-
Linux之free命令介绍 及buffer和cache的区别
free命令介绍
- [root@VM_16_17_centos bin]# free -h
- total used free shared buff/cache available
- Mem: 1882892 785272 280428 40496 817192 852060
- Swap: 0 0 0
先说明一些基本概念
第一列
Mem 内存的使用信息
Swap 交换空间的使用信息
第一行
total 系统总的可用物理内存大小
used 已被使用的物理内存大小
free 还有多少物理内存可用
shared 被共享使用的物理内存大小
buff/cache 被 buffer 和 cache 使用的物理内存大小
available 还可以被 应用程序 使用的物理内存大小- free 与 available 的区别
free 是真正尚未被使用的物理内存数量。
available 是应用程序认为可用内存数量,available = free + buffer + cache (注:只是大概的计算方法)
Linux 为了提升读写性能,会消耗一部分内存资源缓存磁盘数据,对于内核来说,buffer 和 cache 其实都属于已经被使用的内存。但当应用程序申请内存时,如果 free 内存不够,内核就会回收 buffer 和 cache 的内存来满足应用程序的请求。这就是稍后要说明的 buffer 和 cache。
free命令界面变化
老版的free命令长成这个样子:

较新版本的Ubuntun、CentOS等中的free命令是这个样子的:

主要的变化是buff/cache被合并为一列,并且增加了available这一列。
available这一列的具体含义可以参见内核的这个commit:
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=34e431b0ae398fc54ea69ff85ec700722c9da773
天冷手冻,不详细解释和翻译了,具体直接看英文:

- diff --git a/Documentation/filesystems/proc.txt b/Documentation/filesystems/proc.txt
- index 22d89aa3..8533f5f 100644
- --- a/Documentation/filesystems/proc.txt
- +++ b/Documentation/filesystems/proc.txt
- @@ -767,6 +767,7 @@ The "Locked" indicates whether the mapping is locked in memory or not.
- MemTotal: 16344972 kB
- MemFree: 13634064 kB
- +MemAvailable: 14836172 kB
- Buffers: 3656 kB
- Cached: 1195708 kB
- SwapCached: 0 kB
- @@ -799,6 +800,14 @@ AnonHugePages: 49152 kB
- MemTotal: Total usable ram (i.e. physical ram minus a few reserved
- bits and the kernel binary code)
- MemFree: The sum of LowFree+HighFree
- +MemAvailable: An estimate of how much memory is available for starting new
- + applications, without swapping. Calculated from MemFree,
- + SReclaimable, the size of the file LRU lists, and the low
- + watermarks in each zone.
- + The estimate takes into account that the system needs some
- + page cache to function well, and that not all reclaimable
- + slab will be reclaimable, due to items being in use. The
- + impact of those factors will vary from system to system.
- Buffers: Relatively temporary storage for raw disk blocks
- shouldn't get tremendously large (20MB or so)
- Cached: in-memory cache for files read from the disk (the
- diff --git a/fs/proc/meminfo.c b/fs/proc/meminfo.c
- index a77d2b2..24270ec 100644
- --- a/fs/proc/meminfo.c
- +++ b/fs/proc/meminfo.c
- @@ -26,7 +26,11 @@ static int meminfo_proc_show(struct seq_file *m, void *v)
- unsigned long committed;
- struct vmalloc_info vmi;
- long cached;
- +long available;
- +unsigned long pagecache;
- +unsigned long wmark_low = 0;
- unsigned long pages[NR_LRU_LISTS];
- +struct zone *zone;
- int lru;
- /*
- @@ -47,12 +51,44 @@ static int meminfo_proc_show(struct seq_file *m, void *v)
- for (lru = LRU_BASE; lru < NR_LRU_LISTS; lru++)
- pages[lru] = global_page_state(NR_LRU_BASE + lru);
- +for_each_zone(zone)
- +wmark_low += zone->watermark[WMARK_LOW];
- +
- +/*
- + * Estimate the amount of memory available for userspace allocations,
- + * without causing swapping.
- + *
- + * Free memory cannot be taken below the low watermark, before the
- + * system starts swapping.
- + */
- +available = i.freeram - wmark_low;
- +
- +/*
- + * Not all the page cache can be freed, otherwise the system will
- + * start swapping. Assume at least half of the page cache, or the
- + * low watermark worth of cache, needs to stay.
- + */
- +pagecache = pages[LRU_ACTIVE_FILE] + pages[LRU_INACTIVE_FILE];
- +pagecache -= min(pagecache / 2, wmark_low);
- +available += pagecache;
- +
- +/*
- + * Part of the reclaimable swap consists of items that are in use,
- + * and cannot be freed. Cap this estimate at the low watermark.
