-
【Java八股文总结】之读写分离&分库分表
读写分离&分库分表
一、读写分离
1、何为读写分离
读写分离主要是为了 将对数据库的读写操作分散到不同的数据库节点上。 这样的话,就能够小幅提升写性能,大幅提升读性能。
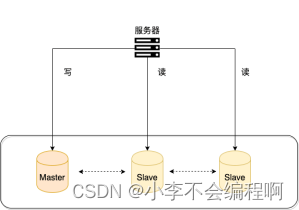
一般情况下,我们都会选择一主多从,也就是一台主数据库负责写,其他的从数据库负责读。主库和从库之间会进行数据同步,以保证从库中数据的准确性。这样的架构实现起来比较简单,并且也符合系统的写少读多的特点。2、读写分离会带来什么问题?如何解决?
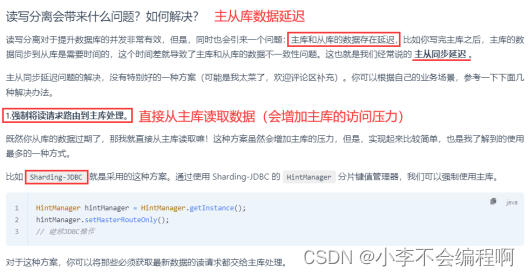

3、如何实现读写分离?

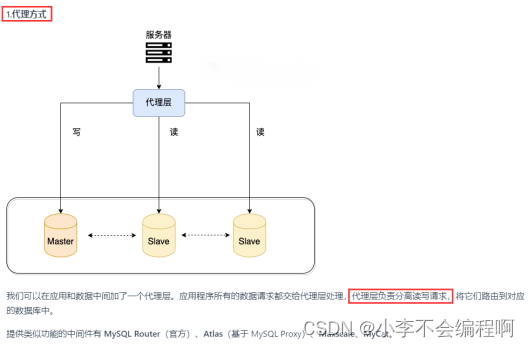

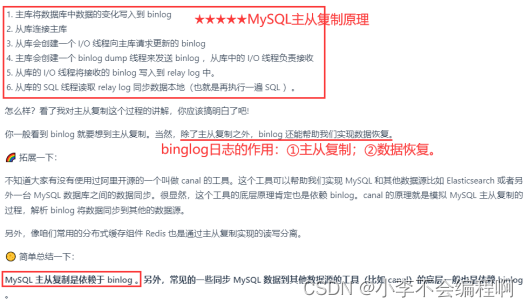
4、主从复制原理
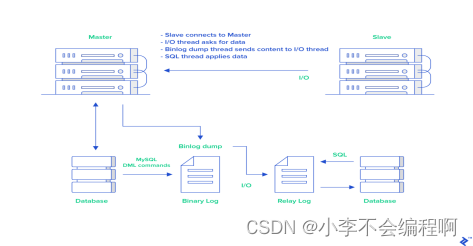
MySQL binlog(binary log即二进制日志文件)主要记录了MySQL数据库中数据的所有变化(数据库执行的所有DDL和DML语句)。因此,我们根据主库的MySQL binlog日志就能够将主库的数据同步到从库中。
二、分库分表
1、为什么要进行分库分表?
当MySQL中一张表的数据量过大的时候,不便于存储,因此我们需要分库分表。
2、何为分库?
分库 就是将数据库中的数据分散到不同的数据库上,可以是垂直拆分也可以是水平拆分。
下面这些操作都涉及到了分库:
①你将数据库中的用户表和用户订单表分别放在两个不同的数据库。
②由于用户表数据量太大,你对用户表进行了水平切分,然后将切分后的2张用户表分别放在两个不同的数据库。3、何为分表?
分表 就是 对单表的数据进行拆分 ,可以是垂直拆分,也可以是水平拆分。
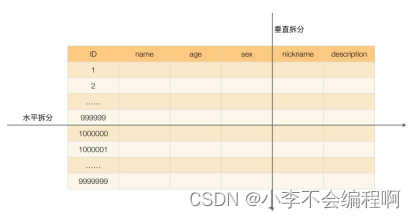
★4、垂直和水平拆分?
1、数据库的垂直&水平拆分?
垂直分库: 以表为依据,不同表到不同库,每个库的表结构和数据都不一样=,合起来是全量数据。(如用户表和用户订单表放到不同数据库)
水平分库: 以字段==为依据,一个库的数据拆分到多个库,每个库的表结构一致,数据不一致,合起来是全量数据。(如用户表的1-100000条记录在1号数据库,100001-200000条记录在2号数据库)2、表的垂直&水平拆分?
垂直分表: 以字段为依据(对列拆分),不同字段分到不同表,每个表结构和数据不一致,合起来是全量数据。(如将用户信息表的1-10列抽取出来作为一张表,10-20列抽取出来作为另一张表)
水平分表: 以字段为依据(对行拆分),一张表数据拆分到多张表,每个表结构一致,数据不一致,合起来是全量数据。(如将用户信息表的1-100000条记录作为表1,100001-200000条记录作为表2,这样就可以避免单一表数据量过大对性能造成影响)
5、什么时候需要分库分表?
遇到下面几种场景可以考虑分库分表:
①单表的 数据达到千万级别以上 ,数据库读写速度比较缓慢(分表)。
②数据库中的数据占用的空间越来越大,备份时间越来越长(分库)。
③应用的并发量太大(分库)。6、分库分表会带来什么问题?
引入分库分表之后,会给系统带来什么挑战呢?
① join操作:同一个数据库中的表分布在了不同的数据库中,导致无法使用 join操作。这样就导致我们需要手动进行数据的封装,比如你在一个数据库中查询到一个数据之后,再根据这个数据去另外一个数据库中找对应的数据。(不同数据库的表无法使用join操作,需要手动封装数据)
② 事务问题:同一个数据库中的表分布在了不同的数据库中,如果单个操作涉及到多个数据库,那么数据库自带的事务就无法满足我们的要求了。(不同数据库表操作,无法保证事务)
③ 分布式id:分库之后,数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。我们如何为不同的数据节点生成全局唯一主键呢?这个时候,我们就需要为我们的系统引入分布式id了。(不同数据库表操作,无法使用数据表的自增主键,得使用分布式id)7、分库分表使用什么?
ShardingSphere 项目(包括Sharding-JDBC、Sharding-Proxy和 Sharding-Sidecar)是当当捐入 Apache 的,目前主要由京东数科的一些巨佬维护。

