-
卷积神经网络——李宏毅机器学习笔记
以Image Classification为例
第一个解释角度:
先将不同尺寸的image,rescale成大小一样的尺寸,再丢到model中。
下图中,我们希望Cross entropy 越小越好

在计算机视角下的图片:
3 channels 对应R G B三个通道
随着模型参数的增多,全连接层网络的弹性越大,overfitting的风险越大
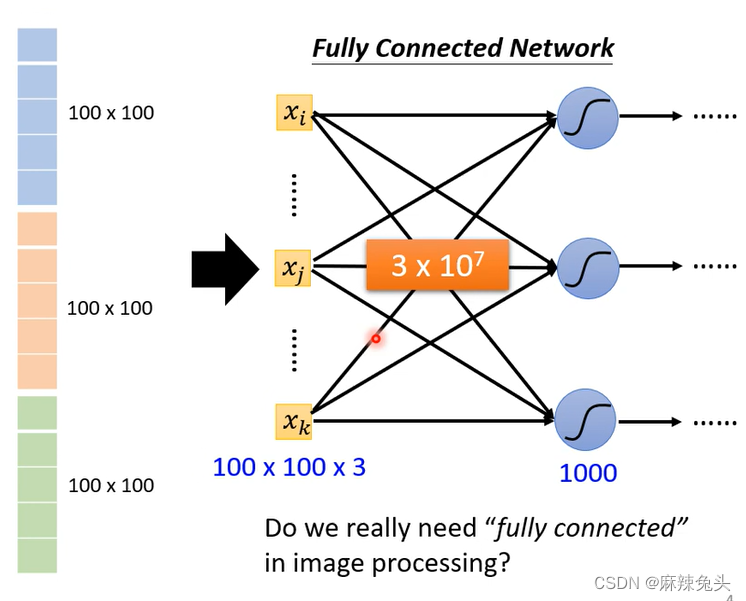
那么怎么避免在做图像识别参数过多的问题?
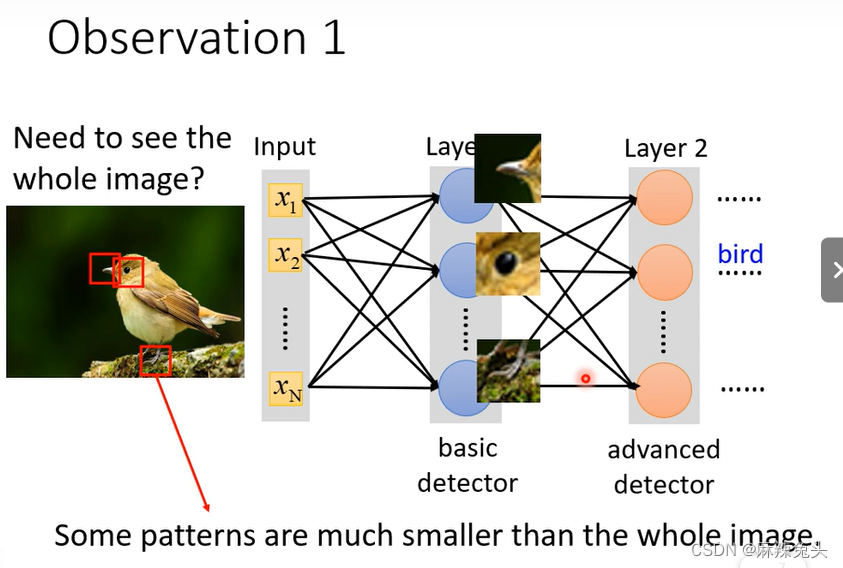
我们没有必要考虑每一个neuron跟input的每一个dimension都有一个weight。Observation 1:
我们并不需要观察整张图就可以辨别出图片中是一只鸟。所以我们可以使用整张图片的一小部分当成输入,就足以识别出某些特别的Pattern。
因此可以做第一个简化:
每一个neuron只考虑自己的receptive field


