-
【Flink】基本转换算子使用之fliter、flatMap,键控流转换算子和分布式转换算子
一 Flink DataStream API
1 基本转换算子的使用
基本转换算子的定义:作用在数据流中的每一条单独的数据上的算子。基本转换算子会针对流中的每一个单独的事件做处理,也就是说每一个输入数据会产生一个输出数据。单值转换,数据的分割,数据的过滤,都是基本转换操作的典型例子。
(1)fliter

a 使用匿名类实现
public class Example3 { public static void main(String[] args) throws Exception{ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStreamSource<Event> stream = env.addSource(new ClickSource()); stream.filter(r -> r.user.equals("Marry")).print(); stream .filter(new FilterFunction<Event>() { @Override public boolean filter(Event event) throws Exception { return event.user.equals("Marry"); } }) .print(); env.execute(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
b 使用外部类函数实现
stream .filter(new MyFilter()) .print();- 1
- 2
- 3
public static class MyFilter implements FilterFunction<Event>{ @Override public boolean filter(Event event) throws Exception { return event.user.equals("Marry"); } }- 1
- 2
- 3
- 4
- 5
- 6
b 使用flatMap实现
stream .flatMap(new FlatMapFunction<Event, Event>() { @Override public void flatMap(Event event, Collector<Event> collector) throws Exception { if(event.user.equals("Marry")) collector.collect(event); } }) .print();- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
输入一条元素,输出1个结果使用map,输出0 或 1 个结果使用filter,针对每一个条数据输出0 1 或者多个结果使用flatmap。
(2)flatMap
a 使用匿名类实现
public class Example4 { public static void main(String[] args) throws Exception{ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // 将white直接输出,将black复制,将gray过滤 DataStreamSource<String> stream = env.fromElements("white", "black", "gray"); // 当每一条数据进入到flatMap算子时,就会触发flatMap的调用 // 在flink中程序只是定义了一个有向无环图,需要事件去驱动它的运行 stream .flatMap(new FlatMapFunction<String, String>() { @Override public void flatMap(String s, Collector<String> collector) throws Exception { if(s.equals("white")){ collector.collect(s); }else if(s.equals("black")){ collector.collect(s); collector.collect(s); } } }) .print(); env.execute(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
b 使用匿名函数实现
stream .flatMap((String s,Collector<String> collector) -> { if(s.equals("white")){ collector.collect(s); }else if(s.equals("black")) { collector.collect(s); collector.collect(s); } }) // Collector会被擦除 .returns(Types.STRING) .print();- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2 键控流转换算子
很多流处理程序的一个基本要求就是要能对数据进行分组,分组后的数据共享某一个相同的属性。DataStream API 提供了一个叫做 KeyedStream 的抽象,此抽象会从逻辑上对 DataStream 进行分区,分区后的数据拥有同样的 Key 值,分区后的流互不相关。
针对 KeyedStream 的状态转换操作可以读取数据或者写入数据到当前事件 Key 所对应的状态中。这表明拥有同样 Key 的所有事件都可以访问同样的状态,也就是说所以这些事件可以一起处理。KeyedStream 可以使用 map,flatMap 和 filter 算子来处理。
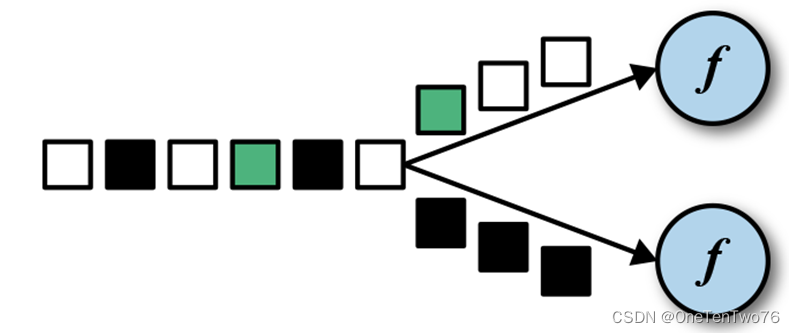
DataStream → KeyedStream:逻辑地将一个流拆分成不相交的分区,每个分区包含具有相同key的元素,在内部以hash的形式实现的。从逻辑上分区去对这些数据进行处理,物理上的位置无关紧要。不过最终同一个Key中的数据一定在一个任务槽中,这样会出现数据倾斜的问题。
