-
自知识蒸馏(知识蒸馏二)
自知识蒸馏(知识蒸馏二)
- 自知识蒸馏(知识蒸馏二)
- Born-Again Neural Networks(ICML2018)
- Training Deep Neural Networks in Generations: A More Tolerant Teacher Educates Better Students(AAAI 2019)
- Self-Distillation Amplifies Regularization in Hilbert Space(NIPS2020)
- Adjustable super-resolution network via deep supervised learning and progressive self-distillation(Neurocomputing2022)
- Deep Mutual Learning(CVPR2018)
自知识蒸馏(知识蒸馏二)
因工作需要研究了一下知识蒸馏,选择了一个小领域,自知识蒸馏,进行了调研。
Born-Again Neural Networks(ICML2018)
自蒸馏领域的早期工作之一(应该是第二早的,同时第一次系统提出了标准自知识蒸馏)。思想非常简单清晰效果也很好,在此做简单介绍。(吐槽一下越是经典和简洁有效的工作越好理解,垃圾文章往往要看一堆methods然后靠trick刷分)
文如其题,与传统的知识蒸馏不同,本文的自知识蒸馏将教师网络和学生网络的结构设定为一模一样(或者是具有相同复杂度的不同结构),发现即使如此,学生也能超过从头训练甚至超过老师。
方法
将教师模型的参数设置为 θ 1 \theta_1 θ1,学生模型的参数设置为 θ 2 \theta_2 θ2,那么知识蒸馏可以简洁地表示为:
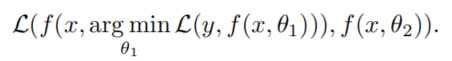
除此之外,作者还选择了连续知识蒸馏,即不断将上一代学生学成后作为新的老师训练后一代学生:
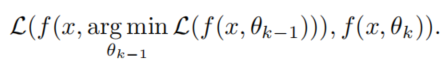
最后还选择了综合所有代的输出平均获得最后结果:
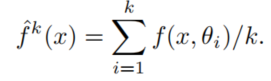