- + */
- +available += global_page_state(NR_SLAB_RECLAIMABLE) -
- + min(global_page_state(NR_SLAB_RECLAIMABLE) / 2, wmark_low);
- +
- +if (available < 0)
- +available = 0;
- +
- /*
- * Tagged format, for easy grepping and expansion.
- */
- seq_printf(m,
- "MemTotal: %8lu kB\n"
- "MemFree: %8lu kB\n"
- +"MemAvailable: %8lu kB\n"
- "Buffers: %8lu kB\n"
- "Cached: %8lu kB\n"
- "SwapCached: %8lu kB\n"
- @@ -105,6 +141,7 @@ static int meminfo_proc_show(struct seq_file *m, void *v)
- ,
- K(i.totalram),
- K(i.freeram),
- +K(available),
- K(i.bufferram),
- K(cached),
- K(total_swapcache_pages()),
另外,关于free命令里面的cached、buffers的区别,下面一幅图可以表达:
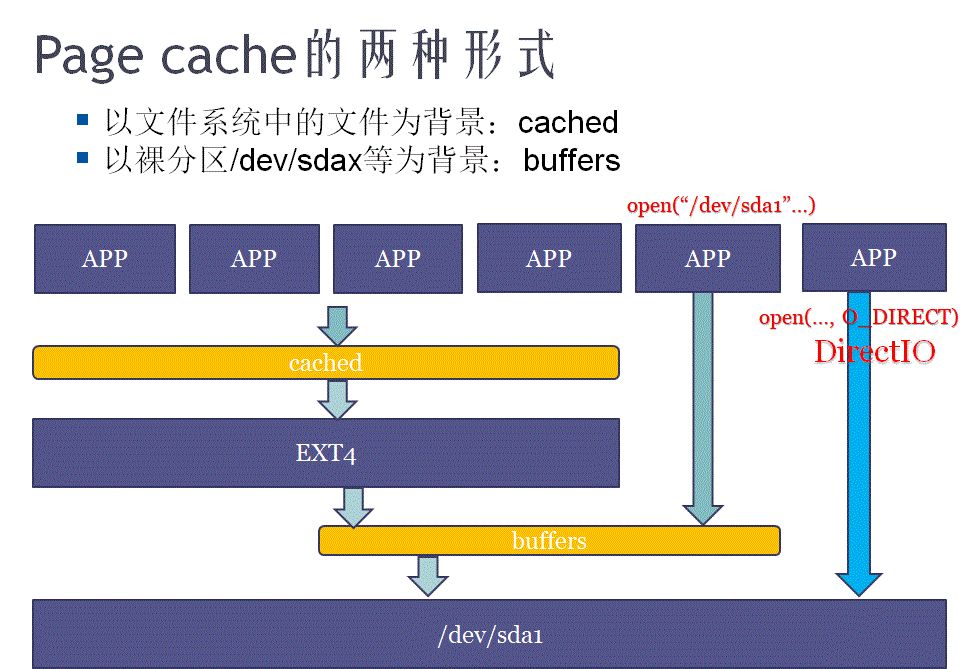
Linux下 buffer和cache的区别
区别
- A buffer is someting that has yet to be 'written' to disk.
- A cache is someting that has been 'read' from the disk and stored for later use.
buffer用于存放输入到磁盘上的数据,而cache是从磁盘中读出数据存储在内存中待以后进行使用。
Cache与Buffer是我们容易混淆的内存概念,从字面意思来看,Cache名为缓存,Buffer名为缓冲,虽一字之差,但是它们在不同语境下的含义却大不相同。CPU执行的指令需要从内存中取出,计算结果也需回写到内存中,但内存的响应速度跟不上CPU的话,CPU只能等待,这样CPU也无法发挥效率。同理,内存中的数据也是要回写到磁盘的,但是磁盘的低速读写远比不上内存的二进制电压变化速度。这样巨大的差异,即使内存读写速度再快,还是要被磁盘拖后腿。而
Cache和Buffer的出现就是为了弥补高速设备和低速设备之间的矛盾而设立的中间层。Cache会将低速设备中常被访问的数据缓存起来,当高速设备需要再次访问这些数据时,会命中Cache中的数据,以减少对低速设备的访问。Buffer用于缓和高速设备要把数据回写到低速设备时带来的冲击,当数据量比较大时,Buffer能将数据分割成合适的大小,分批回写到磁盘;当数据量比较小的时候,Buffer能将分散的写操作集中进行,减少磁盘碎片和硬盘的反复寻道,通过“流量整形”提高系统性能。buffer名为缓冲,cache名为缓存。我们知道各种硬件在制作工艺上存在差别,所以当这两种硬件需要交互的时候,肯定会存在速度上的差异,而且只有交互双方都完成才可以各自处理其他的事物。假如现在有两个需要交互得设备 A 和 B,A设备用来交互得接口速率为 1000M/s,B设备用来交互得接口速率为 500M/s,那他们彼此访问的时候都会出现以下两种情况:(以A来说)
1. A 从 B 取一个 1000M 的文件结果需要 2s,本来 1s就可以完成的工作,却还需要额外等待 1s,B设备把剩余的 500M找出来,还需要等待 B 取出来剩下的 500M 的空闲时间内(1s)其他的事务还干不了。
