-
C++:STL::String模拟实现
前言:
浅拷贝和深拷贝
实现string需要知道深浅拷贝问题。观察如下自命名空间中实现的string,不自写string的string类型参数的构造函数,编译器会默认生成,做浅拷贝。对于自定义类型使用自定义类型的构造函数,如果是默认类型,会做浅拷贝。这里创建s2用string s1来构造,string自定义类型,但是没有默认构造函数,系统自动生成,内部的_str指针类型,会做浅拷贝或叫值拷贝,把s1的_str地址给s2的_str,最后s1是临时变量,空间被释放后,因为s2中_str指向同一片空间,连续两次析构函数使用:delete [],同一片空间用两次,造成如下错误。
#pragma once #include#include // 想定义一个和库中一样名字的类 // 定义命名空间做隔离 防止冲突 namespace bit { class string { public: // :_str(str):这样是浅拷贝,把str的值给了_str,str右值是字符串常量,str值是地址,str是指针 // str值在常量区,不是在堆上,扩容不方便。 用所以建议用new做深拷贝。这样方便扩容。 // 以下这种方式只是拷贝值 string(const char* str) :_str(new char[strlen(str)+1]) { strcpy(_str, str); } ~string() { delete[] _str; _str = nullptr; } private: char* _str; }; void test_string1() { string s1("hello world"); // 如果是以下的方式,使用系统默认的构造函数做浅拷贝,s2的_str值会和s1的_str相等 // s1是临时变量,s2以s1为模板,s1的没了,s2的_str也没了。 // s2以s1为模板 s1是临时变量的栈空间会做释放,s2指向的内存栈空间也会释放, // 释放两次,肯定会报错。 // !!!程序报错是因为创建s2时,编译器调用默认的构造函数 s1后面释放了,s2的以s1作浅拷贝。 string s2(s1); } } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
错误如下

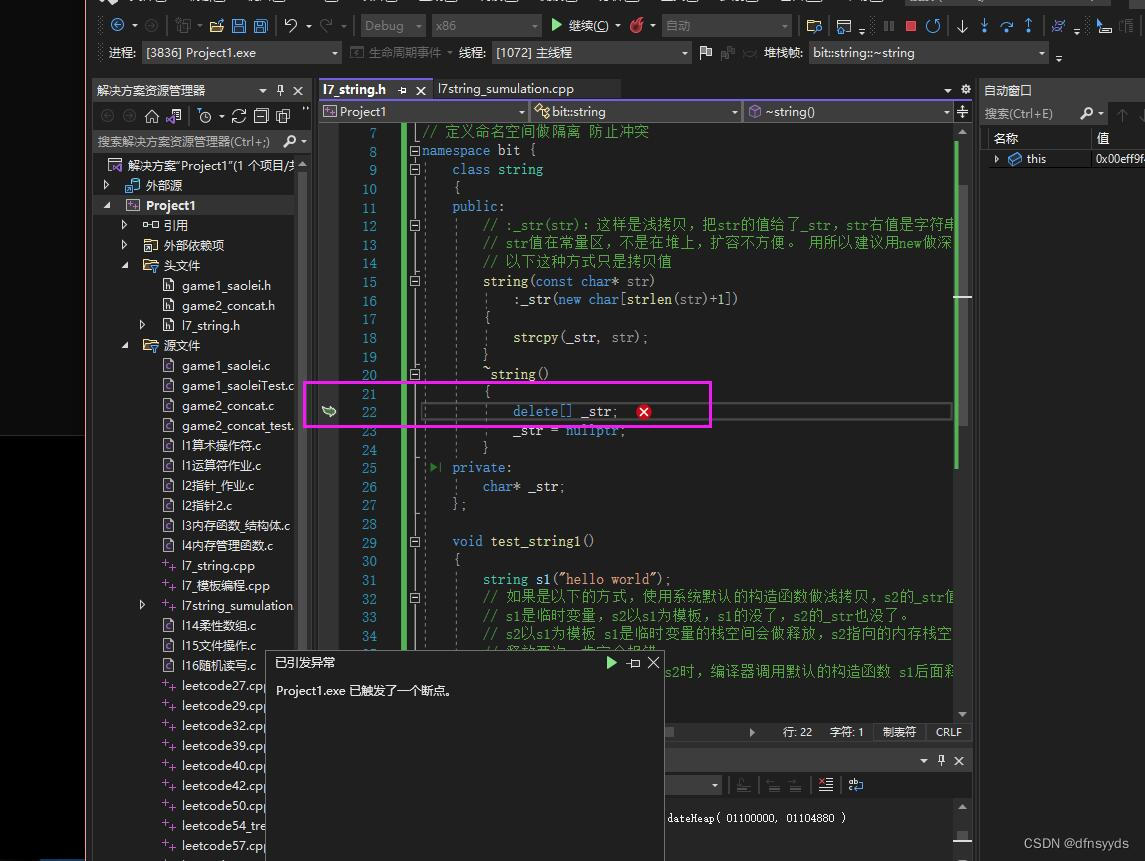
这个报错就是说明:delete出错,可能连续释放了。-
深拷贝:
先申请一片一样大的空间,再做复制。
这里string类使用Strcpy()做值复制。 -
string s3(s1) 和 string s3 (“aaa”); s3 = s1 的区别是什么?
