-
李沐论文精度系列之七:Two-Stream双流网络、I3D
文章目录
传送门:- 李沐论文精读系列一: ResNet、Transformer、GAN、BERT
- 李沐论文精读系列二:Vision Transformer、MAE、Swin-Transformer
- 李沐论文精读系列三:MoCo、对比学习综述(MoCov1/v2/v3、SimCLR v1/v2、DINO等)
- 李沐论文精读系列四:CLIP和改进工作串讲(LSeg、GroupViT、VLiD、 GLIPv1、 GLIPv2、CLIPasso)
- 李沐论文精读系列五:DALL·E2(生成模型串讲,从GANs、VE/VAE/VQ-VAE/DALL·E到扩散模型DDPM/ADM)
- 李沐论文精读系列六:端到端目标检测DETR、最简多模态ViLT
一、双流网络
- 论文:《Two-Stream Convolutional Networks for Action Recognition in Videos》(用于动作识别的双流卷积神经网络)
- 参考:李沐《双流网络论文逐段精读》
1.1 前言
1. 为什么要做视频?
- 视频包含更多信息:比如时序信息、声音&图像等多模态信息,而且是连续信息而非静止的图像。
- 论文引言提到,视频天生能提供一个很好的数据增强,因为同一个物体在视频中会经历各种形变、光照变换、遮挡等等,非常丰富而又自然,远比生硬的去做数据增强好得多
- 视频处理是未来突破的方向:目前计算机视觉领域,很多研究热衷于在ImageNet等几个榜单刷分,往往训练了很大的模型,使用很多的策略,也只能提高一点点,类似深度学习出现以前,CV领域中机器学习的现状,已经达到了一个瓶颈期。要想突破必须有新的网络结构,指标之一就是要能很好地处理视频数据。
本文是做视频分类的,为啥论文题目是动作识别呢?
- 包含人类动作的视频更容易收集,直到现在,大部分的视频分类还是做动作识别
- 动作识别非常实际意义,对VR、视频检索等等很多工作都有帮助
2. 双流网络:视频领域开山之作
在这篇文章出现之前,用深度学习来处理视频主要有两种方式:
- CNN+LSTM:即CNN抽取关键帧特征,LSTM进行时序建模
具体来说,就是先抽取视频中的关键帧得到K张图,然后将这K张图输入CNN网络得到图片特征。再将这些特征全部输入LSTM网络,进行各个时间戳上图片特征的融合,得到整个视频的融合特征。最后将LSTM最终时刻的特征接一个FC层得到分类结果。 - 3D网络:将视频帧(分割好的一个个的视频段,每段含有K张图片)直接输入3D 的CNN网络进行时空学习。
此时卷积核必须是3维的(比如每个卷积核都是3×3×3,加入了时间维度),网络不光学习空间信息,还需要学习时序信息(运动信息)。最后3D Conv输出的特征也是接一个全连接层得到分类结果。因为多了一个维度,模型的参数量很大,不太好训练,而且效果也不好。
这两种方式的效果都还不如手工设计的特征。双流网络是第一个能让深度学习网络效果媲美手工设计特征的视频分类结构,从此之后,深度学习在视频领域开始占据主流。
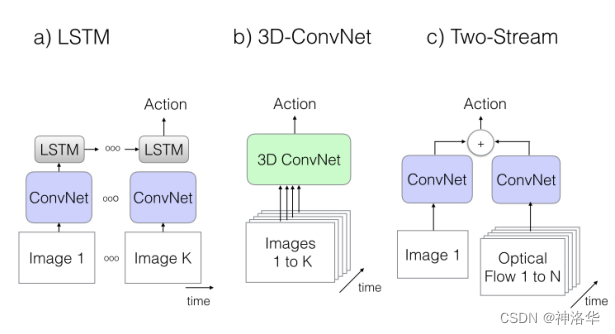
3D网络做视频处理的代表工作是2014年的DeepVideo,把当时能够魔改的CNN结构都在动作识别上试了一遍,实验做的很多。作者为了做出好的效果,还收集了一个很大的数据集:
Sports-1M。这个数据集有100万视频,时长几十秒到几分钟,视频帧超10亿,直到现在都还在使用。
最终的结果,是在Sports-1M这么大的数据集上预训练,再在UCF-101数据集上微调,精度也只有65%,比最好的手工特征方法差了20%,所以结果是非常差的。作者认为,目前CNN网络无法将视频处理的很好,是因为卷积神经网络很擅长处理静态的外观信息(
appearance information,比如物体形状大小颜色、场景信息等等),而非运动信息(motion information) 。既然如此,就干脆用另一个网络(光流网络)抽取好运动信息的特征,CNN只需要学习输入的光流和最后的动作信息之间的映射就行(或者说是光流输入到时间流网络的分类之间的映射),这种映射是深度神经网络最擅长的。也就是说CNN本身不需要学习运动信息,也不需要进行时序建模,这些都交给光流做了,所以模型非常的简单。两个网络互不干扰,很好训练也很好优化,最终模型的性能也非常高(见实验部分)。在相关工作中,作者列出了两种手工设计的特征:
STIP特征(spatio-temporal interest points):基于局部的时空学习, 演变为今天的3D网络IDT特征( improved dense trajectories ):dense trajectories是指光流特征。先算出光流,再利用光流找到运动轨迹,然后在物体运动轨迹上抽取特征,这样能很好的利用物体的运动信息。而IDT就是后续改进的dense trajectories特征。
