-
NeRF-SLAM 学习笔记
NeRF-SLAM: Real-Time Dense Monocular SLAM with Neural Radiance Fields
主页:https://deepai.org/publication/nerf-slam-real-time-dense-monocular-slam-with-neural-radiance-fields
论文:https://arxiv.org/pdf/2210.13641.pdf
Code:None
效果:
摘要
We propose a novel geometric and photometric 3D mapping pipeline for accurate and real-time scene reconstruction from monocular images. To achieve this, we leverage recent advances in dense monocular SLAM and real-time hierarchical volumetric neural radiance fields. Our insight is that dense monocular SLAM provides the right information to fit a neural radiance field ofthe scene in real-time, by providing accurate pose estimates and depth-maps with associated uncertainty. With our proposed uncertainty-based depth loss, we achieve not only good photometric accuracy, but also great geometric accuracy. In fact, our proposed pipeline achieves better geometric and photometric accuracy than competing approaches (up to 179% better PSNR and 86% better L1 depth), while working in real-time and using only monocular images.
译文:
提出了一种新的几何和光度3D mapping pipeline,用于从单目图像中精确和实时地重建场景。为了实现这一点,我们利用了密集单目SLAM和实时分层体积神经辐射场的最新进展。我们的见解是,密集单眼SLAM通过提供精确的姿势估计和具有相关不确定性的深度图,提供了正确的信息来实时拟合场景的神经辐射场。通过我们提出的基于不确定性的深度损失,我们不仅获得了良好的光度精度,而且获得了很高的几何精度。事实上,我们提出的mapping pipeline实现了比竞争方法更好的几何和光度精度(高出179%的PSNR和86%的L1深度),同时实时工作并仅使用单目图像。文章工作
