-
数仓搭建-ODS层
数仓搭建-ODS层
1)保持数据原貌不做任何修改,起到备份数据的作用。
2)数据采用LZO压缩,减少磁盘存储空间。100G数据可以压缩到10G以内。
3)创建分区表,防止后续的全表扫描,在企业开发中大量使用分区表。
4)创建外部表。在企业开发中,除了自己用的临时表,创建内部表外,绝大多数场景都是创建外部表。ODS层(用户行为数据)
创建日志表ods_log
1)创建支持lzo压缩的分区表
在hive中创建ods分区表,数据的压缩采用lzo
(1)建表语句
hive (gmall)> drop table if exists ods_log; CREATE EXTERNAL TABLE ods_log (`line` string) PARTITIONED BY (`dt` string) -- 按照时间创建分区 STORED AS -- 指定存储方式,读数据采用LzoTextInputFormat; INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION '/warehouse/gmall/ods/ods_log' -- 指定数据在hdfs上的存储位置 ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
(2)分区规划

2)加载数据
将hdfs上对应日期的数据导入到hive表中
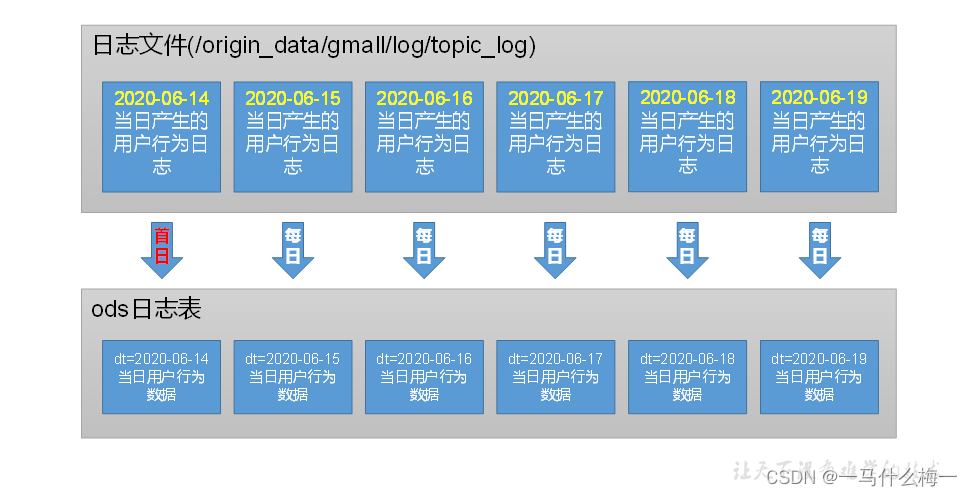
hive (gmall)> load data inpath '/origin_data/gmall/log/topic_log/2022-06-14' into table ods_log partition(dt='2022-06-14');- 1
- 2
3)为lzo压缩文件创建索引
[atguigu@hadoop102 bin]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /warehouse/gmall/ods/ods_log/dt=2022-06-10- 1
ODS层日志表加载数据脚本
1)编写脚本
(1)在hadoop102的/home/atguigu/bin目录下创建脚本
[atguigu@hadoop102 bin]$ vim hdfs_to_ods_log.sh- 1
在脚本中编写如下内容
#!/bin/bash # 定义变量方便修改 APP=gmall # 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天 if [ -n "$1" ] ;then do_date=$1 else do_date=`date -d "-1 day" +%F` fi echo ================== 日志日期为 $do_date ================== sql=" use gmall; load data inpath '/origin_data/$APP/log/topic_log/$do_date' into table ${APP}.ods_log partition(dt='$do_date'); " hive -e "$sql" #创建索引文件 hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /warehouse/$APP/ods/ods_log/dt=$do_date- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
(1)说明1:
[ -n 变量值 ] 判断变量的值,是否为空
– 变量的值,非空,返回true
– 变量的值,为空,返回false
注意:[ -n 变量值 ]不会解析数据,使用[ -n 变量值 ]时,需要对变量加上双引号(" ")
(2)说明2:
查看date命令的使用,date --help
(2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod 777 hdfs_to_ods_log.sh- 1
2)脚本使用
(1)执行脚本
[atguigu@hadoop102 module]$ hdfs_to_ods_log.sh 2020-06-14- 1
(2)查看导入数据
ODS层(业务数据)
ODS层业务表分区规划如下,以其中两张为例

ODS层(用户行为数据)
1)活动信息表
DROP TABLE IF EXISTS ods_activity_info; CREATE EXTERNAL TABLE ods_activity_info( `id` STRING COMMENT '编号', `activity_name` STRING COMMENT '活动名称', `activity_type` STRING COMMENT '活动类型', `start_time` STRING COMMENT '开始时间', `end_time` STRING COMMENT '结束时间', `create_time` STRING COMMENT '创建时间' ) COMMENT '活动信息表' PARTITIONED BY (`dt` STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION '/warehouse/gmall/ods/ods_activity_info/';- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2)省份表
省份地区表比较特殊,一般情况下只需要同步一次,所以不需要分区