受光流特征的启发,作者将光流也应用到神经网络结构中,也就是本文的双流网络。
3. 贡献
将深度神经网络应用于视频动作识别的难点,是如何同时利用好静止图像上的appearance information以及物体之间的运动信息motion information。本文主要有三点贡献:- 提出了一种融合时间流和空间流的双流网络;
- 证明了直接在光流上训练的网络,即使训练集很小,仍能获得很好的效果;
- 在两个动作识别数据集上使用多任务学习(multi-task learning),同时训练一个backbone,可以增加训练数据量,提高模型性能。
1.2 网络结构
双流网络(使用两个卷积神经网络)结构如下:
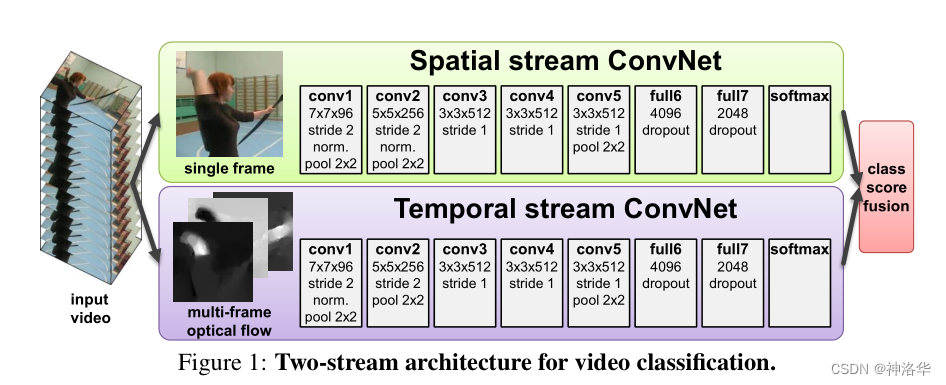
Spatio Stream Convet:空间流卷积网络,输入是单个帧画面(静态图片),主要学习场景信息。因为是处理静态图片,所以可以使用预训练的模型来做,更容易优化。最后根据网络输出的特征得出一个logist(假设模型是在UCF-101数据集上做测试,数据集共101个类,logist是softmax之后的类别概率,那么时间流网络的输出就是一个1×101维的向量)。temporal stream convet:时间流卷积网络(光流网络),输入是光流图像,通过多帧画面的光流位移来获取画面中物体的运动信息,最后也根据网络输出的特征得出一个logist。- 光流输入显式地描述了视频帧之间的运动,而不需要CNN网络去隐式地估计运动信息,所以使得识别更加容易。加入时间流卷积网络之后,模型精度大大提升。
- 直接以光流做输入来预测动作,而不用CNN本身去学动作信息,大大简化了学习过程。
- 融合有两种方式:
late fusion融合:两个logist加权平均得到最终分类结果(比如两个softmax向量取平均,再做一个argmax操作)。- 将softmax分数作为特征再训练一个SVM分类器。
late fusion就是指在网络输出层面做做融合(这里是logits层面),另外还有early fusion,就是在网络中间层特征上做融合。- 空间流和时间流网络结构几乎是一样的,唯一区别就是输入不一样。前者输入的是静止的视频帧,输入
channel=3;后者输入是L张光流图的叠加,输入channnel=2×L(一般取L=10)。因为时间流网络输入通道是2L,所以没法用一般的CNN预训练模型。
1.3 光流(Optical flow)
1.3.1 什么是光流
optical flow简单说就是每个物体的运动轨迹,运动越明显的区域亮度越高。比如下图左侧由两张图片组成,背景不变,只有人的运动状态变了;右图背景运动状态不变,所以是黑色的,只有图中的人处于运动中,是亮色的。通过提取光流,可以去掉背景噪声、人物穿着性别等和运动无关的特征都忽略掉,所以最后提取的特征能很好的描述运动信息,也变相的相当于视频里的时序信息的特征表示。

光流由一些位移矢量场(displacement vector fields)组成的,其中第
t帧的位移矢量用dt表示,是通过第t和第t+1帧图像得到的。dt可以拆分成水平部分dtx和竖直部分dty。将dt、dtx、dty可视化后结果如下:

- a、b:前后两帧图片,维度为240×320×3(
UCF-101数据集视频帧的大小) - c:光流
dt的可视化显示,射箭动作是超右上走的,维度是240×320×2。- 因为图片上每个点都可能运动,所以每个像素点都有对应的光流值,所以论文中一直称之为密集光流(dense optical flow)。最终光流图和原图大小一致。
- 2表示水平和垂直两个方向(维度)。
- 每两张图得到一个光流,如果视频一共抽取L帧,那么光流就是L-1帧。这些光流一起输入光流网络
- d、e分别是水平位移
dtx和垂直位移dty
1.3.2 如何利用光流
光流网络主要是为了学习视频中物体的运动信息(时序信息),所以其输入应该是多张光流图的叠加,而非单张光流图(在之前手工设计的特征中,一般是用10帧或者16帧光流图的叠加)。在3.1 章节,讨论了两种叠加方式:直接叠加和根据光流轨迹叠加,示意图如下:(这些光流图都是要输入网络的 ,所以都经过了resize 224×224)
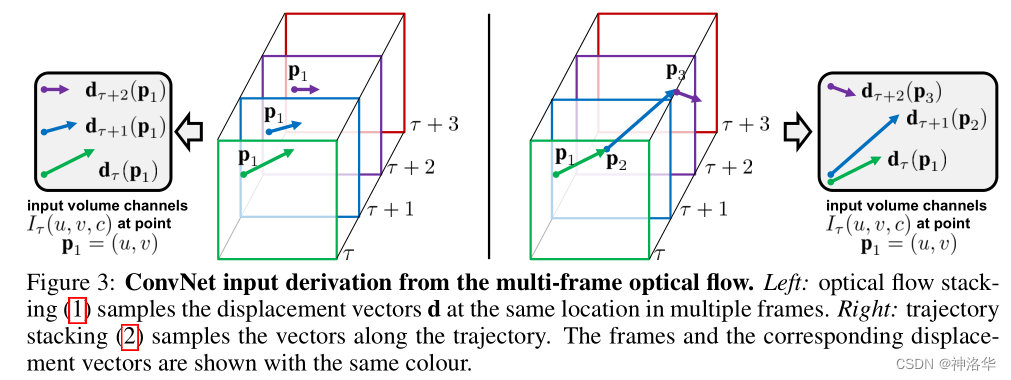
- 简单叠加:网络输入是图中每个点多次光流的叠加,比如网络每次都取P1处的光流。这种方式简单直接,但是应该没有充分利用光流信息。
- 按轨迹叠加:每一帧都根据光流轨迹,更新光流点的位置,比如网络按照P1、P2、P3…这些位置依次提取光流。这种方式听起来合理很多,充分利用了光流信息。
- 每次叠加都是先叠加水平位移,再叠加垂直位移,所以是
[
x
1
,
x
2
,
.