(1) keyBy
keyBy 通过指定 key 来将 DataStream 转换成 KeyedStream。基于不同的 key,流中的事件将被分配到不同的分区中去。所有具有相同 key 的事件将会在接下来的操作符的同一个子任务槽中进行处理。拥有不同 key 的事件可以在同一个任务中处理。但是算子只能访问当前事件的 key 所对应的状态。keyBy() 方法接收一个参数,这个参数指定了 key 或者 keys,有很多不同的方法来指定 key。
如之前使用的匿名类方式,针对每一条数据指定key。
KeyedStream<WordWithCount, String> keyedStream = mappedStream // 第一个泛型:流中元素的泛型 // 第二个泛型:key的泛型 .keyBy(new KeySelector<WordWithCount, String>() { public String getKey(WordWithCount value) throws Exception { return value.word; } });- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
只要存在分组,就一定存在聚合,所以提出了滚动聚合的概念。
(2)滚动聚合
滚动聚合算子由 KeyedStream 调用,并生成一个聚合以后的 DataStream,例如:sum,minimum,maximum。一个滚动聚合算子会为每一个观察到的 key 保存一个聚合的值。针对每一个输入事件,算子将会更新保存的聚合结果,并发送一个带有更新后的值的事件到下游算子。滚动聚合不需要用户自定义函数,但需要接受一个参数,这个参数指定了在哪一个字段上面做聚合操作。DataStream API 提供了以下滚动聚合方法。
- sum():在输入流上对指定的字段做滚动相加操作。
- min():在输入流上对指定的字段求最小值。
- max():在输入流上对指定的字段求最大值。
- minBy():在输入流上针对指定字段求最小值,并返回包含当前观察到的最小值的事件。
- maxBy():在输入流上针对指定字段求最大值,并返回包含当前观察到的最大值的事件。
滚动聚合算子无法组合起来使用,每次计算只能使用一个单独的滚动聚合算子。
如以下例子按照key进行分组并聚合:
public static void main(String[] args) throws Exception{ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStreamSource<Tuple2<Integer, Integer>> stream = env .fromElements( Tuple2.of(1, 3), Tuple2.of(1, 4), Tuple2.of(2, 3) ); // 逻辑上进行分流 KeyedStream<Tuple2<Integer, Integer>, Integer> keyedStream = stream.keyBy(r -> r.f0); // 针对第一个位置进行聚合 keyedStream.sum(1).print(); env.execute(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
输出结果也同样体现出滚动聚合的效果:
(1,3) (1,7) (2,3)- 1
- 2
- 3
(3)reduce
reduce 算子是滚动聚合的泛化实现。它将一个 ReduceFunction 应用到了一个 KeyedStream 上面去。reduce 算子将会把每一个输入事件和当前已经 reduce 出来的值做聚合计算。reduce 操作不会改变流的事件类型。输出流数据类型和输入流数据类型是一样的。
reduce 函数可以通过实现接口 ReduceFunction 来创建一个类。ReduceFunction 接口定义了 reduce() 方法,此方法接收两个输入事件,输出一个相同类型的事件。
如下同样可以实现sum的功能。
keyedStream .reduce(new ReduceFunction<Tuple2<Integer, Integer>>() { @Override public Tuple2<Integer, Integer> reduce(Tuple2<Integer, Integer> value1, Tuple2<Integer, Integer> value2) throws Exception { return Tuple2.of(value1.f0,value1.f1 + value2.f1); } }) .print();- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
(4)案例
求整数的平均值。
public static void main(String[] args) throws Exception{ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); env .addSource(new SourceFunction<Integer>() { private boolean running = true; private Random random = new Random(); @Override public void run(SourceContext<Integer> ctx) throws Exception { while (running){ ctx.collect(random.nextInt(10)); Thread.sleep(100); } } @Override public void cancel() { running = false; } }) .map(r -> Tuple2.of(r,1)) .returns(Types.TUPLE(Types.INT,Types.INT)) // reduce必须在keyBy之后使用 // 如果想在一条流上直接使用滚动聚合 // 将所有数据shuffle到同一个逻辑分区 .keyBy(r -> true) .reduce(new ReduceFunction<Tuple2<Integer, Integer>>() { @Override public Tuple2<Integer, Integer> reduce(Tuple2<Integer, Integer> value1, Tuple2<Integer, Integer> value2) throws Exception { return Tuple2.of(value1.f0 + value2.f0,value1.f1 + value2.f1); } }) .map(new MapFunction<Tuple2<Integer, Integer>, Object>() { @Override public Object map(Tuple2<Integer, Integer> value) throws Exception { return (double) value.f0 / value.f1; } }) .print(); env.execute(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
总结:滚动聚合的要点在于每一个Key都有自己的累加器(状态变量),一条数据来到处理完成之后就丢弃了,向下游发送的数据是累加器中的数据,这样就不需要将所有的数据都保存下来,节省内存空间,性能高于批处理。
scala中为什么会出现伪递归:在纯正的函数式编程中是没有循环的,那么如何实现循环的功能呢?使用递归!那么使用递归又带来了一个问题,递归的栈会超过内存,造成内存溢出Stack Overflow,那么伪递归用新来的栈去覆盖原有的栈,栈的深度不变,所以可以使用伪递归来模拟循环,伪递归当中有累加器的存在。
3 分布式转换算子
分区操作对应于之前的“数据交换策略”。这些操作定义了事件如何分配到不同的任务中去。当使用 DataStream API 来编写程序时,系统将自动的选择数据分区策略,然后根据操作符的语义和设置的并行度将数据路由到正确的地方去。
有些时候,当需要在应用程序的层面控制分区策略,或者自定义分区策略时。例如,如果我们知道会发生数据倾斜,那么想要针对数据流做负载均衡,将数据流平均发送到接下来的操作符中去。又或者,应用程序的业务逻辑可能需要一个算子所有的并行任务都需要接收同样的数据。再或者,需要自定义分区策略的时候。
keyBy() 方法不同于分布式转换算子。所有的分布式转换算子将产生 DataStream 数据类型。而 keyBy() 产生的类型是 KeyedStream,它拥有自己的 keyed state。
综上,分布式转换算子可以对数据进行物理分区,也就是说可以将数据分配到不同的任务槽中。
(1)Random
Random随机数据交换由 DataStream.shuffle() 方法实现。shuffle 方法将数据随机的分配到下游算子的并行任务中去,可以将数据分配到不同的任务槽中。
env .fromElements(1,2,3,4).setParallelism(1) .shuffle() .print("shuffle: ").setParallelism(2);- 1
- 2
- 3
- 4
运行结果如下:第一任务槽中数据为1和3,第二个任务槽中数据为2和4。
shuffle: :1> 1 shuffle: :1> 3 shuffle: :2> 4 shuffle: :2> 2- 1
- 2
- 3
- 4
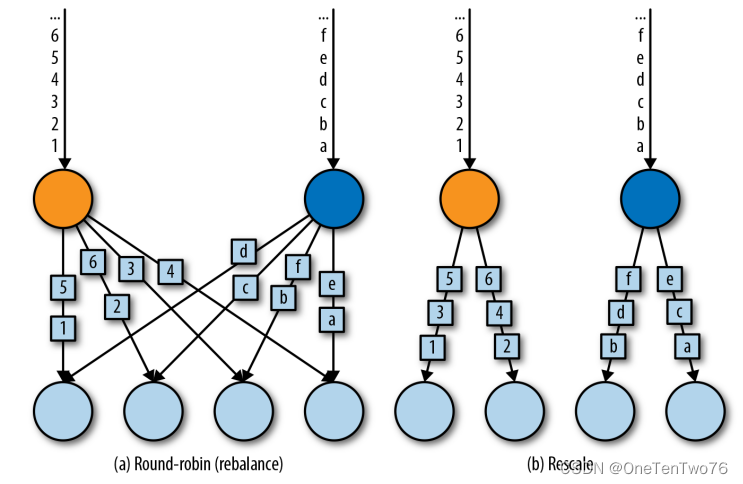
(2)Round-Robin
rebalance() 方法使用 Round-Robin 负载均衡算法将输入流平均分配到随后的并行运行的任务中去。
env .fromElements(1,2,3,4).setParallelism(1) .rebalance() .print("rebanlance: ").setParallelism(2);- 1
- 2
- 3
- 4
(3)Rescale
rescale()方法使用的也是round-robin算法,但只会将数据发送到接下来的并行运行的任务中的一部分任务中。本质上,当发送者任务数量和接收者任务数量不一样时,rescale分区策略提供了一种轻量级的负载均衡策略。如果接收者任务的数量是发送者任务的数量的倍数时,rescale 操作将会效率更高。
rebalance() 和 rescale() 的根本区别在于任务之间连接的机制不同。rebalance() 将会针对所有发送者任务和所有接收者任务之间建立通信通道,而 rescale() 仅仅针对每一个任务和下游算子的一部分子并行任务之间建立通信通道。
两者的示意图如下:
(4)Broadcast(常用)
broadcast() 方法将输入流的所有数据复制并发送到下游算子的所有并行任务中去。
env .fromElements(1,2,3,4).setParallelism(1) .broadcast() .print("broadcast: ").setParallelism(2);- 1
- 2
- 3
- 4
(5)Global
global() 方法将所有的输入流数据都发送到下游算子的第一个并行任务中去。这个操作需要很谨慎,因为将所有数据发送到同一个 task,将会对应用程序造成很大的压力。
(6)Custom
当 Flink 提供的分区策略都不适用时,我们可以使用 partitionCustom() 方法来自定义分区策略。这个方法接收一个 Partitioner 对象,这个对象需要实现分区逻辑以及定义针对流的哪一个字段或者 key 来进行分区。
-
相关阅读:
弘辽科技:淘宝怎么才能获得更多流量?要做点什么?
DSA之栈
整合定位技术应对物联网碎片化场景应用
令人头痛的延时双删
浅谈配置元件之TCP取样器配置/TCP取样器
视频监控系统/视频汇聚平台EasyCVR如何反向代理进行后端保活?
uniapp2023年微信小程序头像+昵称分别获取
return 0 和 return true 是什么意思
Debain JDK8 安装
μC/OS-II---内核:多任务与调度
- 原文地址:https://blog.csdn.net/weixin_43923463/article/details/127960141
