-
数据库的常用操作
数据库的分类
数据库大体可以分为 关系型数据库 和 非关系型数据库
关系型数据库:是指采用了关系模型来组织数据的数据库,关系模型指的就是二维表格模型,关系型数据库都基于标准的SQL,只是内部一些实现有区别
常见关系型数据库有:Oracle、 MySQL、SQL Server、SQLite
非关系型数据库:不规定基于SQL实现,现在更多是指NoSQL数据库
常见非关系型数据库有:redis、mongodb
关系型数据库的概念
数据库有客户端和服务端两端,客户端和服务端是通过网络进行数据交互的(不一定要用外部网络)
我们自己电脑的客户端和服务端都是在主机上的,在硬盘上存储着数据
我们数据库中所有的数据都是存储在服务端上的
使用数据库的数据时,数据库一般都是把数据放在外存(硬盘)上,但也有少数数据库把数据放在内存中(例如redis)
数据库这个词既可以指各种的数据库软件(MySQL、Oracle),也可以指逻辑上的数据集合(也就是一个数据库软件中的每一个子数据库)
关系型数据库服务器中包含了许多的数据库(此处数据库表示逻辑上的数据集合),每一个数据库中包含了很多的数据表,数据表中包含了很多的行(记录),行(记录)中包含了很多的列(字段)
非关系型数据库一般是按照"文档"或"键值对"方式存储的
MySQL的安装
1、安装MySQL安装包
2、配置环境变量Path:在里面添加MySQL文件夹下bin目录的路径
登录MySQL
命令:mysql -u root -p密码
MySQL的客户端和服务端都在主机上
SQL命令行输入技巧
1、使用上下方向键,可以快速找到上一条/下一条SQL语句
2、如果某个SQL语句输入了一半,不想执行了,可以按ctrl+c来中止
常用数据类型
数值类型
数据类型 大小 说明 对应的java类型 bit[(M)] M指定位数,默认为1 二进制数,M范围从1到64,存储数值范围从0到2^M-1 常用Boolean对应BIT,此时默认是1位,即只能存0和1 tinyint 1字节 Byte smallint 2字节 Short int 4字节 Integer bigint 8字节 Long float(M,D) 4字节 单精度,M指定几位数字(包括小数),D指定小数位数,会发生精度丢失 Float double(M,D) 8字节 双精度,M指定几位数字(包括小数),D指定小数位数,会发生精度丢失 Double decimal(M,D) M/D的最大值+2 双精度,M指定几位数字(包括小数),D表示小数点位数,精确数值 BigDecimal numeric(M,D) M/D的最大值+2 和decimal一样 BigDecimal 上述的数值类型可以指定为无符号(unsigned关键字),表示不取负数,能表示更大范围的数字,但是unsigned比较坑,官方都快废弃了,不推荐使用
1、有符号范围:-2^(类型字节数*8-1)到2^(类型字节数*8-1)-1,如int是4字节,就是-2^31到2^31-1
2、无符号范围:0到2^(类型字节数*8)-1,如int就是2^32-1
字符串类型(SQL中字符串使用单引号或双引号均可)
数据类型 大小 说明 对应的java类型 varchar(size) 0-65535字节 可变长度字符串,size表示字符串最多能包含多少个字符(不是字节) String text 0-65535字节 长文本数据 String mediumtext 0-1677 7215字节 中等长度文本数据,它比长文本数据还长 String blob 0-65535字节 二进制形式的长文本数据 byte[] 文本文件和二进制文件区别:文件中存储的是二进制形式的数据的就是二进制文件,文件中存储的是文字形式(我们能看懂的)的数据的就是文本文件,简而言之就是文件中存储的是我们能看的懂的真实数据就是文本文件,存储的是我们看不懂的二进制/加密数据的就是二进制文件
日期类型
数据类型 大小 说明 对应的java类型 datetime 8字节 范围从1000到9999年,不会进行时区的检索及转换 java.util.Date、java.sql.Timestamp timestamp 4字节 范围从1970到2038年,自动检索当前时区并进行转换 java.util.Date、java.sql.Timestamp 一般常用的类型:int、bigint、double、decimal、varchar、datetime
now函数:获取当前时间可以使用 now() 这个函数进行获取
标准时间格式:'YYYY-MM-DD HH:mm:ss' //例如 '2022-08-02 00:00:00',可以使用<>=等运算符对其进行比较,它是一个时间类型,只不过是按照字符串形式插入的
数据库的操作(SQL语言)
SQL语言的每个单词之间至少有一个空格,末尾要带有英文;分号,SQL不区分大小写,数据库的操作是相对低效的,SQL语言是数据库的客户端和服务端交互的语言
SQL语言不能使用关键字(例如create)来作为数据库名/表名/字段名,如果非要用关键字命名,可以使用`关键字`这种语法来使用(`就是反引号,是tab上面那个键),数据库中不可以定义名字相同的表,命名可以使用驼峰命名和下划线命名的方式