.
.
x
L
,
y
1
,
y
2
,
.
.
.
y
L
]
[x_{1},x_{2},...x_{L},y_{1},y_{2},...y_{L}]
[x1,x2,...xL,y1,y2,...yL],即光流网络输入维度
224×224×2L。
最终实验结果表明简单叠加的方式更好,作者也没有解释清楚这一点。
1.3.3 双向光流(Bi-directional optical flow)
Bi-directional 的操作,就类似BERT一样,都是一种保险、会涨点的操作。光流前向计算和后向计算都是合理的,物体从位置a到位置b或者反过来都是可行的。
具体来说,如果光流有L帧,就把前一半计算前向光流,后一半计算后向光流,最后得到的光流还是L帧,通道数为2L。1.3.4 光流的局限性及和对应的预处理(抽取)方式
1. 光流抽取非常耗时(单张0.06秒)
计算光流的算法来自《 High accuracy optical flow estimation based on a theory for warping》这篇论文,使用的是其GPU实现,计算一帧光流需要约0.06秒,所以抽取光流是非常耗时的。比如对于
UCF-101数据集,有约1万视频,每个视频约10秒,每秒30fps(30帧),一共约300万帧。每两帧抽一张光流图,总共耗时约50h。如果是Sports-1M这种更大的数据集(100万视频,视频时长长达几分钟),抽取光流就要成千上万个小时了,这样即使是8卡GPU也要抽取一个多月。2. 光流的密集表示导致其存储困难,无法训练
图片上每个点都有光流值,也就是一个密集的表示。要把这个密集的表示存下来,所耗费的空间会非常大。对于UCF-101这个小的数据集来说,存下所有的光流也需要1.5T的空间,如果是Sports-1M数据集,至少也得是PB级了。即使有这么大的硬盘存储,IO速度也提不起来,还是没法训练。3.光流预处理为JPEG图
论文在中,作者将光流的密集表示(dense)转为稀疏表示(sparse)以减少光流存储空间,具体来说就是做类似RGB图像的压缩。将光流值全部rescaled到[0,255]的整数,存成JPEG图片。这样每张光流图就十几kb,存储空间大大减小(UCF-101 dataset from 1.5TB to 27GB)。双流网络从14年提出到现在,这种将光流的密集表示存为图片的预处理方式 一直沿用至今。但其实即使如此,光流的提取速度慢和存储空间大这两点还是受人诟病,后续有很多工作尝试改进光流,或者直接舍弃光流,改为3D网络。
1.3.5 视频模型测试
本章双流网络实现细节为:
-
所有视频帧都 rescale 至最短边为 256
-
固定抽取25帧:不管视频有多长,都从视频中等间距的抽取25帧视频帧
当时UCF-101数据集和HMDB-51数据集视频长度都是5-7秒,按一秒30帧算,一共是150-210帧。固定取25帧就基本是每隔6到8帧取一帧,约0.25秒。 -
10 crop:取出来的每一帧都做10 crop(224×224)。简单说就是每一帧都裁剪4个边和一个中心,然后翻转图像之后再类似的crop五张图,最终每一帧得到10张图。最终空间流网络的结果就是250 crop(224×224)经过CNN后得到的结果的平均。


多放一张美图,不用谢了 -
光流网络也是先抽取25帧,再取连续的11帧得到10张光流图,输入时间流网络,得到光流网络的结果。两个网络结果做
late fusion得到最终的模型结果

Two-Stream:任选一帧,然后取剩下的10帧共11帧,计算出10张光流。整个时间跨度是11帧,约0.4s
视频模型做测试的方式是很多样化的。比如很多模型都采用了上面这种25×10 crop的输入方式,也就是常说的
250view来做视频测试。但是也有一些工作,每个视频抽取20、15、10甚至是5帧,所以在对比结果时,也要看一下是不是公平比较。
另外在3D网络中,使用的是30view;引入了vision transformer之后,测试方式又进一步改变了,有12view、4view、3view等等。所以每篇视频论文看结果之前,要看看其测试方式是怎样的。1.4 实验
1.4.1 网络结构的消融试验
下图是在
UCF-101数据集试验了空间流网络预训练效果,和时间流网络的光流堆叠方式:

- a:空间流网络:使用预训练模型效果更好
- From scratch:不使用预训练模型而是从头训练,效果很差。