2. A 给 B 一个 1000M 的文件结果也需要 2s,本来需要也就 1s 就可以完成的工作,却由于 B,1s 内只能拿 500M,剩下的 500M 还得等下一个 1s 由 B 来取,这等待下一个 1s 的时间还做不了其他事务。
那有什么办法既可以让 A 在'取'或'给' B 的时候既能完成目标任务又不浪费那 1s 空闲等待时间取处理其他事物呢?我们知道产生这种结果主要是因为 B 没有跟上 A 的节奏,但即使这样 A 也得必须等待 B 处理完本次事务才能干其他活(单核cpu来说),除非你有三头六臂。那么有小伙伴可能会问了,能不能在 A 和 B 之间加一层区域比如说 ab,让 ab 既能跟上 A 的频率也会照顾 B 的感受,没错我们确实可以这样设计来磨合接口速率上的差异,你可以这样想象,在区域 ab 提供了两个交互接口一个是 a 接口另一个是 b 接口,a接口的速率接近 A,b接口的速率最少等于 B,然后我们把 ab 的 a和 A相连,ab的 b 和 B 相连,ab 就像一座大桥把 A 和 B 连接起来,并告知 A 和 B 通过他都能转发给对方,文件可以暂时存储,最终拓补如下
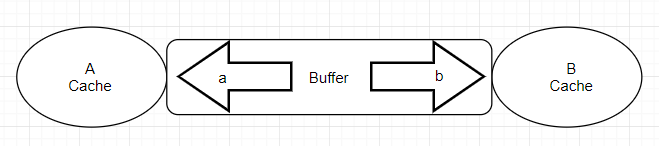
示例
现在我们再来看上述的两种情况:
对于第一种情况 A 要 B:当 A 从 B 取一个 1000M 的文件,他把需求告诉了 ab,接下来 ab通过 b 和 B 进行文件传送,由于 B 本身的速率,传递第一次 ab并没有什么用,对于 A 来说不仅浪费了时间还浪费了感情,ab 这家伙很快感受到了 A 的不满,所以在第二次传送的时候,ab 背着 B 偷偷缓存了一个一摸一样的文件,而且只要从 B 取东西,ab都会缓存一个拷贝下来放在自己的大本营,如果下次 A 或者其他 C 来 B 取东西,ab 直接给 A 或 C 一个货真价实的赝品,然后把它通过 a 接口传递给 A 或 C,所以 A 觉着不错问他省了时间,最终和 ab 成为了好基友,说白了此时的 ab 提供的就是一种缓存能力,即 cache,绝对的走私!因为 C 取得是 A 执行的结果。所以在这种工作模式下,怎么取得东西是最新的也是我们要考虑的,一般就是清 cache。例如 cpu 读取内存数据,硬盘一般都是提供一个内存作为缓存来增加系统的读取性能。
对于第二种情况 A 给 B:当 A 发给 B 一个 1000M的文件,因为 A 知道通过 ab 的 a接口就可以转交给 B,而且通过 a 接口要比通过 B 接口传送文件需要等待的时间更短,所以 1000M 通过 a 给了 ab,站在 A 视图上他已经把 1000M 的文件给了 B,但对于 ab 并不立即交给 B,而是先缓存下来,除非 B执行 sync 命令,即使 B 马上要,但由于 b 的接口速率要大于 B接口速率,所以也不会存在漏洞时间,但最终的结果是 A 节约了时间就可以干其他的事务,说白了就是推卸责任,而 ab 此时提供的就是一种缓冲能力,即 buffer,它存在的目的适用于当速度快的往速度慢的输出东西。例如内存的数据要写磁盘,cpu 寄存器里的数据写到内从。
看一下现在计算机领域,在处理磁盘 IO 读写的时候,cpu、memory、disk 基于这种模型给出的一个实例。
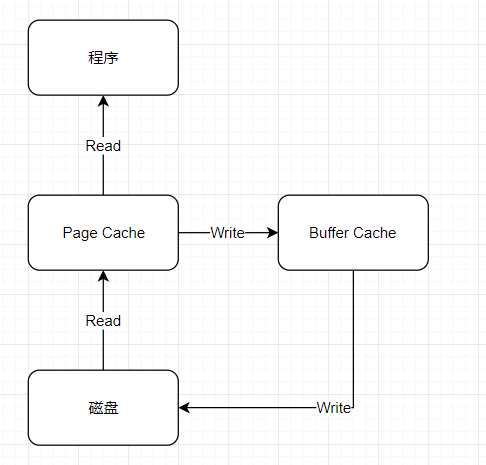
示例
Page Cache:文件系统层级的缓存,从磁盘里读取的内容是存储到这里,这样读取程序读取磁盘内容就会非常快,比如使用 grep 和 find 等命令查找内容和文件时,第一次回慢很多,再次执行几乎是瞬间。但如上所说,如果对文件的更新并不关心,就没必要清除 cache,否则如果要实时同步,必须要把内存空间中的 cache clean 下。