一个receptive field 可以有多个neuron

可以,receptive field都是可以自己设计的,但是要想想看自己为什么要这样做。经典的做法:
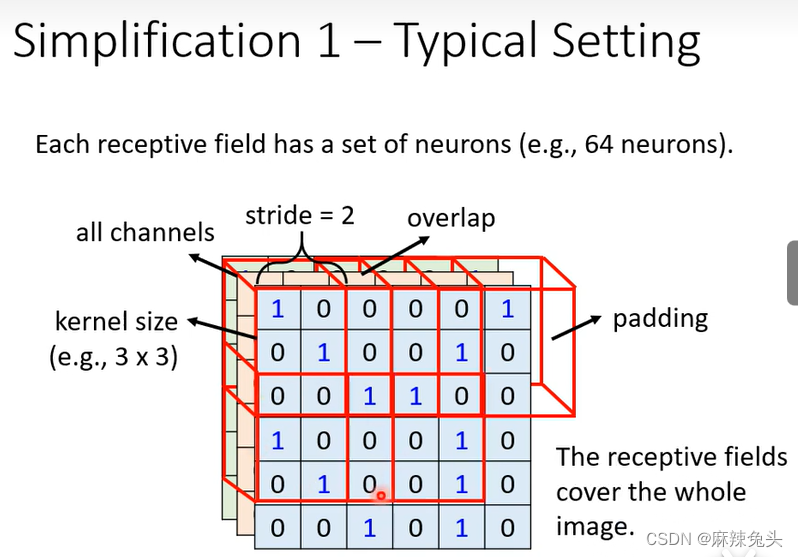
(1)all channels;
(2)kernel size 一般设3*3;
(3)一个receptive field对应一组neuron(例如 64 neurons)
(4)stride往往1或2;
我们往往希望Receptive field 之间有高度的重叠,因为如果两个receptive field没有重叠,而pattern出现在两个receptive field交界处,从而没有neuron去侦测他,这样就会miss掉这个pattern
(5)padding;Observation 2:
图片中有same patterns,所以没必要在每一个pattern设置neuron,可以共享参数。


经典的做法:

(1)每一个receptive field有一组参数;
(2)每一个receptive field共享参数;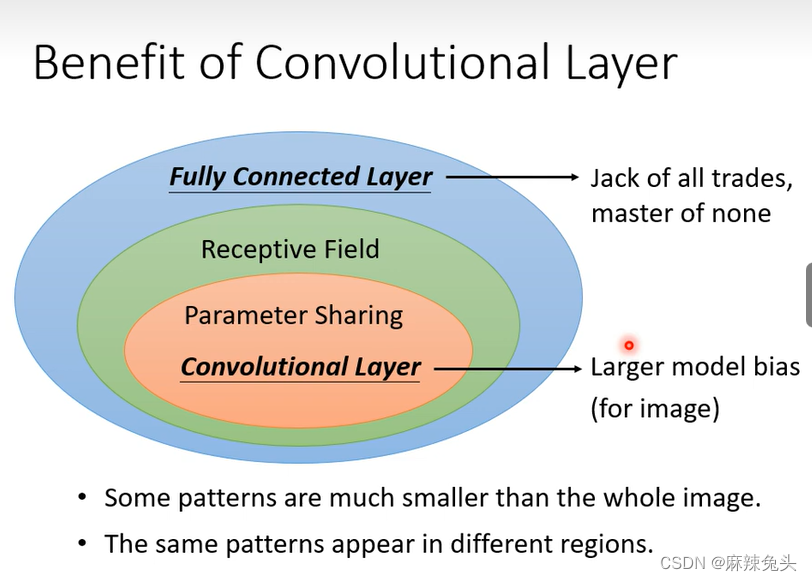
相比全连接层,cnn的model bias很大,但由于cnn是特别为图像设计的,所以他依然能在影像上做到很好,但影响之外的任务就不一定了。第二个解释角度:
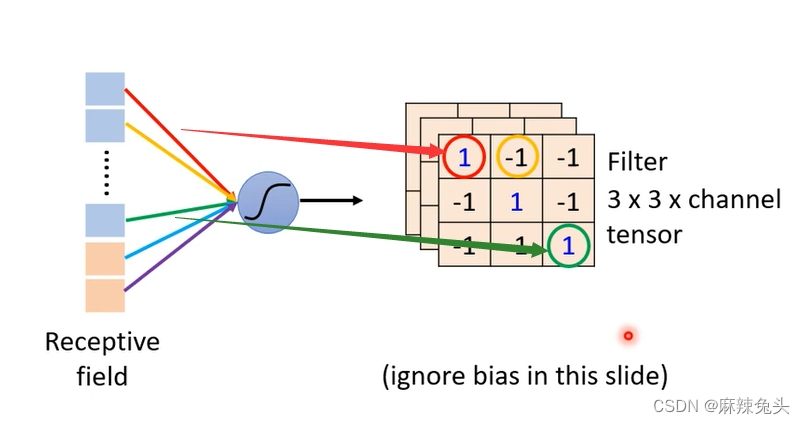
Another story based on filter
每一个filter去图片里抓取pattern
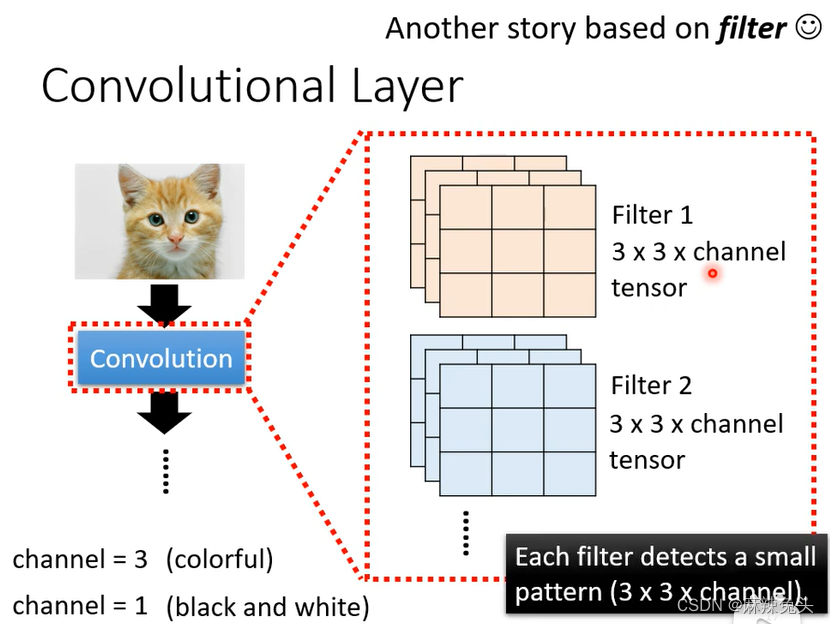
例子:
(1)假设channel=1;
(2)假设filter中的参数已知(实际上filter中的参数是需要训练出来的);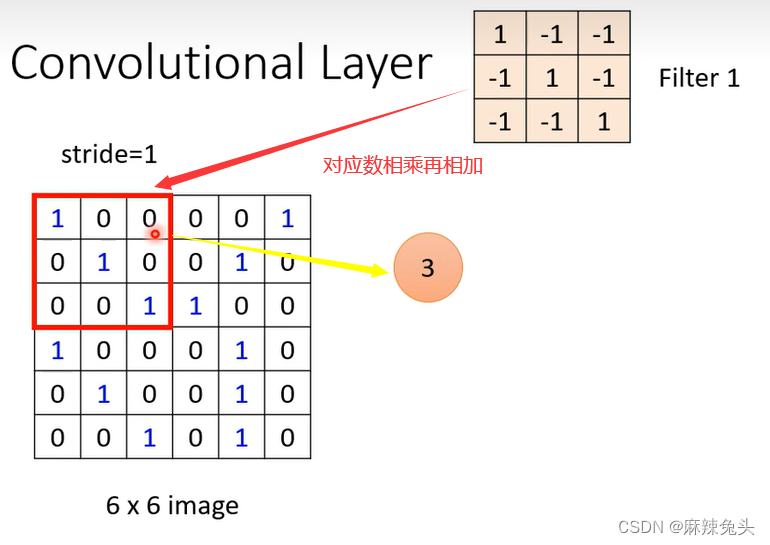
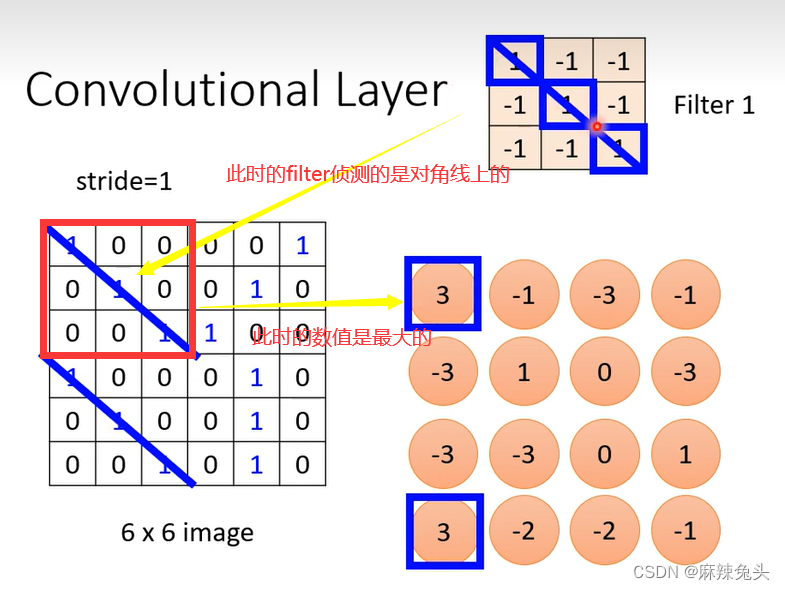
对每一个filter做同样的操作