- Pre-trained + fine-tuning:整个网络做微调。因为数据集太小,整个网络微调作者担心过拟合,所以试验了dropout ratio=0.9,此时效果最好。后续工作因为训练的数据集更大,所以这种全部网络微调的方式效果更好。
- Pre-trained + last layer:只微调最后一层,就不用太担心过拟合,所以dropout ratio=0.5最优。
- b:时间流网络:简单的叠加光流效果更好,双向光流略微提高性能。
- Single-frame optical flow:网络输入是单张光流图
- Optical flow stacking、Trajectory stackin:前者表示简单的叠加光流,效果更好;后者表示按轨迹叠加光流。

上图是单向/双向光流、加权平均/SVM分类、是否多任务的消融试验(时空流网络融合时,双向光流是不利的)。1.4.2 模型效果对比
通过上面的消融试验确定了网络结构之后,和其它的模型进行性能对比:

- 第一行是IDT手工特征的效果,非常的好。
- 二、三行是对IDT的改进,加了全局特征,使其更适合做视频,结果也更高。
- 四、五行是之前深度学习尝试做视频处理的工作,结果非常差。(第五行就是上面说的
DeepVideo) - Spatial stream ConvNet、Temporal stream ConvNet:单独的空间流和时间流网络。可以看到单独的时间流网络效果已经非常好,而且是从头训练的网络,没有使用预训练模型。
- 最后两行是两个网络分别用加权平均融合,以及额外训练SVM分类器。
1.5 未来工作、总结
1.5.1 未来工作
作者对未来工作的期望有三点:
- 让光流网络也能使用预训练模型或者是更多的数据(比如
Sports-1M数据集); - 为什么基于轨迹的光流叠加方式效果并不好。这一点在2015年的Trajectory-Pooled Features中已经解决了,沿着轨迹抽取特征效果提升显著(
UCF101精度91.5%); - 消除 camera motion(相机自带的移动而非物体的移动)。camera motion会影响光流计算导致计算不准,或者是影响光流上的动作识别。本文作者的方式是将光流减去均值,相当于简单的进行全局camera motion消除,但是作者认为这一点还需要改进(之前手工设计特征的工作,在这一块考虑了很多因素)。
1.5.2 总结
之前的深度学习处理视频的方法没有利用物体的运动信息,导致其效果还不如传统的手工设计的特征效果好,这也是本文的研究动机。引入运动信息有多种方式,光流是其中最好用的一种,其本身就包含了非常准确和强大的物体运动信息在里面。
引入光流的方式是额外引入一个时间流网络,巧妙的利用光流提供的物体运动信息,而不用神经网络自己去隐式地学习运动特征,大大提高了模型的性能。整个双流网络从结构上来说都非常简单,就是沿用AlexNet网络并做了小小的改动,最后的操作也是一个简单、常规的
late fusion融合。双流网络除了引入光流这一点,也展示了一种可能性:当神经网络即使如何魔改也无法解决某个问题的时候(比如改模型结构或者目标函数),不如给模型提供一些先验信息,模型学不到就帮它学,往往能大幅简化这个任务。所以一个网络无法解决问题,就可以尝试加入另一个网络,使用别的的数据、别的模型。这种多流网络的思想(网络互补),在别的领域也被广为应用,效果也很好。这一点也从侧面验证了数据的重要性,真实场景中收集更多更好的数据,对模型效果的提升更为巨大,也能更好解决模型泛化、偏见等等一系列问题。
双流网络也可以看做是多模态网络,RGB图片和光流可以看做是不同的模态,有点类似CLIP(两个网络输入分别是图片和文本)。
双流网络在视频理解的地位,可看做是AlexNet在图片分类中的地位。一旦证明其做视频的有效性,就马上有大批工作跟进了,称得上是开山之作。
二、I3D(双流网络的3D实现)
2.1 前言
1. 本文有两大贡献:
-
提出了一个新的模型I3D,即
Inflated 3D ConvNet。
Inflated是扩大膨胀的意思,这里是指把一个2D模型扩张到一个3D模型(比如直接将ResNet的卷积核从二维替换为三维,池化也使用3D池化等等)。这样做有几个优点:- 不用再费尽心思的设计一个针对视频理解的网络了,否则从头设计3D网络,还得考虑各种网络结构,方方面面。
- 可以沿用CV领域的2D网络,比如ResNet、VGG等等,这些模型都是经过多年优化的。
- 可以使用2D预训练网络进行3D网络的初始化,所以模型可以做的很深,也不需要太多的视频数据进行训练
