-
2022亚太杯C题思路代码分析
C题就是数学比较开放的题目了,属于一个数据分析类题目,跟前两年的华为杯差不多,考察的也是全球变暖问题。更多内容文末名片查看
问题1.你同意有关全球气温的说法吗?使用2022_APMCM_C_Data。附件中的csv和其他您的团队收集的数据集,以分析全球温度变化。
a)你同意2022年3月全球气温的上升导致了比过去10年期间更大的上升吗?为什么或为什么不呢?
b)根据历史数据,请建立两个或两个以上的数学模型来描述过去,并预测未来的
全球温度水平。
c)使用1个(b)中的每个模型来分别预测2050年和2100年的全球气温。你们的模型是否同意2050年或2100年全球观测点的平均温度将达到20.00°C的预测?如果不是在2050年或2100年,那么您的预测模型中的观测点的平均温度何时会达到20.00°C?
d)你认为1(b)的模型最准确?为什么
然后第一问主要是一个数据的预处理和预测类问题,首先是数据的预处理,对于给出的温度数据均经过严格的质量控制和均一性检验,对个别缺失数据采用相邻站点线性回归方法进行插补,保证经过处理修正后的气象数据具有很好的连续性,然后可以基RClimDex软件对数据异常值与错误值进行过滤筛选(也可以直接筛除),以满足分析要求。
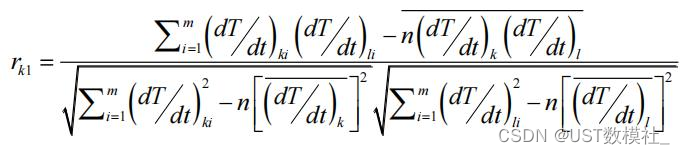
上面的公式为均一性检验
根据给出的数据,我们进行一个数据可视化处理,这里着重讲一下,亚太杯、包括美赛其实是很看重你的数据可视化能力的,图画的好不好,最终能够很大程度影响到你的成绩,这里推荐大家使用可视化工具tableau,比较简单好用,或者用python也可以,主要问题a就是通过对比来进行一个分析。
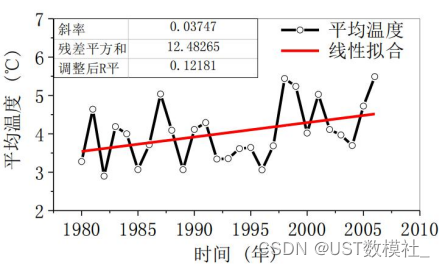
类似于上面的折线图就可以比较清晰的反映平均温度的变化
然后b是一个预测问题的话,推荐使用ARMA,比较适用,其他的像线性回归、灰色预测等等也可以用到。也可以使用LSTM模型来分析,这里我们用LSTM来求解一下,流程图如下:
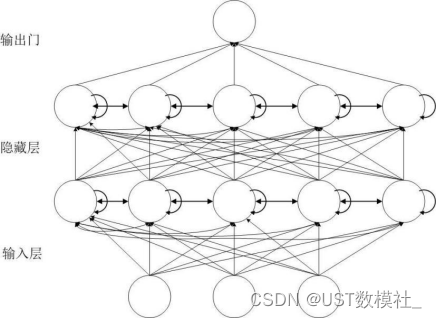
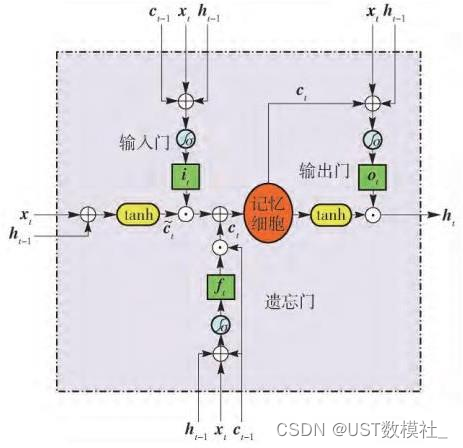
LSTM 的气候变化时空数据关键信息提取及趋势分析模型求解过程如下:
Step1:原始数据输入
输入给出的各个国家温度时间数据图
Step2:数据集化
将原始数据进行输入时空数据集化作为程序自变量的输入:
T[ ( u , v )
Step3:M-K 非参数统计
输出趋势检验指标如下:
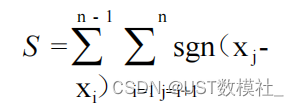
输出突变趋势检验检验如下:
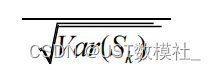
Step4:数据集输入 LSTM 气候时空趋势变化模型:
时空趋势模型通过 Python/matlab 进行程序实现,并且将 Step2 中的数据集输入程序。
部分 LSTM 机器学习代码
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- import torch
- from torch import nn
- from torch. aut ograd import Variable
- #LSTM(长短期记忆网络)
- data_csv = pd.read_csv
- #pandas.read_csv读取时空序列数据
- plt.plot(dat a_csv)
- plt.show()
- #数据预处理
- data_ csv = dat a csv. dropna()
- dat aset = dat_csv. values
- dataset = dat aset.astype ('float32')
- max_value = np. max (dataset)
- min value = np. min(dat aset)
- scalar = max_value-min_value
- dataset = list (map(
- lambda x∶ x/scalar,dataset))#将数据标准化到0~1之间
- def create_dataset(
- dataset,look_back=2)∶#look back 以前的时间步数用作输入变量来预测下—个时间段
- datak,dat aY=[ ],[ ]
- for i in range(len(dat aset)- look_back):
- a = dataset [i∶(
- i+look_back] #i和i+1赋值
- dat alX. append(a)
- dataY.append(
- dataset [i+look back]) #i+2赋值
- return np.array(
- dataX),np.array(
- datal) #np.array构建数组
- data X,data_Y = create_dataset (dataset)
- #data_Y: 1*142 data X: 2*142
- #划分训练集和测试集,70%作为训练集
- train_size = int (len(data_X)* 0.7)
- test_size = len(data_X)-train_size
- train_X = data_X[:train_size]
- train_Y = data_Y[:train_size]
- rrain_X =data_X[train_size:]
- train_Y = data_Y[train_size:]
- train_X = train_X.reshape(-1,1,2)
- #reshape中,-1使元素变为一行,然后输出为1列,每列2个子元素
- train_Y=train_Y.reshape(-1,1,1)#输出为1列,每列1个子元素
- Train_X=test_X.reshape(-1,1,2)
更多思路↓
-
相关阅读:
深入浅出PyTorch中的nn.CrossEntropyLoss
COM组件中调用JavaScript函数的实例讲解
14:00面试,14:06就出来了,问的问题有点变态。。。
C#窗体设计SaveFileDialog的用法
Rust错误处理简介
机器学习——代价敏感错误率与代价曲线
【Linux学习】跨平台开发 Linux + VS2019 环境配置(Ubantu16.04)
环保企业网站前后台管理系统(Java+SSM+MySQL)
027、工具_redis-benchmark
【07】请你谈谈单例模式的优缺点,注意事项,使用场景?
- 原文地址:https://blog.csdn.net/zzzzzzzxxaaa/article/details/128013840