SQL删除数据都是逻辑删除,也就是要删除数据的时候,并不是把这些盘块上的数据给涂抹掉~~而是简单的标记成"无效"~~,标记成"无效之后",这个盘块就会被系统后续分配给其他程序来保存数据~~但是在盘块被分出去之前,上面原来的数据其实还是存在的~~还是有机会找回的(不一定能找回全部)~~
数据库默认的字符编码集是拉丁文的(latin1),不支持汉字,如果想要输入汉字需要更改数据库的字符编码集为utf-8,utf-8是变长编码,能表示全世界所有语言的文字,它是当下最主流的字符编码方式
SQL语言中,因为没有字符类型,因此使用单引号' '和双引号“ ”都可以用来表示字符串
以下所有的[]都是可选的意思
数据库(逻辑上的数据集合)的操作
显示当前所有的数据库:show databases;
创建数据库:create database 数据库名 [character set 字符编码集名];
选中数据库/使用数据库:use 数据库名;
删除数据库:drop database 数据库名;
数据表的操作(表操作之前要选中/使用指定的数据库)
创建表:create table 表名 (列名 类型,列名 类型.....); //可以在列名与类型的后面加上 comment ‘内容’ 表示注释,也可以用 -- ‘内容’ 表示注释
查看当前数据库有哪些表:show tables;
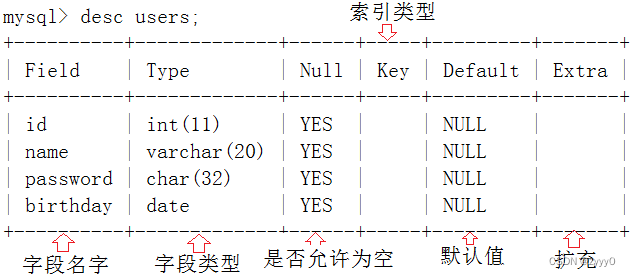
查看表结构:desc 表名;
删除表:drop table 表名;
数据的增删改查
CRUD 即增加(Create)、查询(Retrieve)、更新(Update)、删除(Delete)四个单词的首字母缩写
增
插入数据:insert into 表名 values (值,值.....); //这里值的类型和个数要与表的列的类型和个数匹配
指定列插入数据:insert into 表名 (列名,列名...) values (值,值.....);
一条语句插入多个数据:insert into 表名 values (值,值.....) , (值,值.....); //一条语句插入三行记录,效率比一行一行插入高(因为插入时有额外的工作)
将查询结果插入到表中:insert into 表名 [(列名,列名...)] 查询语句; //要求查询结果的列和插入表的列相匹配
查(这些查询方式都是可以结合在一起使用的)
这些查询方式都可以结合在一起使用,达到复杂SQL语句的效果
全列查询(查询出当前表所有的行和列):select * from 表名; //*表示所有的列,此语句在数据量非常大的情况下,是一个危险操作
指定列查询:select 列名,列名... from 表名;
查询带表达式(列和列运算):select 列名+10,列名+列名 from 表名; //所有的查询都是临时表,它只会影响到数据展示,对于数据库服务器中的原有数据没有任何影响
列名起别名:setect 列名 as 别名 , 表达式 as 别名 from 表名;
查询去重:select distinct 列名,列名... from 表名; //如果去重的列只有一列则是把这列数据去重,如果去重的列是多列则是多个列对照去重(自己的列中不去重)
查询结果排序:select 列名,列名 from 表名 order by 列名1[desc],列名2 [desc]; //按照order by后面指定列来排序,默认是升序排序,desc则是降序排序,先按列名1排序,列名1相同再按列名2排序
条件查询:select 列名 from 表名 where 条件语句; //条件查询语句先执行条件语句where,再执行查询语句,因此where不能使用查询语句中的别名,条件查询是需要遍历表的,在表很大的时候,条件查询还是比较低效的
比较运算符 说明(运算符优先级问题建议多加括号) >, >=, <, <= 大于,大于等于,小于,小于等于 = 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL <=> 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE !=,<> 不等于 between a0 and a1 范围匹配[a0, a1]闭区间,如果 a0 <= value <= a1,返回 TRUE(1) in(值,值.....) 如果当前值是()括号中的任意一个,返回 TRUE(1) is null 是 NULL 返回 TRUE(1) is not null 不是 NULL 返回 TRUE(1) like 模糊匹配,即只要是符合通配符的匹配规则的就可以,% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符,它比较低效 逻辑运算符 说明(运算符优先级问题建议多加括号) and 多个条件必须都为 TRUE(1),结果才是 TRUE(1),and优先级比or高 or 任意一个条件为 TRUE(1), 结果为 TRUE(1) not 条件为 TRUE(1),结果为 FALSE(0) 分页查询:
select 列名 from 表名 limit N; //查询前N条记录
select 列名 from 表名 limit N offset M; //从第M条记录开始,查询N条记录(M从0开始算)
select 列名 from 表名 limit M,N; //从第M条记录开始,查询N条记录(M从0开始算),和上面一样
聚合查询(行和行运算):