之前的3D网络参数量太大,也没有合适的视频数据集去预训练,所以之前的3D网络都不能太深(比如C3D模型,其网络只有8层),效果也不如双流网络。
-
提出了一个新的视频分类数据集
Kinetics,其优点是:- 类别均衡、规模合适:
Kinetics一开始只有400类所以也叫Kinetics 400,每个类别都超过400个clips(10s左右的视频段落一般叫video clip)。后续又推出了Kinetics 600、Kinetics 700;其视频数量分别有30万、50万、60万。 - 多样性好:每段视频都来自独一无二的YouTube视频。有些视频数据集的视频,都是一个长视频中截取的,比如
UCF101。 - 标注精准:每个clips都是视频中精准抽出10s左右的段落,所以整个数据集都标注的非常精准。
- 难度适中:如果数据集的视频都过于难或者过于简单,就失去其意义了,也没人会用。
- 类别均衡、规模合适:
Sports-1M:2014年提出,有一百万视频,但是基本都是运动类,应用场景受限。Youtube 8M:2016年由google提出,共有800万视频。但是数据集实在是太大了,一般人即使下载了也根本玩不动,所以比赛时都是直接提供抽取好的特征。UCF101和HMDB-51:前者101类,13000个视频;后者51类只有7000个视频。这两个数据集都太小了,无法发挥深度神经网络的威力Kinetics:类别均衡,难度适中,数据集规模合适,很多人都玩得动,所以被广泛使用。基本现在视频分类的工作是一定要在Kinetics上跑一个结果。
Kinetics数据集
论文题目中的Quo Vadis来自1951年的电影《A still from ‘Quo Vadis’ (1951)》,英语译为Where is this going?电影讲的是古罗马一个昏君的故事。作者的意思是,只通过一张图片,是没法确定很多动作的。比如不能确定下面两个演员是将要亲吻还是已经亲吻过了;无论是否亲吻了,下一步动作如何发展也是未知的。只有看完了上下文的视频帧,才知道发生了什么,以及未来会发生什么。
视频理解的模型,最好是在视频上做预训练,正要视频领域缺少这样的一个数据集,所以提出了Kinetics。本文提出的I3D模型在Kinetics上做预训练,然后迁移到别的数据集上,模型性能得到了巨大的提升(UCF101精度刷到了98%,宣告了这个数据集的终结)。

但其实后来大家发现,直接选取
Kinetics数据集视频的最中间一帧,然后做图像动作分类,模型的准确度已经很高了,根本不需要太多的上下文信息和时序建模能力。
直到现在也很难构建一个很好的视频数据集,让模型能很好的利用上下文信息,进而可以处理长时间、复杂的视频任务,拓展到真实世界的方方面面。2.2 视频处理模型对比
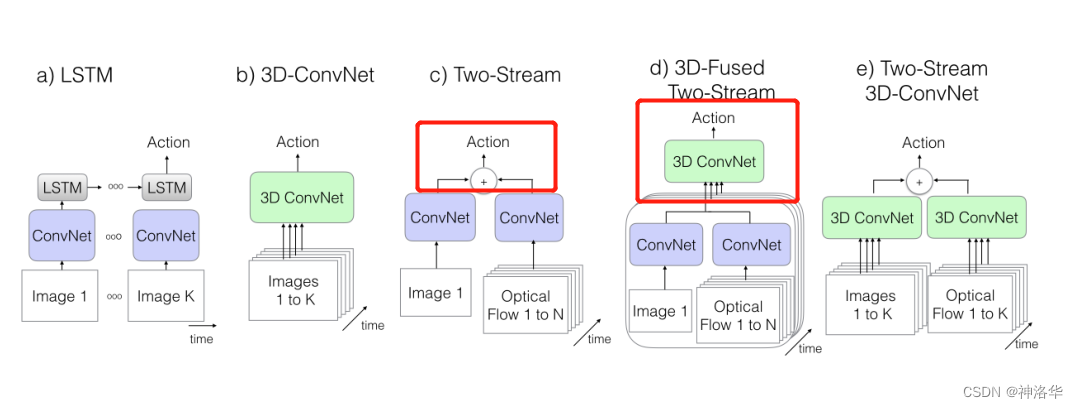
在本文1.1中已经引用了这张图,介绍了视频理解模型的几种结构,再次做个说明:
CNN+LSTM:即CNN抽取关键帧特征,LSTM进行时序建模
具体来说,就是先抽取视频中的关键帧得到K张图,然后将这K张图输入CNN网络得到图片特征。再将这些特征全部输入LSTM网络,进行各个时间戳上图片特征的融合,得到整个视频的融合特征。最后将LSTM最终时刻的特征接一个FC层得到分类结果。3D Conv:将视频帧(分割好的一个个的视频段,每段含有K张图片)直接输入3D 的CNN网络进行时空学习。
此时卷积核必须是3维的(比如每个卷积核都是3×3×3,加入了时间维度),网络不光学习空间信息,还需要学习时序信息(运动信息)。最后3D Conv输出的特征也是接一个全连接层得到分类结果。因为多了一个维度,模型的参数量很大,不太好训练,而且效果也不好。Two stream(late fusion)`:如果不想用LSTM进行时序建模,也不想用3D网络直接进行时空学习,那么还可以使用光流来得到时序信息(运动信息)。
双流网络整体还是2D网络结构,但额外引入一个时间流网络。通过巧妙的利用光流来提供的物体运动信息,而不用神经网络自己去隐式地学习运动特征,大大提高了模型的性能。3D Fused Two stream(early fusion)`:双流网络的改进。作者认为双流网络中,两个网络的输出只是进行简单的加权平均来处理,效果还不够。所以将其替换为一个较小的3D网络,进一步融合特征。实验证明这种先进行2D卷积网络训练,再进行3D卷积网络融合的效果更好。Two stream 3D ConvNet:I3D是3D网络和双流网络的结合。因为单纯的使用3D网络,模型效果还是不好,加上光流之后,可以大大提高模型性能。所以可以说I3D=Two stream+3D Conv。另外两个分支网络都已经是3D网络了,也就不需要另外加一个3D网络进行融合,直接加权平均得到最终的结果就行。