-
对于赋值运算符=的重载注意点:引用做参数、比较是不是自己等知识点
-
Find_first(const string& str. size_t pos=0, size_t n):了解它常用的三个参
str:子串。
pos:查找的起始位置
n:找n个字符。不给就找到末尾。 -
str.c_str()
答:返回字符串,但是其实是得到指向内容的指针,所以直接比较两个string变量的c_str() ,==判断的是指针相等否,必然不等。如下第一个是F、此外,都做深拷贝,所以都是F。
关于代码输出正确的结果是( )(vs2013 环境下编译运行)
int main(int argc, char *argv[])
{
string a=“hello world”;
string b=a;
if (a.c_str()==b.c_str())
{
cout<<“true”<
}
else cout<<“false”<
string c=b;
c=“”;
if (a.c_str()==b.c_str())
{
cout<<“true”<
}
else cout<<“false”<
a=“”;
if (a.c_str()==b.c_str())
{
cout<<“true”<
}
else cout<<“false”<
return 0;
}
- resize()和reserve()
resize()调整的是size(),其中的字符数量,reserve()是扩大容量。resize()允许size变小,但是reserve(n)中n< capacity(),在变小了,就不起作用。
下面程序的输出结果正确的是( )
int main()
{
string str(“Hello Bit.”);
str.reserve(111);
str.resize(5);
str.reserve(50);
cout<
return 0;
}string模拟实现
数据成员
- string是连续的字符串,所以底层一般指针指向连续的一片空间。使用char* _str。
- 还要字符串长度、字符串容量,此外还看到了npos,这是个标志位,默认值-1,标记寻找不到或到末尾。
- npos是静态成员变量,需要在类外部设置。
class string { private: char* _str; size_t _size; size_t _capacity; static size_t npos; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
构造函数和析构函数
普通构造函数一有两种,无参和有参。但我们常用有参的,但是如果要写有参,编译器就不会实现无参,这样如果不初始化只申请会出错。
string(const char* str = “” ):
1.构造函数设置为缺省参数,不传入参数,则构造""空字符串,不然你只写const char* str,不写别的,编译器发现你有构造函数,就不会自己生成。不然 string s; 不能通过,因为这是无参的。定义 string s;不做初始化,就会报错。此外:需要设置:capacity、size、str。 能用构造参数列表尽量用 效率高,但是初始化列表中的顺便按private顺序。
2. 申请空间,其实多申请一个,比如我要构造长度为n的字符串,其实我new char[n+1],因为n+1个位置要放‘\0’。关于拷贝构造,常有现代写法和普通写法,现代写法和普通写法的区别是现代写法更加简介,通过调用工具函数(自己实现的swap交换拷贝构造得到的临时对象的string的成员指针免去自己写大量重复代码)。
关于析构,我们注意有非默认类型(默认类型是:int、double等那些)如指针或包含了指针的类对象成员需要自己实现析构函数,编译器生成的不行。析构需要delete[]释放连续空间。
迭代器
本质其实是typedef char*。一般有普通迭代器和反向迭代器。因为不能只因为返回值构成重载,所以我们再typedefconst char* const迭代器。此外,()const是对this加const,根本上保证了成员变量权限缩小。
扩容
插入时需要判断容量是否满。
- 注意reserve()和resize()前面只开辟空间而不做初始化,resize()做初始化,且n小于当前时,只改变size而不变capacity。
增删改查
- append():只实现插入一个长串即可,它底层用insert()可实现。插入单个字符通过push_back()即可。
- push_back():用insert()插入末尾即可。
- insert():挪动旧的,还要判断位置是否合法。
工具函数
swap:自己内部交换掉所有成员变量。
重载
实现两个就可以实现一个,比如>,底层用了字符串的strcmp函数做比较。
重载出两个就可以根据这两个去简写其它了。
重载:[],我们需要返回引用类型,所以用string&接收。使用到的C语言函数:
重载比较、构造函数中等地方,多用strlen()计算参数长度,用strcpy()拷贝两个字符串,strcat()不建议使用,内部会一直查找到末尾,效率非常低。strcmp()比较两个字符串以字典序。
遇到的错误
- 类外写重载报错了:原因是除了返回值地方要加string::,在operator前面也要加string::。

重载发现已经声明,找了半天发现:一个加个const,类外一个没有加

原始模拟全部代码
#define _CRT_SECURE_NO_WARNINGS #include#include using namespace std; /* 补:流重载的知识: string: 1。 string的默认成员函数: private 私有成员: char* str : string的底层一定是指向字符串的指针,char*即可。 size_t _size :有效长度 size_t _capacity:容量 static const size_t npos; :查找结果的返回,常设置为-1,默认表示找不到 静态成员变量,需要在类外部设置 public 公有成员: 构造函数: string str = "abc"; 需要实现:string(const char* str = "" ) 这样的话,免去了写无参 string s = str; 需要实现拷贝构造: string(const string& s); string s(str); 需要实现拷贝构造 同上 string& operator=(const string& s) ~string() 1.1 string(const char* str = "" ): : 构造函数设置为缺省参数,不传入参数,则构造""空字符串,不然你只写const char* str,不写别的,编译器发现你有构造函数,就不会自己生成, 此外 string s; 不能通过,因为这是无参的。 定义 string s;不做初始化,就会报错。 此外:需要设置:capacity、size、str。 