-
第二章 爬虫的实现原理和技术(一)
2.1 爬虫的实现原理
不同类型的爬虫,具体的实现原理也不尽相同,但是这些爬虫之间存在许多共性。下面我将以通用爬虫与聚焦爬虫为例,具体来讲解爬虫是如何来运作的。
通用爬虫的工作原理
通用爬虫是一个自动提取网页的程序,能够从Internet上下载网页,是大多的搜索引擎的重要组成部分。
通用爬虫从一个或若干个初始的URL开始,获取初始网页上的URL,再爬去网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统程序的停止条件。
通用爬虫从互联网中收集网页、采集信息,这些网页信息用于为搜索引擎提供支持,它决定着整个引擎系统是否丰富,是否能够及时更新,因此设计出来的爬虫性能的优劣将直接影响着搜索引擎的搜索效果。
但是,用于搜索引擎的的通用爬虫其爬行的行为需要符合一定的规则,遵循一些命令或者文件的内容,如标出nofollow的链接,或者rebots的协议。(关于rebots协议的详细将会,在后面介绍)。
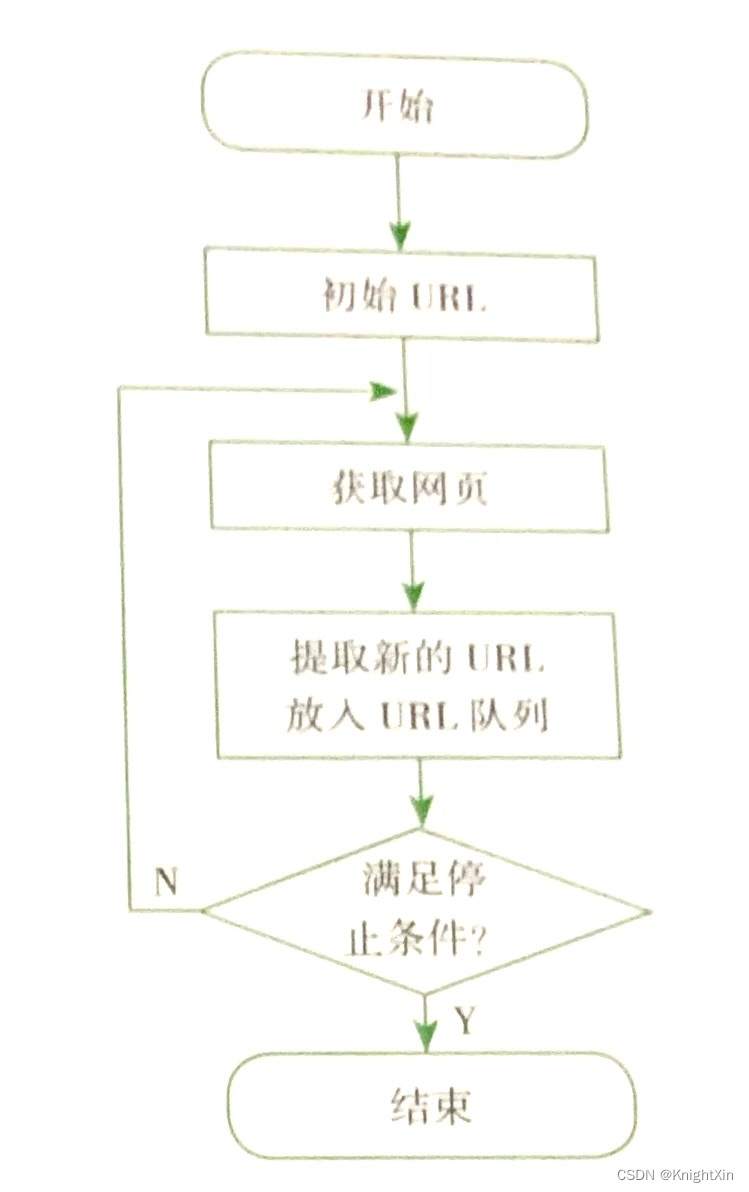
聚焦爬虫工作原理
与通用爬虫相比,聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法进行过滤与主题无关的链接,来保留需要的链接,并对其进行爬取。然后他将根据一定的搜索策略,从队列中选择要爬取的网页URL,并不断重复上述的过程,知道达到系统的某一条件时停止。
相对于通用网络爬虫,聚焦爬虫还需要解决3个主要的问题。- 对爬取的目标描述或者定义。根据爬虫所要爬取的要求定义聚焦爬虫的爬取目标,并惊醒相关的描述。