2.3 I3D网络结构
2.3.1 Inflated:2D网络扩张为3D网络
扩张方式简单粗暴,其它网络结构都不变,就是把2D的卷积核加一维变为3D(
K*K —> K*K*K),2D池化改为3D池化。一直到最新的video swin transformer(2022年),将swin transformer从2D扩张到3D,也是使用这种方式。2.3.2 Bootstrapping:预训练的2D模型初始化3D网络,及代码实现
验证模型是否正确初始化:使用预训练模型初始化自己的模型时,如果同一张图片,分别输入原模型和初始化后的模型,最终输出的结果都一样,就说明原模型的参数初始化是对的(因为两个模型的结构和输入都是一样的)。
受此启发,作者将一张图复制粘贴N次就得到了一个视频,这个视频每个时间步上都是同一张图片(a boring video)。将图片 x x x和其复制N次得到的视频 x ′ {x}' x′分别输入2D网络 f f f和3D网络 f ′ {f}' f′,将后者的网络除以N,如果和2D网络的输出一样,则说明3D网络初始化OK。比如2D网络输出设为 y = f θ ( x ) y=f_{\theta }(x) y=fθ(x),3D网络输出为 y ′ = f θ × N ′ ( x × N ) = N × f θ ( x ) {y}'={f}'_{\theta \times N}(x\times N)=N\times f_{\theta }(x) y′=fθ×N′(x×N)=N×fθ(x)。然后将3D网络的所有 2D filters权重除以N,那么就等于 N × f θ ( x ) ÷ N = f θ ( x ) N\times f_{\theta }(x)\div N= f_{\theta }(x) N×fθ(x)÷N=fθ(x),和2D网络输出结果一致。
Bootstrapping初始化具体实现代码如下(来自dmlc/gluon-cv):
def init_weights(self, ctx): """Initial I3D network with its 2D pretrained weights.""" self.first_stage.initialize(ctx=ctx) self.res_layers.initialize(ctx=ctx) self.head.initialize(ctx=ctx) if self.pretrained_base and not self.pretrained: if self.depth == 50: resnet2d = resnet50_v1b(pretrained=True) elif self.depth == 101: resnet2d = resnet101_v1b(pretrained=True) else: print('No such 2D pre-trained network of depth %d.' % (self.depth)) weights2d = resnet2d.collect_params() # 获取2D网络的预训练参数 if self.nonlocal_cfg is None: weights3d = self.collect_params() # 获取3D网络的参数 else: train_params_list = [] raw_params = self.collect_params() for raw_name in raw_params.keys(): if 'nonlocal' in raw_name: continue train_params_list.append(raw_name) init_patterns = '|'.join(train_params_list) weights3d = self.collect_params(init_patterns) # 获取3D网络的参数 # 下面一行是判断句式,2D网络和3D网络的结构应该一样,参数长度一样 assert len(weights2d.keys()) == len(weights3d.keys()), 