由于采用同样结构重新训练,所以作者成为Born Again Networks(BAN)。特别注意实际训练中有可能会让某些层在教师和学生间共享。为什么有效
作者还尝试将知识蒸馏的“暗知识”进行剖析,甄别出其起作用的部分。
对于教师学生标签的交叉熵损失函数,梯度如下(就是对每一个分项class的概率彼此求交叉熵),推导可以参考这篇(虽然讲的是硬标签的情况):
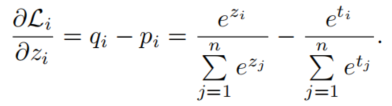
区分正确标签(表示为*)和错误标签(下图中的i)的情况下,公式可以分解为:
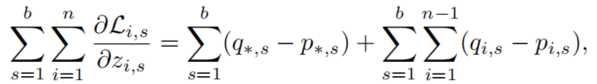
这个函数可以分成两部分,一个是后面的对负标签梯度的修正(即认为加深了对负面标签彼此关系的理解也能帮助模型学习),一个是前面部分的的正确标签,可以改写为对hard-label情况下的基于教师模型预测的样本加权:
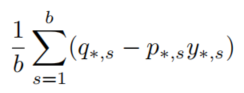
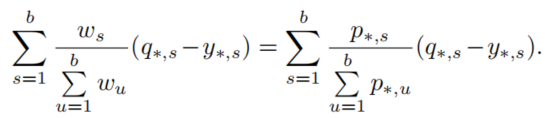
为了验证究竟是暗知识还是样本权重起作用,作者设计了一个实验,模拟了上面的改写,在不进行蒸馏的情况下使用教师模型的最大输出(但是不一定是正确的类吧)加权由one-hot标签的样本训练模型,记为Confidence Weighted by Teacher Max (CWTM):
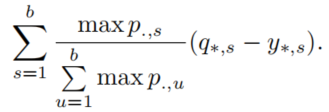
同时,还设计了使用蒸馏的同时,打乱非真实标签的类的概率的实验,记为dark knowledge with Permuted Pedictions (DKPP)。实验结果
这里只看部分,可以看到BAN模型基本都显著高于Teacher模型,同时BAN随着连续知识蒸馏,效果提升仍然存在但逐渐减少(这部分感觉重复不够多,BAN和BAN1的区别只在于随机种子,差距居然可以达到0.66。而ensemble模型的效果果然是最强的。
同时,作者发现最好的结果是不加入真实标签直接用教师输出训练(自然语言任务中则不然,作者猜测可能是因为测试的自然语言任务教师预测的准确性不够,所以相对更需要标签辅助判断)。