- 对网页或数据的分析与过滤。
- 对URL的搜索策略。
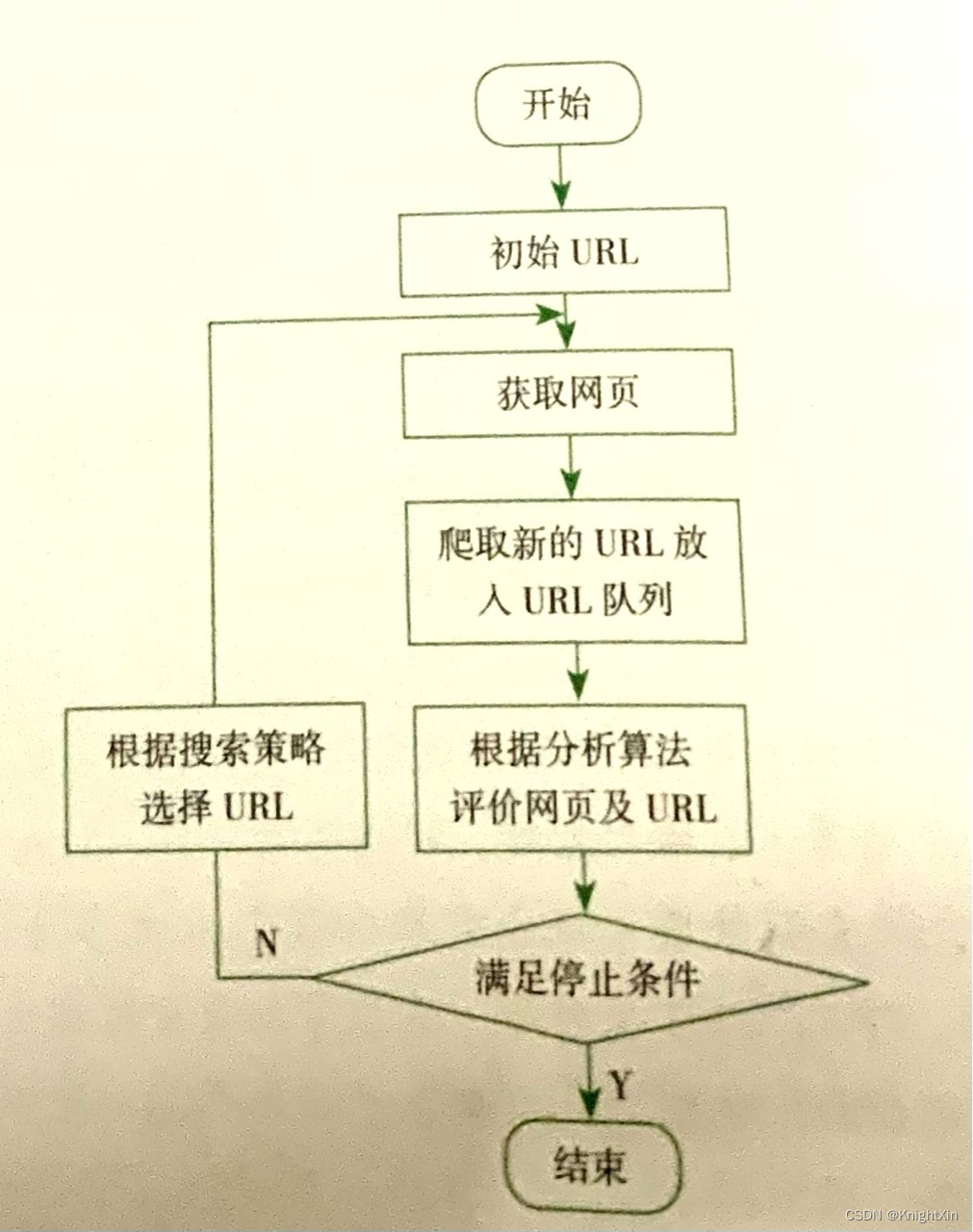
搜索引擎的工作流程
搜索引擎是通用爬虫的最重要应用领城,也是人们使用网络功能的最强助手。下面介绍搜索引擎的工作流程,其主要包含以下几个步骤。
第一步:爬取网页
披索引擎使用通用爬虫来爬取网页,其基本工作流程与其他爬虫类似,大致步骤如下:- 选取一部分种子 URL,将这些 URL 放入待爬取的URI队列。
- 取出待爬取的 URL,解析DNS 得到主机的IP,并将URL对应的网页下載下来,存储至已下载的网页库中,并将这些URL 放进已爬取的 URL队列。
- 分析已爬取URL队列中的URL,分析其中的其他URL,并且将URL 放入待爬取的 URL 队列,从而进入下一个循环。
那么,搜索引擎如何获取一个新网站的 URL? - 新网站向搜索引擎主动提交网址(如百度 http://zhanzhang.baidu.com/linksubrnit/ur)。
- 在其他网站上设置新网站外链(尽可能处于搜索引擎爬虫爬取范围)。
- 搜索引擎和DNS 解析服务商(如DNSPod 等)合作,新网站城名将被还速爬取。
第二步:数据存储
搜索引擎通过爬虫爬取到网页后,将数据存入原始页面数据库。其中的页面数据与用户浏览器得到的 HTMI 是完全一样的。
搜索引擎蜘蛛在爬取页面时,也做一定的重复内容检测,一旦遇到访问权重很低的网站上有大量抄袭、采集或者复制的内容,很可能就不再爬行。
第三步:预处理