SQL中提供了一些函数,通过这些函数就可以进行行和行的运算
聚合查询写法:select 函数(参数) from 表名; //聚合函数可以用在任意位置(只要语法合理即可)
函数 说明 count 返回查询到的数据的数量 sum 返回查询到的数据的总和,不是数字没有意义 avg 返回查询到的数据的平均值,不是数字没有意义 max 返回查询到的数据的最大值,不是数字没有意义 min 返回查询到的数据的最小值,不是数字没有意义 分组查询:
select中使用group by子句可以对指定列进行分组查询,分组就是值相同的列(字段)为一组,分组需要满足:使用group by进行分组查询时,select指定的字段(列)必须是“分组依据字段”,其他字段若想出现在select中则必须包含在聚合函数中,分组后进行运算是以每组的数据进行运算的
如果直接使用select * from 表名 group by 列名; 的话,显示的是分组后每组第一条数据,这是不合理的
分组查询写法:select 指定列名,函数(参数) from 表名 group by 指定列名;
分组前筛选写法:select 指定列名,函数(参数) from 表名 [where]... group by 指定列名; //先筛选,后分组
分组后筛选写法:select 指定列名,函数(参数) from 表名 group by 指定列名 having 条件语句;//先分组,后筛选
联合查询:
实际开发中往往数据来自不同的表,所以需要多表联合查询,多表查询是对多张表的数据取笛卡尔积,笛卡尔积就是两张表的记录(行)排列组合的结果
笛卡尔积的列数(字段数),就是两个表的列数之和
笛卡尔积的行数(记录数),就是两个表的行数之积

笛卡尔积就是一个简单粗暴的排列组合,把所有可能的情况列出来了,因此其中的情况必然有些是合理的,有些是不合理的,因此就需要把合理的留下,不合理的筛选掉,用来筛选笛卡尔积有效数据的条件,就称为连接条件
联合查询 = 笛卡尔积 + 连接条件(where) + 其他条件(根据其他需求)
求笛卡尔积:select * from 表名1,表名2; 或者 select * from 表名1 join 表名2;
内连接查询方式1:select * from 表名1,表名2 where 表名1.列名 = 表名2.列名;
内连接查询方式2:select * from 表名1 join 表名2 on 表名1.列名 = 表名2.列名; //显示两表都对应的记录
左外连接查询:select * from 表名1 left join 表名2 on 表名1.列名 = 表名2.列名; //左外连接就是以左表为主,把左侧表的数据都显示完整
右外连接查询:select * from 表名1 right join 表名2 on 表名1.列名 = 表名2.列名; //右外连接就是以右表为主,把右侧表的数据都显示完整
自连接查询:select * from 表名1 join 表名1 on 连接条件; 或者 select * from 表名1,表名1; //自连接用于记录与记录之间关系比较的查询
join可以看作是,的意思,on可以看作是where的意思~~
如果两张表的连接条件的列名相同的话,使用 表名.列名 的形式,如果不同可以直接写 列名 或者 表名.列名 均可
子查询:
子查询是指select语句中嵌套了select语句,也叫嵌套查询,子查询的子语句只能返回一条/多条单列的记录,子查询本质上就是把多个查询语句组合成了一个查询语句
子查询写法:select * from 表名 where 列名 = (select 列名 from 表名 where 列名 = 值); //子查询的子语句只能返回一条单列的记录(行)
in子查询写法:select * from 表名 where 列名 in (select 列名 from 表名 where 列名 = 值); //子查询的子语句可以返回多条单列的记录(行)
union子查询写法:select * from 表名1 union [all] select * from 表名2 //如果表1和表2列(字段)完全相同,可以将两张表查询的记录合并到一起,union会去掉重复数据,union all不会去掉重复数据
改
修改数据:update 表名 set 列名 = 值,列名 = 值... [where][order by][limit]...; //它会改变真实数据,这也是一个危险操作
删
删除数据:delete from 表名 [where][order by][limit]...; //它会删除数据,这也是一个危险操作
-
相关阅读:
力扣刷题day27|455分发饼干、376摆动序列、53最大子序和
1226:装箱问题 (贪心)
ERP系统有哪些优点和缺点?
用QT的modbus相关类编写ModbusTcp主站
[附源码]Python计算机毕业设计SSM考勤系统设计(程序+LW)
亿图导出word和PDF中清晰度保留方法
Day59|leetcode 503.下一个更大元素II、42. 接雨水
【Oculus Interaction SDK】(九)使用控制器时显示手的模型
详解: Spring 的 @Enable 开头
【附源码】Python计算机毕业设计三味书屋图书借阅与售卖系统
- 原文地址:https://blog.csdn.net/zyyy0/article/details/128050226