同时,CWTM和DKPP情况下的模型仍然表现出了一定的效果。DKPP的结果表面至少暗知识并不是依靠显性的某个负样本的输出,至少也受益于负样本的分布,同时即使没有负样本学习,CWTM也证明了教师模型在平衡样本权重方面的作用和对训练的效果。看来暗知识仍然是综合性的啊。Training Deep Neural Networks in Generations: A More Tolerant Teacher Educates Better Students(AAAI 2019)
这篇也是讲自蒸馏的,主要是改进了教师模型的训练,认为差一点的教师可能可以更好地教学生,因为不那么尖锐的分布可以提供更多类之间的关系信息,这确实是符合知识蒸馏的本意的,不然直接用标签就行了。不过作者的方法实验效果感觉没那么显著,过实验稍微感觉有些不够充分。
Secondary Information
也讨论了上一篇文章,认为BAN对于教师网络的结构分析还不够深入,尤其是缺少考虑了其对class-level similarity的引导作用。作者做了一个实验,分析了born-again process中概率第二大的类和第一大类的关系,如下图,横轴是标签类(似乎不一定是第一大类?)纵轴是第二大类,可以看到教师和学生具有很大的相似性:

说实话考虑到蒸馏损失的形式,我觉得这结果是显然的,不能说明因此对学生有什么帮助,不过作者还是以此为出发点,认为通过一些方法,让学生更好地学习这些class-level similarity的信息就能提高表现。为了实现这一点,作者认为需要平滑模型输出,并测试了三种方法,label smoothing regularization(LSR),confidence penalty(CP)和作者提出的,更针对较相似类的top score difference(TSD):
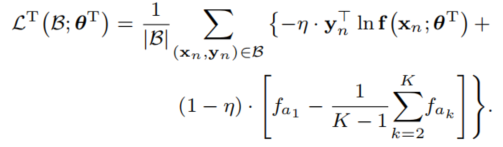
其中 f a k f_{a_k} fak表示第 k k k大的输出概率类。也就是说,该损失希望模型不要太纠结于排名最前的 K K K类彼此之间的差距,甚至是不希望有太大差距。文章中实验作者都取K=5。实验
为了更好验证关于secondary information的假设,作者讲CIFAR100模型的100个类划分成了20个超类,用右上角S表示,普通类则用C表示。作者定义了两个向量(用最后一层特征做平均池化得到)评估超类内部类到超类中心的分布和超类到所有类中心的分布,越大表示区别越大越分散,如下:
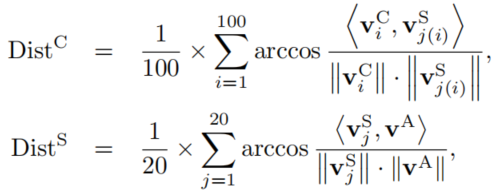
作者仅仅按照baseline和前面提到的三种方式训练不同的Teacher进行训练,两个指标图下:
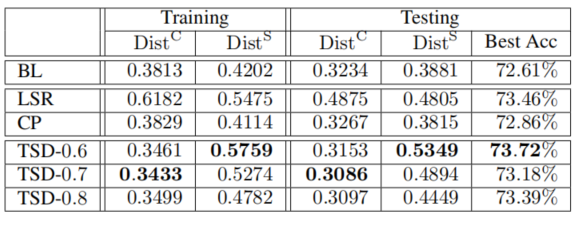
可以看到TSD比较好地实现了自己的目的,超类间尽量分散,类内尽量紧凑(提供更好的相似性信息)。LSR和CP没有考虑类的相似性,所以会造成超类内聚合不不够。最后的准确率也表明了,该模型可以取得好效果。(虽然我感觉区别其实不大)具体到不同的模型配置,用 D ( η , λ ) \mathscr{D(\eta,\lambda)} D(η,λ)来表示不同的TSD模型, η \eta η越大表明teacher模型训练的越严格,为1时就是最baseline的teacher,可以看到基本表现不如稍微不严格的teacher,虽然一开始不严格的老师可能会有比较低的准确率,但是随着蒸馏的代数提升,其优势逐渐显现,不过随着进一步训练,新的教师模型会逐渐自动变得严格。
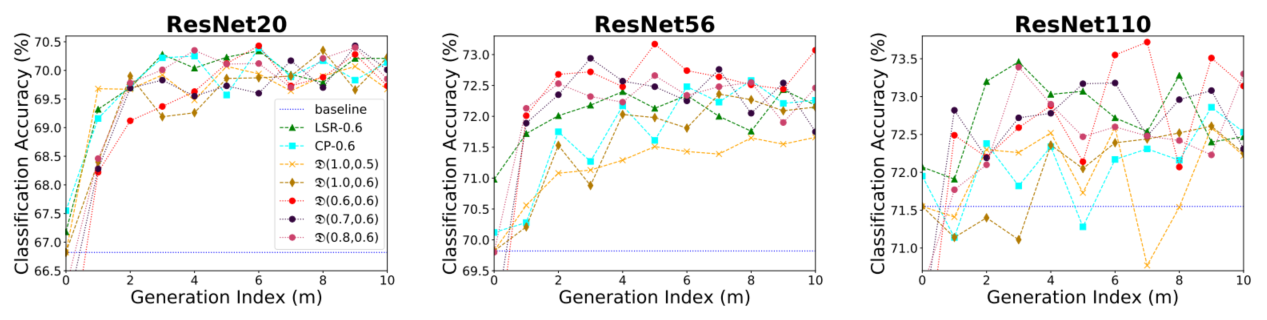
作者还在ImageNet做了实验,不过继承了之前实验的参数,只是证明了该方法相对非自蒸馏方法的有效性。还有一些其它的迁移学习实验,也没有说明什么关键问题。Self-Distillation Amplifies Regularization in Hilbert Space(NIPS2020)
硬核文章,从数学角度解释自蒸馏的效果,将其解释为希尔伯特空间的正则化,数学部分就不写了(主要我也看不懂)。只写结论:自蒸馏可以被视为一种正则化,限制了模型的复杂性。过度使用将会造成欠拟合。作者还比较了自蒸馏和early stop的效果的异同,不过这部分不在我的关注范围了。
实验
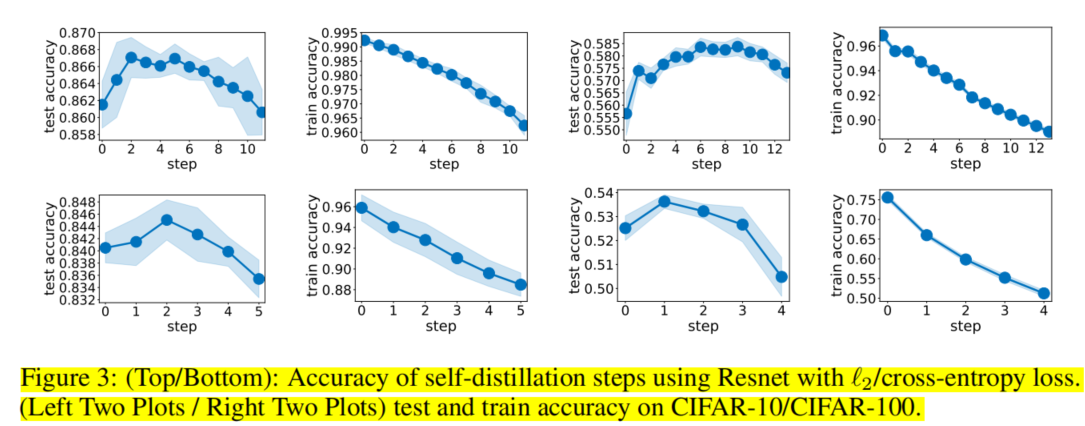
作者在CIFAR-10和CIFAR-100上使用ResNet和VGG模型进行了实验,分别使用了l2损失(数学推导中使用的)和交叉熵损失,随着self-distillation代数的增加,训练准确率下降的同时,测试准确率先上升后下降,符合正则化的特征。VGG结果如下如图。
