-
分布式锁:不同实现方式实践测评
Hello读者朋友们,今天打算分享一篇测评实践类的文章,用优雅的代码与真实的数据来讲述在分布式场景下,不同方式实现的分布式锁,分别探究每一种方式的性能情况与最终的优劣分析。
开门见山,我们先看一张表格,是由Jmeter测试生成的数据结果,现在不必看懂,本篇文章会从业务场景说起,到分布式锁的引入与分析,相信读完全文后大家就可以融会贯通。
1 总体描述与业务实现
说到分布式锁,我们就会想到分布式架构设计的场景,想到分布式架构设计,一般就认定他是为了高并发高负载的业务而起,想到高并发高负载的业务,我们首先可以想到的就是电商平台的秒杀商品场景,没错,通过逆向推导,我们本次的主要业务就是一个电商平台秒杀商品的场景,在此场景下,我们使用分布式锁用来防止商品超卖这个问题,当然此场景下还有诸多需要解决的问题,但是其余我们在此不会涉及。
1.1 场景描述
本次场景就是一个超级简易版的电商秒杀后端系统,大量用户同时购买库存有限的商品,主要流程就是:
用户进行商品购买,商品系统首先查询库存量,足够时则去到数据库进行库存扣减,而后生成通知订单系统生成订单,最终返回给用户,而库存不够时则直接返回用户提示购买失败,不会经过订单系统,所以正常情况下库存量的数量和生成的最大订单量需一致。
因此,我们重点关注的问题就是
如何在超大请求量的情况下防止出现超卖现象。库存足够:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JmCWkkCU-1669462401391)(一文讲述多种分布式锁性能评测与实践.assets/image-20221123201617972.png)]](https://1000bd.com/contentImg/2024/04/18/14435b8c17864d0b.png)
库存不足:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pCHThOK1-1669462401392)(一文讲述多种分布式锁性能评测与实践.assets/image-20221123201804382.png)]](https://1000bd.com/contentImg/2024/04/18/659a7a7b2b4adfa3.png)
1.2 业务代码实现
安装上面的场景描述,我们使用Go语言+MySQL数据库进行简单的实现:
数据访问层代码:
package dao import ( "database/sql" "fmt" _ "github.com/go-sql-driver/mysql" ) type Book struct { Id int64 `json:"id"` Name string `json:"name"` Price int32 `json:"price"` Store int64 `json:"store"` } type BookDao struct { db *sql.DB tbName string } func NewBookDao() *BookDao { mysqlDB, err := sql.Open("mysql", "root:12345@tcp(127.0.0.1:3306)/test?charset=utf8") if err != nil { fmt.Errorf("Open mysql connection is err %s", err) } return &BookDao{db: mysqlDB, tbName: "book"} } func (dao *BookDao) GetBookById(id int64) (Book, error) { var book Book querySql := fmt.Sprintf("SELECT id,name,price,store FROM %s WHERE id=%d", dao.tbName, id) rows, err := dao.db.Query(querySql) if err != nil { fmt.Errorf("GetBookById Query err %s", err) return Book{}, err } if rows.Next() { err = rows.Scan(&book.Id, &book.Name, &book.Price, &book.Store) if err != nil { fmt.Errorf("GetBookById Scan err %s", err) return Book{}, err } } return book, nil } func (dao *BookDao) UpdateBookStoreById(book Book) error { updateSql := fmt.Sprintf("UPDATE %s SET name=?,price=?,store=? WHERE id=?", dao.tbName) stmt, err := dao.db.Prepare(updateSql) if err != nil { fmt.Errorf("UpdateBookStoreById Prepare err %s", err) return err } _, err = stmt.Exec(book.Name, book.Price, book.Store, book.Id) return err }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
业务层代码:
package service import ( "fmt" "lock_demo/dao" ) var orderCount int32 //记录订单数量 func BuyBook(userName string, buyNum int64) string { bookDao := dao.NewBookDao() book, err := bookDao.GetBookById(1) if err != nil { fmt.Errorf("GetBookById err %s", err) return userName + "购买失败" } if book.Store >= buyNum && book.Store > 0 { book.Store = book.Store - buyNum err := bookDao.UpdateBookStoreById(book) if err != nil { fmt.Errorf("UpdateBookStoreById err %s", err) return userName + "购买失败" } orderCount += 1 fmt.Printf("===%s 购买成功!数量:%d,剩余:%d,订单量:%d ===\n", userName, buyNum, book.Store, orderCount) return userName + "购买成功" } fmt.Printf("===%s 购买失败!数量:%d,剩余:%d,数量不足===\n", userName, buyNum, book.Store) return userName + "购买失败" }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
