-
「风控算法服务平台」高性能在线推理服务设计与实现
本文作者:郁昌存 来自京东科技-风险管理中心
一、背景/目标
1) 风控智能化体系建设依赖大量深度学习/机器学习模型进行实时在线的风险识别、智能决策。要求可以将算法模型快速部署为在线服务,供决策引擎调用。
2) 风控决策引擎涵盖交易、支付、营销等核心链路,业务场景对决策系统性能要求极高,平均tp99<50ms。要求算法模型实时服务在高吞吐量下,仍能满足性能要求。
3)精细化运营大背景下,算法模型服务需要支持大促不降级,且不能通过野蛮加机器方式提高吞吐量。要求从技术及架构层进行改进,对算法模型在线推理性能有质的提升。
二、平台整体概览
 三、产品功能
三、产品功能
四、在线推理模块设计方案
本文主要以在线推理服务模块展开讲解:
1. 多引擎支持
抽象底层,将不同框架实现、自定义脚本语言统一定义为引擎,引擎提供模型load、predict方法。
1)自定义脚本引擎:Python、Groovy。
2)机器学习引擎:Pytorch、Tensorflow、MxNet、XGBoost、PMML、TensorRT。
3)支持引擎动态扩展,接口继承实现load、predict方法即可。
2. 高性能
- 集成native引擎。
2)优化pyhton执行引擎,改变传统REST接口封装方式,规避python GIL性能限制。
3)除推理操作外,其余流程全部异步化。
4)CPU精细化控制。
- GPU实时推理支持。
3. 动态部署
1)基于服务网关支持模型的动态发现、动态路由。
2)管理端配置模型服务信息,后通知模型计算节点,节点进行模型文件下载、启动加载及服务注册。节点定时检查,校对需要上线/下线的模型。
3)对外提供统一jsf(公司内部RPC服务)/rest接口,基于业务+场景获取对应模型计算节点列表,进行负载转发。
4. 计算资源动态调整
1)对模型计算节点进行资源分组,不同资源组配置不同规格机器资源(基于JDOS可轻松实现)。
2)模型可部署至1到多个分组上,支持单机器多模型混部,通过网关进行路由转发。
5. 灵活输入数据源支持
支持实时加工数据,r2m(公司内部redis集群)、hbase数据源等作为模型输入数据。
五、在线推理模块实现
1. 在线推理服务模块设计

2. 核心功能及实现
1)网关服务注册及路由
将单个模型服务抽象为一个独立的微服务,因此可套用微服务技术架构。基于SpringCloud,使用nacos做注册中心、ribbon负载、feign做服务间接口调用。
2)模型动态部署
▪管理端上传模型文件,配置对应的推理引擎,配置服务相关参数。
▪定义模型适配器为translator,Translator接口包含preProcess和postProcess方法,分别对应模型的前置和后置数据处理。Translator实现类支持动态编译加载(groovy/字节码),管理端配置时,定义对应模型translator代码,模型加载时进行代码动态编译和注册,如此可实现灵活的配置化方式。
▪服务节点通过事件广播、定时检查机制,更新拉取对应模型文件及适配器代码,执行模型部署。
▪模型部署成功后,将相关信息注册的服务网关,业务请求通过网关入口进行路由。
▪模型调用过程:
▪对于模型输入数据,在translator前置处理(preProcess)中获取对应数据源/实时加工数据,汇总后进行数据对齐、标准化处理。
▪数据喂给模型,使用对应推理引擎执行推理操作,得到模型输出结果。
▪对于模型输出结果,在translator后置处理(preProcess)中进行模型输出结果解析提取、线性调整、解释加工等。
3)模型服务网关
支持服务动态注册、发现,基于nacos服务发现。
支持模型服务负载、路由,基于feign+ribbon。
支持一键降级/限流,基于nacos配置中心实现。
支持A/BTest、灰度发布,从配置中心获取到服务节点列表后,通过配置规则做对应路由转发即可。
支持实时推理数据回落10K(公司内部大数据集群,支持MQ消息管道落数),方便算法人员进行模型迭代验证。发送请求出入参数MQ,通过MQ落10K。
4)模型自动迭代
提供python sdk,打通KuAI(公司内部一站式AI模型开发平台),模型推理数据通过MQ回落10K,算法同学通过KuAI提取数据加工,对模型进行迭代训练,验证完成后将训练好模型通过python sdk部署至算法服务平台,替换/灰度提供在线服务。
实现实时推理数据回落模型再训练模型版本迭代 流程自动化,基于此实现风控领域自动对抗能力。
5)打通风控决策体系
集成风控特征平台,支持食蚁兽(风控自研流式数据加工平台)、flink数据获取,支持hbase、r2m(公司内部redis集群)等数据源数据获取,解决模型输入数据加工问题。