Adjustable super-resolution network via deep supervised learning and progressive self-distillation(Neurocomputing2022)
单纯随便找的相关领域比较近的工作,也算是将自蒸馏应用到图像分类任务之外的一个尝试。本文提出了一种轻量级的超分网络(Adjustable Super-Resolution Network),并使用了Deep Supervised Learning(DSL)方法(也就是对中间输出也进行监督)和创新性的Progressive Self-Distillation(PSD)策略,也就是逐步自蒸馏方法,进行训练。最终目的是能够动态调整模型的体量和权重而不需要重复训练,就能够适应不同需求下的任务。
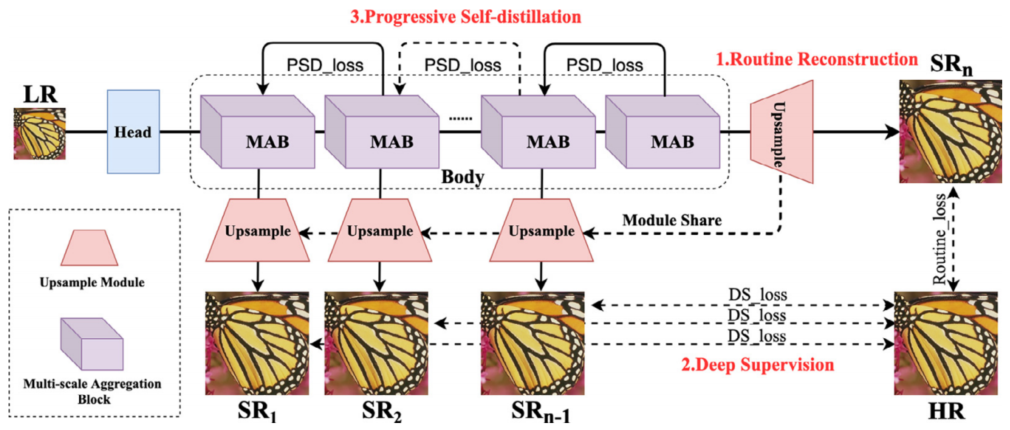
Progressive Self-Distillation(PSD)
我比较关注自蒸馏部分,本文中的自蒸馏采用的是另外一种定义,即一个模型一代训练中不同层之间的蒸馏。因为模型中间不断有输出,可以被视为不同深度的子网络,那么深层的输出用来监督浅层的输出是一个非常好的想法。
值得注意的是因为对于重建任务来说不存在soft-target所以作者采用了对特征而不是图像进行蒸馏。因为重加目标是精确的,所以直接使用教师输出的图像会限制模型性能(不过没看到文献支撑)。
同时,为了减少计算量,作者使用了Attention Transfer,也就是对特征图的通道维度做一定的处理(平均、最大等),本文选择的是绝对值求和。
作者还注意到不同层的注意力实际上区别很大,为了避免模型教师差别过大影响学习效率,模型还限制了每个模型只学习下一层作为教师。这样也减少了计算量。
蒸馏损失如下:
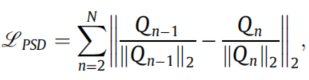
其中 Q n − 1 Q_{n-1} Qn−1是第n-1层的特征图在通道维求和后展平的向量, Q n Q_{n} Qn同理。实验
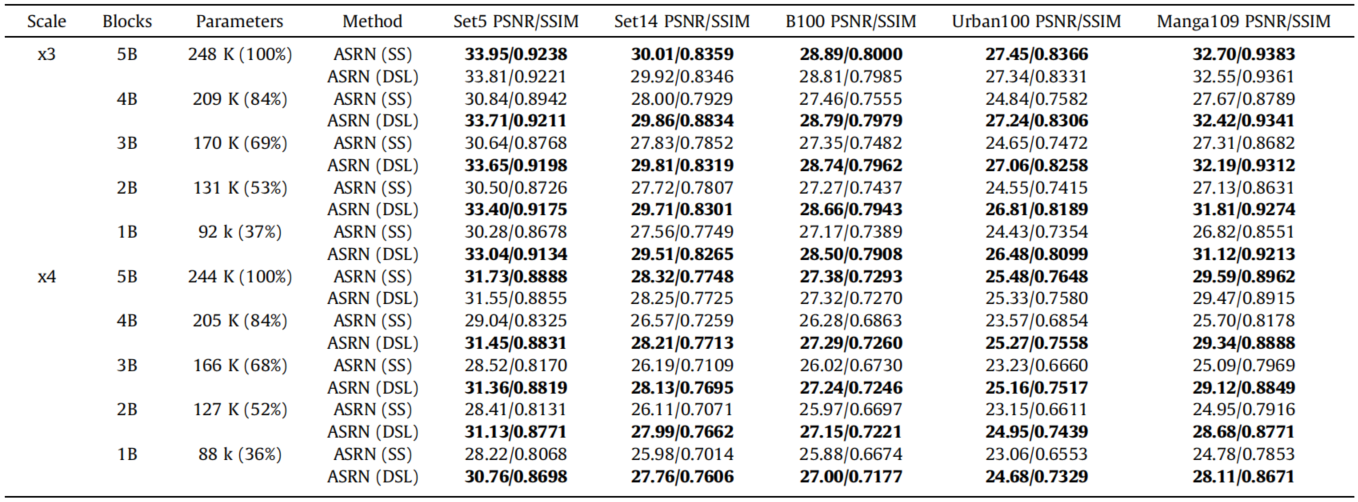