接口层代码:
package main import ( "fmt" "github.com/spf13/cast" "lock_demo/service" "net/http" ) func RunServer() { http.HandleFunc("/buyBook", func(w http.ResponseWriter, r *http.Request) { username := r.URL.Query().Get("name") buyNum := r.URL.Query().Get("num") resp := service.BuyBook(username, cast.ToInt64(buyNum)) _, err := w.Write([]byte(resp)) if err != nil { fmt.Errorf("write err %s", err) } }) err := http.ListenAndServe(":8081", nil) if err != nil { fmt.Errorf("Http run err %s ", err) } } func main() { RunServer() }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
项目需要添加的依赖(包括将要使用的分布式锁的依赖):
github.com/go-redis/redis/v8 v8.11.4 github.com/go-redsync/redsync/v4 v4.6.0 github.com/go-sql-driver/mysql v1.6.0 github.com/go-zookeeper/zk v1.0.3 github.com/spf13/cast v1.5.0 go.etcd.io/etcd/client/v3 v3.5.5- 1
- 2
- 3
- 4
- 5
- 6
数据库:
CREATE TABLE `book`( `id` int(11) NOT NULL, `name` varchar(255) NOT NULL, `price` double NOT NULL, `store` int(11) NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into book value(1,'Go学习笔记',299,100);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
1.3 问题的产生
为了更直观的看到问题所在,我们先不加锁,启动项目,访问地址:
GET http://localhost:8081/buyBook- 1
加上必要的请求参数
GET http://localhost:8081/buyBook?name=BarryYan&num=1- 1
下面我们打开Jmeter工具,新建测试计划,在测试计划中新建线程组和Http请求,我们的参数为20线程循环100次,由上面的SQL语句我们知道,商品的库存只有1000,但是20*100次的请求会有2000的请求量,去抢购1000个商品,正常来讲一定是有1000个用户因为库存不足买不到商品:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9tLkkPPs-1669462401393)(一文讲述多种分布式锁性能评测与实践.assets/image-20221125191805787.png)]](https://1000bd.com/contentImg/2024/04/18/2e4d388d684b3118.png)
接下来我们启动Jmeter,查看运行项目的控制台,如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dGfey2O5-1669462401394)(一文讲述多种分布式锁性能评测与实践.assets/image-20221125192631584.png)]](https://1000bd.com/contentImg/2024/04/18/e7cd354418554526.png)
等Jmeter执行完成后我们看一下MySQL中还有没有库存:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-01MGPKu0-1669462401395)(一文讲述多种分布式锁性能评测与实践.assets/image-20221125192857046.png)]](https://1000bd.com/contentImg/2024/04/18/d764d4291360f65b.png)
大家可以看到,20*100个请求过后,我们的库存还剩余712,并且订单量也是不正确的,这个问题就是典型的
高并发下线程不安全导致的超卖问题。1.4 分析问题的原因
简述问题的原因,就是在
多线程情况下资源被每个线程都获取一份相同的实例,而后在更新库存时每个线程都更新自身操作后的数据,进而每个线程执行过后产生了相同的数据结果,导致了操作多次后数量未发生改变,举个例子:(1)当前库存900
(2)用户A在D1时间访问数据库看到库存900,用户B在D1时间访问数据库看到库存900
(3)用户A购买1个,库存剩余900-1=899,修改数据库库存为899,用户B也购买1个,库存剩余900-1=899,修改数据库库存为899
(4)此时,数据库剩余库存为899
但是用户A和用户B都获得了订单,库存却只减了1,那么如果D1时间点还有用户C、D、E同时购买呢?结果我们不得而知。
2 分布式锁引入
2.1 分布式锁的概念
先说锁
线程是进程的一个实体,
同一进程下的多个线程可以进行资源的共享,多个线程共享一个资源时则会进行资源的竞争进而引发线程异常。基于此类问题,我们引入锁这个概念,锁,是一种线程中的一种同步机制。
通过加锁我们就可以实现对共享资源的互斥访问。为什么会出现分布式锁?