能用构造参数列表尽量用 效率高 分析: 1. size:看你传入的str长度:用strlen(),C语言的接口 2. 初始容量和 _size相等,为了节省空间 3. strcpy:拷贝:给前面拷贝后面,最后一个位置会给'\0' 4. char* str要多一个空间,因为最后存'\0' 但 '\0'不计入sizes 直接new char【】 5. 构造参数列表:能用多用,效率高。初始化变量在构造参数列表里面用,而使用函数比如做赋值等在函数体里面。 遇到的错误: 1. 类内声明 外定义 缺省值 const char* str = "" 必须删一个,建议删下面,但其实上下删哪个都行 2. 初始化参数列表里的执行顺序是按你的private来写,所以_str(new char[capacity+1])时,是错的,建议用函数体 就不会考虑 注意: !!可以调用同类型对象的私有成员。 1.2 析构: 分析: 释放申请的连续空间 变量置0 delete[] 这里数组是连续空间,用delete[]释放 _str 置null _size、_capacity置0 1.3 拷贝构造函数 传统写法分析: s._str,怎么可以的 在类内部就可以 现代写法分析: 利用swap()交换两个对象内部的全部成员。所以下面需要实现swap() 错误点: 1. 当:s1 = s1 自己给自己赋值,就防止出麻烦,避免掉因为释放掉自己,也相当于释放掉参数的内容了 判断用的地址比较: this != &s 注意: 这里无非是考虑深浅拷贝问题,最简单判定方法就是看看是否成功析构 1.4 access [] : 要开放对它内容修改,所以用& const operator[](size_t pss)const: !!! :必须加()后const,加上const变了参数类型,不加只是变返回值类型不能构成重载 1.51 迭代器:本质是字符串指针,所以现在public中做typedef 类型必须公有,因为外面需要调用 begin(): 类型是迭代器,其实就是个指针 返回_str即可 是首地址 end(): 1.52 const迭代器: 分析: 重命名类型 所以就返回str 或 str 的加法即可 ()后面加const 否则只是类型不同不能构成重载,()后面加const改变的是this指针,相当于变了参数 1.6 重载 = : 类型:我们肯定要得到一个一直要存在的值,所以函数返回类型必须是&。 传统写法: 释放原来指针指向连续空间 _str = new char[] 申请新的 capacity+1 strcpy()拷贝内容 = :现代写法: 先释放原指针指的连续空间 再创建tmp 做交换 注意: 1. 还是得判断 this != &s 2. 返回类型是 string& 不需要再次拷贝构造 3. return *this 得在判断之外 1.7 容量 reserve:只改变容量capacity 不改变size 1.8 CRUD find:字符串我好像不会 resize:n小可以缩 不改变capacity 1.x 工具函数 swap():内部交换全部成员变量 必要性: 它和全局swap()不一样,全局的std::swap()可以针对任何类型 如果我直接用std::swap()做交换行不行,不行,它内部用模板类型 a = b,使得一直调用 重载= ,而我们重载=里面用的就是用的这个,就不断重复做, 而且每个里面都有string tmp创建临时对象,都开辟空间,这样最后就会栈溢出。 size():直接_size 注意 size_t类型和参数类型是const 2. 回忆在类外部定义成员函数,在一个命名空间内,只加类::即可 3. */ namespace lz { class string { public: typedef char* iterator; typedef const char* const_iterator; // 默认成员函数 string(const char* str =""); string(const string& s); ~string(); // 重载 = 传统写法 /*string& operator=(const string& s) { if (&s != this) { delete[] _str; _str = new char[s._capacity + 1]; _capacity = s._capacity; _size = s._size; strcpy(_str, s._str); } return *this; }*/ // 重载 = 现代写法 /*string& operator=(const string& s) { if (&s != this) { delete[] _str; string tmp(s); swap(tmp); } return *this; }*/ // 重载 = 现代写法之更简洁 string& operator=(string s) { swap(s); return *this; } iterator begin() { return _str; } iterator end() { return _str+_size; } const_iterator begin() const { return _str; } const_iterator end() const { return _str + _size; } // 访问 access char& operator[](size_t pos) { assert(pos < _size); return _str[pos]; } const char& operator[](size_t pos)const { assert(pos < _size); return _str[pos]; } // 容量: // 扩容:多申请一个空间 n+1,未来放 '\0' ,但是capacity = n ,容量不算\0 void reserve(size_t n) { if (n > _capacity) { char* tmp = new char[n + 1]; strcpy(tmp, _str); delete _str; _str = tmp; _capacity = n; } } // 开空间加初始化 void resize(size_t n, char ch = '\0') { if (n > _size) { // 插入数据 reserve(n); // 里面会判断 for (size_t i = _size; i < n; i++) { _str[i] = ch; } _str[n] = '\0'; _size = n; // resize后_size肯定变了 } else { // 删除数据 _str[n] = '\0'; // 因为从0开始 _size = n; } } // =======================CRUD // append要接字符串,所以不适合直接扩容2倍,可能太多了 // 计算插入串长度 //void append(const char* str) //{ // size_t len = strlen(str); // // 判容量够不够 // if (_size + len > _capacity) // reserve(_size+len); // 容量不够至少扩这么多 // strcpy(_str + _size, str); // C语言的函数可以直接用 +_size直接到末尾'\0'位置,这里可以直接拷贝过去 strcpy:拷贝到'\0' 包括'\0' // _size += len; // capacity不动,只有reverse才动 //} // 以insert实现 追加一串 void append(const char* str) { insert(_size, str); } // 重载的append 放n个一样的字符 多次pushback效率低,n很大,可能会扩容多次,所以直接reverse(n) void append(size_t n, char ch) // { reserve(_size + n); for (size_t i = 0; i < n; i++) { push_back(ch); } } /*void append(size_t n, char ch) { insert(_size, ch); }*/ // pos位置合法 满了就扩容:小心0问题,如果pos == 0 到insert0,会因为size_t无符号,0--,导致从0到int最大值,死循环 string& insert(size_t pos, char ch) { assert(pos <= _size); if (_size == _capacity) { reserve(_capacity == 0 ? 4 : 2 * _capacity); } for (size_t i = _size+1; i > pos; i--) { _str[i] = _str[i-1]; // 从_size+1开始,其实_size处是'\0',所以连 '\0'也拿走 } _str[pos] = ch; // 总之还是给pos位置 ++_size; return *this; } // 插入串,先挪动开旧的 string& insert(size_t pos, const char* str) { assert(pos <= _size); size_t len = strlen(str); if (_size + len > _capacity) { reserve(_size + len); // 实际扩容会比这个多一个 } size_t end = _size + len; // 现在在'\0'处 pos处后面的得挪动len个。且从_size开始的,'\0'也挪动了 while (end >= pos + len) // end 不会是0 ,不会发生0再到大的事 { _str[end] = _str[end-len]; end--; } strncpy(_str + pos, str, len); // len个长度 //strcpy(_str+pos, str); _size += len; return *this; } // 满了要扩容,且别忘'\0' /*void push_back(char ch) { if (_size == _capacity) { reserve(_capacity == 0?4: 2*_capacity ); } _str[_size] = ch; _str[_size + 1] = '\0'; ++_size; }*/ // push_back用insert实现 void push_back(char ch) { insert(_size, ch); } // erase:删除npos之后全部 void erase(size_t pos, size_t len = npos) { assert(pos < _size); if (len == npos || pos+len>=_size) // len == npos意思是len没有给值是默认就删完,或 该位置后删的长度多于pos后本有长度就删完 { _str[pos] = '\0'; _size = pos; } else // pos后删len个,就跳过len个,都挪前面来,包括了'\0' { strcpy(_str + pos, _str + pos+len); _size -= len; } } // ==================================重载 string& operator+=(char ch) { push_back(ch); return *this; } string& operator+=(const char* str) { append(str); return *this; } /*bool operator >(const string& s) { return strcmp(_str, s._str) > 0; }*/ bool operator >(const string& s)const; bool operator ==(const string& s) { return strcmp(_str, s._str) == 0; } bool operator >=(const string& s) { return *this > s || *this == s; } bool operator <(const string& s) { return !( * this >= s); } bool operator <=(const string& s) { return !(*this > s); } bool operator !=(const string& s) { return !(* this == s); } // 其余工具函数 void swap(string& s); // c_str 早期模拟实现流重载先用它测试输出 const char* c_str() const { return _str; } // clear() void clear(); size_t size() const { return _size; } size_t find(char ch, size_t pos = 0) const { for (size_t i = 0; i < _size; i++) { if (ch == _str[i]) { return i; } } return npos; } // 作差返回 pos size_t find(const char* sub, size_t pos = 0) const { // strstr返回的是地址 const char* ptr = strstr(_str + pos, sub); if (ptr == nullptr) { return npos; } else { return ptr - _str; } } // 取子串 string