效果就不放了,总之很好。只放针对DSL和PSD的消融实验,SS表示不适用DSL和PSD的普通模型,DSL表示使用了DSL没有使用PSL。
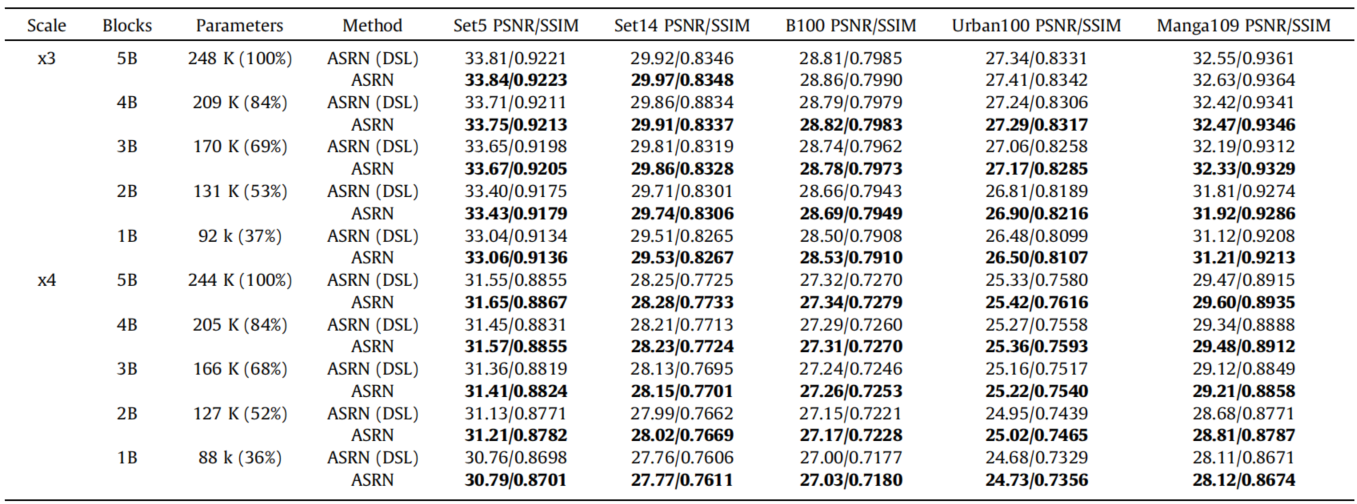
视觉效果展示:

值得注意的是,虽然弹性有了,但是由于其多任务学习的设定,全模型输出的表现还是不可避免地下降了,PSD缓解了这一现象但是无法彻底解决。Deep Mutual Learning(CVPR2018)
虽然和自蒸馏方法有区别,但是原理是类似的,所以我也把它放在一起介绍。和蒸馏方法需要训练好一个模型再进行蒸馏不同,Deep Mutual Learning直接同时训练一堆模型,每一个模型又同时以其它模型的输出结果作为指导进行学习,达到相互学习的效果。作者的实验证明了这种方法对于性能提升的有效性,该方法还可以非常方便地应用到分布式训练中。
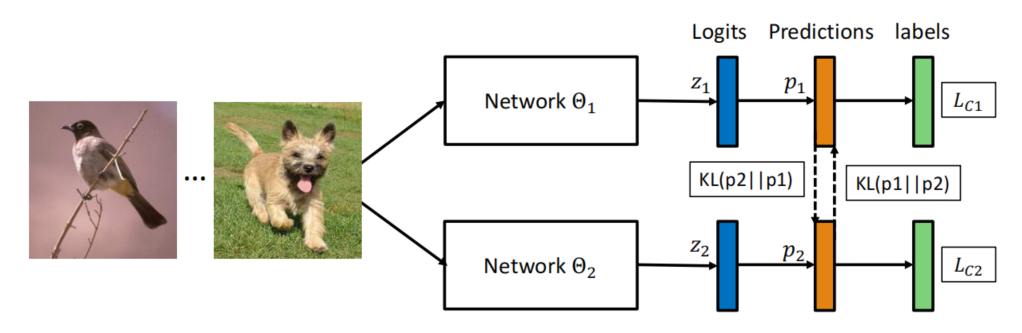
基本方法
下面以两个模型为例介绍Deep Mutual Learnings,假设两个模型 Θ 1 \Theta_1 Θ1和 Θ 2 \Theta_2 Θ2的输出的概率分布为 p 1 ( x ) p_1(x) p1(x)和 p 2 ( x ) p_2(x) p2(x),模型1为例,其监督损失可以表示为:
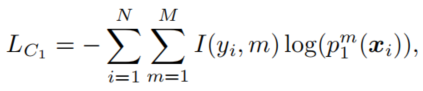
其从其它模型那里学习的蒸馏损失可以表示为模型输出的概率分布的KL散度(当然换成JS散度什么的也可以,实验上没有大区别):
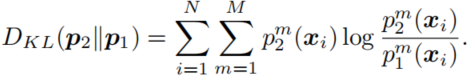
模型2同理,所以损失函数由两项组成:
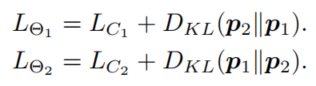
完整的算法流程如下:

变体
对于K个模型相互学习的情况,只需要将损失函数改成:
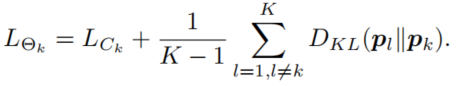
即可,除此之外,作者还尝试了将所有其它预测综合成一个老师进行学习,作者认为这是因为ensemble操作让预测概率分布更加尖锐,虽然有利于预测,但是并不是好老师(暗合前面文章提到的不那么严格的老师更能教好学生):