因为集群环境下,无法避免要把一个项目部署成多个节点,但是数据的一致性导致每个节点访问的数据都是一样的,至此我们可以把每一个项目节点都当做一个线程,整个分布式集群当做一个进程,数据就是多个节点共享的资源,因此难免会引发分布式环境下的多线程问题。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZDZIYfIB-1669462401396)(一文讲述多种分布式锁性能评测与实践.assets/image-20221123205401035.png)]](https://1000bd.com/contentImg/2024/04/18/7905e695aac892f1.png)
2.2 Redis实现分布式锁
package redis_lock import ( "github.com/go-redis/redis/v8" "github.com/go-redsync/redsync/v4" "github.com/go-redsync/redsync/v4/redis/goredis/v8" "time" ) type RLock struct { Mutex *redsync.Mutex } func NewRLock(key string, expire ...time.Duration) *RLock { client := redis.NewClient(&redis.Options{ Addr: "localhost:6379", }) pool := goredis.NewPool(client) rs := redsync.New(pool) option := redsync.WithExpiry(time.Second * 5) if len(expire) == 1 { option = redsync.WithExpiry(expire[0]) } mutex := rs.NewMutex(key, option) return &RLock{Mutex: mutex} } func (r *RLock) Lock() error { return r.Mutex.Lock() } func (r *RLock) Unlock() error { if ok, err := r.Mutex.Unlock(); !ok || err != nil { return err } return nil }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
2.3 etcd实现分布式锁
package etcd_lock import ( "context" "fmt" "go.etcd.io/etcd/client/v3" "go.etcd.io/etcd/client/v3/concurrency" "time" ) type EtcdLock struct { Mutex *concurrency.Mutex } func NewEtcdLock(key string, expire ...time.Duration) *EtcdLock { timeOut := time.Second * 5 if len(expire) == 1 { timeOut = expire[0] } cli, err := clientv3.New(clientv3.Config{ Endpoints: []string{"127.0.0.1:2379"}, DialTimeout: time.Second * 5, }) if err != nil { fmt.Println(err) } s1, err := concurrency.NewSession(cli, concurrency.WithTTL(int(timeOut/time.Second))) if err != nil { fmt.Println(err) } return &EtcdLock{Mutex: concurrency.NewMutex(s1, key)} } func (r *EtcdLock) Lock(ctx context.Context) error { return r.Mutex.Lock(ctx) } func (r *EtcdLock) Unlock(ctx context.Context) error { return r.Mutex.Unlock(ctx) }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
2.4 Zookeeper实现分布式锁
package zk_lock import ( "fmt" "time" "github.com/go-zookeeper/zk" ) type ZkLock struct { ZLock *zk.Lock } func NewZkLock(key string, expire ...time.Duration) *ZkLock { timeOut := time.Second * 5 if len(expire) == 1 { timeOut = expire[0] } c, _, err := zk.Connect([]string{"127.0.0.1:2181"}, timeOut) if err != nil { fmt.Println(err) } lock := zk.NewLock(c, fmt.Sprintf("/zkLock/lock-%s", key), zk.WorldACL(zk.PermAll)) return &ZkLock{ZLock: lock} } func (z *ZkLock) Lock() error { return z.ZLock.Lock() } func (z ZkLock) Unlock() error { return z.ZLock.Unlock() }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