substr(size_t pos, size_t len = npos)const { assert(pos < _size); size_t realLen = len; // == _size:刚刚好,需要末'\0' 要不要等于 等于也是到末尾,但是不用加加上也没事 if (len == npos || pos+len > _size) { realLen = _size - pos; } string sub; // 全取上 for (size_t i = 0; i < realLen; i++) { sub += _str[pos + i]; } return sub; } private: char* _str; size_t _size; size_t _capacity; static size_t npos; }; size_t string::npos = -1; //================================================================================================================================================================= // 缺省普通构造 传统写法 /*string::string(const char* str) { _size = strlen(str); _capacity = _size; _str = new char[_capacity + 1]; strcpy(_str, str); }*/ // 缺省普通构造 现代写法 string::string(const char* str) :_size(strlen(str)) ,_capacity(_size) ,_str(new char[strlen(str)+1]) { strcpy(_str, str); } // 流重载 好像用问题,用'\0'会停止输出 ostream& operator<<(ostream& out, const string& s) { for (size_t i = 0; i < s.size(); i++) { out << s[i]; } return out; } // 如何提取:字符串默认以 string之间默认以'\n'间隔 搜 in.get() // 用 in.get(),发现不是 ' ' 和 '\n'即 istream& operator>>(istream& in, string& s) { //char ch; //in >> ch; // :in >> ch:拿不到空格和换行,字符串默认以 string之间默认以 '\n' 和 ' ' 间隔 //while (ch != ' ' && ch != '\0') //{ // s += ch; //} // 上述方法不行 s.clear(); // 你重复cin>>s,s会不断拼接。所以需要它 char ch; ch = in.get(); const size_t N = 32; char buff[N]; size_t i = 0; while (ch != ' ' &&ch != '\n') { buff[i++] = ch; if (i == N - 1) { buff[i] = '\0'; s += buff; i = 0; } ch = in.get(); } // 出来以后 buff中还有剩余 buff[i] = '\0'; s += buff; return in; } // 拷贝构造 传统写法:用错误 /*string::string(const string& s) :_str(new char[s._capacity+1]) , _size(s._size) , _capacity(s._capacity) { strcpy(_str, s._str); } */ // 现代写法: string::string(const string& s) :_str(nullptr) ,_size(0) ,_capacity(0) { lz::string tmp(s._str); swap(tmp); } // 赋值运算符重载 /*string::string& operator=(string& s); { return this; }*/ /*string::string& operator=(string s) { string::swap(s); return *this; }*/ //bool string::operator > (const string& s)const //{ // return false; /* bool string::operator == (const string& s) { } bool string::operator >= (const string& s) { } bool string::operator < (const string& s) { } bool string::operator <= (const string& s) { } bool string::operator !=(const string& s) { }*/ string::~string() { delete[] _str; _str = nullptr; _size = _capacity = 0; } // 工具 void string::swap(string& s) { std::swap(s._str, _str); std::swap(s._size, _size); std::swap(s._capacity, _capacity); } void string::clear() { _str[0] = '\0'; _size = 0; } } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
- 446
- 447
- 448
- 449
- 450
- 451
- 452
- 453
- 454
- 455
- 456
- 457
- 458
- 459
- 460
- 461
- 462
- 463
- 464
- 465
- 466
- 467
- 468
- 469
- 470
- 471
- 472
- 473
- 474
- 475
- 476
- 477
- 478
- 479
- 480
- 481
- 482
- 483
- 484
- 485
- 486
- 487
- 488
- 489
- 490
- 491
- 492
- 493
- 494
- 495
- 496
- 497
- 498
- 499
- 500
- 501
- 502
- 503
- 504
- 505
- 506
- 507
- 508
- 509
- 510
- 511
- 512
- 513
- 514
- 515
- 516
- 517
- 518