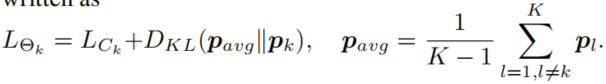
最后,对于半监督学习任务,对有标签的样本可以激活完整的损失函数,而对所有样本都可以使用蒸馏损失函数:
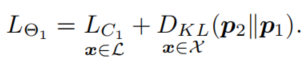
该方法衍生出了交替更新和同时更新两种变体,也就是一个更新完之后另一个蒸馏,还是彼此都在一轮中用更新前的结果来蒸馏。也就是Algorithm1中使用1234还是1324的顺序。实验
作者再分类任务(CIFAR和ImageNet)以及行人重识别任务(Market-1501)上进行了实验,选择了ResNet-32,MobileNet,InceptionV1等网络结构。部分结果如下所示:
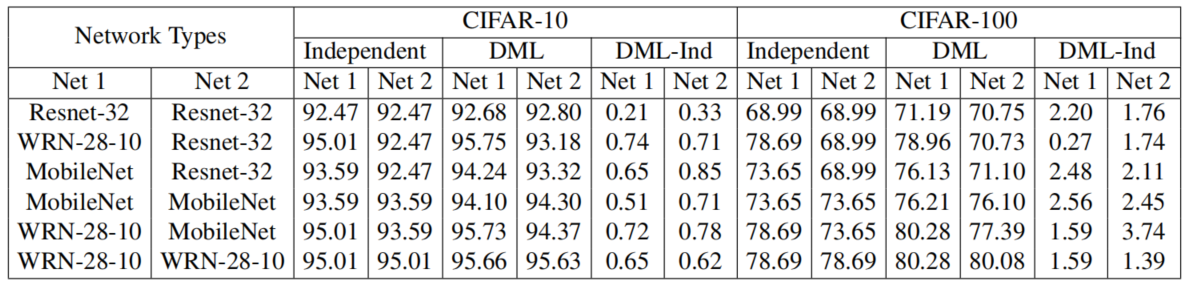
Independent模型就是单独训练,DML就是交互学习训练,DML-Ind是他们的差值。下图还有ImageNet的结果。
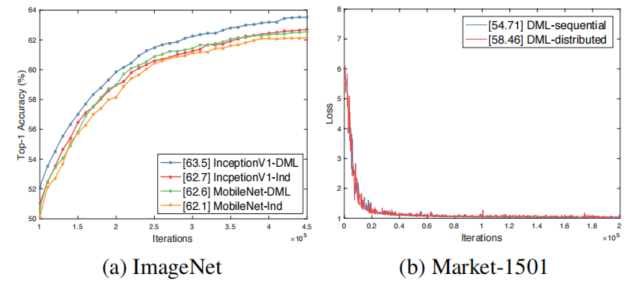
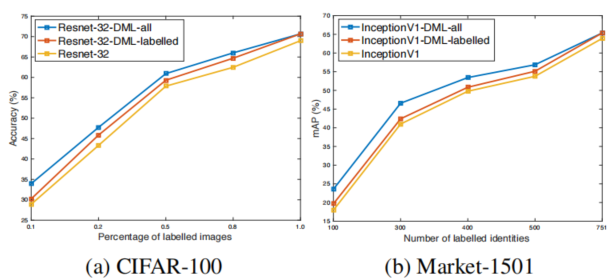
上图中Market1501饰演了迭代更新(Algorithm1顺序1234执行)和同时更新(Algorithm1顺序1324执行),发现后者效果更好,后者中各个学生的优化更加平等,说明了减少学生在学习过程中的差异有利于DML训练(注意不是说结构差异)。此外作者还对比了DML和其它蒸馏方法的对比(两个数据集分别对比Top-1 Acc和mAP):
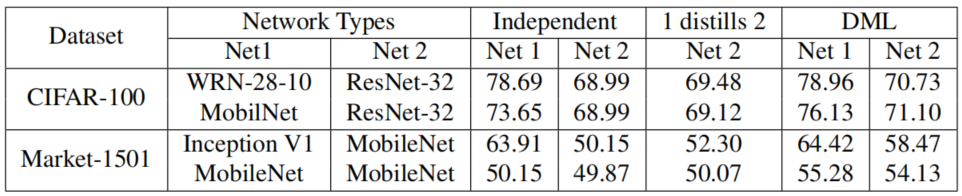
可以看到,蒸馏方法显然好于单独训练,而DML甚至可以超过蒸馏方法。这个结论比较有意思。另外最后一列其实就是类似自蒸馏的设定了,不过似乎没有看到自蒸馏带来的效果提升,可能是因为两个网络不知道初始化是否一致。随着DML中网络数量的增加,结果也在提升:
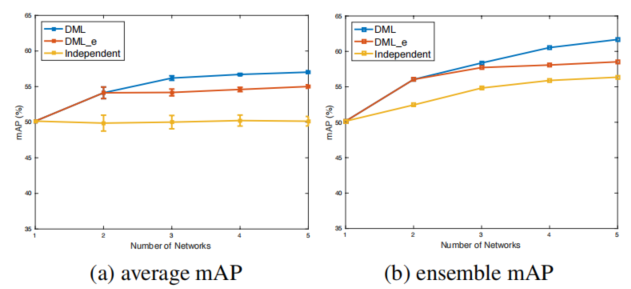
探索
在解释上,和所有蒸馏方法一样,都涉及到神经网络的泛化性分析(注意前面模型的优势是体现在测试集上的),具体而言,蒸馏损失惩罚了预测学生输出为0而教师不为0的部分,使得输出空间更加平滑(熵更大),这样的解在泛化性分析中被认为是更加优秀的。