无缝对接天盾风控引擎,支持模型快速转换为决策引擎原子规则。
3. 在线推理性能优化
1)集成native引擎
集成常用机器学习框架C++ lib库,通过native调用方式使用C++来执行模型的推理,速度飞快。
如何整合各个lib库,及其间接so包依赖?JDOS 容器化(JDOS是公司内部基于k8s的一体化应用部署平台),一遍趟坑,构建基础环境镜像,解决各种环境依赖,在此之上构建应用镜像。
2)优化python引擎调用方式
由于python GIL(全局解释锁)的存在,同一时刻一个python进程只能使用一个CPU,传统通过flask封装Rest接口包装模型服务方式在高吞吐量场景存在严重性能瓶颈。
通过使用本地进程通信(基于socket),在计算节点启动多个python进程实例,由计算节点(java进程)统一管控python进程,通过多进程来规避GIL限制,提升CPU资源利用率。
3)模型计算资源动态分组
由于网关的存在,模型分组就很轻松随意了,建立对应的路由映射关系即可。
可以通过不同模型对CPU/GPU要求不同、计算资源量、IO请求量、内存占用量等进行组合调配,实现机器资源的最大化利用。
4)线程池资源隔离,参数动态配置
针对每个模型服务,建立独立的线程池资源和处理队列,这里很关键,后续很多优化都基于线程池和队列,相关配置(queueSize、batchSize、waitTime、workers等)可在管理端进行配置,模型加载时使用动态配置进行加载。
资源混部下,独立的线程池资源可控制每个模型最大资源使用量,防止单个模型服务流量异常对其他模型服务造成影响。
其次将tomcat线程资源与模型计算资源进行解耦,保障模型的计算不阻塞其他web资源访问。
5)CPU精细化利用
模型推理服务不同于大多数的业务应用,业务应用多为IO密集型服务,多数业务操作为读写DB/cache等,多数时间消耗在IO等待,该类应用可以通过适当加大处理线程数来提升整体吞吐量。
然而模型推理服务为强计算密集型服务,对CPU消耗极大,如果对于每一次推理请求,都创建一个线程来进行进行推理,则会出现CPU高速运转且线程频繁切换状态,效率肯定高不了。如何解决?
5.1. 限制引擎框架CPU使用核数:
比如pytorch框架在推理时默认会使用全部CPU,这种情况对于只有一个训练任务时无疑是最高效的,但是对于在线推理服务来讲,单机每秒处理上千请求量,第一次请求把CPU占满,后面的请求只能和前面请求共享CPU,等待时间片切换分配计算,来回切换上下文处理,效率并不会高。这时候限制单次推理使用单核CPU,其他请求过来后分配到其他空闲CPU上,减少线程切换次数,提升处理效率。数据对比验证,进行CPU核数限制后,tps可提升5倍以上,且tp99 也可提升40%以上。
5.2. 增加处理队列,使用独立线程池有序处理每次请求
CPU利用率最高的状态是,同一时刻单核CPU只处理一件事情,当本次请求处理完成后再继续下次请求处理,解决方案如下:

模型推理请求进入后,放入模型独立的处理队列,创建Future对象,由各模型独立的worker线程池来执行模型推理任务。如此,通过控制worker线程数量,尽可能减少上下文切换次数,提升CPU利用率。
6)深度模型batch聚合
对于深度模型来说,处理卷积运算,执行一次batchSize=10的推理的耗时远小于执行10次batchSize=1的推理耗时。
由此我们可以通过如上队列+独立线程池,天然的将请求和计算逻辑解耦,于是可以将单条的推理进行batch聚合操作,结果业务场景,通过时间窗口+batchSize对推理请求进行聚合,即在一定时间内,batchSize到达制定数量或等待时间到了,将聚合的多条推理请求一次性送入模型,进行执行推理。得到结果后依次分发,响应各future。
7)GPU推理加速
▪主要是环境依赖:容器环境下安装gpu驱动,cuda/cudnn。比较好的实践方案是使用NVIDIA 官方的docker镜像作为基础镜像,在此基础上构建公司内部基础依赖base镜像,再基于base镜像构建环境服务依赖->应用镜像。
8)除模型推理外,其他处理逻辑均异步
▪场景管理/路由规则查询异步化,基于caffine本地缓存,当本地缓存过期时,异步加载更新数据,不会造成穿透及tps抖动。
▪推理结果MQ落10K,MQ发送逻辑异步+批量化。与模型batch聚合类似,MQ消息推送本地内存队列,开启单个MQ发送线程,拉取队列消息,满足时间窗口/batchSize后进行聚合发送。
▪使用异步日志,性能提升约30%。
六、性能对比(提升近百倍)
以风控滑块人机识别CNN模型为例,使用tensorflow引擎,基于老的模型服务平台与迁移新的算法平台后,接口性能提升近百倍!