将feature map可以看做一张新的图片,有64个channel,注意第二层filter的大小高度为64

如果我们的filter一直设33会不会让我们的network无法看比较大范围的pattern呢?
不会
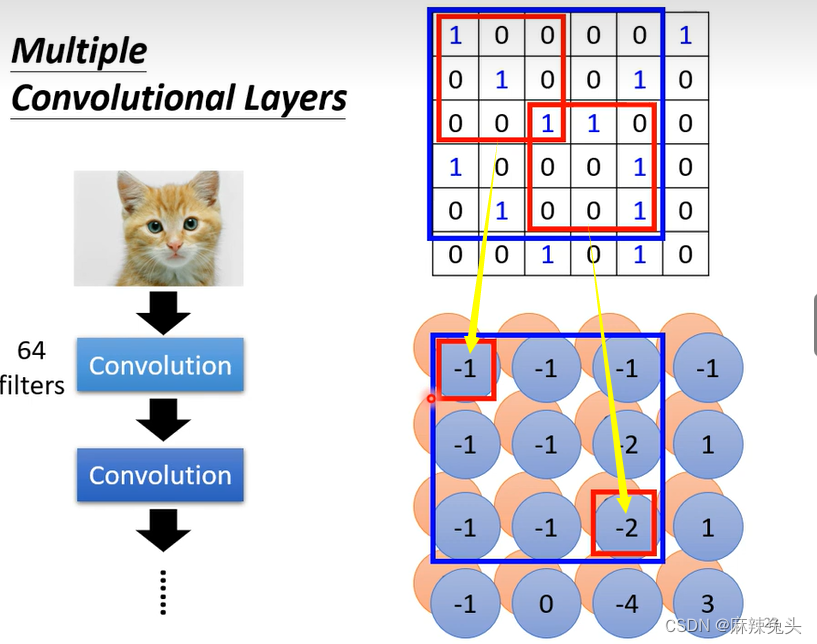
左上角的这个数值,在影像上对应的是33的范围,下面33的范围,对应影像上55的范围。从而,也就是说叠的深度越深,所覆盖的范围越大。Comparison of Two Stories