- SLAM部分:受到Rosinol等人[23]工作的启发,其中我们将体积TSDF替换为分层体积神经辐射场作为我们的映射表示。通过使用辐射场,我们的方法实现了光度精确的映射,并提高了重建的完整性,同时还允许同时优化姿势和映射。
- NeRF部分:工作通过使用从密集SLAM提供的信息来利用这些见解,该SLAM估计姿势和密集深度图。我们还使用密集SLAM输出在本质上是概率性的这一事实,并且使用在当前方法中通常被丢弃的该信息来加权监控信号以适合辐射场
- 总体而言,工作利用了最近在密集单眼SLAM(Droid-SLAM [31])、概率体积融合(Rosinol等人[23])和基于哈希的分层体积辐射场(Instant-NGP [17])方面的工作,以实时估计场景的几何和光度图,而无需深度图像或姿势。
算法框架
主要思想是利用密集单目SLAM的输出来监督神经元辐射场。密集单目SLAM可以估计密集深度图和相机姿态,同时还提供深度和姿态两者的不确定性估计。利用该信息,可以训练具有由深度的边缘协方差加权的密集深度损失的辐射场。通过使用密集SLAM和辐射场训练两者的实时实现,并且通过并行运行它们,我们实现了实时性能。
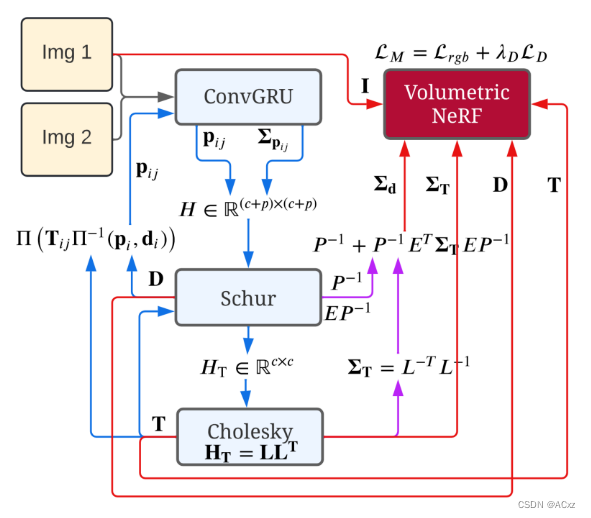
fig 2. 我们的流水线的输入包括顺序的单目图像(这里表示为Img 1和Img 2)。从右上角开始,我们的架构使用Instant-NGP [17]拟合NeRF,我们使用RGB图像I、深度D对其进行监督,其中深度通过其边缘协方差ΣD进行加权。受Rosinol等人[23]的启发,我们从密集单眼SLAM计算这些协方差。在本例中,我们使用Droid-SLAM [31]。我们将在第3.1.蓝色表示Droid-SLAM [31]的贡献和信息流,同样,粉色表示Rosinol的贡献[23],红色表示我们的贡献。Related Work
Dense SLAM
- 实现密集SLAM的主要挑战是:
- 由于要估计的深度变量的剪切量而导致的计算复杂度
- 通过姿态和深度估计解耦而绕过该问题。例如,DTAM [19]通过使用与稀疏PTAM [13]相同的范例来实现密集SLAM,稀疏PTAM [13]以去耦合的方式首先跟踪相机姿态,然后跟踪深度。
- 处理模糊或缺失信息以估计场景的深度,诸如无纹理表面或混叠图像
- 使用提供显式深度测量的RGB-D或激光雷达传感器或简化深度估计的立体相机来避免。
- 由于要估计的深度变量的剪切量而导致的计算复杂度
- 最近关于密集SLAM的研究 :
- CodeSLAM [4]优化了自动编码器的潜在变量,该自动编码器从图像中推断深度图。通过优化这些潜在变量,问题的维数显著降低,同时所得深度图保持密集。
- Tandem [14]能够通过在单目深度估计上使用预先训练的MVSNet型神经网络,然后通过执行帧到模型光度跟踪来解耦姿势/深度问题,从而仅使用单目图像来重建3D场景。
- Droid-SLAM [31]通过使现有技术的密集光流估计架构[30]适应于视觉里程计的问题,可以在各种挑战性数据集(诸如Euroc [5]和TartanAir [34]数据集)中实现有竞争力的结果,Droid-SLAM通过使用下采样的深度图来避免维度问题,所述下采样的深度图随后使用学习的上采样算子上采样。