- 519
- 520
- 521
- 522
- 523
- 524
- 525
- 526
- 527
- 528
- 529
- 530
- 531
- 532
- 533
- 534
- 535
- 536
- 537
- 538
- 539
- 540
- 541
- 542
- 543
- 544
- 545
- 546
- 547
- 548
- 549
- 550
- 551
- 552
- 553
- 554
- 555
- 556
- 557
- 558
- 559
- 560
- 561
- 562
- 563
- 564
- 565
- 566
- 567
- 568
- 569
- 570
- 571
- 572
- 573
- 574
- 575
- 576
- 577
- 578
- 579
- 580
- 581
- 582
- 583
- 584
- 585
- 586
- 587
- 588
- 589
- 590
- 591
- 592
- 593
- 594
- 595
- 596
- 597
- 598
- 599
- 600
- 601
- 602
- 603
- 604
- 605
- 606
- 607
- 608
- 609
- 610
测试代码
#include "L1_string.h" void string1() { lz::string s1 = "come the way abc"; lz::string s2; //lz::string s2 = s1; cout << "临时测试s1能不能初始化成功,s2空字符串" << endl; cout << s1.c_str() << endl; cout << "s2.c_str() : " << s2.c_str() << endl; cout << "下面测试 []访问" << endl; for (size_t i = 0; i < s1.size(); i++) { cout << s1[i] << " "; } cout << endl; cout << "通过[] 修改" << endl; for (size_t i = 0; i < s1.size(); i++) { cout << ++s1[i]<< " "; } cout << endl <<"下面测试迭代器访问" << endl; lz::string::iterator it = s1.begin(); while (it != s1.end()) { cout << *it << " "; it++; } cout << endl << "测试范围for"<< endl; for (auto ch : s1) { cout << ch << " "; } cout << endl; } /* 如果没有拷贝构造,会崩溃,因为编译器默认生成的浅拷贝构造使得s2和s1指向一样, 最后会重复释放,但是对于日期这种,没有向内存申请空间的对象,就可以做浅拷贝。 2. 对初始化后的赋值,会报错,因为析构了两次,所以得重写operator */ void testCopy() { lz::string s1("hello gan"); lz::string s2(s1); s2[0] = 'w'; cout << s1.c_str() << endl; cout << s2.c_str() << endl; cout << "修改了sw[0]也一样" << endl; cout << "下面测试赋值 s3 = s1 ," << endl; lz::string s3 = "aaa"; cout << "s3 = " << s3.c_str() << endl; cout << "自己给自己赋值 出现乱码 需要在拷贝构造中加判断,这算个思想BUG 要防范" << endl; s3 = s3; cout << s3.c_str() << endl; } void test_push_back() { lz::string s1("hello back"); s1.push_back('6'); cout << s1.c_str() << endl; } void test_append() { lz::string s1("hello back"); s1 += ' '; s1.append("sir"); cout << s1.c_str() << endl; cout << "下面是+=字符串" << endl; s1 += " o haha"; cout <<s1.c_str() << endl; } void test_insert() { lz::string s1("hello back"); s1.insert(s1.size(), 'a'); cout << s1.c_str() << endl; } void test_insertSring() { lz::string s1("hello www"); s1.insert(6, "orld hh"); cout << s1.c_str() << endl; } void test_append_ByInsert() { lz::string s1("hello world"); s1.append(" ahh"); cout << s1.c_str() << endl; cout << "下面append不加一个字符,加一个字符第一个都能匹配上,且编译通不过" << endl; s1.append("abcd"); } void test_PB_ByInsert() { lz::string s1("hello world"); s1.push_back('!'); cout << s1.c_str() << endl; } void test_Erase() { string s1("hello"); cout << "对h1 = hello 删1, 10, 理论只留下一个h" << endl; s1.erase(1, 10); cout << s1.c_str() << endl; string s2("hello"); s2.erase(1); cout << s2.c_str() << endl; string s3("hello"); s3.erase(); cout << s3.c_str() << endl; } // void test_cout() { lz::string s("hello world"); cout << s.c_str() << endl; cout << s << endl; cout << "=== , +='\0' 和 +=world == " << endl; s += '\0'; s += " world"; cout << s.c_str() << endl; cout << s << endl; } void test_in() { lz::string s; cin >> s; cout << s << endl; cout << "测试连续输入" << endl; cin >> s; cout << s; } void test_sub() { lz::string s("hekki eptka"); lz::string a = s.substr(0, 45); cout << a << endl; } void test_resize() { lz::string s("hekki eptka"); s.resize(20, 'x'); cout << s << endl; s.resize(3); cout << s << endl; } int main() { // lz::string s1 = "abc"; //string1(); //test_push_back(); // test_append(); //test_insert(); //test_insertSring(); //test_PB_ByInsert(); // test_insert(); //test_PB_ByInsert(); //test_append_ByInsert(); //test_Erase(); //test_cout(); //test_cout(); //test_in(); //test_sub(); test_resize(); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
零碎笔记
reverse: pb需要借助,满了要扩容,满了的判断
push_back:记得’\0’
string& 引用需要对象,所以return *this;
+=:注意返回值返回谁、类型是什么
append(): 它用来加一串,最后可以用insert加一串简化,
它不实现append()加1个,因为用push_back()
strcpy为什么不用strcat:它是个失败的设计,找’\0’,太费劲。
借助append() += 字符串也实现了
insert()某个位置插字符:size_t pos 0问题,end >pos,即可,不要end>=pos,
end = _size+1
用 str[i] = str[i-1],使得前一个比如0号位的也拿到了,i就不用在0时–了。
原来 end >= pos :pos==0
end从 _size~0,
改为:end>=_size+1, pos == 0
s[i+1] =s[i] ,这样 i == 0, s[0+1] = s[0],但是 i–后成了最大正数,死循环
初始:end =_size+1, end > pos
s[i] = s[i-1] 这样pos 不用到0,不存在–到最大值的情况
总之,就是想办法让i不能为0insert()插串:插入方式特别用end
调用strncpy
erase():借助npos,类中声明,类外定义,静态成员变量必须在类外
len == npos意思是len没有给值是默认就删完,或 该位置后删的长度多于pos后本有长度就删完
注意删完,我们也是给了’\0’的。
巧妙的npos+len <_size写法:
pos后删len个,就跳过len个,都挪前面来,包括了’\0’流重载:不一定要友元
把每个字符给out : out<out:
重载后发现,如果插入‘\0’,cout<in: 流提取
1、输入和输出不一样,输入要考虑扩容问题,因为你在造一个string,
而且不断输入过程中,可能面临输入很长,但是你会不断扩容的过程,
扩容速度较慢,应该让它少做。用一个数组缓冲区。每次够一定程度,
做一次 +=
2、in >> ch,不行,遇到空格和换行会停止读取。
用in.get()、不会中断
istream读取效率不低,用缓冲区
3. 有BUG,重复对s输出,先应该对s清理。clear()。不然上一次字符接收有剩余clear:_size清0
0位置置’\0’;find:
找字符:从头到尾找,找不到返回npos,默认-1
找子串:strstr:原理是暴力查找,
resize:除了开空间,还初始化
比现在小,不会变capacity,变size,保留n之前。
判断 n 和 _size分if elsevs下string被做了特殊处理
空串的:容量开了十几,因为加了优化,向堆申请小空间,会有内存碎片,
所以多开了16字节数组,给string里面加了char _buff[16],一开始给buff放
优点:效率会高,空间换时间。缺点显然就是:空间
但是Linux中又不一样。string使用练习题
string s = “hello world”;
- 题:
1 . 字符串转int:
判断是否越界:使用int接收,如果某个时刻res/10 > int_max/10,就说明越界了。
合理利用条件:因为说了+ -只能在第一位出现,其它位置只是可能出现字母,但凡有字母,就返回0.
所以一个while加3个if简单判定就可以搞定。且这个题,给了返回值是int,不用考虑越界。
思路和做法:
巧妙点: 1. 充分利用条件:+、-只在1位,碰到字母就返回0。且判断+ - ,如果是数字isdigit()才做计算
巧妙点: 2 注意进位:直接ans = ans*10 + ch - ‘0’ 更是巧妙不用进位计算。
注意点:函数使用:isdigit()和 isalpha :啊了佛class Solution { public: int StrToInt(string str) { int ans = 0; int isplus = 1; // 默认必须给1 :因为有时候首位没有+ // 从尾到头计算:每次 ans = ans * 10 + ch - '0' 更nb 进位也不用 迭代器也可 for(int i = 0; i < str.size(); i++) { if(isalpha(str[i])) return 0; else if(str[i] == '+' || str[i] == '-') isplus = (str[i] == '+')?1:-1; else if(isdigit(str[i])) ans = ans * 10 + str[i] - '0'; } return ans*isplus; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 字符串相加:
思路:相加共有部分,再看进位剩余,再看谁剩余逐个位相加。
注意: 1. i、j别给错
2. 谁空就给另外一个,开头的出口条件
3. 字符串反转: Reverse() 、Reverse()、Reverse() 不是 sort() 不是sort() 。class Solution {
public:
string addStrings(string num1, string num2) {
if(num1.size() == 0)
return num2;
if(num2.size() == 0)
return num1;
// 先加共有部分
int i = num1.size()-1;
int j = num2.size()-1;
string res= “”;