'Number of parameters should be same.' dict2d = {} for key_id, key_name in enumerate(weights2d.keys()): dict2d[key_id] = key_name dict3d = {} for key_id, key_name in enumerate(weights3d.keys()): dict3d[key_id] = key_name dict_transform = {} for key_id, key_name in dict3d.items(): dict_transform[dict2d[key_id]] = key_name cnt = 0 for key2d, key3d in dict_transform.items(): # 通过for循环,一步步地将2D网络参数转为3D网络的参数 if 'conv' in key3d: temporal_dim = weights3d[key3d].shape[2] temporal_2d = nd.expand_dims(weights2d[key2d].data(), axis=2) inflated_2d = nd.broadcast_to(temporal_2d, shape=[0, 0, temporal_dim, 0, 0]) / temporal_dim # 上一步就是Bootstrapping操作,将2D网络参数复制temporal_dim份,然后再除以temporal_dim assert inflated_2d.shape == weights3d[key3d].shape, 'the shape of %s and %s does not match. ' % (key2d, key3d) weights3d[key3d].set_data(inflated_2d) cnt += 1 print('%s is done with shape: ' % (key3d), weights3d[key3d].shape) if 'batchnorm' in key3d: assert weights2d[key2d].shape == weights3d[key3d].shape, 'the shape of %s and %s does not match. ' % (key2d, key3d) weights3d[key3d].set_data(weights2d[key2d].data()) cnt += 1 print('%s is done with shape: ' % (key3d), weights3d[key3d].shape) if 'dense' in key3d: cnt += 1 print('%s is skipped with shape: ' % (key3d), weights3d[key3d].shape) assert cnt == len(weights2d.keys()), 'Not all parameters have been ported, check the initialization.'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
2.3.3 I3D网络结构
具体来说,
I3D使用的是Inception-V1进行3D扩张,模型结构如下图所示,整体改动还是很小的。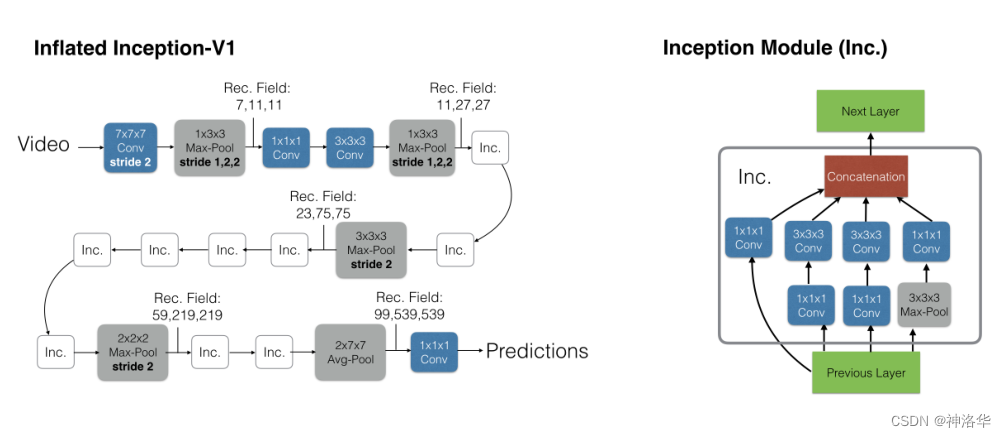
- 左侧是
Inflated Inception-V1结构,就是卷积核都加了一个维度(K*K —> K*K*K,上图蓝色框)。池化层也加了一个维度,但时间维度不进行下采样。比如池化是3*3—>1*3*3而非3*3*3,对应的stride是2*2—>1*2*2*,而非2*2*2*。不过在后面几个阶段进行了时间维度的下采样(后三个池化层) - 右图是
Inception Module,和之前2D结构一样,只是卷积核变为了3D。
之所以使用Inception-V1非ResNet,是因为当年(2016年——2017年),很多视频工作的消融表明,使用I