- Rosinol等人[23]进一步表明,密集单目SLAM可以通过用其边缘协方差对密集SLAM中估计的深度进行加权,并随后将其融合在体积表示中,来重建场景的忠实3D网格。产生的网面在几何上是精确的,但由于TSDF表现法的限制,它们的重新建构缺少光度细节且不完全完整。
NeRF
- Mono-SDF [41]表明,用于从单目图像进行深度和法线估计的最先进深度学习模型提供了有用信息,可显著提高辐亮度场重建的收敛速度和质量。
使用NeRF的SLAM
- iMap [26]和Nice-SLAM [42]随后展示了如何在不需要姿势的情况下,通过部分解耦姿势和深度估计(类似于我们的方法),并通过使用RGB-D图像,构建精确的3D重建。iMAP对整个场景使用单个MLP,而Nice-SLAM利用了对空间进行体积划分的学习,如上所述,以使推理更快、更准确。这两种方法都使用RGB-D相机的深度作为输入,相反,我们的工作只使用单眼图像。
- VolBA [8], Orbeez-SLAM [7] and Abou-Chakra等人[1]也使用分层体积图用于实时SLAM,但是这次来自单目图像。VolBA使用直接RGB损失进行姿态估计和映射。
- Orbeez-SLAM和Abou-Chakra等人使用ORBSLAM [18]提供初始姿态。通过使用密集的单目SLAM,我们的方法既利用了姿态估计的间接损失,已知其比直接图像对准更鲁棒,又具有深度监督辐射场的能力,已知其改善质量和收敛速度。
- 此外,与其他深度监督方法[3,10,11,26,39]不同,我们的深度损失由深度的边缘协方差加权,并且深度是根据光流估计的,而不是由RGB-D相机测量的。
Method
Tracking:带协方差的密集SLAM
我们使用Droid-SLAM [31]作为跟踪模块,它为每个关键帧提供密集的深度图和姿势。从图像序列开始,Droid-SLAM首先使用与Raft [30]类似的体系结构计算帧对i和j之间的密集光流 p i j p_{ij} pij。Raft的核心是一个卷积GRU(ConvGRU,图2),给定帧对之间的相关性和当前光流pij的猜测,计算一个新的流 p i j p_{ij} pij,以及每个光流测量的权重 ∑ p i j \sum p_{ij} ∑pij。
DroidSLAM使用这些流和权重作为测量值,解决了密集束调整(BA)问题,其中3D几何体被参数化为每个关键帧的一组反向深度图。
如fig 2.所示,为了解决线性最小二乘问题,我们采用Hessian的Schur补来计算简化的摄像机矩阵 H T H_T HT,它不依赖于深度,并且具有更小的维数 R c × c R^{c×c} Rc×c。通过采用 H T = L L T H_T = LL^T HT=LLT的Cholesky因式分解,其中L是下三角Cholesky因式,然后通过前代和后代求解姿态T,来解决相机姿态上的所得较小问题。如图2的底部所示,给定这些姿态T,我们可以求解深度d。此外,给定姿态T和深度D,Droid-SLAM提出计算诱导光流,并将其作为初始猜测再次馈送到ConvGRU网络,如fig 2.左侧所示,其中 ∏ \prod ∏和 ∏ − 1 \prod^{-1} ∏−1是投影和反投影函数。fig 2.中的蓝色箭头表示跟踪回路,对应于Droid-SLAM。