Buffer Cache:磁盘等设备的缓冲,内存的这一部分是要写入磁盘里的。这种情况需要注意,位于内存 buffer 中的数据不是即时写入磁盘,而是系统空闲或者 buffer 达到一定大小写到磁盘中,所以断电易失,为了防止数据丢失所以我们最好正常关机或者多执行几次 sync 命令,让位于 buffer上的数据立刻写道磁盘里。
在Linux 2.4以前page cache和buffer cache是两个独立的缓存,Linux 2.4开始
buffer cache不再是一个独立的缓存,如下图所示的那样,它被包含在page cache中,通过page cache来实现。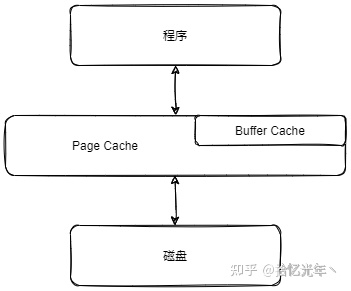
测试
- 生成一个测试文件。
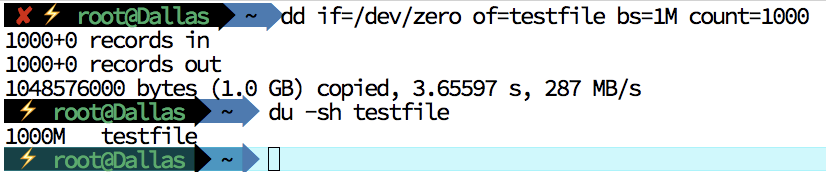
- 清空缓存

三种清空方式:
echo 1 > /proc/sys/vm/drop_caches:仅清除页面缓存echo 2 > /proc/sys/vm/drop_caches:清除目录项和inode(索引节点)echo 3 > /proc/sys/vm/drop_caches:清除页面缓存、目录项以及inode(索引节点)
- 读取测试文件,查看读取时长

我们可以看到,读取时长在52s,第一次读取文件后,已经写入cache。
- 测试第二次读取文件时长

当我们清除cache后读取此测试文件时长为52s,当第一次读取完成后写入cache再次读取时,时长为0.24s,性能可谓极大提升。
坑
测试时可能遇到的关于time命令的坑,我们系统中是自带time命令的,不过并不常用,我们用于测试使用的time是需要单独安装的:
yum -y install time。可以使用以下方法进行区分:which time/usr/bin/which: no time in (/usr/lib64/qt-3.3/bin:/root/perl5/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin)给我们上述返回值时,表示我们的time命令还没有安装。
type timetime is a shell keyword返回time是一个shell关键字同样不是我们想要的time命令。
time --version- zsh: command not found: --version
- --version 0.00s user 0.00s system 60% cpu 0.001 total
查看time版本提示命令未安装,表示我们需要使用的time命令还没有被安装。
yum -y install timewhich time/usr/bin/time/usr/bin/time --versionGNU time 1.7有上述信息,我们就可以开始使用啦。
参考文章:
Linux系统中的Page cache和Buffer cache - 知乎
三分钟增强内功!Linux中的Buffer与Cache - 知乎
Linux Buffer/Cache 的区别 - Federico - 博客园
-
相关阅读:
十二、【漏洞复现】Rails任意文件读取(CVE-2019-5418)
JAVA:实现MinPriorityQueue最小优先级队列算法(附完整源码)
【数据分析实战】kaggle项目:bike sharing demand
WangEditor在Vue前端的应用
【spring和容器系列】spring bean
【mcuclub】温度传感器DS18B20
yarn的安装与配置(Windows/macOS)
MySQL 主从同步(读写分离)
C++基础——默认成员函数讲解1
.[nicetomeetyou@onionmail.org].faust深入剖析勒索病毒及防范策略
- 原文地址:https://blog.csdn.net/lovedingd/article/details/128039681