Observation 3:
把奇数的column、偶数的row都拿掉,图片变为原来的1/4,但是不会影响里面是什么东西。


Max Pooling:选filter最大的一个


pooling最主要的作用是把图片变小,减少运算量,所以如果计算资源足够的话可无pooling。
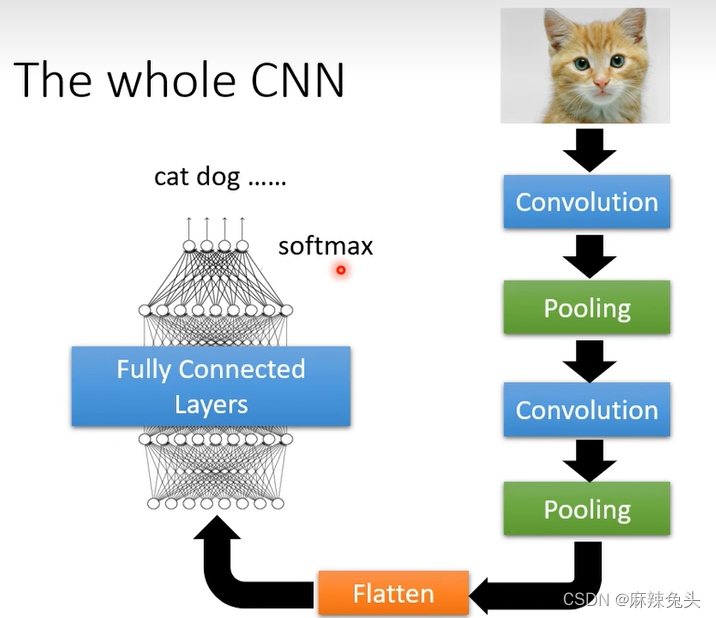
CNN应用:
此例子不需要Pooling
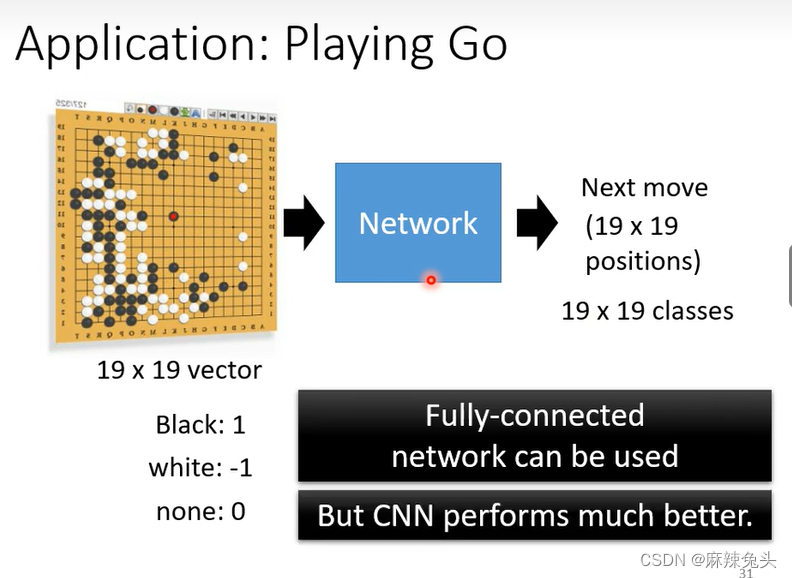
虽然可以使用FCN,但是CNN效果更好
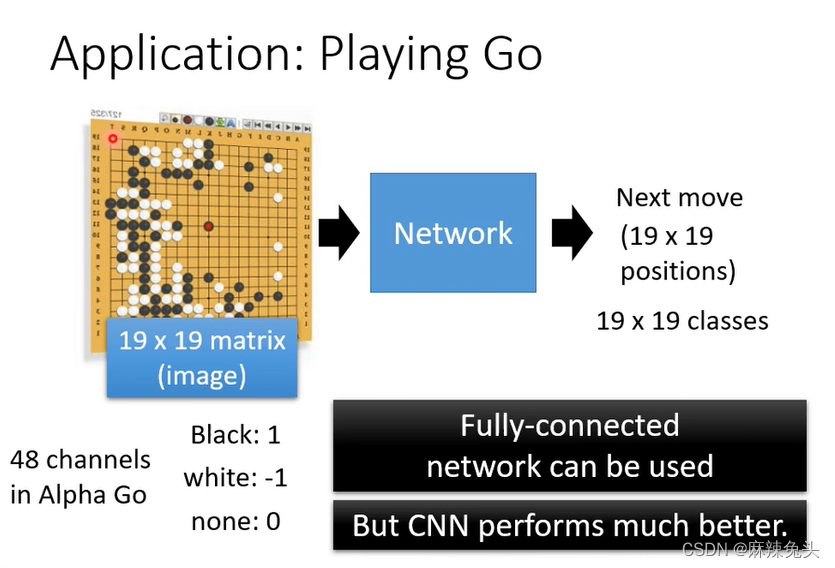
48 channels:每一个位置有48个状态。