然后,受Rosinol等人[23]的启发,我们进一步计算Droid-SLAM中密集深度图和姿势的边缘协方差(图2中的紫色箭头)。为此,我们需要利用黑Hessian的结构,我们如下进行块划分:
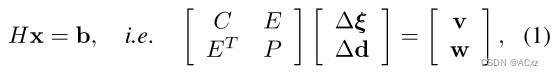
其中H是海森矩阵,B是残差,C是块相机矩阵,P是对应于每关键帧每像素的逆深度的对角矩阵。我们用Δ ξ表示SE(3)中摄像机姿态李代数上的增量更新,而Δ d是每像素逆深度的增量更新。E是相机/深度非对角线Hessian的块矩阵,v和w对应于姿态和深度残差。
根据Hessian的块划分,我们可以有效地计算密集深度 ∑ d \sum_d ∑d和姿态 ∑ T \sum_T ∑T的边缘协方差,如[23]所示:
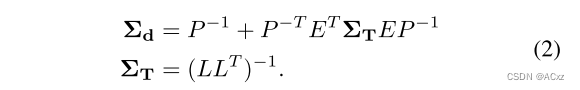
关于如何实时计算这些参数的详细信息,请参见[23]。最后,给定由跟踪模块计算的所有信息-姿态、深度、它们各自的边缘协方差以及输入RGB图像-我们可以优化我们的辐射场参数并同时细化相机姿态。Mapping:概率体积NeRF
给定每个关键帧的密集深度图,可以对我们的神经体积进行深度监督。不幸的是,深度图由于其密度而具有极大的噪声,因为即使是无纹理区域也被赋予了深度值。图3显示了从密集单目SLAM得到的点云噪声特别大,并且包含大的离群值(图3中的顶部图像)。
在给定这些深度图的情况下,监督我们的辐射场可能导致有偏差的重建,如后面第4.4.Rosinol等人[23]表明,深度估计的不确定性是对经典TSDF体积融合的深度值进行加权的极好信号。受这些结果的启发,我们使用深度不确定性估计来加权我们用来监督我们的神经体积的深度损失。图1显示了输入RGB图像、其相应的深度图不确定性、生成的点云(通过 σ d ≤ 1.0 \sigma_d ≤ 1.0 σd≤1.0对其不确定性进行阈值化以实现可视化)以及使用不确定性加权深度损失时的结果。给定不确定性感知损失,我们将映射损失公式化为:
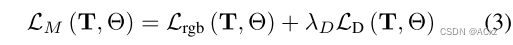
给定超参数 λ D \lambda_D λD平衡深度,我们相对于姿势T和神经参数 Θ \Theta Θ两者最小化。颜色监控(我们将 λ D \lambda_D λD设置为1.0)。具体而言,我们的深度损失由下式给出:

其中 D ∗ D^* D∗是渲染深度, D , ∑ D D,\sum_D D,∑D是由跟踪模块估计的密集深度和不确定性。我们将深度 D ∗ D^* D∗渲染为预期的光线终止距离,类似于[10,16]。通过沿着像素射线对3D位置进行采样,计算样本 i i i处的密度 σ i \sigma_i σi,并对所得密度进行alpha-compositing,计算每个像素的深度,类似于标准体积渲染:

其中di是样本i沿着射线的深度,δi = di+1 − di是连续样本之间的距离。σi是体积密度,通过评价样品i的3D世界坐标处的MLP生成。有关MLP输入的更多详细信息,请参见[17]。最后,Ti是沿着射线直到样品i的累积透射率,定义为:
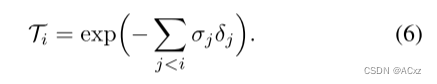
在原始NeRF [16]中,我们对颜色损失进行了定义:

其中 I ∗ I^* I∗是渲染的彩色图像,通过使用体积渲染与深度图像类似地合成。每个像素的每种颜色同样是通过沿着像素的射线采样并对生成的密度和颜色进行alpha-compositing来计算的: ∑ i T i ( 1 − e x p ( − σ i δ i ) ) \sum_iT_i(1-exp(-\sigma_i\delta_i)) ∑iTi(1−exp(−σiδi))是由MLP估计的颜色。对于给定的样本i,同时估计密度 σ i \sigma_i σi和颜色 C i C_i Ci。
映射线程不断地最小化我们的映射损失函数 L M ( T , Θ ) L_M(T,\Theta) LM(T,Θ)。
总体结构
我们的管道由一个跟踪线程和一个映射线程组成,这两个线程都是实时并行运行的。跟踪线程持续最小化关键帧的活动窗口的BA重新投影误差。映射线程始终优化从跟踪线程接收的所有关键帧,并且没有活动帧的滑动窗口。
这些线程之间的唯一通信发生在跟踪管道生成新关键帧时。在每个新的关键帧上,跟踪线程将当前关键帧的姿态及其各自的图像和估计的深度图以及深度的边缘协方差发送到映射线程。只有信息当前在跟踪线程的滑动优化窗口中可用的数据被发送到映射线程。跟踪线程的活动滑动窗口最多包含8个关键帧。只要前一个关键帧和当前帧之间的平均光流高于阈值(在我们的示例中为2.5像素),跟踪线程就会生成新的关键帧。最后,映射线程还负责渲染,以实现重建的交互式可视化。
实施详细信息
我们在Pytorch和CUDA中执行所有计算,并在所有实验中使用RTX 2080 Ti GPU(11 Gb内存)。我们使用Instant-NGP [17]作为我们的分层体积神经辐射场映射,我们对其进行修改,以在等式中添加我们提出的映射损失LM作为我们的跟踪前端,我们使用Droid-SLAM [31],并重新使用它们预先训练的权重。我们使用Rosinol方法[23]计算深度和姿态不确定性,该方法实时计算不确定性。我们使用相同的GPU进行跟踪和映射,尽管我们的方法允许使用两个单独的GPU进行跟踪和映射。
结果
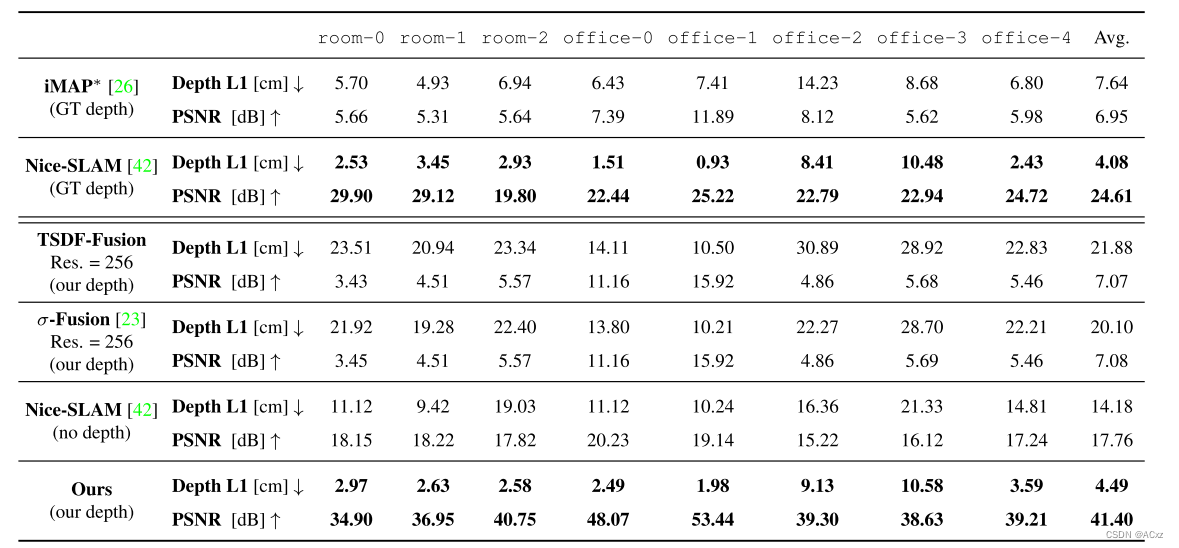
表1.复本数据集的几何(L1)和光度(PSNR)结果。iMAP和Nice-SLAM首先使用来自副本的地面实况深度作为监督进行评估(顶部两行)。当不使用地面实况深度作为比较监督时,我们还评估了Nice-SLAM。TTSDF-Fusion, σ-Fusion和我们的方法使用来自密集单目SLAM的姿态和深度进行评估。
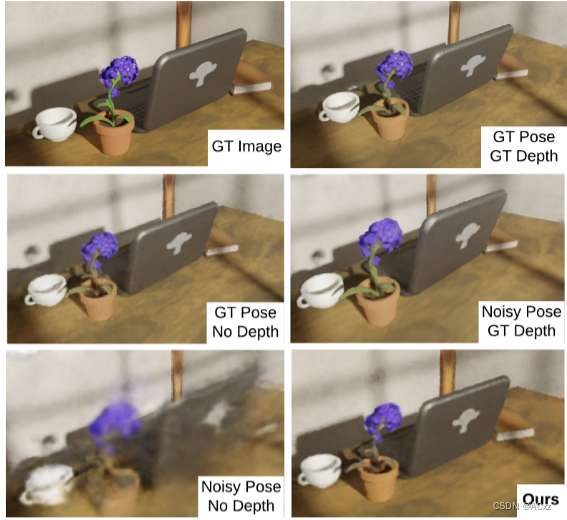
-
相关阅读:
记录数据库备份与检查脚本
错题汇总11 12
day14 - 提取图像信息
uni-app基于vite和vue3创建并集成pinia实现数据持久化
概率模型校准
kafka、rabbitmq 、rocketmq的区别
洛谷 P1948 / loj 10074 / 一本通 1496【分层图】
软件测试误区
期末前端web大作业:餐饮美食网站设计与实现——HTML+CSS+JavaScript美食餐饮网站 3页面
使用poi操作excel详解
- 原文地址:https://blog.csdn.net/pylittlebrat/article/details/128051040