8、分库分表后,数据如何迁移?
停机迁移,将老库的数据利用脚本文件更新到新库中。
双写方案,对老库的更新操作(增删改),同时也要写入新库(双写)。如果操作的数据不存在于新库的话,需要插入到新库中。这样就能保证,咱们新库里的数据是最新的。
在迁移过程,双写只会让被更新操作过的老库中的数据同步到新库,我们还需要自己写脚本 将老库中的数据和新库的数据做比对。如果新库中没有,那咱们就把数据插入到新库。如果新库有,旧库没有,就把新库对应的数据删除 (冗余数据清理)。重复上一步的操作,直到老库和新库的数据一致为止。9、分库分表后,ID键如何处理?
分库分表后不能每个表的ID都是从1开始,所以需要一个 全局ID ,设置全局ID主要有以下几种方法:
(1)UUID:
优点:本地生成ID,不需要远程调用,全局唯一不重复。
缺点:占用空间大,不适合作为索引。(2)数据库自增ID:
在分库分表表后使用数据库自增ID,需要一个专门用于生成主键的库,每次服务接收到请求,先向这个库中插入一条没有意义的数据,获取一个数据库自增的ID,利用这个ID去分库分表中写数据。
优点:简单易实现。
缺点:在高并发下存在瓶颈。(3)Redis生成ID:
优点:不依赖数据库,性能比较好。
缺点:引入新的组件会使得系统复杂度增加。(4)Twitter的snowflake雪花算法: 是一个64位的long型的ID,其中有1bit是不用的,41bit作为毫秒数,10bit作为工作机器ID,12bit作为序列号。
1bit:第一个bit默认为0,因为二进制中第一个bit为1的话为负数,但是ID不能为负数。
41bit:表示的是时间戳,单位是毫秒。
10bit:记录工作机器ID,其中5个bit表示机房ID,5个bit表示机器ID。
12bit:用来记录同一毫秒内产生的不同ID。 -
相关阅读:
kotlin基础之协程
最近面试被问到的vue题
C规范编辑笔记(四)
GO语言的错误处理
入门力扣自学笔记207 C++ (题目编号:1758)
破局「二次创业」:合思的新解法
芯片生产封装过程简介及概念
IO Watch:用 Arduino UNO 制造的可编程手表
【C语言进阶(14)】程序的编译与链接
linux常用命令
- 原文地址:https://blog.csdn.net/qq_46111316/article/details/127943066