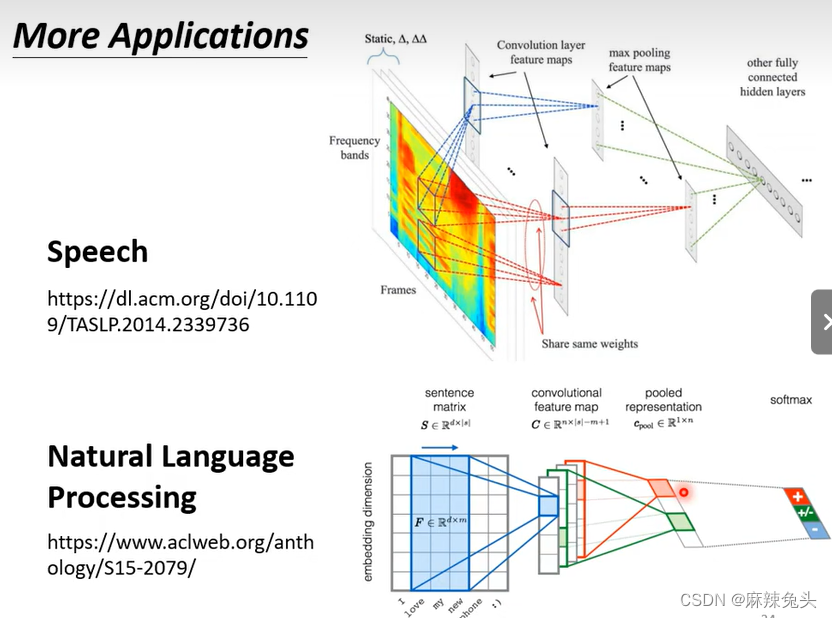
CNN并不能处理影像放大缩小或旋转问题。 -
相关阅读:
linux入门到精通-第四章-gcc编译器
linux软件安装
2024.4.6学习笔记
Python:实现radix sort基数排序算法(附完整源码)
如何用AB测试完善产品激励体系
开源两个月总结
企业化运维(5)_mysql数据库
开源软件:推动软件行业繁荣的力量
Qt 中模型视图编程的基本概念
MicroPython RP2040点灯实验
- 原文地址:https://blog.csdn.net/overload_/article/details/128023825