为了证明这个结论,作者做了几个实验,为输入增加高斯噪声,DML模型的损失变化平缓,计算前几类的预测概率的平均值,DML模型在非首选类中的值高于Independent训练的模型,除此之外,对所有训练样本预测概率的熵求平均,DML模型为1.7099而Independent模型为0.2602。
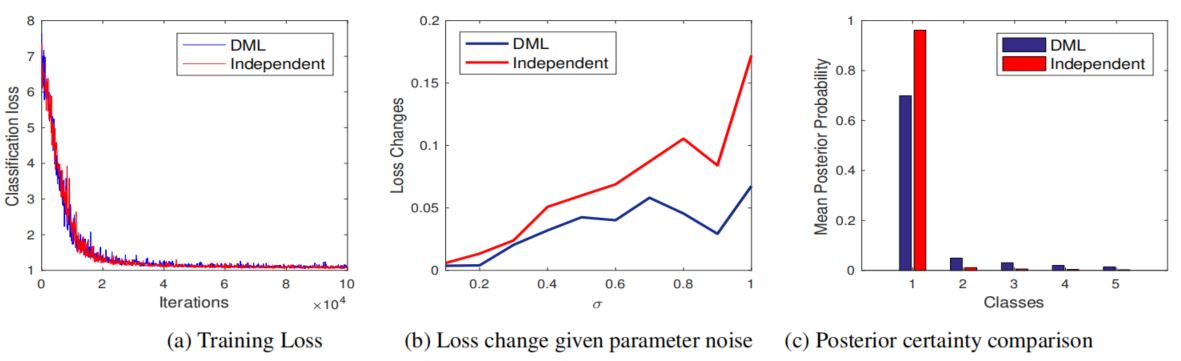
此外,比起为了提高泛化性直接引入熵正则化,DML也有着更好的效果:

此外作者还探索了DML是否会让模型同质化,对MobileNets在Market-1501上的特征做了分析,结论是无论有没有DML,都没有让它们更加相似,这也帮助说明了DML的有效性(每个模型总能学到一些其它模型不知道的):
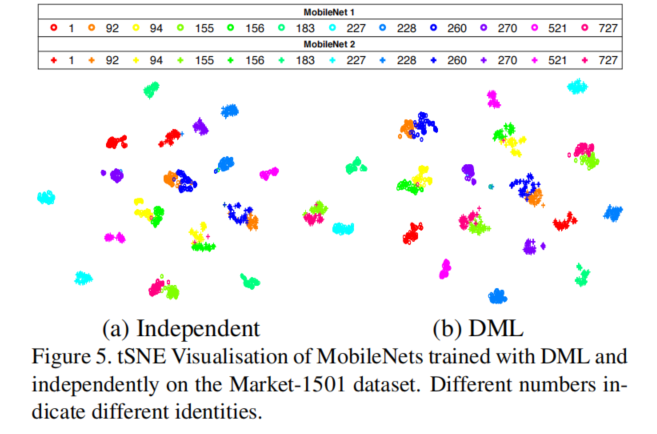
特别注意的是,上述结果也是因为DML没有在特征层面对模型做蒸馏损失,该方法在蒸馏训练好的模型时或许是有效的,但是对DML来说这会导致特征趋同从而削弱网络彼此学习的能力从而影响效果(上表中DML, L2就是对特征做了损失的结果,不如纯DML)。作者对于半监督设置也做了有趣的探索,发现除了监督数据外,对无监督数据进行DML能进一步提升模型的效果,而且在标签有限的情况下,该提升相比于只使用标签数据进行DML要更加显著。这里感慨一下,这篇18年的文章这里的探索几乎摸到了后来大火的无监督学习的边了,换个思路再前进一步就是BYOL,SimSam之类的模型了啊,品析一下它与对比学习的异同也是很有意思的。
-
相关阅读:
2022阿里云金秋上云双十一轻量服务器2核2G 2核4G
【密评】商用密码应用安全性评估从业人员考核题库(七)
浏览器输入URL 到页面加载过程?
多线程之生产者与消费者
javascript解决闭包漏洞的一个问题
狂神说Go语言学习笔记(四)
【总】HEC-RAS学习记录
如何用 vscode 捞出还未国际化的中文词条
【设计模式】行为型设计模式之 备忘录模式(快照模式)
ubuntu中编译ncnn+vulkan
- 原文地址:https://blog.csdn.net/weixin_42939529/article/details/127895750