3 实践测评过程与需要注意的问题
以Zookeeper加锁的代码举例:
func RunServer() { http.HandleFunc("/buyBook", func(w http.ResponseWriter, r *http.Request) { username := r.URL.Query().Get("name") buyNum := r.URL.Query().Get("num") zkLock := zk_lock.NewZkLock(username, time.Second*3) err := zkLock.Lock() if err != nil { fmt.Errorf("Lock err = %s",err) w.Write([]byte("购买失败")) return } defer func() { err = zkLock.Unlock() if err != nil { fmt.Errorf("UnLock err = %s",err) } }() resp := service.BuyBook(username, cast.ToInt64(buyNum)) _, err = w.Write([]byte(resp)) if err != nil { fmt.Errorf("write err %s", err) } }) err := http.ListenAndServe(":8081", nil) if err != nil { fmt.Errorf("Http run err %s ", err) } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
实践过程就不是很难了,就是一个加锁和解锁的过程,但是要注意的一些问题:
-
锁过期时间。分布式锁设置过期时间可以确保在未来的一定时间内,无论获得锁的节点发生了什么问题,最终锁都能被释放掉。但是时间也不能过短,防止业务还没有执行完锁就失效了。 -
锁的全局唯一标识。 -
锁的合理释放。我们要考虑在业务执行完成或发生异常时锁也能得到释放。
4 结论
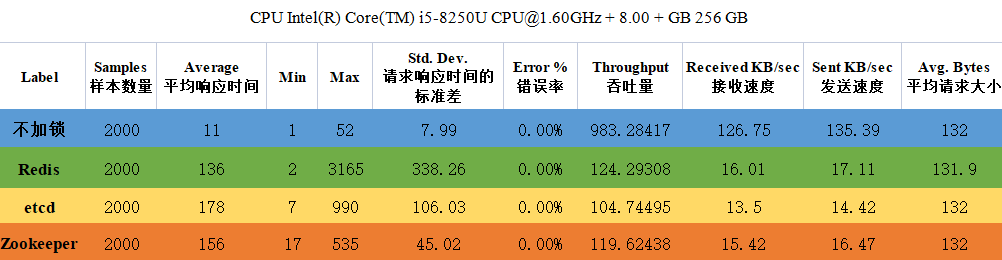
经过Jmeter的分析报告,我们汇总成了一张表格:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IpLthqwY-1669462401397)(一文讲述多种分布式锁性能评测与实践.assets/image-20221123185215876.png)]](https://1000bd.com/contentImg/2024/04/18/3e6a33de0d13c2b3.png)
依照表格我们可以得出结论:
Redis是三者中吞吐量、平均响应时间最优的一种方式,但是相对而言不如Zookeeper更加稳定,etcd在虽然在各个维度都不如Redis和Zookeeper,但是它仍然是一款比较优秀的云原生领域分布式注册中心,在集群环境中,Redis会产生脑裂、主从同步失败等安全问题,etcd则可以很大程度上屏蔽此类问题,所以我们不能只关注表面的数据,同时也要兼顾每个组件背后的原理和安全性。最后,做一个小总结,
分布式锁是一个相对复杂的组件,除了本文所讲述的以外,如果想要更好的使用分布式锁,还需要考虑其背后的诸多问题,比如锁操作的原子性、一致性、可重入性等,这些当然也与不同组件背后的算法相关,由于篇幅有限就没有一一详解,当然除了etcd、Redis、Zookeeper等组件之外,还有许多方式可以实现分布式锁,比如高性能的关系型数据库、MySQL乐观锁等等,都需要我们针对自身的业务进行选择。其实无论是一般的线程锁,还是分布式锁的作用都是一样的,只是作用的范围大小不同。只是范围越大技术复杂度就越大。 -
相关阅读:
ArcGIS基础:点要素分割线要素和提取线要素的交点
哪个问卷工具便于团队作业?
2022-04-07-SpringCloud
cocos creator项目构建问题
Java入门第112课——使用Iterator的hasNext方法、next方法遍历集合
如何在Win10上安装docker
解决docker报eeror: write unix /var/run/docker.sock->@ write:broken pipe
【优化调度】基于与学算法实现库存优化控制问题附matlab代码
算法笔记之蓝桥杯&pat系统备考(2)
【音视频开发】为什么无损音频会有44.1Khz这样的奇葩采样率?
- 原文地址:https://blog.csdn.net/Mr_YanMingXin/article/details/128055915