DROP TABLE IF EXISTS ods_base_province; CREATE EXTERNAL TABLE ods_base_province ( `id` STRING COMMENT '编号', `name` STRING COMMENT '省份名称', `region_id` STRING COMMENT '地区ID', `area_code` STRING COMMENT '地区编码', `iso_code` STRING COMMENT 'ISO-3166编码,供可视化使用', `iso_3166_2` STRING COMMENT 'IOS-3166-2编码,供可视化使用' ) COMMENT '省份表' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION '/warehouse/gmall/ods/ods_base_province/';- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
ODS层业务表首日数据装载脚本
首日脚本与每日脚本最大的区别就是地区省份表只需要首日加载,每日脚本无需加载
1)编写脚本
(1)在/home/atguigu/bin目录下创建脚本hdfs_to_ods_db_init.sh
[atguigu@hadoop102 bin]$ vim hdfs_to_ods_db_init.sh- 1
在脚本中填写如下内容
#!/bin/bash APP=gmall if [ -n "$2" ] ;then do_date=$2 else echo "请传入日期参数" exit fi ods_order_info=" load data inpath '/origin_data/$APP/db/order_info/$do_date' OVERWRITE into table ${APP}.ods_order_info partition(dt='$do_date');" ods_order_detail=" load data inpath '/origin_data/$APP/db/order_detail/$do_date' OVERWRITE into table ${APP}.ods_order_detail partition(dt='$do_date');" case $1 in "ods_order_info"){ hive -e "$ods_order_info" };; "ods_order_detail"){ hive -e "$ods_order_detail" };; "all"){ hive -e "$ods_order_info$ods_order_detail" };; esac- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
(2)增加执行权限
[atguigu@hadoop102 bin]$ chmod +x hdfs_to_ods_db_init.sh- 1
2)脚本使用
(1)执行脚本
[atguigu@hadoop102 bin]$ hdfs_to_ods_db_init.sh all 2020-06-14- 1
(2)查看数据是否导入成功
ODS层业务表每日数据装载脚本
地区表与省份表每日装载脚本不需要添加,因为首日加载脚本已经添加
1)编写脚本
(1)在/home/atguigu/bin目录下创建脚本hdfs_to_ods_db.sh
[atguigu@hadoop102 bin]$ vim hdfs_to_ods_db.sh- 1
在脚本中填写如下内容
#!/bin/bash APP=gmall # 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天 if [ -n "$2" ] ;then do_date=$2 else do_date=`date -d "-1 day" +%F` fi ods_order_info=" load data inpath '/origin_data/$APP/db/order_info/$do_date' OVERWRITE into table ${APP}.ods_order_info partition(dt='$do_date');" ods_order_detail=" load data inpath '/origin_data/$APP/db/order_detail/$do_date' OVERWRITE into table ${APP}.ods_order_detail partition(dt='$do_date');" case $1 in "ods_order_info"){ hive -e "$ods_order_info" };; "ods_order_detail"){ hive -e "$ods_order_detail" };; "all"){ hive -e "$ods_order_info$ods_order_detail" };; esac- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
(2)修改权限
[atguigu@hadoop102 bin]$ chmod +x hdfs_to_ods_db.sh- 1
2)脚本使用
(1)执行脚本
[atguigu@hadoop102 bin]$ hdfs_to_ods_db.sh all 2020-06-14- 1
(2)查看数据是否导入成功
-
相关阅读:
怎样做好金融投资翻译
NodeJs的安装与配置(安装包)
ETL实现实时文件监听
LDA代码训练报错记录
游戏中的随机——“动态平衡概率”算法
【SA8295P 源码分析】130 - GMSL2 协议分析 之 I2C/UART 双向控制通道原理分析
Jenkins从配置到实践(2022尚硅谷Jenkins学习笔记)
宗老师团队国家工程-园区GIS应用
【Docker】华为云服务器安装 Docker 容器
工作心得总结
- 原文地址:https://blog.csdn.net/weixin_44616592/article/details/128043273