nception-V1的效果比ResNet更好。但是ResNet统治力是在是太强了,一年后《Non-local Neural Networks》用ResNet实现了I3D模型,并且加入了self-attention。后续大家一般提到I3D,都是指其ResNet实现的版本。最近几年的工作也表明,2D卷积网络扩张到3D时。池化层的时间维度最好不要进行下采样。比如输入是64帧,输出也是64帧,这个对应的实际只有2秒左右,已经很短了。
2.3.4 几种模型结结构对比
下图是将之前讲的五种模型都在
Kinetics 400数据集上进行预训练,再进行测试:
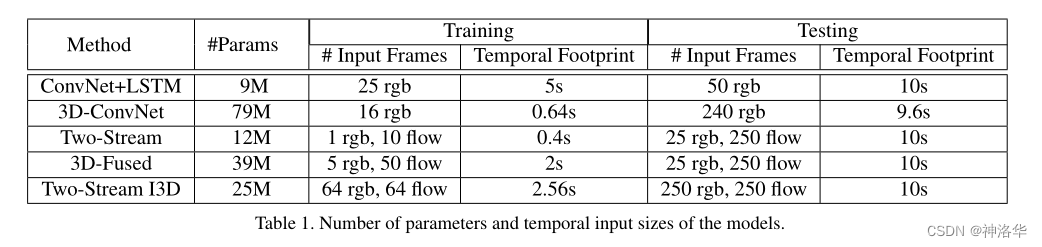
- ConvNet+LSTM:输入是25帧视频帧。作者每1秒取5帧,25帧就是一共5s(fps=25)。
- 3D-ConvNet :输入是16帧,fps=25,所以一共0.64s(输入是连续帧)。
- Two-Stream:任选一帧,然后取剩下的10帧共11帧,计算出10张光流。整个时间跨度是11帧,约0.4s。
- 测试时,
Kinetics 400数据集每个视频都是10s左右。为了保证公平,使用整个视频来做测试,即测试的视频时长都是10s左右。
2.4 实验
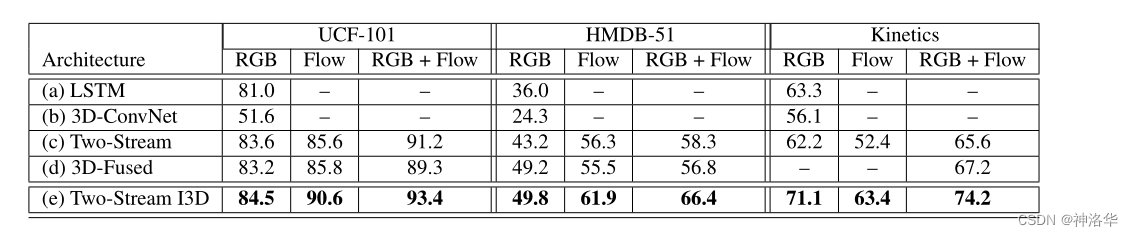
- 对比其他视频处理模型,
I3D效果最好。
下图也可以看到,不论时间流效果比空间流好还是坏,二者结合之后,模型性能都大幅提升,说明光流对2D、3D视频处理网络都非常有帮助
- 只使用
Kinetics 400数据集进行预训练,而不用ImageNet,效果也很好
黑体是top-1精度,括号内为top-5精度
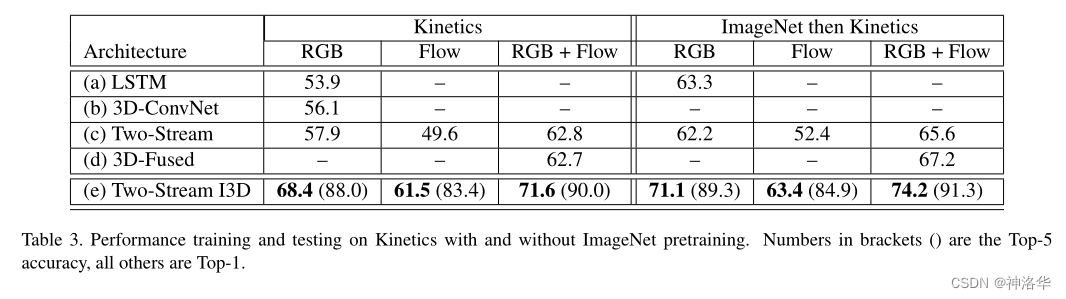
- 对比各种视频处理模型,
I3D效果最好
- 中间蓝色框是之前的3D网络模型效果,可见都比较差。可以说I3D之前的3D视频处理网络都不流行,被光流网络和传统手工特征碾压。
- 下面的I3D模型,对比了单独的空间流
I3D和单独的时间流网络I3D、完整的I3D;以及这三种模型只在Kinetics 400数据集上进行预训练的效果。后面三个模型的效果也不差,说明只用视频数据集进行预训练效果就已经很好了。 - 后续的这种扩展3D模型,可以不再需要使用ImageNet上预训练的模型,直接从头训练就可以了。
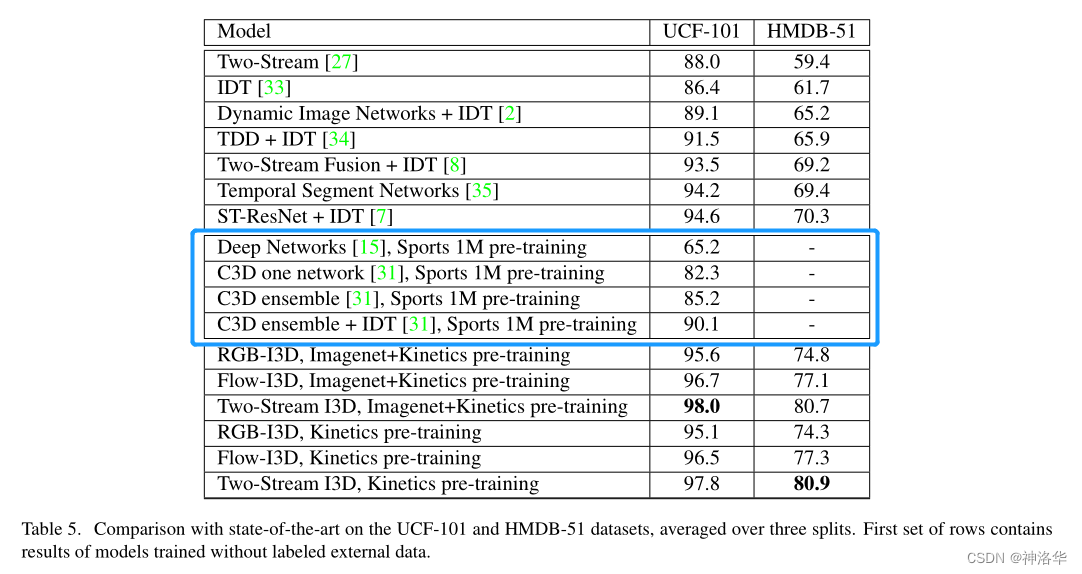
Kinetics 400数据集的迁移效果非常好,证明视频领域,使用预训练模型进行微调的方式效果也是非常好的。
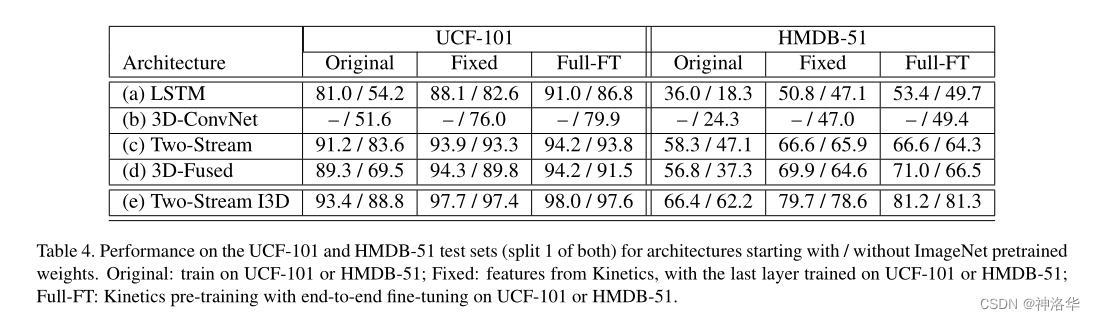
- Original:只在 UCF-101 o或HMDB-51上进行训练,然后测试
- Fixed :在
Kinetics 400上预训练模型,测试时其它层冻住,只训练最后的全连接层 - Full-FT :在
Kinetics 400上预训练模型,测试时整个网络进行微调
以上实验都只是做了视频分类任务。
2.5 总结
本文从两个方面解决了视频模型的训练问题:
- 如果没有好的训练数据,可以使用ImageNet上预训练的模型按本文的方式扩张到3D网络,这样不用设计3D网络结构,而且使用了预训练模型的参数进行初始化,效果一般都很好(
Inflating+Bootstrapping); - 如果你想从头设计一个3D网络,那么可以使用
Kinetics 400数据集进行预训练,是一个不错的选择(不需要依赖于ImageNet预训练的模型参数)。
I3D最大的亮点就是Inflating操作,不仅不用再从头设计一个3D网络,直接使用成熟的2D网络进行扩充就行,而且看还可以使用2D网络的预训练参数,简化了训练过程,使用更少的训练时间达到了更好的训练效果。I3D的最终结果,也超过了之前的2D CNN或者双流网络(UCF101精度刷到98%)。所以自从I3D在2017年提出之后,到2020年,3D CNN基本霸占了整个视频理解领域,双流网络瞬间就不香了,直到vision transformer的出现。 -
相关阅读:
Vue中实现3D得球自动旋转
弹窗组件只能传值一次,并且闪现
设计模式概述
【微信h5】获取用户openid:基于vue3+springBoot
html--旋转眩晕特效
win7下安装nodejs16+
shell实验
mysql 时间字段默认设置为当前时间
Python文件的操作处理,一看就会
Kubernetes面试题分享
- 原文地址:https://blog.csdn.net/qq_56591814/article/details/127873069