int flag = 0;
while(i>=0 && j>=0 )
{
int t = num1[i] - ‘0’ + num2[j] - ‘0’ + flag;
if(t > 9)
{
t -= 10;
flag = 1;
}
else
{
flag = 0;
}
res += char(t + ‘0’);
i–;
j–;
}
// 进位有剩余 res 一直走 :但是res完了 又得和剩余的num1和num2,但是可以直接做 ,不用单纯加进位
while(i>=0)
{
int t = num1[i] - ‘0’ + flag;
if(t > 9)
{
t -= 10;
flag = 1;
}
else
{
flag = 0;
}
res += char(t + ‘0’);
i–;
}
// 如果是num2剩余
while(j>=0)
{
int t = num2[j] - ‘0’ + flag;
if(t > 9)
{
t -= 10;
flag = 1;
}
else
{
flag = 0;
}
res += char(t+ ‘0’);
j–;
}
// 如果flag剩余 其实也就一个了 直接插入即可
if(flag)
{
res += ‘1’;
}
// 逆置
std::reverse(res.begin(), res.end());
return res;
}
};- 验证回文串
思路:首先,它里面都是字母、空格、符号,我们需要比较每个字母即可。所以大体思路就是双指针正序和逆序去比较。
注意点:1 。 为了跳过空格和其它标点,借助判断数字或字母的的函数。
2. 发现当前不是数字或字母,直接跳过,用while更猛。
3. 大小写不影响:都化小写:记住转小写:tolower(),此外是!isNumOrLetter
4.class Solution { public: bool isNumOrLetter(char a) { if(a >= '0' && a <= '9') return true; else if((a <= 'z' && a >= 'a') || ('A' <= a && a <= 'Z')) return true; else return false; } bool isPalindrome(string s) { int start = 0; int end = s.size()-1; while(start < end) { // 跳过非字母数字 while(start < end && !isNumOrLetter(s[start])) start++; while(start < end && !isNumOrLetter(s[end])) end--; // 用小写比较 if(tolower(s[start]) != tolower(s[end])) return false; else { start++; end--; } } return true; } }; // raceacar // racaecar- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 反转字符串中的单词:III
答:每次逆转一个单词。双指针:i找空格或最后一个,而j标记到i。j 和 i 之间,夹住一个单词。
- 注意点(犯错点):不要用for,直接while,因为i++在内部即可。每次找到一个空格位置,翻转完一定要i++。到了下一个单词的开头,j = i。因为j每次需要靠i的旧值得走到单词首位。而我用了for,i++两次,且在j = i之后。忘了i++。且不用for,不然i++多了一个。
- 注意这个题,最后不需要整体翻转过来。它就是要反转一个句子里面的每个单词。
class Solution { public: void Reverse(string& str, int start , int end) { while(start < end) { char t = str[start]; str[start] = str[end]; str[end] = t; start++; end--; } } string reverseWords(string s) { int i = 0; int j = 0; // 9一次转一个词 while(i < s.size()) { while(i < s.size() && (s[i]!= ' ' || i == s.size()-1)) i++; Reverse(s, j, i-1); // 翻转完一定得i++到下一个单词开头 i++; j = i; } //Reverse(s, 0, s.size()-1); return s; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 反转字符 II:
思路:每2k个,转k个,我求了一下loop。然后看剩余几个。
妙点: i += 2* k
每个loop里面: 翻转: ( i , i + k - 1 )class Solution { public: void Reverse(string& s, int start, int end) { while(start < end) { char t = s[start]; s[start] = s[end]; s[end] = t; start++; end--; } } string reverseStr(string s, int k) { // 每2k,就翻转2k的前k:看有几个2k int loop = s.size() / (2 * k); int i = 0; while(loop) { loop--; Reverse(s, i, i + k-1); i += 2*k; } loop = s.size() / (2 * k); int surplus = s.size() - 2 * k * loop; if( 0 < surplus && surplus < k) { Reverse(s, i, s.size()-1); } else if(k <= surplus &&surplus < 2*k) { int end = i + k - 1; Reverse(s, i, end); } return s; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
-
相关阅读:
分享几个 Selenium 自动化常用操作
app专项测试(网络测试流程)
【2251. 花期内花的数目】
人生第一个java项目 学生管理系统
mindspore用户自定义数据问题
Matlab论文插图绘制模板第65期—带等高线的曲面图(Surfc)
导航【mysql高级】【java提高】
软件测试基础知识详解
c语言字符指针、字符串初始化问题
Css切换不同窗口
- 原文地址:https://blog.csdn.net/myscratch/article/details/127321223
