全局最小的。
批量读取文件。
分阶段的快速排序。先取得十个文件时间戳的最小值数组的最小值a,和最大值数组的最大值b。然后取mid=(a+b)/2,然后把每个文件按照mid分割,取所有前面部分之和,如果小于1g就可以读入内存快排生成中间文件,否则继续取时间戳的中间值分割文件,直到区间内文件之和小于1g。同理对所有区间都做同样处理。最终把生成的中间文件按照分割的时间区间的次序直接连起来即可。类似桶排序。
2、如何在O(n)时间复杂内查找无序数组第K大的元素?
利用快速排序的思想,数组下标和K进行比较。3、如何根据年龄对100万用户进行排序?
利用桶排序。五、空间复杂度为O(n)排序,桶排序、计数排序、基数排序
1、桶排序(Bucket sort)

适用于在外部排序,数据存储在磁盘中,数据量比较大,内存有限,无法将全部数据加载到内存进行排序。
重点是如何将数据均匀的划分到每个桶里面。2、计数排序(Counting sort)
桶排序的特殊情况,当数据的范围较小时,例如高考成绩排序,有一组数据2,5,3,0,2,3,0,3,使用大小为6的桶C[6]:


3、基数排序(radix sort)
例如对十万个电话号码进行排序,借助与稳定的排序,从高位向低位开始进行排序,排序11次即可。但是有时候要排序的数据长度不是等长的,可以对位数不够的在后面补0。
基数排序对要排序的数据是有要求的,需要可以分割出独立的“位”来比较,且位之间有递进的关系,如果数据a的高位比数据b高位大,那剩下的就不用比较了。六、如何实现一个通用、高效的排序算法?
快速排序如何优化:主要是找到合适的分区点,为了避免极端情况,可以采用三数取中,随机法
七、二分法
如何快速的定位出IP对应的省份地址?
如果IP和归属地的关系不经常更新,可以先按照IP大小关系进行排序,查找时根据二分法进行查找。有重复值的有序序列中查找一地个大于某值的元素?
-
相关阅读:
UniCode 常用字符大全
kubernetes资源对象概述
多节点树的层序遍历
java数据结构与算法刷题-----LeetCode28:实现 strStr()
SSM+Vue+Element-UI实现教资考前指导系统
Git目录不对,即当前文件夹不对应git仓库
【Unity】实现轮盘抽奖
ES小版本整理
数据安全治理:构建与实施的关键要素及总体架构
开源视频监控服务器Shinobi
- 原文地址:https://blog.csdn.net/peng_shakalaka/article/details/127856414