搜索引擎将爬虫爬取回来的页面,进行各种预处理,包括:提取文宇、中文分词、消除噪声(如版权声明文宇、导航条、广告等)、索引处理、链接关系计算、特殊文件处理……⋯…•
除了 HTML文件外,搜索引擎通常还能爬取和索引以文宇为基础的多种文什类型,如
PDF、Word、WPS、XIS、PPT、TXT 文件等。在搜索结果中经常会看到这些文件类型。
但搜索引擎还不能处理图片、视频、Flash这类非文宇内容,也不能执行程序。
第四步:提供检索服务,网站排名
搜索引揫在对信息进行组织和处理后,为用户提供关键宇检索服务,将用户检索的相关信息展示给用户。
同时会根据页面的 PageRank值(链接的访问量排名) 来进行网站排名,这样PasePank值高的网站在搜索结果中排名会提高。当然,也可以直接付费购买排名,这也是搜索引擎公司的盈利手段之一。
-
相关阅读:
blender3.3下载安装(Windows)
24-Docker-常用命令详解-dcoker search
【博客492】使用iptables trace跟踪iptables流量
ubuntu 里根文件系统的扩容,/dev/ubuntu-vg/ubuntu-lv 文件系统扩充到整个分区
Nodejs入门实战一篇精通
【SSM】SpringMVC系列——SpringMVC概述
ImmunoChemistry艾美捷基本细胞毒性试验试剂盒测定方案
问题 B: Ella的密码——map
双十二购买护眼台灯亮度多少合适?灯光亮度多少对眼睛比较好呢
【Vue基础】路由以及axios详解与使用案例
- 原文地址:https://blog.csdn.net/qq_42929788/article/details/128045491