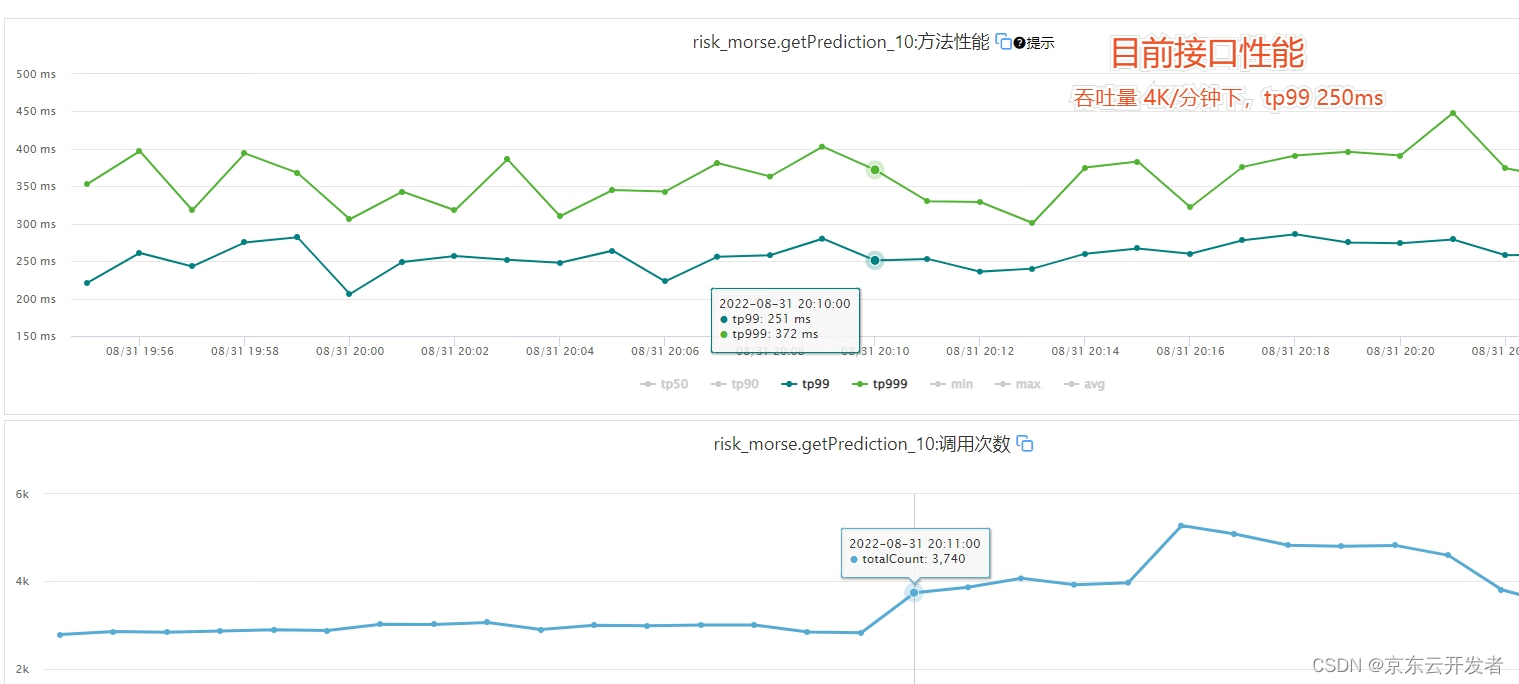

大促多个模型混个压测,整体性能如下:(CPU 使用率55%,满负荷(80%)下可达10W+ tps,tp99 11ms)

七、结语
目前算法服务平台为内部天盾决策引擎、滑块人机识别以及保险业务等多个场景提供实时模型推理服务,支撑相关模型推理服务大促不降级。
以上为在线推理服务模块整体设计与实现方案,其中细节部分未详细展开,感兴趣部分欢迎大家随时沟通交流~
-
相关阅读:
【论文简述】 Point-MVSNet:Point-Based Multi-View Stereo Network(ICCV 2019)
【IoT】生产制造:锅仔片上机做 SMT 加工吗?
DailyPractice.2023.10.19
RepGhost实战:使用RepGhost实现图像分类任务(一)
Linux ❀ 磁盘IO较大故障告警排查确认方法
html5怎么实现语音搜索
Go语言 并发与通道
2022“杭电杯”中国大学生算法设计超级联赛(1)(6题newbie,后续会更新)
SVG标签 内path标签自适应缩放问题
Redis缓冲穿透和缓冲击穿工具类的封装
- 原文地址:https://blog.csdn.net/jdcdev_/article/details/128017920